本指南可協助您瀏覽進階容器網路服務 (ACNS),作為在 Azure Kubernetes Service (AKS) 中處理實際網路使用案例的主要解決方案。 無論是疑難排解 DNS 解析問題、最佳化輸入和輸出流量,或是確保遵守網路策略,本手冊皆會示範如何利用 ACNS 可觀測性儀表板、容器網路日誌、容器網路指標和視覺化工具來有效診斷和解決問題。
進階容器網路服務是 Microsoft 全面的企業級網路可觀察性和安全性平台,提供最進階的功能來監視、分析和疑難排解 AKS 叢集中的網路流量。 這包括預先建置的 Grafana 儀表板、即時指標、詳細記錄和 AI 支援的見解,可協助您深入了解網路效能、快速識別問題,並透過完整的 Microsoft 支援最佳化容器網路環境。
進階容器網路服務儀錶板概觀
我們已建立進階容器網路服務的範例儀錶板,以協助您在 Kubernetes 叢集中可視化和分析網路流量、DNS 要求和封包捨棄。 這些儀錶板的設計目的是提供網路效能的深入解析、找出潛在問題,以及協助進行疑難解答。 若要瞭解如何設定這些儀錶板,請參閱 設定 Azure Kubernetes Service (AKS) 的容器網路可觀察性 - 由 Azure 管理的 Prometheus 和 Grafana。
儀表板套件中包含:
- 流程記錄:顯示 Pod、命名空間和外部端點之間的網路流量。
- 流量記錄 (外部流量):顯示 Pod 與外部端點之間的網路流量流量。
- 叢集:顯示叢集的節點層級計量。
- DNS (叢集):顯示叢集或所選節點上的 DNS 計量。
- DNS (工作負載):顯示指定工作負載的 DNS 計量 (例如,DaemonSet 的 Pod 或部署,例如 CoreDNS)。
- 置放 (工作負載):顯示指定工作負載為目的地/來源的置放 (例如部署或 DaemonSet 的 Pod)。
- Pod 流量(命名空間):顯示進出指定命名空間的 L4/L7 封包流量(也就是命名空間中的 Pod)。
- Pod 流量 (工作負載):顯示從指定的工作負載往返的 L4/L7 封包流量 (例如,部署或精靈集的 Pod)。
- L7 流程(命名空間):套用第 7 層原則時,顯示 HTTP、Kafka 和 gRPC 封包流程,來自或發往指定的命名空間(亦即命名空間中的 Pod)。 這僅適用於具有 Cilium 數據平面的叢集。
- L7 流量(工作負載):在套用基於第 7 層的政策時,顯示 HTTP、Kafka 和 gRPC 流量來自或前往指定工作負載的情況(例如,部署的 Pod 或 DaemonSet)。 這僅適用於具有 Cilium 數據平面的叢集。
使用案例 1:解析域名伺服器(DNS)問題以進行根因分析(RCA)
Pod 層級的 DNS 問題可能會導致服務探索失敗、應用程式回應緩慢,或 Pod 之間的通訊失敗。 這些問題經常發生於設定錯誤的 DNS 原則、有限的查詢容量,或解決外部網域的延遲。 例如,如果 CoreDNS 服務超載或上游 DNS 伺服器停止回應,可能會導致相依 Pod 失敗。 解決這些問題不僅需要識別,而且需要深入查看叢集中的 DNS 行為。
假設您已在 AKS 叢集中設定 Web 應用程式,而且現在無法連線到 Web 應用程式。 當 DNS 伺服器解析 Web 應用程式的位址時,您會收到 DNS 錯誤,例如
DNS_PROBE_FINISHED_NXDOMAIN或SERVFAIL。
步驟 1:在 Grafana 儀錶板中查看 DNS 效能指標
我們已建立兩個 DNS 儀表板來調查 DNS 計量、要求和回應:DNS (叢集) 顯示叢集或節點選擇上的 DNS 指標,以及 DNS (工作負載) 顯示特定工作負載的 DNS 計量 (例如,DaemonSet 的 Pod 或 CoreDNS 等部署)。
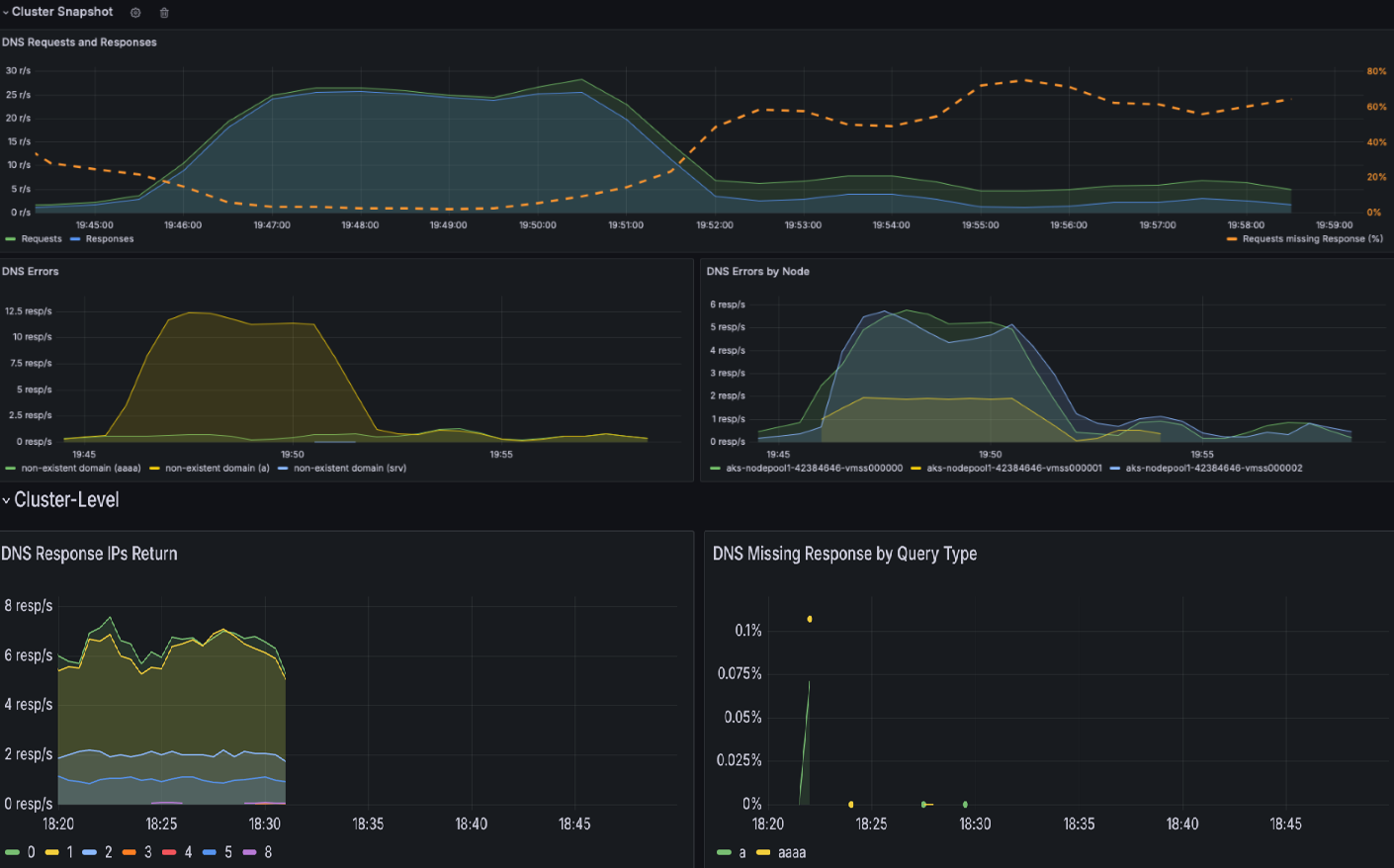
檢查 DNS 叢集 儀表板以取得所有 DNS 活動的快照。 此儀錶板提供 DNS 要求和回應的高階概觀,例如哪些查詢缺少回應、最常見的查詢,以及最常見的回應。 它也會醒目提示最上方的 DNS 錯誤,以及產生大部分錯誤的節點。
向下滾動以找出所有命名空間中具有最多 DNS 請求和錯誤的 Pod。
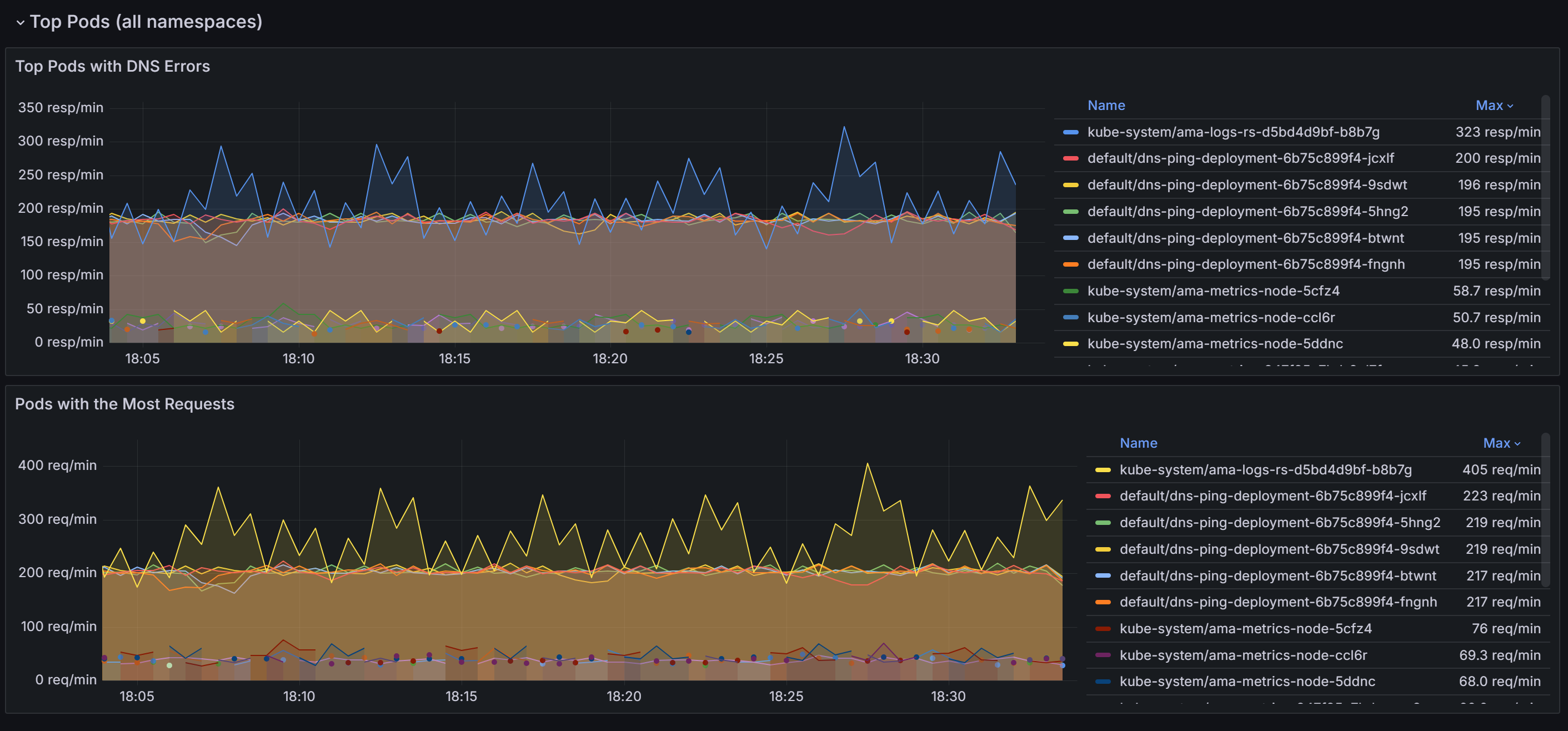
識別出造成最多 DNS 問題的 Pod 之後,您可以進一步深入研究 DNS 工作負載 儀表板,以獲得更精細的檢視。 透過將儀錶板內各種面板的數據相互關聯,您可以有系統地縮小問題的根本原因。
「DNS 要求」和「DNS 回應」區段可讓您識別趨勢,例如回應率突然下降或遺失回應增加。 高要求遺漏回應 % 表示潛在的上游 DNS 伺服器問題或查詢多載。 在範例儀錶板的下列螢幕快照中,您可以看到要求和回應在 15.22 左右突然增加。

