在本指南中,我們會檢閱在 Azure Kubernetes Service(AKS) 上使用 Strimzi Operator 部署和操作高可用的 Apache Kafka 叢集的先決條件、架構考量和重要元件。
這很重要
整個 AKS 文件和範例都會提及開放原始碼的軟體。 您部署的軟體會從 AKS 服務等級協定、有限保固和 Azure 支援 中排除。 當您搭配 AKS 使用開放原始碼技術時,請參閱個別社群和專案維護人員所提供的支援選項,以開發計畫。
例如,Ray GitHub 存放 庫 描述數個因回應時間、用途和支援層級而異的平臺。
Microsoft負責建置我們在 AKS 上部署的開放原始碼套件。 該責任包括擁有組建、掃描、簽署、驗證和 Hotfix 程式的完整擁有權,以及控制容器映像中的二進位檔。 如需詳細資訊,請參閱 AKS 弱點管理和 AKS 支援涵蓋範圍。
什麼是 Strimzi?
Strimzi 是一個開放原始碼專案,可簡化 Kubernetes 上 Apache Kafka 的部署、管理和作業。 它提供一組 Kubernetes 運算子和容器映像,可透過宣告式設定將複雜的 Kafka 作業工作自動化。
Strimzi 運算子遵循 Kubernetes 運算符模式來自動化 Kafka 作業。 它會持續協調 Kafka 元件的宣告狀態與其實際狀態,並自動處理複雜的作業工作。
若要深入瞭解 Strimzi,請檢閱 Strimzi 檔。
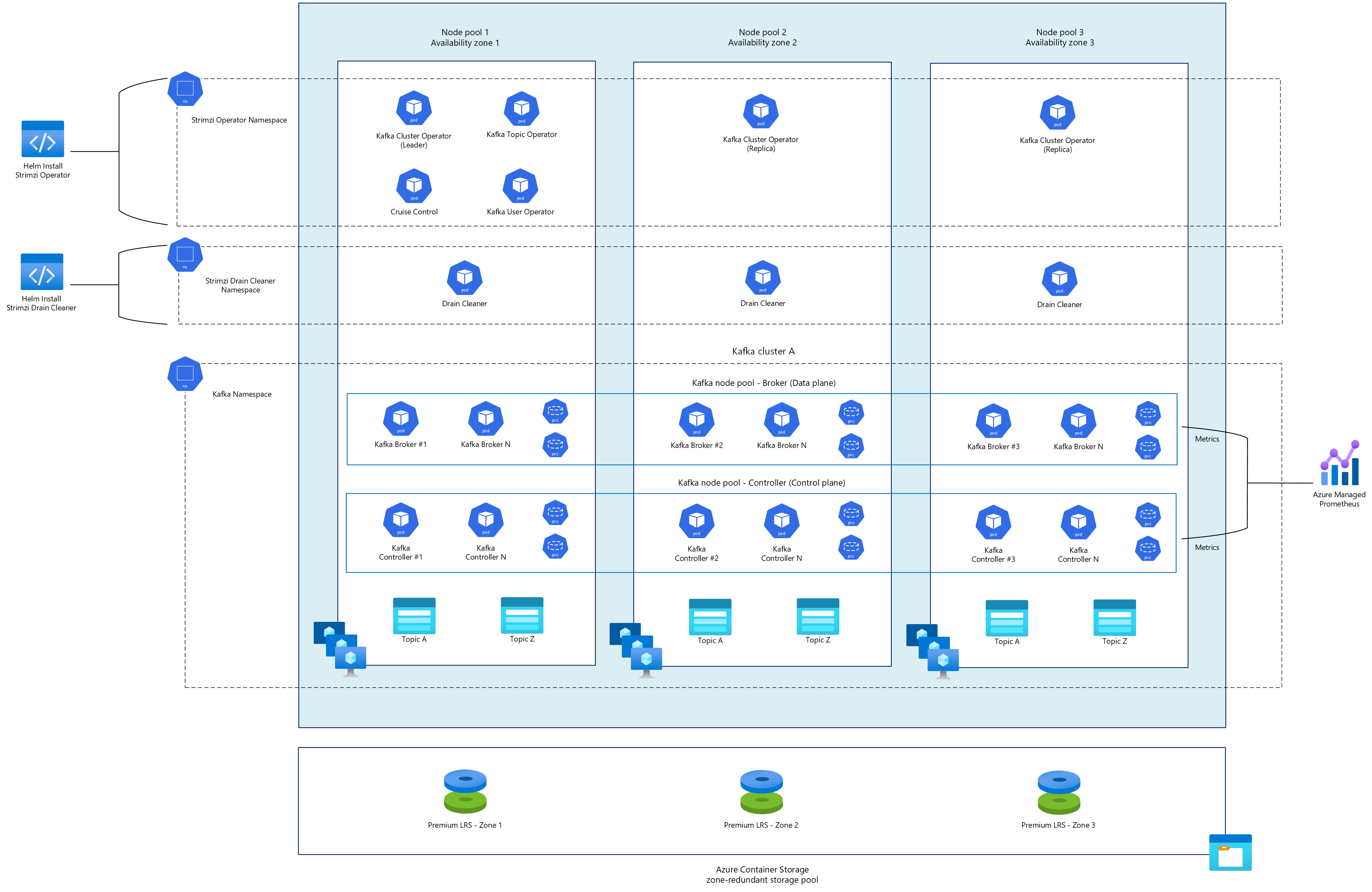
元件
Strimzi 叢集運算符
Strimzi 叢集作員是管理整個 Kafka 生態系統的中央元件。 部署時,它也可以配置實體操作員,其中包含:
- 主題作員:根據
KafkaTopic自定義資源自動建立、修改和刪除Kafka主題。 - 使用者作員:透過
KafkaUser自定義資源管理 Kafka 使用者及其存取控制清單(ACL)。
這些作員會一起建立一個完全宣告式管理系統,其中 Kafka 基礎結構會定義為 Kubernetes 資源,您可以跨環境進行版本控制、稽核及一致部署。
Kafka 叢集
Strimzi 叢集作員會透過特殊的自定義資源來管理 Kafka 叢集:
- KafkaNodePools:定義具有特定角色的 Kafka 節點群組(Broker、控制器或兩者)。
- Kafka:將所有項目系結在一起的主要自定義資源,定義全叢集組態。
KafkaNodePools 和 Kafka 的一般部署包括:
- 處理客戶端流量和數據儲存的專用 broker 節點。
- 管理叢集元數據和協調的專用控制器節點。
- 各可用性區域中分布著每個元件的多個複本。
巡航控制
Cruise Control 是進階元件,可提供 Kafka 叢集的自動化工作負載平衡和監視。 當部署為 Strimzi 受控 Kafka 叢集的一部分時,Cruise Control 提供:
