檔智慧自定義模型
重要
- Document Intelligence 公開預覽版本提供早期存取作用中開發的功能。
- 根據使用者意見反應,功能、方法和流程在正式發行 (GA) 前可能有所變更。
- Document Intelligence 用戶端連結庫的公開預覽版本預設為 REST API 版本 2024-02-29-preview。
- 公開預覽版本 2024-02-29-preview 目前僅適用於下列 Azure 區域:
- 美國東部
- 美國西部 2
- 西歐
此內容適用於:![]() v4.0 (預覽) | 舊版:
v4.0 (預覽) | 舊版:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
此內容適用於:![]() v2.1 | 最新版本:
v2.1 | 最新版本:![]() v4.0(預覽)
v4.0(預覽)
檔智慧使用進階機器學習技術來識別檔、偵測及擷取表單和文件的資訊,並在結構化 JSON 輸出中傳回擷取的數據。 透過文件智慧,您可以使用檔分析模型、預先建置/預先定型,或已定型的獨立自定義模型。
自定義模型現在包含 自定義分類模型 ,適用於您需要在叫用擷取模型之前識別檔類型的案例。 分類器模型可從 2023-07-31 (GA) API 開始使用。 分類模型可以與自訂擷取模型配對,以分析及擷取您企業專屬的表單和文件中的欄位,以建立文件處理解決方案。 您可以結合獨立自訂擷取模型來建立組成模型。
自訂文件模型類型
自訂文件模型可以是兩種類型之一:自訂範本或自訂表單,以及自訂神經或自訂文件模型。 這兩個模型的標籤和定型程序都相同,但模型不同,如下所示:
自訂擷取模型
若要建立自訂擷取模型,您可以使用所要擷取的值來標記文件的資料集,並針對加上標籤的資料集定型模型。 您只需要五個相同表單或文件類型的範例,即可開始使用。
自訂神經模型
重要
從 4.0 版 — 2024-02-29-preview API 開始,自定義類神經模型現在支援 重疊的欄位 和 數據表、數據列和單元格層級信賴度。
自訂神經 (自訂文件) 模型會使用深度學習模型,以及在大型文件集合上定型的基礎模型。 當您使用已加上標籤的資料集來定型模型時,此模型接著會經過微調或調整為符合您的資料。 自訂神經模型支援結構化、半結構化和非結構化文件,以擷取欄位。 自訂神經模型目前支援英文文件。 當您選擇這兩種模型類型時,請從神經網路開始,以判斷其是否符合您的功能需求。 若要深入瞭解自訂文件模型,請參閱神經模型。
自訂範本模型
自訂範本或自訂表單模型依賴一致的視覺化範本來擷取標記的資料。 模型的正確性會受到文件視覺結構變異數的影響。 問卷或申請表等結構化表格是一致的視覺範本範例。
您的定型集會包含結構化文件,其中格式設定和版面配置是靜態的,且在文件實例之間都是不變的。 自訂範本模型支援索引鍵/值組、選取標記、資料表、簽章欄位和區域。 範本模型,可以在任何支援語言的文件上定型。 如需詳細資訊,請參閱自訂範本模型。
如果您的檔和擷取案例的語言支援自定義類神經網路模型,建議您透過範本模型使用自定義神經模型,以取得更高的精確度。
提示
若要確認您的定型文件呈現一致的視覺化範本,請將所有使用者輸入的資料從集合中的每個表單中移除。 如果空白表單在外觀上相同,則其代表一致的視覺化範本。
如需詳細資訊,請參閱解譯並改善自訂模型的正確性和信賴度。
輸入需求
若要得到最佳結果,請為每個文件提供一張清晰的照片或高畫質的掃描檔案。
支援的檔案格式:
模型 PDF 圖片:
jpeg/jpg、png、bmp、tiff、heifMicrosoft Office:
Word(docx)、Excel(xlsx)、PowerPoint(pptx)參閱 ✔ ✔ ✔ 版面配置 ✔ ✔ ✔ (2024-02-29-preview、 2023-10-31-preview 及更新版本) 一般文件 ✔ ✔ 預建 ✔ ✔ 自訂擷取 ✔ ✔ 自訂分類 ✔ ✔ ✔ ✱ Microsoft Office 檔案目前不支援其他模型或版本。
針對 PDF 和 TIFF,最多可以處理 2,000 個頁面(使用免費層訂用帳戶,只會處理前兩個頁面)。
用於分析文件的檔案大小是付費 (S0) 層的 500 MB,免費 #F0 層為 4 MB。
影像維度必須介於 50 x 50 像素和 10,000 x 10,000 像素之間。
如果您的 PDF 有密碼鎖定,則必須先移除鎖定才能提交。
針對 1024 x 768 像素影像的擷取文字高度下限為 12 像素。 此維度對應至每英吋 150 個點的大約
8點文字。針對自訂模型定型,自訂範本模型的定型資料頁數上限為 500,而自訂神經網路模型的上限則為 50,000。
針對自訂擷取模型定型,範本模型的定型資料大小總計為 50 MB,而神經模型的大小總計則為 1G-MB。