依類型檢查是否有任何 DNS 錯誤,並檢查特定錯誤類型的峰值 (例如,
NXDOMAIN表示不存在的網域)。 在此範例中, 查詢拒絕的錯誤大幅增加,這表示 DNS 設定或不支援的查詢不相符。
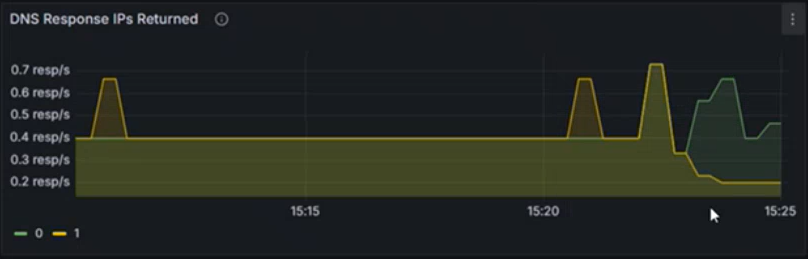
使用 DNS 回應 IP 傳回 等區段,以確保預期的回應正在處理中。 此圖表會顯示每秒處理成功的 DNS 查詢速率。 這項資訊有助於瞭解為指定的工作負載成功解析 DNS 查詢的頻率。
- 增加的速率可能表示流量激增或潛在的 DNS 攻擊 (例如,分散式阻斷服務 (DDoS))。
- 降低的速率可能表示連線到外部 DNS 伺服器時出現問題、CoreDNS 設定問題,或無法自 CoreDNS 連線的工作負載。
檢查最常見的 DNS 查詢有助於識別網路流量中的模式。 這項資訊有助於瞭解工作負載散發,並偵測任何可能需要注意的異常或非預期查詢行為。

DNS 回應表可藉由醒目提示查詢類型、回應和錯誤碼,例如SERVFAIL (伺服器失敗),協助您進行 DNS 問題根本原因分析。 它會識別有問題的查詢、失敗模式或設定錯誤。 藉由觀察傳回碼和回應率的趨勢,您可以找出導致 DNS 中斷或異常的特定節點、工作負載或查詢。
在下列範例中,您可以看到對於 AAAA (IPV6) 記錄,沒有錯誤,但 A (IPV4) 記錄發生伺服器故障。 有時候,DNS 伺服器可能會設定為將 IPv6 優先於 IPv4。 這可能會導致 IPv6 位址正確傳回的情況,但 IPv4 位址會面臨問題。

確認發生 DNS 問題時,下圖會識別造成特定工作負載或命名空間中 DNS 錯誤的前十個端點。 您可以使用此選項來排定疑難解答特定端點的優先順序、偵測設定錯誤,或調查網路問題。