- 自動分割區重新平衡:於代理之間重新分佈分割區,以優化資源使用率。
- 異常偵測:識別和警示異常叢集行為。
- 自我修復功能:自動解決常見的叢集不平衡問題。
- 工作負載分析:提供叢集效能和資源使用量的深入解析。
當工作負載隨著時間而變更時,Cruise Control 有助於維持最佳效能,減少調整事件或後續理程式失敗期間手動介入的需求。
排水管清潔劑
Strimzi Drain Cleaner 是一項公用程式,旨在協助管理 Strimzi 在 Kubernetes 節點清空期間所部署的 Kafka 代理程式 Pod。 Strimzi Drain Cleaner 會透過其許可 Webhook 來攔截 Kubernetes 節點清空作業,以協調 Kafka 叢集的正常維護。 對 Kafka 代理程式 Pod 提出收回要求時,會偵測到要求,而 Drain Cleaner 會標註 Pod,以通知 Strimzi Cluster Operator 處理重新啟動,確保 Kafka 叢集維持良好狀態。 此程式會在例行維護作業或非預期的節點失敗期間維護叢集健康情況和數據可靠性。
Kafka on AKS 的重要考量
Azure 容器存儲 (Azure Container Storage)
Azure Container Storage 是受控 Kubernetes 記憶體解決方案,可動態布建適用於 Kafka 等具狀態應用程式的永續性磁碟區。 根據OpenEBS開放原始碼專案,它提供專為容器化工作負載優化的企業級記憶體功能。
針對 Kafka 部署,Strimzi 會利用 一堆磁碟 (JBOD) 組態來管理數據持續性。 為了確保基礎設施故障時的高可用性,應配置 Azure 容器儲存的區域備援存放集,以便將基礎磁碟分散至所有可用性區域。 每個區域都會使用本地備援記憶體 (LRS) 搭配進階 SSD v2 磁碟。 因為 Kafka 提供應用程式層級的內建數據複寫,因此不需要 Zone-Redundant 記憶體 (ZRS)。 進階 SSD v2 可以透過優化的成本結構,提供 IO 密集 Kafka 工作負載所需的延遲、高 IOPS 和一致輸送量。
備註
不建議生產 Kafka 叢集使用暫時記憶體。 使用暫時記憶體時,訊息代理程式重新啟動會觸發整個叢集的完整數據復寫,這可能會影響效能和復原時間。
下表提供跨不同 Kafka 叢集大小的進階 SSD v2 磁碟組態起點:
| Kafka 叢集大小 | 磁碟大小 | IOPS | 帶寬 |
|---|---|---|---|
| 小型 (3-9 個代理程式) |
1 TB | 5,000 | 250 MB/秒 |
| 中度 (10-19 個代理程式) |
2 TB | 1萬 | 500 MB/s |
| 大型 (20+ 經紀人) |
4 TB | 20,000 | 1,000 MB/s |
實際的必要 IOPS、頻寬和磁碟大小會根據您的特定 Kafka 工作負載特性而有所不同。 隨著應用程式的輸送量和保留需求變更,這些屬性可能會隨著時間而演進。
