在本教學課程中,您將使用 Express.js、Azure OpenAI 和 Azure AI 搜尋來建立 Node.js 擷取擴增世代 (RAG) 應用程式,並將其部署至 Azure App Service。 此應用程式示範如何實作聊天介面,以從您自己的文件中擷取資訊,並利用 Azure AI 服務,以適當的引文提供精確且具內容語境的答案。 解決方案會使用受控識別進行服務之間的無密碼驗證。
在本教學課程中,您將瞭解如何:
- 部署使用 RAG 模式並搭配 Azure AI 服務的 Express.js 應用程式。
- 設定 Azure OpenAI 和 Azure AI 搜尋以進行混合式搜尋。
- 上傳檔並編製索引,以用於 AI 支援的應用程式中。
- 使用受控識別來保護服務對服務通訊。
- 使用生產服務在本機測試您的RAG實作。
架構概觀
在開始部署之前,了解您將建置的應用程式架構是很有幫助的。 下圖來自 Azure AI 搜尋的自訂 RAG 模式:
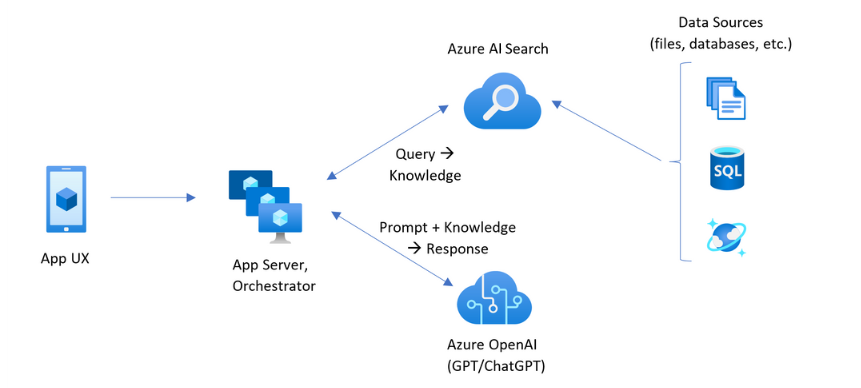
在本教學課程中,App Service 中的 Blazer 應用程式會同時處理應用程式 UX 和應用程式伺服器。 不過,它不會對 Azure AI 搜尋進行個別的知識查詢。 相反地,它會告訴 Azure OpenAI 執行將 Azure AI 搜尋指定為數據源的知識查詢。 此架構提供數個主要優點:
- 整合向量化:Azure AI 搜尋的整合向量化功能可讓您輕鬆且快速地擷取所有文件進行搜尋,而不需要更多程式代碼來產生內嵌。
- 簡化的 API 存取:使用 Azure OpenAI On Your Data 模式搭配 Azure AI 搜尋作為 Azure OpenAI 完成的數據源,就不需要實作複雜的向量搜尋或內嵌產生。 這隻是一個 API 呼叫,Azure OpenAI 會處理所有專案,包括提示工程和查詢優化。
- 進階搜尋功能:整合式向量化提供進階混合式搜尋與語意重新調整所需的一切,結合關鍵詞比對、向量相似度和 AI 支援排名的優點。
- 完整的引文支援:回應會自動包含源檔的引文,使資訊可驗證和可追蹤。
先決條件
- 具有使用中訂閱的 Azure 帳戶 - 免費建立帳戶。
- GitHub 帳戶用於使用 GitHub Codespaces - 進一步了解 GitHub Codespaces。
1.使用 Codespaces 開啟範例
最簡單的開始使用方式是使用 GitHub Codespaces,其提供預安裝所有必要的工具的完整開發環境。