步驟 2:分析容器網路記錄的 DNS 解析問題
容器網路記錄提供 DNS 查詢及其回應在預存和隨選模式中的詳細深入解析。 使用容器網路記錄,您可以分析特定 Pod 的 DNS 相關流量,其中顯示 DNS 查詢、回應、錯誤碼和延遲等詳細數據。 若要在 Log Analytics 工作區中檢視 DNS 流程,請使用下列 KQL 查詢:
RetinaNetworkFlowLogs | where TimeGenerated between (datetime(<start-time>) .. datetime(<end-time>)) | where Layer4.UDP.destination_port == 53 | where Layer7.type == "REQUEST" | where Reply == false or isnull(Reply) | project TimeGenerated, SourcePodName, DestinationPodName, Layer7.dns.query, Layer7.dns.qtypes, Verdict, TrafficDirection, AdditionalFlowData.Summary, NodeName, SourceNamespace, DestinationNamespace | order by TimeGenerated desc將
<start-time>和<end-time>替換為格式2025-08-12T00:00:00Z中的想要時間範圍。容器網路記錄提供 DNS 查詢及其回應的完整見解,有助於診斷和疑難解答 DNS 相關問題。 每個日誌項目都包含查詢類型 (例如 A 或 AAAA)、查詢的網域名稱、DNS 回應代碼 (例如查詢 拒絕、 不存在網域或 伺服器失敗) 以及 DNS 要求的來源和目的地等資訊。
識別查詢狀態:檢查 [判決 ] 字段是否有 DROPD 或 FORWARDED 等回應,這表示網路連線或原則強制執行的問題。
確認來源和目的地:確定 SourcePodName 和 DestinationPodName 欄位中所列的 Pod 名稱正確無誤,且通訊路徑為預期。
追蹤流量模式:查看 判定 字段,以了解請求是被轉發還是丟棄。 轉送中斷可能表示網路或設定問題。
分析時間戳記:使用 TimeGenerated 欄位將特定 DNS 問題與系統中的其他事件產生關聯,以進行全面診斷。
依 Pod 和命名空間進行篩選:使用 SourcePodName、DestinationPodName 和 SourceNamespace 等字段,專注於遇到問題的特定工作負載。
步驟 3:使用容器網路記錄儀錶板將 DNS 流量可視化
容器網路記錄可透過 Azure 入口網站儀錶板和 Azure Managed Grafana 提供豐富的可視化功能。 服務相依性圖表和流程記錄視覺效果藉由提供 DNS 相關流量和相依性的可視化見解,來補充詳細的記錄分析:
- 服務相依性圖表:將哪些 Pod 或服務傳送大量 DNS 查詢及其關聯性可視化
- 流量記錄儀錶板:即時監視 DNS 要求模式、錯誤率和回應時間
- 流量分析:識別已被捨棄的 DNS 封包,以及通往 CoreDNS 或外部 DNS 服務的通訊路徑

