自定義模型:精確度和信賴分數
此內容適用於:![]() v4.0 (預覽)
v4.0 (預覽)![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
注意
- 自訂類神經模型不會在定型期間提供精確度分數。
- 從 2024-02-02-29-preview API 版本開始,即可取得數據表、數據表數據列和數據表單元格的信賴分數。
自定義範本模型會在定型時產生估計的正確性分數。 使用自訂模型分析的文件會產生已擷取欄位的信賴度分數。 在本文中了解如何解譯正確性和信賴度分數,以及使用這些分數來改善正確性和信賴度結果的最佳做法。
精確度分數
build (v3.0) 或 train (v2.1) 自訂模型作業的輸出包含估計的精確度分數。 此分數代表模型在視覺上類似文件上正確預測標記值的能力。
精確度值範圍是介於 0% (低) 和 100% (高) 之間的百分比。 預估精確度的計算方式是執行一些不同定型資料組合來預測標記的值。
Document Intelligence Studio
定型自定義模型 (發票)
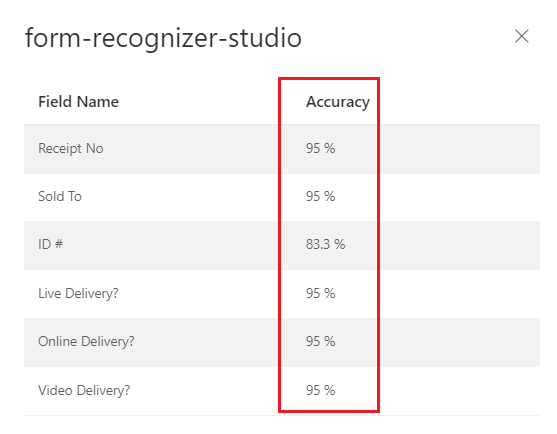
信賴分數
注意
- 數據表、數據列和儲存格信賴分數現在隨附於 2024-02-29-preview API 版本。
- 從 2024-02-29-preview API 開始,自定義模型的數據表數據格信賴分數會新增至 API。
Document Intelligence 分析結果會傳回預測字組、索引鍵/值組、選取標記、區域和簽章的估計信賴度。 目前,並非所有文件欄位都會傳回信賴分數。
欄位信賴度表示預測正確 0 到 1 之間的估計可能性。 例如,信賴值 0.95 (95%) 表示 20 次的預測中可能有 19 次正確。 對於精確度至關重要的案例,信賴度可用來判斷是否要自動接受預測,或將其標幟為人工檢閱。
Document Intelligence Studio
已分析發票預先建置的發票模型
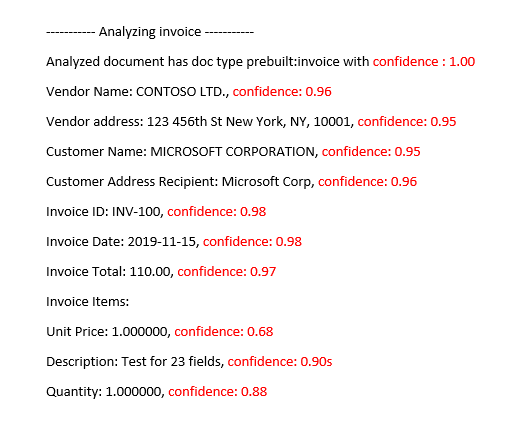
解譯自定義模型的精確度和信賴分數
從自定義模型解譯信賴分數時,您應該考慮從模型傳回的所有信賴分數。 讓我們從所有信賴分數的清單開始。
- 檔類型信賴分數:檔類型信賴度是類似定型數據集中檔之仔細分析檔的指標。 當檔類型信賴度很低時,它會指出分析檔中的範本或結構變化。 若要改善檔類型信賴度,請將具有該特定變化的檔加上標籤,並將其新增至您的定型數據集。 重新定型模型之後,應該更適合處理該類別的變化。
- 欄位層級信賴:每個已擷取的已標記欄位都有相關聯的信賴分數。 此分數會反映模型對所擷取值位置的信心。 評估信賴分數時,您也應該查看基礎擷取信賴度,以產生擷取結果的完整信賴度。
OCR根據欄位類型來評估文字擷取或選取標記的結果,以產生欄位的複合信賴分數。 - 文字信賴分數 檔內擷取的每個字都有相關聯的信賴分數。 分數代表轉譯的信賴度。 pages 陣列包含單字數位列,而且每個單字都有相關聯的範圍和信賴分數。 從自定義欄位擷取的值範圍符合所擷取字組範圍。
- 選取標記信賴分數:頁面陣列也包含選取標記的陣列。 每個選取標記都有一個信賴分數,代表選取標記和選取狀態偵測的信賴度。 當標示的欄位具有選取標記時,結合選取範圍標記信賴的自定義欄位選取範圍是整體信賴精確度的準確表示法。
下表示範如何解譯精確度和信賴分數,以測量自訂模型的效能。
| 準確率 | 信賴度 | 結果 |
|---|---|---|
| 高 | 高 | • 此模型使用加上標籤的索引鍵和檔案格式執行良好。 • 您有平衡的定型數據集。 |
| 高 | 低 | • 分析的文件與定型數據集不同。 • 模型可受益於使用至少五份已加上標籤的文件進行重新定型。 • 這些結果也可能表示定型數據集與分析檔之間的格式變化。 請考慮新增模型。 |
| 低 | 高 | • 此結果不太可能。 • 針對低精確度分數,請新增更多標記的數據,或將視覺上不同的檔分割成多個模型。 |
| 低 | 低 | • 新增更多已標記的數據。 • 將視覺上不同的檔分割成多個模型。 |
數據表、數據列和儲存格信賴度
使用 API 新增數據表、數據列和儲存格信賴 2024-02-29-preview 度,以下是一些常見問題,有助於解譯數據表、數據列和儲存格分數:
問: 是否可以看到儲存格的高信賴分數,但數據列的信賴分數較低?