流覽至 位於 https://github.com/Azure-Samples/app-service-rag-openai-ai-search-nodejs的 GitHub 存放庫。
選取 [ 程序代碼] 按鈕,選取 [ Codespaces] 索引 標籤,然後按兩下 main 上的 [建立程式碼空間]。
請稍候片刻,讓 Codespace 初始化。 準備好時,您會在瀏覽器中看到完整設定的 VS Code 環境。
2.部署範例架構
在終端機中,使用 Azure 開發人員 CLI 登入 Azure:
azd auth login請遵循指示來完成驗證程式。
使用 AZD 範本布建 Azure 資源:
azd provision出現提示時,請提供下列答案:
問題 回答 輸入新的環境名稱: 輸入唯一名稱。 選取要使用的 Azure 訂用帳戶: 選取訂用帳戶。 挑選要使用的資源群組: 選取 [建立新的資源群組]。 選取要用來建立資源群組的位置: 選取任何區域。 資源實際上將會在美國 東部 2 中建立。 輸入新資源群組的名稱: 輸入 Enter。 等候部署完成。 此過程將:
- 建立所有必要的 Azure 資源。
- 將 Blazor 應用程式部署至 Azure App Service。
- 使用受管理的身份設定安全的服務間驗證。
- 設定必要的角色分配,以在服務之間安全存取。
備註
若要深入瞭解受控識別的運作方式,請參閱 什麼是適用於 Azure 資源的受控識別? 以及如何 搭配 App Service 使用受控識別。
成功部署之後,您會看到已部署應用程式的URL。 請記下此 URL,但尚未存取它,因為您仍然需要設定搜尋索引。
3.上傳檔並建立搜尋索引
現在已部署基礎結構,您必須上傳檔,並建立應用程式將使用的搜尋索引:
在 Azure 入口網站中,流覽至部署所建立的記憶體帳戶。 名稱會以您稍早提供的環境名稱開頭。
從左側導覽功能表中選取 [容器 ],然後開啟 檔 容器。
按兩下 [上傳] 來 上傳範例檔。 您可以使用存放
sample-docs庫中資料夾中的範例檔,或您自己的 PDF、Word 或文字檔。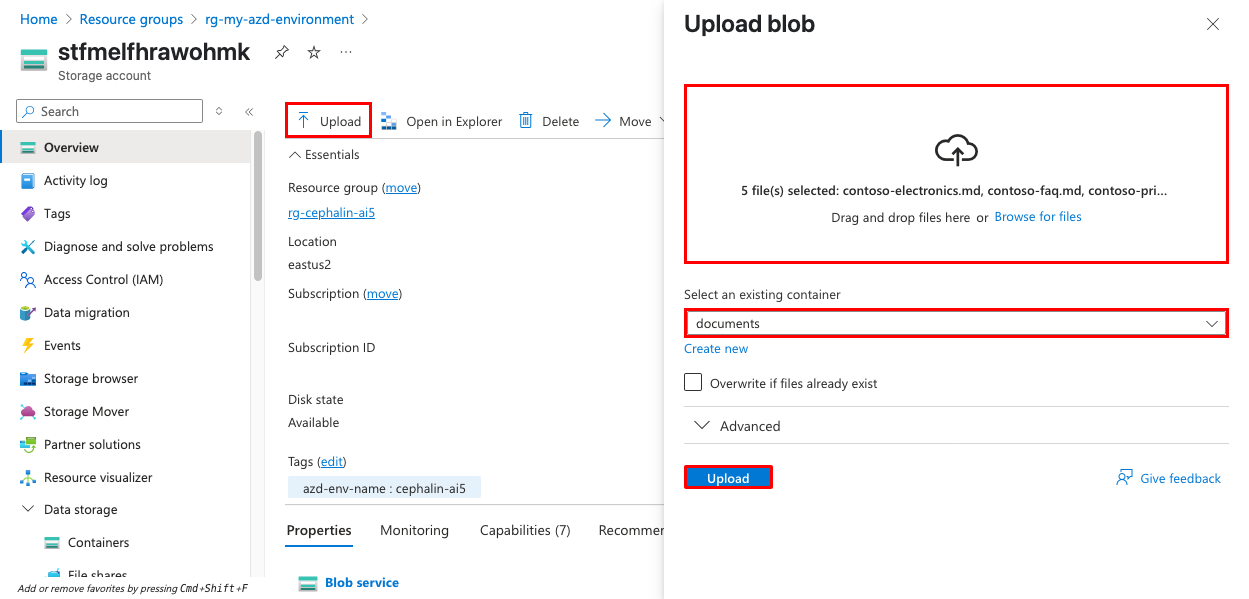
在 Azure 入口網站中瀏覽至您的 Azure AI 搜尋服務。
選取 [匯入並向量化數據 ] 以開始建立搜尋索引的程式。
![顯示 Azure AI 搜尋中 [匯入和向量化數據] 按鈕的螢幕快照。](media/tutorial-ai-openai-search-dotnet/ai-search-import-vectorize.png)