您可以透過下列方式存取這些視覺效果:
- Azure 入口網站:瀏覽您的 AKS 叢集 → 洞察 → 網路 → 流程記錄
- Azure 受控 Grafana:使用預先設定的「流量記錄」和「流量記錄 (外部流量)」儀表板
透過 Grafana 儀錶板、容器網路記錄的歷史分析儲存模式,以及即時疑難排解的即時記錄功能,您可以識別 DNS 問題,並有效地進行根本原因分析。
使用案例 2:由於設定錯誤的網路政策或網路連接問題,識別叢集及 Pod 層級的封包丟失問題
連線和網路原則強制執行問題通常源於設定錯誤的 Kubernetes 網路原則、不相容的容器網路介面 (CNI) 外掛程式、重疊的 IP 範圍或網路連線降低。 這類問題可能會中斷應用程式功能,導致服務中斷和用戶體驗降低。
當封包掉落時,eBPF 程式會擷取該事件並產生關於封包的元數據,包括掉落的原因及其發生位置。 此數據是由使用者空間程序處理,它會剖析資訊,並將其轉換成 Prometheus 計量。 這些計量提供封包捨棄的根本原因的重要見解,讓系統管理員能夠有效識別並解決網路原則設定錯誤等問題。
除了原則強制執行問題之外,網路連線問題也可能因為 TCP 錯誤或重新傳輸等因素而造成封包中斷。 系統管理員可以藉由分析 TCP 重新傳輸數據表和錯誤記錄來偵錯這些問題,以協助識別降級的網路連結或瓶頸。 透過運用這些詳細指標與除錯工具,團隊能確保網路運作順暢、減少停機時間,並維持最佳應用程式效能。
假設您有一個以微服務為基礎的應用程式,由於網路政策過於限制阻擋了入口流量,導致前端 Pod 無法與後端 Pod 進行通訊。
步驟 1:調查 Grafana 儀表板中的卸除計量
如果有封包卸除,請使用 [Pod 流量 (命名空間)] 儀表板開始調查。 此儀表板有面板可協助識別具有最多卸除的命名空間,接著識別具有最多卸除的命名空間內的 Pod。 例如,讓我們檢閱 [前幾名來源 Pod 的傳出卸除熱度圖] 或 [前幾名目的地 Pod],以識別哪些 Pod 最受影響。 較亮的色彩表示下降率較高。 跨時間比較,以偵測特定 Pod 中的模式或尖峰。
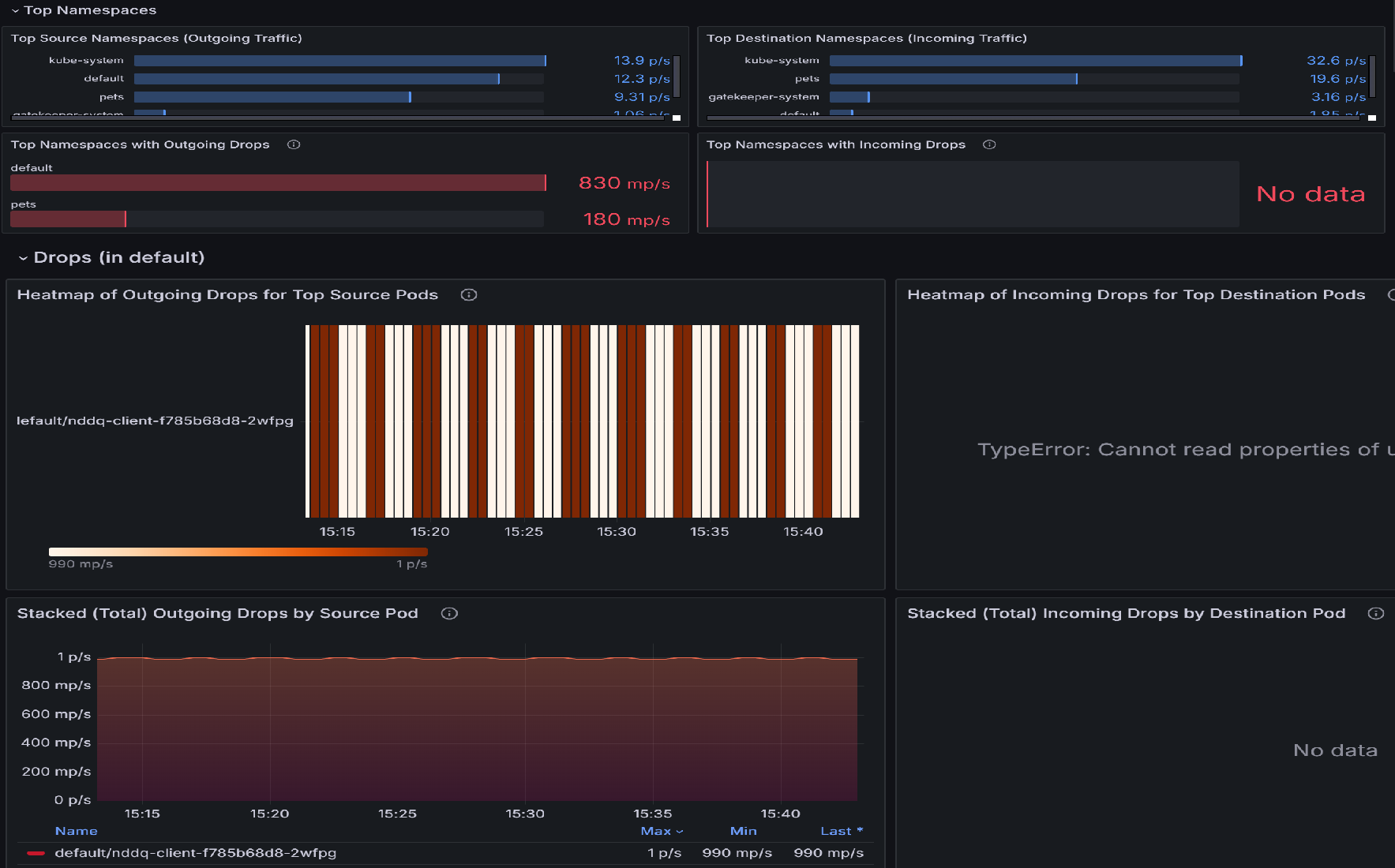
識別掉落率最高的頂端 Pod 之後,請移至 捨棄 (工作負載) 儀表板。 您可以使用此儀錶板來診斷網路連線問題,方法是識別來自特定 Pod 的連出流量下降模式。 視覺效果會醒目提示哪些 Pod 遇到最多卸除、這些卸除的比率,以及其背後原因,例如原則拒絕。 您可使卸除率的峰值與特定 Pod 或時間範圍相互關聯,指出設定錯誤、多載服務或可能會中斷連線的原則強制執行問題。
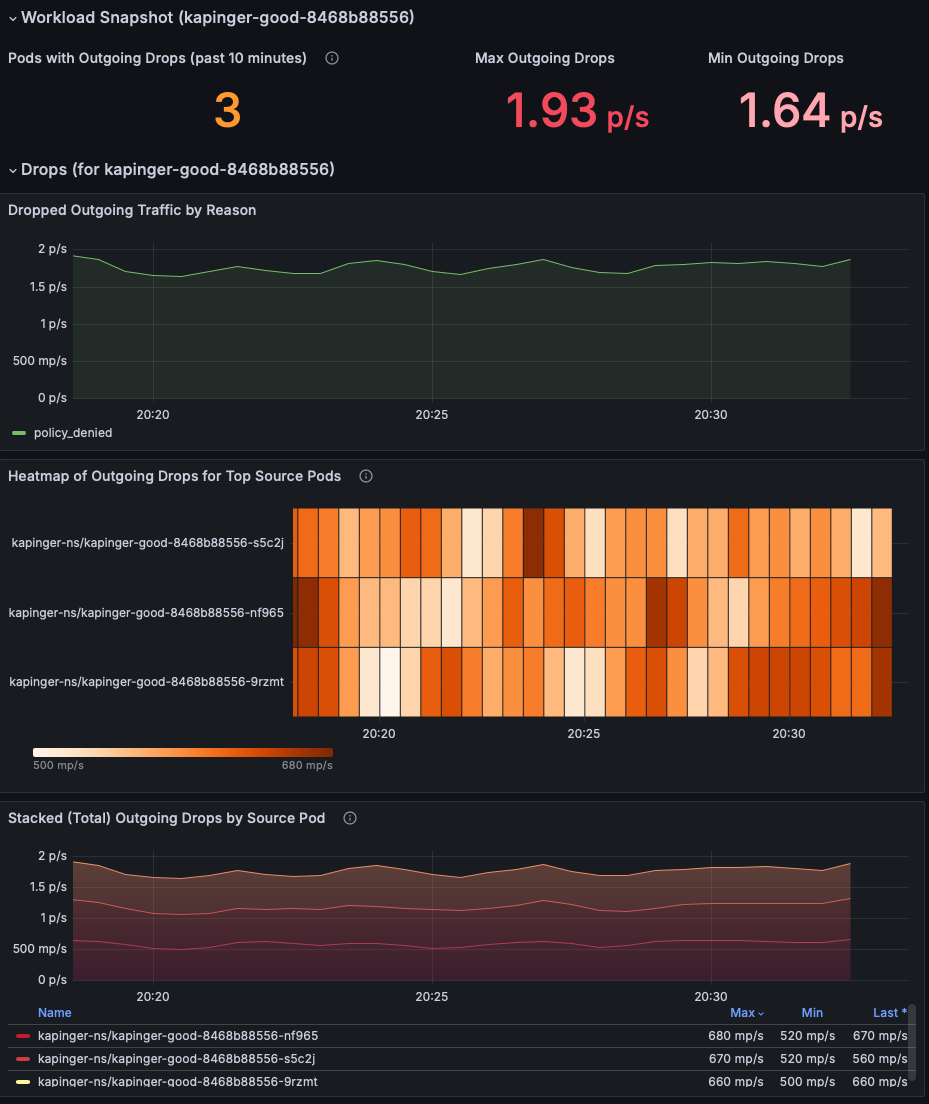
檢閱「工作負載快照」區段,以識別具有傳出封包捨棄的 Pod。 將焦點放在 [傳出卸除上限] 和 [傳出卸除下限] 計量,以了解問題的嚴重性 (此範例顯示每秒 1.93 個封包)。 為封包卸除率居高不下的調查中 Pod 設定優先順序。
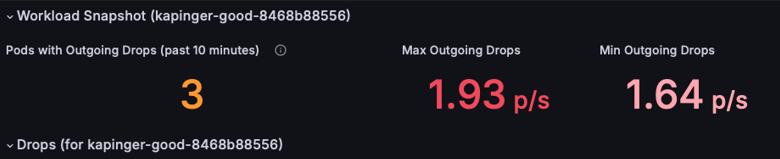
使用 [依原因的已卸除傳入/傳出流量] 圖表來識別卸除的根本原因。 在此範例中,原因是原則遭到拒絕,這表示網路原則設定錯誤,導致阻擋傳出流量。 檢查是否有任何特定的時間間隔顯示卸除峰值,以在問題開始時縮小範圍。
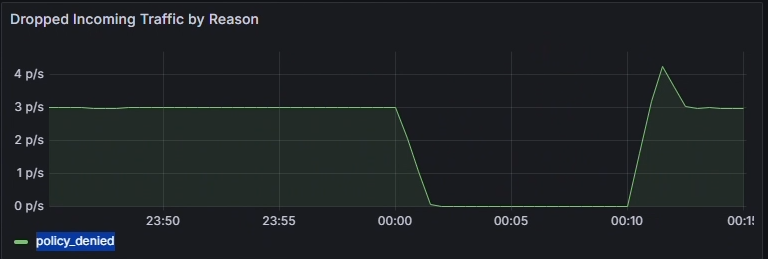
使用 [前幾名來源/目的地 Pod 的傳入卸除熱度圖] 來識別哪些 Pod 最受影響。 較亮的色彩表示下降率較高。 跨時間比較,以偵測特定 Pod 中的模式或尖峰。
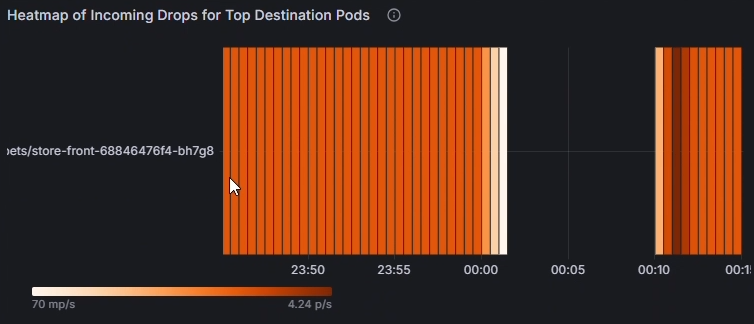
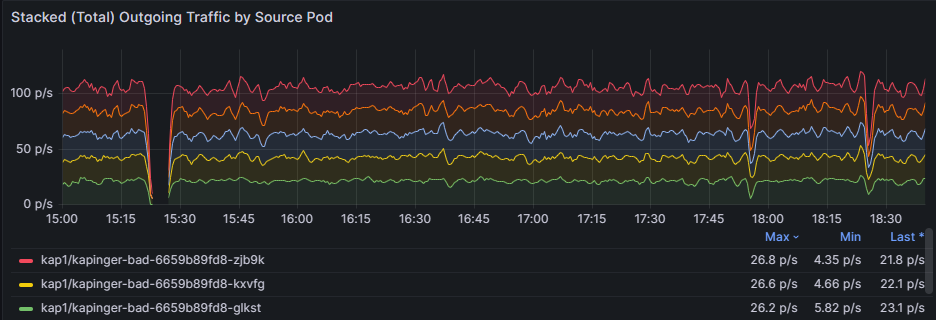
使用 [依來源 Pod 的堆疊 (總計) 傳出/傳入卸除] 圖表來比較受影響 Pod 之間的卸除率。 識別特定 Pod 是否一直顯示較高的卸除 (例如,每秒 26.8 個封包的 kapinger-bad-6659b89fd8-zjb9k)。 在這裡,p/s 是指每秒的卸除封包。 將這些 Pod 與其工作負載、標籤和網路原則交叉參考,以診斷潛在的設定錯誤。