節點集區
針對 AKS 上的 Kafka 部署選取適當的節點集區,是直接影響效能、可用性和成本效益的重要架構決策。 Kafka 工作負載具有獨特的資源使用率模式,其特點是高輸送量需求、記憶體 I/O 強度,以及在不同負載下需要一致的效能。 Kafka 通常比 CPU 密集型更耗用記憶體。 不過,CPU 需求可能會隨著訊息壓縮/解壓縮、SSL/TLS 加密,或具有許多小型訊息的高輸送量案例而大幅增加。
考慮到 Strimzi 的 Kubernetes 原生架構,其中每個 Kafka 代理節點都以獨立的 Pod 形式運行,您的 AKS 節點選擇策略應優化水平方向的擴展能力,而非單一節點的垂直擴展。 AKS 上的適當節點集區組態可確保有效率的資源使用率,同時維護 Kafka 元件必須可靠地運作的效能隔離。
Kafka 會使用 Java 虛擬機執行(JVM)。 調整 JVM 對於最佳 Kafka 效能至關重要,特別是在生產環境中。 LinkedIn,Kafka的創建者,分享了在Java上執行Kafka的典型理由,適用於LinkedIn其中一個最繁忙的叢集:Kafka Java組態。
針對本指南,6 GB 的記憶體堆積將會作為代理程式基準,另外配置 2 GB 以容納堆積外記憶體使用量。 針對控制器,3GB 記憶體堆積會作為基準使用,額外的 1GB 作為額外負荷。
為進行 Kafka 部署時的 VM 大小調整,請考慮下列與工作負載相關的特定因素:
| 工作負載因素 | 調整大小的影響 | 考慮事項 |
|---|---|---|
| 訊息輸送量 | 較高的輸送量需要更多CPU、記憶體和網路容量。 | - 監視每秒的位元組輸入/輸出。 - 請考慮尖峰與平均輸送量。 - 考慮未來的成長預測。 |
| 訊息大小 | 訊息大小調整會影響 CPU、網路和磁碟需求。 | - 小型訊息 (≤1KB) 比較依賴 CPU。 - 大型訊息 (>1MB) 較具有網路界限。 - 非常大的訊息可能需要專門調整。 |
| 保留期間 | 較長的保留期會增加記憶體需求。 | - 根據輸送量×保留量計算總記憶體需求。 |
| 取用者計數 | 更多取用者會增加 CPU 和網路負載。 | - 每個取用者群組都會增加額外負荷。 - 高展開模式需要額外的資源。 |
| 主題分區 | 分割區計數會影響記憶體使用率。 | - 每個分割區都會耗用記憶體資源。 - 過度分割可能會降低效能。 |
| 基礎結構額外負荷 | 其他系統元件會影響 Kafka 可用的資源。 | - Azure 容器記憶體每個節點至少需要 1 個 vCPU。 - 監視代理程式、記錄元件、網路原則和安全性工具會增加額外的額外負荷。 - 保留系統元件的額外負荷。 |
這很重要
下列建議僅做為起始指引。 最佳 VM SKU 選擇應針對特定的 Kafka 工作負載特性、數據模式和效能需求量身打造。 每個代理程式 Pod 估計有約 8GB 的保留記憶體。 每個控制器 Pod 估計都有 ~4 GB 的保留記憶體。 您的 JVM 和堆積記憶體需求可能較大或更小。