在 [ 連線到您的資料 ] 步驟中:
- 選取 [Azure Blob 記憶體 ] 作為 [數據源]。
- 選取 RAG。
- 選擇您的記憶體帳戶和 檔案 容器。
- 確定已選取 [ 使用受控識別進行驗證 ]。
- 選取 下一步。
在 向量化您的文字 步驟中:
- 選取您的 Azure OpenAI 服務。
- 選擇 text-embedding-ada-002 作為內嵌模型。 AZD 樣本已為您部署此模型。
- 選取 [系統指派的身分 識別以進行驗證]。
- 核取 [通知] 複選框以取得額外的成本。
- 選取 下一步。
小提示
深入瞭解 Azure AI 搜尋中的向量搜尋 和 Azure OpenAI 中的文字內嵌。
在 向量化和影像增強 步驟中:
- 保留預設設定。
- 選取 下一步。
在 [ 進階設定] 步驟中:
- 確定已選取 [啟用語意排名器 ]。
- (選擇性)選取索引排程。 如果您想要定期使用最新的檔案變更來重新整理索引,這會很有用。
- 選取 下一步。
在檢視和建立步驟中:
- 複製 物件名稱前置詞的值。 這是您的搜尋索引名稱。
- 選取 [建立] 以開始編製索引程式。
等候索引編製程式完成。 視您的檔案大小和數目而定,這可能需要幾分鐘的時間。
若要測試數據匯入,請選取 [開始搜尋 ],然後嘗試搜尋查詢,例如 「告訴我您的公司」。
回到 Codespace 終端機,將搜尋索引名稱設定為 AZD 環境變數:
azd env set SEARCH_INDEX_NAME <your-search-index-name>將
<your-search-index-name>替換為您先前複製的索引名稱。 AZD 會在後續部署中使用這個變數來設定 App Service 應用程式設定。
4.測試應用程式並部署
如果您想要在部署前後於本機測試應用程式,您可以直接從 Codespace 執行它:
在您的 Codespace 終端機中,取得 AZD 環境值:
azd env get-values開啟 .env。 使用終端機輸出,在各自的佔位元
<input-manually-for-local-testing>中更新下列值:AZURE_OPENAI_ENDPOINTAZURE_SEARCH_SERVICE_URLAZURE_SEARCH_INDEX_NAME
使用 Azure CLI 登入 Azure:
az login這可讓範例程式代碼中的 Azure 身分識別客戶端連結庫接收已登入使用者的驗證令牌。
在本機執行應用程式:
npm run dev當您看到 在埠 8080 上執行的應用程式可用時,請選取 [在瀏覽器中開啟]。