步驟 2:使用容器網路記錄分析封包丟失
容器網路日誌系統提供全面深入的分析,能夠檢測由於網路原則配置錯誤導致的封包丟棄,並且提供詳細的即時和歷史數據。 您可以藉由檢查特定的卸除原因、模式和受影響的工作負載,來分析已卸除的封包。
在您的 Log Analytics 工作區中使用下列 KQL 查詢來辨識封包丟棄:
RetinaNetworkFlowLogs
| where TimeGenerated between (datetime(<start-time>) .. datetime(<end-time>))
| where Verdict == "DROPPED"
| summarize DropCount = count() by SourcePodName, DestinationPodName, SourceNamespace, bin(TimeGenerated, 5m)
| order by TimeGenerated desc, DropCount desc
若要即時分析已卸除的封包,您也可以依特定 Pod 或命名空間進行篩選:
RetinaNetworkFlowLogs
| where TimeGenerated between (datetime(<start-time>) .. datetime(<end-time>))
| where Verdict == "DROPPED"
| where SourceNamespace == "<namespace-name>"
| project TimeGenerated, SourcePodName, DestinationPodName, SourceNamespace, DestinationNamespace, Verdict, TrafficDirection
| order by TimeGenerated desc
將 <start-time> 和 <end-time> 替換為格式 2025-08-12T00:00:00Z 中的想要時間範圍。
容器網路記錄提供對丟棄封包的深入見解,協助您識別錯誤配置的網路政策並驗證修正措施。 這些記錄包含卸除原因、受影響的 Pod,以及可引導疑難排解工作的流量模式相關詳細資訊。
步驟 3:使用容器網路日誌儀表板來可視化封包遺失情況
容器網路日誌提供流量流向和丟棄封包的視覺化表示,並透過 Azure 入口網站儀表板和 Azure Managed Grafana 進行展示。 流量記錄儀錶板會顯示相同命名空間內的Pod、其他命名空間中的Pod,以及來自叢集外部的流量之間的互動。
主要視覺效果功能包括:
- 依原因丟棄分析:識別封包遭到丟棄的原因(策略拒絕、連線追蹤等)
- 流量流向圖:允許和拒絕流量的視覺表示法
- 命名空間和 Pod 層級深入解析:來源和目的地關聯性的詳細檢視
- 時間序列分析:封包丟棄的歷史趨勢及其原因

這項數據有助於檢閱叢集中套用的網路原則,讓系統管理員透過完整的記錄分析和可視化表示,快速識別並解決任何設定錯誤或有問題的原則。
使用案例 3:識別工作負載和命名空間內的流量不平衡
與其他人相比,工作負載或命名空間內的特定 Pod 或服務會處理不成比例的高網路流量時,就會發生流量不平衡。 這可能會導致資源競爭,超載的 Pod 效能降低,以及其他 Pod 資源使用不充分。 這類不平衡通常是因為設定錯誤的服務、負載平衡器不平均的流量分配,或非預期的使用模式所造成。 如果沒有可觀察性,則很難識別哪些 Pod 或命名空間已超載或使用量過低。 進階容器網路服務可藉由監視Pod層級的即時流量模式,提供頻寬使用量、要求率和延遲的計量,讓您輕鬆找出不平衡狀況。
假設您有一個在 AKS 叢集上運行的線上零售平台。 此平臺包含多個微服務,包括產品搜尋服務、使用者驗證服務,以及透過 Kafka 通訊的訂單處理服務。 在季節性銷售期間,產品搜尋服務會經歷流量激增,而其他服務則保持閑置狀態。 負載平衡器無意中將更多要求導向至產品搜尋部署內的Pod子集,導致搜尋查詢的壅塞和延遲增加。 同時,相同部署中的其他 Pod 使用量過低。
步驟 1. 依 Grafana 儀表板調查 Pod 流量
檢視 [Pod 流量 (工作負載)] 儀表板。 工作負載快照會顯示各種統計資料、例如傳出和傳入流量、以及傳出和傳入捨棄。

檢視每個追蹤類型的流量波動。 藍色和綠色線條中的顯著變化表示應用程式和服務的流量變更,這可能會導致壅塞。 藉由識別高流量的期間,您可以找出壅塞的時間,並進一步調查。 此外,比較傳出和傳入流量模式。 如果連出和連入流量之間有顯著的不平衡,則可能表示網路壅塞或瓶頸。

熱圖代表 Kubernetes 叢集中 Pod 層級的流量計量。 前 10 個來源 Pod 的連出流量熱度圖顯示的為來自這些 Pod 的連出流量,而前 10 個目標 Pod 的連入流量熱度圖顯示的為進入這些 Pod 的流量。 色彩強度表示流量量,而較深的陰影代表較高的流量。 一致的模式會將產生或接收大量流量的 Pod 進行醒目提示,例如 default/tcp-client-0 可能作為中央節點。
下列熱度圖指示較高流量正在接收單一 Pod 並從中傳出。 如果相同的 Pod (例如,default/tcp-client-0) 出現在兩個具有高流量強度的熱圖中,則可能表示同時傳送和接收大量流量,可能在工作負載中作為中央節點。 Pod 之間強度的變化可能表示流量分佈不平均,有些 Pod 處理的流量比其他 Pod 多得不成比例。

監視 TCP 重設流量對於瞭解網路行為、疑難解答問題、強制執行安全性和優化應用程式效能至關重要。 它提供如何管理和終止連線的寶貴見解,讓網路和系統管理員能夠維護狀況良好、有效率且安全的環境。 這些指標揭示有多少 Pod 積極參與傳送或接收 TCP RST 封包,這可能表示不穩定的連線或配置錯誤的 Pod 導致網路壅塞。 高重設比率表示 Pod 可能因為連線嘗試或發生資源爭用而不堪負荷。