小型到中型 Kafka 叢集
| VM 產品規格 | vCPU | RAM | 網路 | 代理人密度 (估計) | 主要優點 |
|---|---|---|---|---|---|
| Standard_D8ds | 8 | 32 GB | 12,500 Mbps | 每個節點 1-3 | - 水平擴展符合成本效益,但隨著系統擴展可能需要更多節點。 |
| Standard_D16ds | 16 | 64 GB | 12,500 Mbps | 每個節點 3 到 6 個 | - 使用額外的 vCPU 和 RAM 提升資源使用效率,從而減少所需的 AKS 節點。 |
大型 Kafka 叢集
| VM 產品規格 | vCPU | RAM | 網路 | 代理人密度 (估計) | 主要優點 |
|---|---|---|---|---|---|
| Standard_E16ds | 16 | 128 GB | 12,500 Mbps | 每個節點 6+ | - 較佳的數據密集大型作業效能,且記憶體與核心比率較高。 支持較大的記憶體堆或更多的水平擴展。 |
在完成生產環境之前,建議您執行下列步驟:
- 使用具代表性的數據磁碟區和模式執行負載測試。
- 監視尖峰負載期間的CPU、記憶體、磁碟和網路使用率。
- 根據觀察到的瓶頸調整 AKS 節點集區 SKU。
- 檢閱節點集區 SKU 的成本
高可用性和復原能力
為了確保 Kafka 部署的高可用性:
- 跨多個可用性區域部署。
- 設定適當的副本分配條件約束。
- 實作適當的 Pod 中斷預算。
- 設定 Cruise Control 以進行主題分區重新平衡。
- 使用 Strimzi 清空清除器來處理節點清空和維護作業。
監視和作業
有效監視 Kafka 叢集包括:
- JMX 計量集合組態。
- 使用 Kafka 匯出工具的取用者延隔監視。
- 與 Azure 受控 Prometheus 和 Azure 受控 Grafana 整合。
- 針對關鍵效能指標和健康情況計量發出警示。
在 AKS 上使用 Kafka 的時機
若以下情況成立,請考慮執行 Kafka on AKS:
- 您需要完全控制 Kafka 設定和作業。
- 您的使用案例需要受控供應項目中無法使用的特定 Kafka 功能。
- 您要整合 Kafka 與其他在 AKS 上執行的容器化應用程式。
- 您必須部署在無法使用受控 Kafka 服務的區域。
- 您的組織具有 Kubernetes 和容器協調流程的現有專業知識。
對於較簡單的使用案例,或當作業負擔是個考量時,可以考慮使用完全托管的服務,例如 Azure 事件中樞。
後續步驟
貢獻者們
本文由 Microsoft 維護。 原始撰寫此內容的貢獻者如下:
- 塞爾吉奧·納瓦爾 |資深客戶工程師
- Erin Schaffer |內容開發人員 2