請嘗試在聊天介面中詢問幾個問題。 如果您收到回應,您的應用程式會成功連線到 Azure OpenAI 資源。
使用 Ctrl+C 停止開發伺服器。
在 Azure 中套用新的
SEARCH_INDEX_NAME組態,並部署範例應用程式程式代碼:azd up
5.測試已部署的RAG應用程式
在應用程式完全部署和設定後,您現在可以測試RAG功能:
開啟部署結束時提供的應用程式 URL。
您會看到聊天介面,您可以在其中輸入所上傳檔內容的相關問題。
請嘗試詢問文件內容特有的問題。 例如,如果您在 sample-docs 資料夾中上傳了檔案,您可以嘗試下列問題:
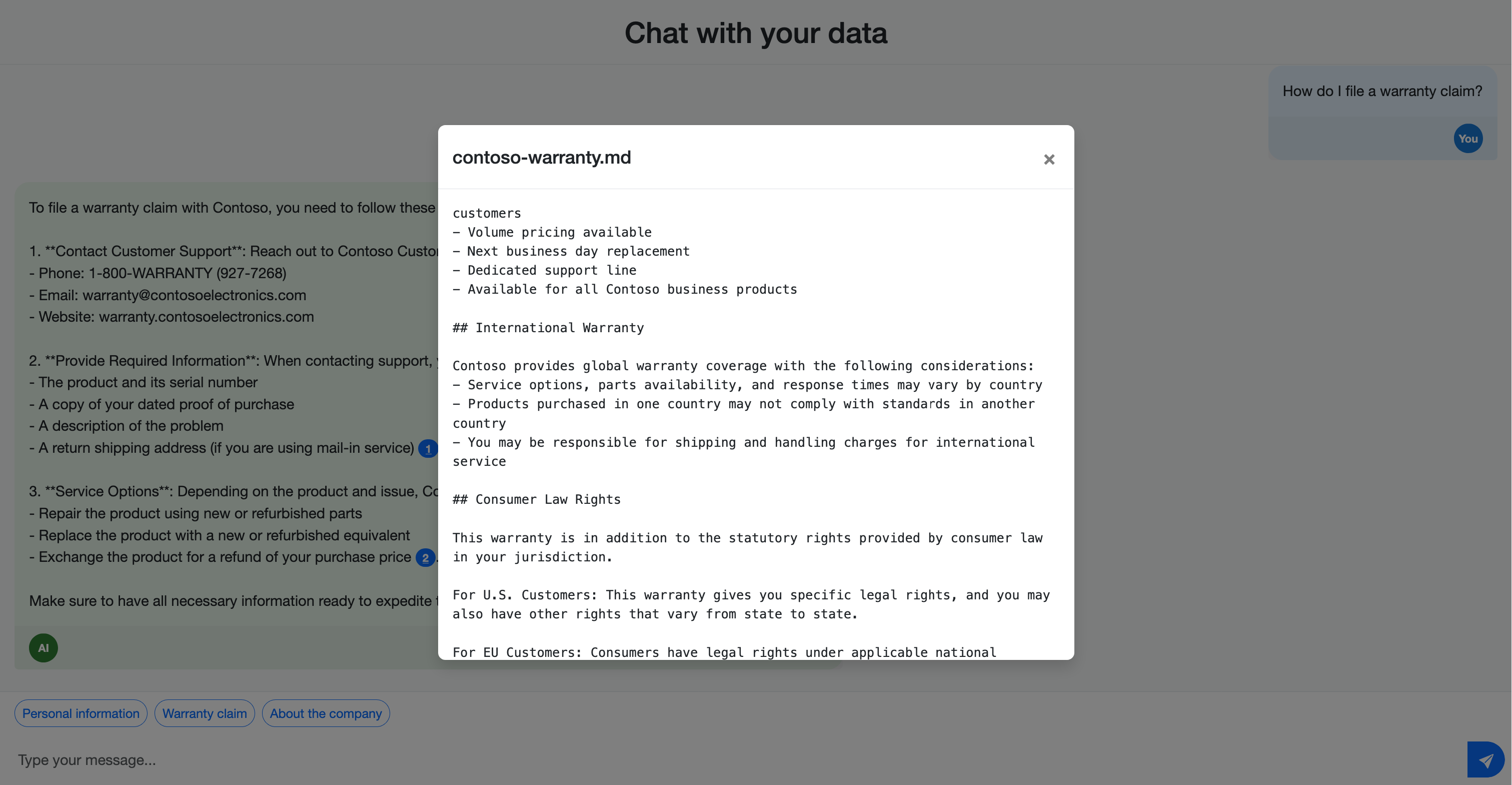
- Contoso 如何使用我的個人資料?
- 您要如何提出保固索賠?
請注意回應如何包含參考源檔的引文。 這些引文可協助使用者驗證資訊的正確性,並在來源數據中尋找更多詳細數據。
藉由詢問可能受益於不同搜尋方法的問題來測試混合式搜尋功能:
- 特定術語的問題(適用於關鍵詞搜尋)。
- 使用不同詞彙來描述的概念相關問題(適用於向量搜尋)。
- 需要了解內容的複雜問題(適用於語意排名)。
清理資源
使用應用程式完成時,您可以刪除所有資源,以避免產生進一步的成本:
azd down --purge
此命令會刪除與應用程式相關聯的所有資源。
常見問題
- 範例程式代碼如何從 Azure OpenAI 聊天完成擷取引文?
- 在此解決方案中使用受控識別有何優點?
- 此架構和範例應用程式中如何使用系統指派的受控識別?
- 混合式搜尋如何在範例應用程式中實作語意排名器?
- 為什麼所有資源都建立在美國東部 2?
- 我可以使用自己的 OpenAI 模型,而不是 Azure 所提供的模型嗎?
- 如何改善響應品質?
範例程式代碼如何從 Azure OpenAI 聊天完成擷取引文?
此範例藉由在聊天用戶端中使用 data_source 搭配 type: "azure_search" 來擷取引文。 要求聊天完成時,回應會包含一個 citations 物件在訊息內容中。 程序代碼會擷取這些引文,如下所示:
const message = choice.message;
const content = message.content;
const citations = message.context?.citations || [];
在聊天回應中,內容會使用 [doc#] 表示法來參考清單中的對應引文,讓使用者追蹤資訊回到原始源檔。 如需詳細資訊,請參閱:
在此解決方案中使用受控識別有何優點?