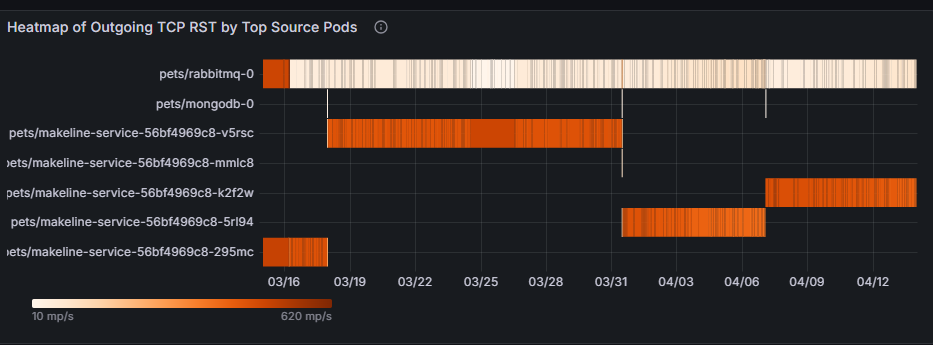
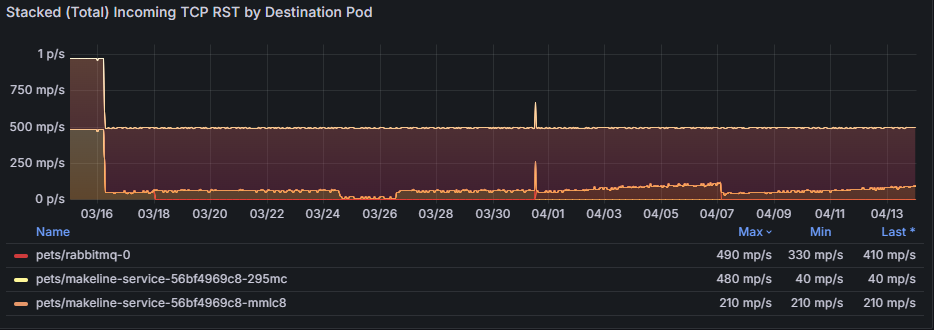
頂端來源 Pod 的傳出 TCP RST 熱度圖顯示哪些來源 Pod 產生最多 TCP RST 封包,以及活動何時達到尖峰。 在下列範例熱圖中,如果 pets/rabbitmq-0 在尖峰流量時段持續顯示高傳出重設,則可能表示應用程式或其基礎資源 (CPU、記憶體) 超載。 解決方案可能是優化Pod的組態、調整資源,或平均分散跨複本的流量。
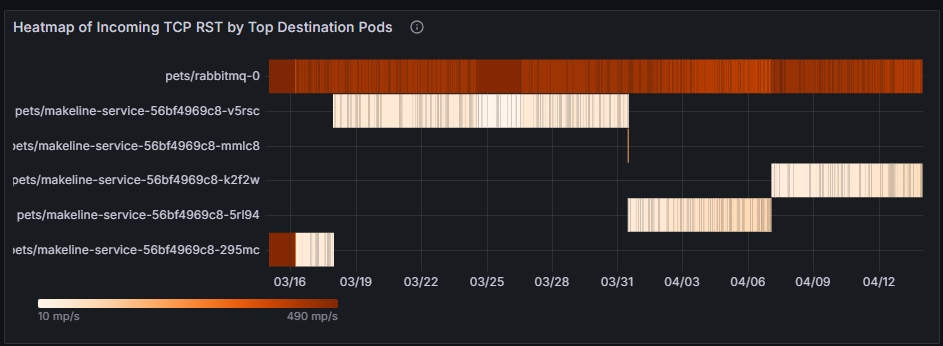
傳入 TCP RST 的頂端目的地 Pod 熱圖 識別那些接收最多 TCP RST 封包的目的地 Pod,指出這些 Pod 可能存在的瓶頸或連線問題。 如果 pets/mongodb-0 經常接收 RST 封包,則可能是資料庫連結超載或網路設定錯誤的指標。 解決方案可能是增加資料庫容量、實作速率限制,或調查造成過多連線的上游工作負載。
[依來源 Pod 的堆疊 (總計) 傳出 TCP RST] 圖表提供一段時間傳出重設的彙總檢視,並醒目提示趨勢或異常狀況。
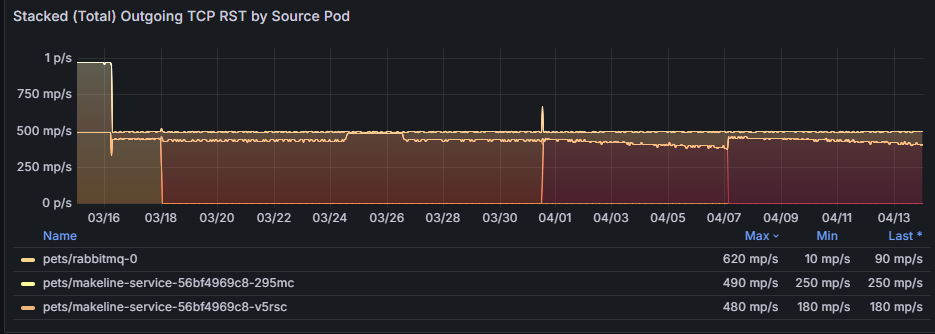
[依目的地 Pod 的堆疊 (總計) 傳入 TCP RST] 圖表彙總傳入重設,並顯示網路壅塞對目的地 Pod 有何影響。 例如,pets/rabbitmq-0 的重設次數持續增加可能表示該服務無法有效處理傳入流量,從而導致逾時。








使用容器網路記錄分析流量不平衡
除了使用 Grafana 儀錶板之外,您還可以使用容器網路記錄來分析流量模式,並透過 KQL 查詢識別不平衡:
// Identify pods with high traffic volume (potential imbalances)
RetinaNetworkFlowLogs
| where TimeGenerated between (datetime(<start-time>) .. datetime(<end-time>))
| extend TCP = parse_json(Layer4).TCP
| extend SourcePort = TCP.source_port, DestinationPort = TCP.destination_port
| summarize TotalConnections = count() by SourcePodName, SourceNamespace
| top 10 by TotalConnections desc
// Analyze TCP reset patterns to identify connection issues
RetinaNetworkFlowLogs
| where TimeGenerated between (datetime(<start-time>) .. datetime(<end-time>))
| extend TCP = parse_json(Layer4).TCP
| extend Flags = TCP.flags
| where Flags contains "RST"
| summarize ResetCount = count() by SourcePodName, DestinationPodName, bin(TimeGenerated, 5m)
| order by TimeGenerated desc, ResetCount desc
將 <start-time> 和 <end-time> 替換為格式 2025-08-12T00:00:00Z 中的想要時間範圍。
這些查詢有助於識別儀錶板視覺效果中可能不會立即顯示的流量不平衡和連線問題。
使用案例 4:即時監視叢集的網路健康情況和效能
在高層級呈現叢集的網路健康情況計量,對於確保系統的整體穩定性和效能至關重要。 高階計量可讓您快速且全面地檢視叢集的網路效能,讓系統管理員輕鬆找出潛在的瓶頸、失敗或效率不佳,而不需要深入探討細微的詳細數據。 這些指標,例如延遲、吞吐量、封包遺失和錯誤率,提供叢集狀況的概況,讓主動式監控和快速疑難排解。
我們有一個代表叢集整體健康情況的範例儀錶板: Kubernetes/網路/叢集。 讓我們深入探討整體儀錶板。
識別網路瓶頸:藉由分析 位元組轉送 和 封包轉送 圖表,您可以識別是否有任何突然下降或尖峰,指出網路的潛在瓶頸或壅塞。

偵測封包遺失:丟棄的封包和丟棄的位元組區段有助於識別特定叢集內是否發生重大封包遺失,這可能表示有硬體故障或網路設定錯誤的問題。

監視流量模式:您可以監視一段時間的流量模式,以瞭解正常與異常行為,這有助於主動進行疑難解答。 藉由比較最大和最小輸入/輸出位元組和封包,您可以分析效能趨勢,並判斷特定時間或特定工作負載是否導致效能降低。

診斷卸除原因: [依原因捨棄的位元組 ] 和 [ 依原因捨棄的封包] 區段有助於瞭解封包捨棄的特定原因,例如原則拒絕或未知的通訊協定。

節點特定分析:節點丟棄的位元組數和節點丟棄的封包數圖表可讓您深入了解封包丟棄次數最多的節點。 這有助於找出有問題的節點,並採取更正動作來改善網路效能。

TCP 連線的分佈:此圖表顯示 TCP 連線在不同狀態下的分佈。 例如,如果圖表顯示狀態中異常大量的連線
SYN_SENT,則可能表示叢集節點因為網路等待時間或設定錯誤而無法建立連線。 另一方面,處於TIME_WAIT狀態的大量連線可能暗示連線未正確釋出,而可能導致資源耗盡。