A: 可以。 不同的數據表信賴等級(儲存格、數據列和數據表)是用來擷取該特定層級預測的正確性。 正確預測的儲存格屬於具有其他可能遺漏的數據列會有較高的數據格信賴度,但數據列的信賴度應該很低。 同樣地,具有其他數據列挑戰之數據表中的正確數據列會有較高的數據列信賴度,而數據表的整體信賴度會很低。
問: 合併儲存格時預期的信賴分數為何? 由於合併會導致識別為變更的數據行數目,因此分數會如何影響?
答: 不論數據表類型為何,合併儲存格的期望值都應該較低。 此外,遺漏的單元格(因為它與相鄰單元格合併)也應該具有 NULL 較低的信賴度值。 這些值可能要低多少取決於定型數據集,合併和遺漏數據格具有較低分數的一般趨勢應該保留。
問: 當值為選擇性時,信賴分數為何? 如果遺漏值,您應該預期具有 NULL 值且信賴分數較高的單元格?
答: 如果您的定型數據集代表單元格的選擇性,它可協助模型知道值在定型集中出現的頻率,以及推斷期間預期的情況。 計算預測或完全不進行預測的信賴度時,會使用這項功能。NULL 對於定型集中大部分空白值的遺漏值,您應該預期有高度信賴的空白字段。
問: 如果欄位是選擇性且不存在或遺漏的,信賴分數會如何受到影響? 信賴分數是否可回答這個問題?
答: 當數據列遺漏值時,單元格會 NULL 指派值和信賴度。 此處的高信賴分數應該表示模型預測(沒有值)更有可能正確。 相反地,低分應該會發出模型更多的不確定性(因此錯誤的可能性,例如遺漏的值)。
問: 在擷取具有跨頁面分割數據列的多頁數據表時,數據格信賴度和數據列信賴的預期為何?
答: 預期儲存格信賴度會很高,且數據列信賴度可能低於未分割的數據列。 定型數據集中分割數據列的比例可能會影響信賴分數。 一般而言,分割數據列看起來與數據表中的其他數據列不同(因此,模型不太確定正確)。
問: 對於具有清楚結束且從頁面界限開始之數據列的跨頁面數據表,假設信賴分數在頁面之間是否一致是正確的?
A: 可以。 由於數據列在圖形和內容中看起來類似,無論它們位於檔的位置(或哪一頁),其各自的信賴分數應該一致。
問: 使用新信賴分數的最佳方式為何?
答: 查看從上到下方法開始的所有數據表信賴層級:從檢查數據表的整體信賴度開始,然後向下切入至數據列層級並查看個別數據列,最後查看數據格層級的信賴度。 根據數據表的類型,有幾個注意事項:
對於 固定數據表,數據格層級信賴度已經擷取了相當多的資訊,以取得事物的正確性。 這表示只要逐一查看每個數據格並查看其信心就足以協助判斷預測的品質。 對於 動態數據表,層級的目的是要彼此建置,因此從上到下的方法更為重要。
確保高模型的精確度
模型的正確性會受到文件視覺結構變異數的影響。 當分析的文件與定型時使用的文件不同時,回報的精確度分數可能會不一致。 請注意,文件組在人員檢視時可能看起來相似,但以 AI 模型檢視時會不同。 下方是最佳做法清單,可用來以最高正確性定型模型。 遵循這些指導方針應該會在分析期間產生具有較高精確度和信賴分數的模型,並減少加上人工檢閱旗標的文件數目。
確定文件的所有變化都包含在訓練資料集中。 變化包含不同的格式,例如數位與掃描的 PDF。
如果您預期模型分析這兩種類型的 PDF 檔,請將每個類型的至少五個樣本新增至定型數據集。
以視覺方式區分不同的文件類型,以定型不同的模型。
- 作為一般規則,如果移除所有使用者輸入的值且文件看起來相似,則您必須將多個定型資料新增至現有的模型。
- 如果文件不同,請將訓練資料分割成不同的資料夾,並針對每個變化定型模型。 您接著可以將不同的變化組合成單一模型。
請確定您沒有任何多餘的標籤。
請確定簽章和區域標籤不包含周圍的文字。