受控識別不需要在程式代碼或組態中儲存認證。 藉由使用受控識別,應用程式可以安全地存取 Azure OpenAI 和 Azure AI 搜尋等 Azure 服務,而不需管理秘密。 此方法遵循零信任安全性準則,並降低認證暴露的風險。
此架構和範例應用程式中如何使用系統指派的受控識別?
AZD 部署會為 Azure App Service、Azure OpenAI 和 Azure AI 搜尋建立系統指派的受控識別。 它也會分別為每個角色指派角色(請參閱main.bicep檔案)。 如需必要角色指派的相關信息,請參閱 Azure OpenAI On Your Data 的網路和存取設定。
在範例 Express.js 應用程式中,Azure SDK 會使用此受控識別進行安全驗證,因此您不需要在任何地方儲存認證或秘密。 例如, AzureOpenAI 會使用 DefaultAzureCredential初始化 ,其會在 Azure 中執行時自動使用受控識別:
const scope = "https://cognitiveservices.azure.com/.default";
const azureADTokenProvider = getBearerTokenProvider(new DefaultAzureCredential(), scope);
// Initialize Azure OpenAI client with managed identity
this.openAIClient = new AzureOpenAI({
azureADTokenProvider,
apiVersion: "2024-02-01", // Update this to a known working API version
endpoint: this.config.openai.endpoint
});
同樣地,設定 Azure AI 搜尋的數據源時,會指定受控識別以進行驗證:
const searchDataSource = {
type: 'azure_search',
parameters: {
// ...
authentication: {
type: 'system_assigned_managed_identity'
},
// ...
}
};
此設定可讓您 Express.js 應用程式和 Azure 服務之間的安全無密碼通訊,並遵循零信任安全性的最佳做法。 深入瞭解 DefaultAzureCredential 和 適用於 JavaScript 的 Azure 身分識別客戶端連結庫。
混合式搜尋如何在範例應用程式中實現語意排名?
範例應用程式會使用 Azure OpenAI SDK 設定具有語意排名的混合式搜尋。 在後端中,數據源會設定如下:
const searchDataSource = {
type: 'azure_search',
parameters: {
// ...
query_type: 'vector_semantic_hybrid',
semantic_configuration: `${this.config.search.index.name}-semantic-configuration`,
embedding_dependency: {
type: 'deployment_name',
deployment_name: this.config.openai.embedding.deployment
}
}
};
此組態可讓應用程式在單一查詢中結合向量搜尋(語意相似性)、關鍵詞比對和語意排名。 語意排名器會重新排序結果,以傳回最相關且內容相關的適當答案,然後由 Azure OpenAI 用來產生回應。
語意組態名稱是由整合式向量化程序自動定義。 它會使用搜尋索引名稱作為前置詞,並將 附加 -semantic-configuration 為後綴。 這可確保語意組態與對應的索引唯一相關聯,並遵循一致的命名慣例。
為什麼所有資源都是在美國東部 2 建立的?
此範例使用 gpt-4o-mini 和 text-embedding-ada-002 模型,這兩種模型都適用於美國東部 2 的標準部署類型。 這些模型之所以被選擇,是因為它們不會在近期退役,為範例部署提供穩定性。 模型的可用性和部署類型可能會因區域而異,因此選擇東美 2 以確保範例可以立即使用。 如果您想要使用不同的區域或模型,請務必選取適用於相同區域中相同部署類型的模型。 選擇您自己的模型時,請檢查其可用性和淘汰日期,以避免中斷。
- 模型可用性: Azure OpenAI 服務模型
- 模型淘汰日期: Azure OpenAI 服務模型被棄用和停止使用。
我可以使用自己的 OpenAI 模型,而不是 Azure 所提供的模型嗎?
此解決方案的設計目的是要與 Azure OpenAI 服務搭配使用。 雖然您可以修改程式代碼以使用其他 OpenAI 模型,但您將失去整合式安全性功能、受控識別支援,以及此解決方案所提供的 Azure AI 搜尋無縫整合。
如何改善響應品質?
您可以透過以下方法來改善回應的品質:
- 上傳高品質、更相關的檔。
- 調整 Azure AI 搜尋服務索引管線中的區塊化策略。 不過,您無法使用這個教學課程中所顯示的整合向量化來自訂區塊化。
- 在應用程式程式代碼中試驗不同的提示範本。
- 使用數據源中的其他
type: "azure_search屬性微調搜尋。 - 針對特定網域使用更特製化的 Azure OpenAI 模型。