使用案例 5:診斷應用層級網路問題
L7 流量可觀察性藉由提供 HTTP、gRPC 和 Kafka 流量的深入可見度,來解決重要的應用層網路問題。 這些深入解析有助於偵測高錯誤率的問題(例如 4xx 用戶端或 5xx 伺服器端錯誤)、非預期的流量下降、延遲尖峰、Pod 之間的流量分佈不平均,以及設定錯誤的網路原則。 在複雜的微服務架構中,通常會發生這些問題,其中服務之間的相依性很複雜,而資源配置是動態的。 例如,丟失的 Kafka 訊息或延遲的 gRPC 呼叫突然增加,可能表示訊息處理或網路壅塞的瓶頸問題。
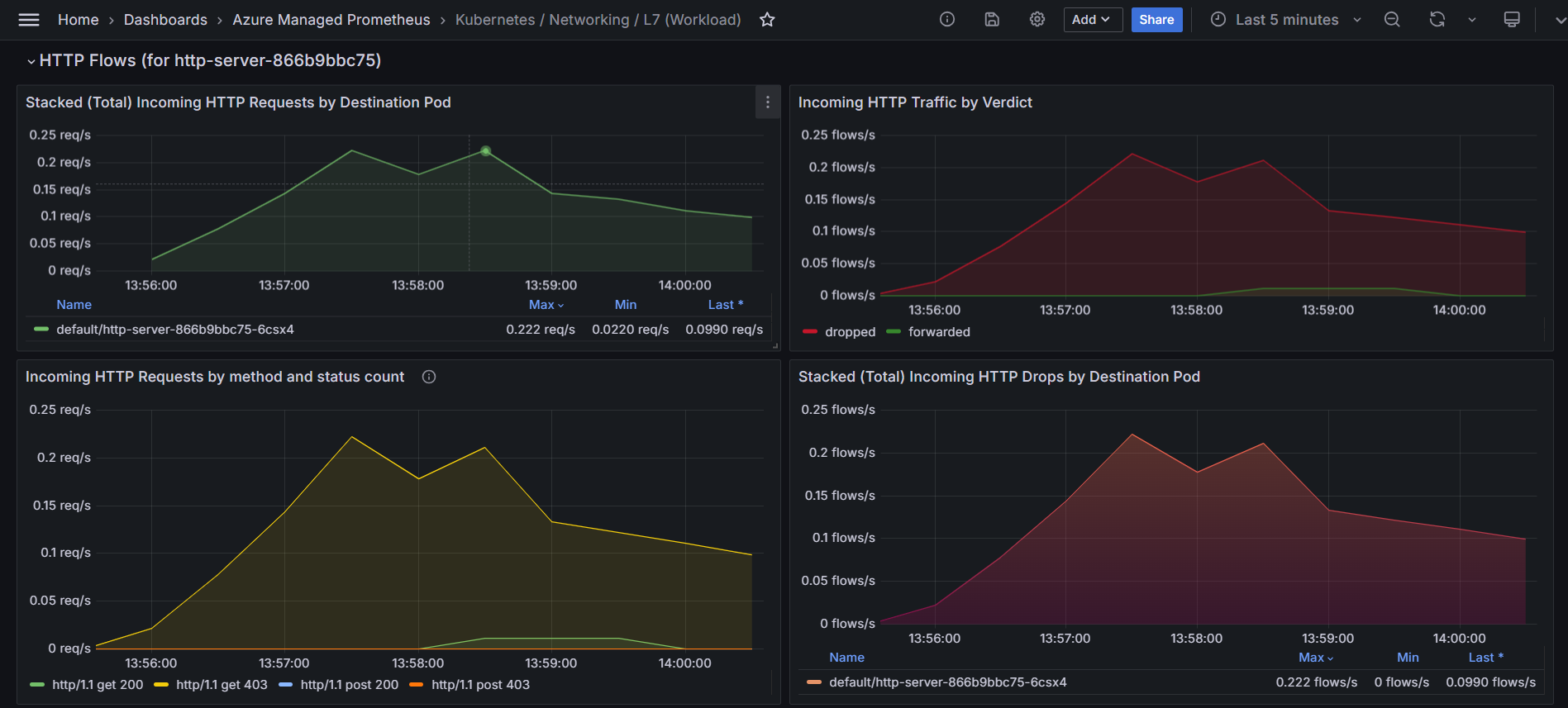
假設您已在 Kubernetes 叢集中部署電子商務平臺,前端服務依賴數個後端微服務,包括付款網關 (gRPC)、產品目錄 (HTTP),以及透過 Kafka 通訊的訂單處理服務。 最近,用戶回報結帳失敗增加,頁面載入時間變慢。 讓我們更深入地了解如何針對 L7 流量的使用預先設定儀表板執行此問題的 RCA:Kubernetes/Networking/L7 (命名空間) 和 Kubernetes/Networking/L7 (工作負載)。
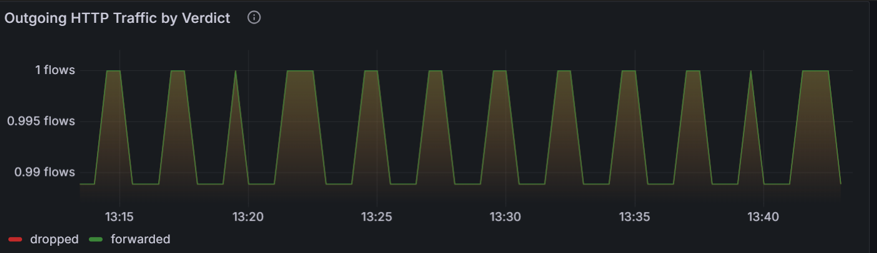
識別已卸除和已轉送 HTTP 要求的模式。 在下圖中,傳出 HTTP 流量會依決策區隔,並醒目提示要求「已轉送」還是「已卸除」。在電子商務平台中,此圖表可協助識別結帳流程中的潛在瓶頸或失敗。 如果丟失的 HTTP 流量明顯增加,可能表示前端與後端服務之間存在配置錯誤的網路策略、資源限制或連線問題。 藉由將此圖表與用戶投訴的特定時間範圍相互關聯,系統管理員可以找出這些下降是否與結帳失敗相符。
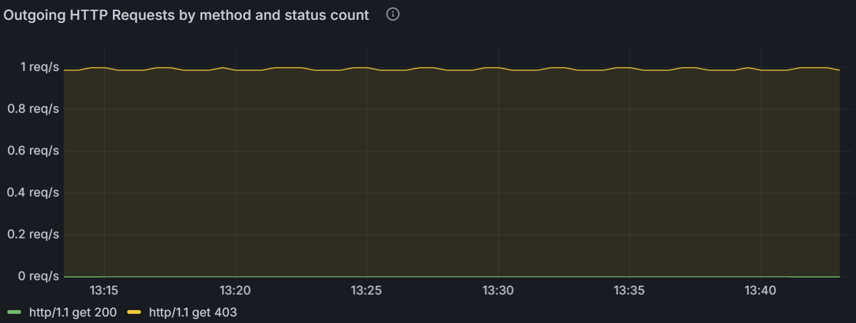
下列折線圖描述一段時間內傳出 HTTP 請求的速率,並依其狀態碼 (例如 200、403) 分類。 您可以使用此圖表來識別錯誤率的峰值 (例如 403 Forbidden 錯誤),這可能表示驗證或存取控制出現問題。 藉由將這些尖峰與特定時間間隔相互關聯,您可以調查並解決根本問題,例如設定錯誤的安全策略或伺服器端問題。
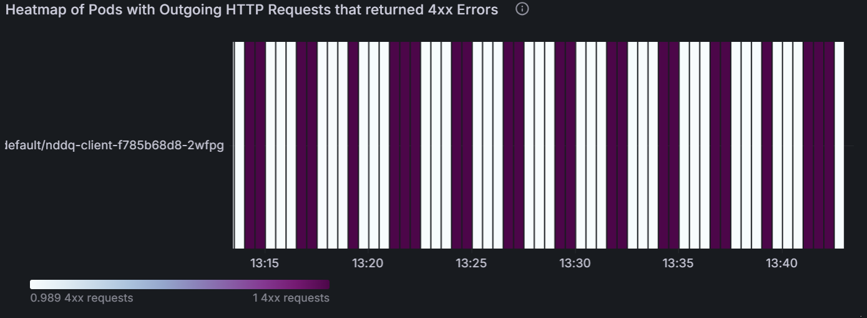
下列熱度圖指出哪些 Pod 有導致 4xx 錯誤的傳出 HTTP 要求。 您可使用此熱度圖來快速識別有問題的 Pod,並調查錯誤的原因。 藉由在 Pod 層級解決這些問題,您可以改善其 L7 流量的整體效能和可靠性。
使用下列圖表來檢查哪些 Pod 接收最多的流量。 這有助於識別過度負擔的 Pod。
- 預設中前10個來源Pod的外寄HTTP請求 顯示前十個來源Pod在一段時間內的外寄HTTP請求數量維持穩定。 該線幾乎保持平坦,表示穩定的流量並沒有明顯的高峰或下降。
- 預設前 10 名來源 Pod 的已卸除傳出 HTTP 要求熱度圖會使用色彩編碼來表示已卸除的要求數目。 較深的色彩表示卸除的要求數目較高,而較淺的色彩則表示較少或沒有卸除的要求。 交替的深色和淺色帶顯示了請求下降的週期性模式。
這些圖表可讓您深入瞭解其網路流量和效能。 第一個圖表可協助您瞭解其連出 HTTP 流量的一致性和數量,這對監視和維護最佳網路效能至關重要。 第二個圖表可讓您識別發生丟失请求問題時的模式或期間,這對於針對網路問題進行疑難解答或優化效能至關重要。





在 L7 流量的根本原因分析期間所要關注的重要因素
流量模式和數量:分析流量趨勢,以識別流量分佈中的激增、下降或不平衡。 多載節點或服務可能導致瓶頸或卸除的要求。
錯誤率:追蹤 4xx (無效請求) 和 5xx (後端失敗) 錯誤的趨勢。 持續性錯誤表示客戶端設定錯誤或伺服器端資源條件約束。
捨棄的要求:調查特定 Pod 或節點的捨棄。 卸除通常會示意連線問題或原則相關拒絕。
原則強制執行和設定:評估網路原則、服務探索機制,以及設定錯誤的負載平衡設定。
熱度圖和流量指標:使用像熱度圖這樣的視覺化工具來快速識別充滿錯誤的pod或流量異常。

使用容器網路記錄分析 L7 流量
容器網路記錄透過預存記錄和可視化儀錶板提供完整的 L7 流量分析功能。 使用下列 KQL 查詢來分析 HTTP、gRPC 和其他應用層流量:
// Analyze HTTP response codes and error rates
RetinaNetworkFlowLogs
| where TimeGenerated between (datetime(<start-time>) .. datetime(<end-time>))
| where FlowType == "L7_HTTP"
| extend HTTP = parse_json(Layer4).HTTP
| extend StatusCode = HTTP.status_code
| summarize RequestCount = count() by StatusCode, SourcePodName, bin(TimeGenerated, 5m)
| order by TimeGenerated desc
// Identify pods with high HTTP 4xx or 5xx error rates
RetinaNetworkFlowLogs
| where TimeGenerated between (datetime(<start-time>) .. datetime(<end-time>))
| where FlowType == "L7_HTTP"
| extend HTTP = parse_json(Layer4).HTTP
| extend StatusCode = tostring(HTTP.status_code)
| where StatusCode startswith "4" or StatusCode startswith "5"
| summarize ErrorCount = count(), UniqueErrors = dcount(StatusCode) by SourcePodName, DestinationPodName
| top 10 by ErrorCount desc
// Monitor gRPC traffic and response times
RetinaNetworkFlowLogs
| where TimeGenerated between (datetime(<start-time>) .. datetime(<end-time>))
| where FlowType == "L7_GRPC"
| extend GRPC = parse_json(Layer4).GRPC
| extend Method = GRPC.method
| summarize RequestCount = count() by SourcePodName, DestinationPodName, Method
| order by RequestCount desc
將 <start-time> 和 <end-time> 替換為格式 2025-08-12T00:00:00Z 中的想要時間範圍。
這些查詢藉由提供應用層效能、錯誤模式和跨微服務架構的流量分佈的詳細見解,來補充視覺儀錶板。
Azure 監視器隨附的網路可檢視性
當您在 AKS 叢集上啟用 Azure 監視器適用於 Prometheus 的受管理服務時,依預設會透過 networkobservabilityRetina 目標收集基本節點網路監視計量。 這提供下列項目:
- 基本節點層級網路指標:節點層級的基本網路流量可見度
- 預設 Prometheus 目標:Azure 監視器自動抓取的網路可檢視性計量
- Azure 監視器整合:與 Azure 監視器無縫整合;計量將會自動收集,且可在 Grafana 中視覺化
- 不需要其他設定:設定 Azure 監視器受控 Prometheus 時會自動啟用
- Microsoft 支援:作為 Azure 監視器和 AKS 的一部分進行支援
備註:這需要在 AKS 叢集上啟用適用於 Prometheus 的 Azure 監視器受控服務,這可能會產生相關的成本。
快速入門:透過 Azure 入口網站或 CLI 在 AKS 叢集上啟用 Azure 監視器適用於 Prometheus 的受管理服務。 系統會自動收集網路可檢視性計量,並可在 Azure 受控 Grafana 中進行視覺效果。
使用 Retina OSS 的網路可檢視性
雖然進階容器網路服務 (ACNS) 是提供全面網路可檢視性的付費產品,但 Microsoft 也支援使用 Retina OSS 進行網路可檢視性,這是一個提供基本網路監視功能的開放原始碼網路可檢視性平台。
Retina OSS 是可在 retina.sh 和 GitHub 上使用的開放原始碼可檢視性平台。 它提供:
- 基於 eBPF 的網路可觀察性:利用 eBPF 技術以最小開銷收集洞見
- 使用 Kubernetes 上下文進行深度流量分析:透過完整的 Kubernetes 整合全面捕獲和分析網路流量
- 進階指標收集:第 4 層計量、DNS 計量和分散式封包擷取功能
- 基於外掛程式的可擴展性:透過外掛程式架構自訂和擴展功能
- Prometheus 相容計量:使用 Prometheus 格式匯出全面的網路計量,並具有可配置的計量模式
- 分散式封包擷取:在多個節點上隨選封包擷取以便深入進行疑難排解
- 平台和 CNI 無關:適用於任何 Kubernetes 叢集 (AKS、已啟用 Arc、內部部署)、任何作業系統 (Linux/Windows) 和任何 CNI
- 社群支援:開放原始碼,社群導向的支援和貢獻
- 自我管理:完全控制部署和設定
- Hubble 整合:與 Cilium 的 Hubble 整合以獲得額外的網絡洞察
開始使用:使用官方 Retina 儲存庫中的 Helm 圖表或 Kubernetes 資訊清單部署 Retina OSS。 設定 Prometheus 和 Grafana 以將計量視覺化、使用 Kubernetes 內容設定深度流量分析、啟用分散式封包擷取進行進階疑難排解,以及使用外掛程式型架構自訂特定使用案例的功能。
網路可檢視性產品的比較
| Offering | Support | 費用 | Management | 部署 | 使用案例 |
|---|---|---|---|---|---|
| 進階容器網路服務 (ACNS) | Microsoft企業支援 | 付費 Azure 服務 | 完全由 Microsoft 管理 | 一鍵式 Azure 整合 | 託管企業可檢視性:Pod 級網絡流程、Pod 級計量、DNS 計量、永久儲存日誌、第 7 層流量分析、網絡安全性原則強制實施、合規性報告、進行 Grafana 儀表板、AI 支援的洞察 |
| 網路可檢視性 (Azure 監視器) | Microsoft 支援作為 Azure 監視器的一部分 | 包含 Azure 監視器受控 Prometheus (套用 Azure 監視器成本) | 完全由 Microsoft 管理 | 啟用 Azure 監視器受控 Prometheus 時為自動 | 節點網路監控:僅叢集和節點層級網路計量,沒有 Pod 層級可見度,沒有儲存的日誌,沒有 DNS 分析 - 適用於基本基礎設施監控和想要最低網路可檢視性的使用者,無需額外設定 |
| Retina OSS | 社群支援 | 免費和開放原始碼 | 自我管理 | 在任何 Kubernetes 叢集上透過 Helm/manifests 手動設定 | 非管理式進階可觀察性:即時封包擷取、自訂指標收集、基於 eBPF 的深度網路分析、哈伯整合、多雲部署、自訂可觀察性管線、透過 tcpdump/Wireshark 整合的進階除錯,以及開發/測試環境 |
深入了解
若要開始使用 AKS 中的網路可觀察性:
進階容器網路服務 (ACNS)
- 設定容器網路記錄:瞭解如何設定 容器網路記錄,以取得完整的網路可觀察性
- 探索進階容器網路服務:如需完整平臺的詳細資訊,請參閱 什麼是適用於 Azure Kubernetes Service 的進階容器網路服務 (AKS)?
- 設定監控:設定 Azure 受控 Grafana 整合以獲得進階視覺效果
- 了解網路安全性:探索用於原則強制執行和威脅偵測的容器網路安全性功能
網路可檢視性 (Azure 監視器)
- Azure 監視器整合:設定適用於容器的 Azure 監視器 以檢視基本網路計量
Retina OSS
- 官方文件:造訪 retina.sh 獲取全面的文件和指南
- GitHub 儲存庫:存取 Microsoft Retina GitHub 儲存庫以獲得安裝指南、範例和社群支援
- 社群支援:加入 Retina 社群討論尋求協助和最佳作法