針對自訂分類模型定型,定型資料的大小總計為
1GB(上限為 10,000 頁)。
建置模式
建置自定義模型作業會新增範本和類神經自定義模型的支援。 舊版的 REST API 和用戶端連結庫僅支援目前稱為 範本 模式的單一建置模式。
範本模型只接受具有相同基本頁面結構的文件—統一的視覺外觀—或文件內元素的相同相對位置。
神經模型支援具有相同資訊但不同頁面結構的文件。 這些檔的範例包括 美國 W2 表單,這些表單共用相同的資訊,但在公司外觀上有所不同。 神經模型目前僅支援英文文字。
下表提供 GitHub 上建置模式程式設計語言 SDK 參考和程式碼範例的連結:
| 程式設計語言 | SDK 參考 | 程式碼範例 |
|---|---|---|
| C#/.NET | DocumentBuildMode Struct | Sample_BuildCustomModelAsync.cs |
| Java | DocumentBuildMode 類別 | BuildModel.java |
| JavaScript | DocumentBuildMode type | buildModel.js |
| Python | DocumentBuildMode 列舉 | sample_build_model.py |
比較模型功能
下表比較自訂範本和自訂神經功能:
| 功能 | 自訂範本 (表單) | 自訂神經 (文件) |
|---|---|---|
| 文件結構 | 範本、表單和結構化 | 結構化、半結構化和非結構化 |
| 定型時間 | 1 至 5 分鐘 | 20 分鐘到 1 小時 |
| 資料擷取 | 索引鍵/值組、資料表、選取標記、座標和簽章 | 索引鍵/值組、選取標記和數據表 |
| 重疊欄位 | 不支援 | 支援 |
| 文件變化 | 每個變化都需要模型 | 針對所有變化使用單一模型 |
| 語言支援 | 多種語言支援 | 英文,具有西班牙文、法文、德文、義大利文和荷蘭 文支援的預覽支援 |
自訂分類模型
檔分類是使用 (v3.1 GA) API 的檔智慧 2023-07-31 所支援的新案例。 檔分類器 API 支援分類和分割案例。 定型分類模型,以識別應用程式支援的不同文件類型。 分類模型的輸入檔案可以包含多個文件,並將每個文件分類在相關聯的頁面範圍內。 若要深入瞭解, 請參閱自定義分類 模型。
注意
從 2024-02-29-preview API 版本檔分類開始,現在支援 Office 檔案類型進行分類。 此 API 版本也引進 分類模型的累加式定 型。
自訂模型工具
檔案智慧 v3.1 和更新版本模型支援下列工具、應用程式和連結庫、程式和連結庫:
| 功能 | 資源 | Model ID |
|---|---|---|
| 自訂模型 | • 文件智慧 Studio • REST API • C# SDK• Python SDK |
custom-model-id |
Document Intelligence v2.1 支援下列工具、應用程式和連結庫:
| 功能 | 資源 |
|---|---|
| 自訂模型 | • 檔案智慧標籤工具 • REST API • 用戶端連結庫 SDK • 檔案智慧 Docker 容器 |
組建自訂模型
使用自訂模型,從特定或唯一的文件擷取資料。 您需要下列資源:
Azure 訂用帳戶。 您可以免費建立一個訂用帳戶。
Azure 入口網站中的 Document Intelligence 執行個體。 您可以使用免費定價層 (
F0) 來試用服務。 部署資源後,選取 [前往資源] 以取得金鑰和端點。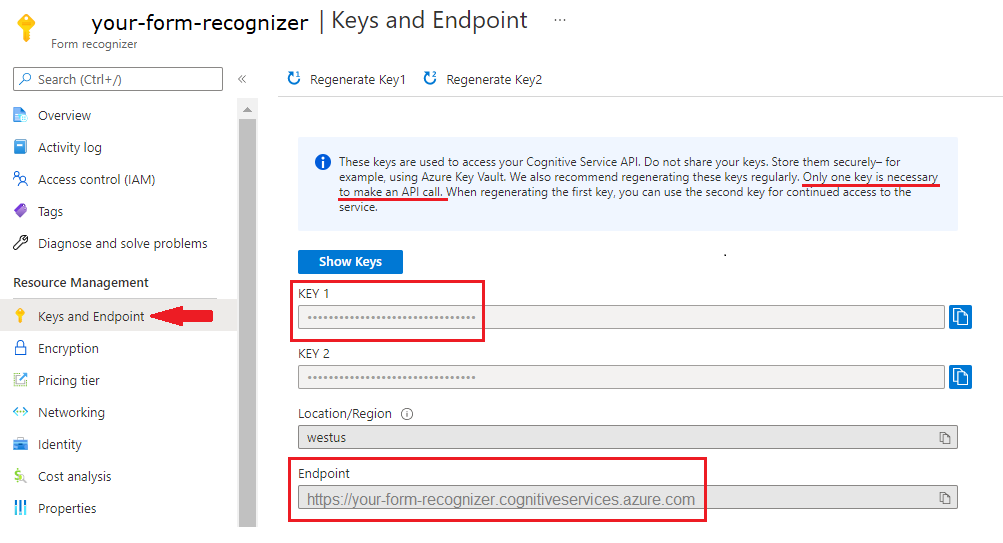
範例標記工具
提示
- 如需增強體驗和進階模型品質,請嘗試文件智慧服務 v3.0 工作室。
- v3.0 工作室支援使用 v2.1 標記資料定型的任何模型。
- 如需從 v2.1 移轉到 v3.0 的詳細資訊,您可以參閱《API 移轉指南》。
- 請參閱我們的 REST API 或是 C#、Java、JavaScript 或 Python SDK 快速入門,以開始使用 v3.0 版本。
檔智慧範例標籤工具是一種 開放原始碼 工具,可讓您測試檔智慧和光學字元辨識 (OCR) 功能的最新功能。
請嘗試樣本標記工具快速入門,以開始建置和使用自訂模型。
Document Intelligence Studio
注意
Document Intelligence Studio 有 v3.1 和 v3.0 API 可供使用。
在 Document Intelligence Studio 首頁上,選取 [自定義擷取模型]。
在 [我的專案] 下,選取 [建立專案]。
完成專案詳細資料欄位。
將儲存體帳戶和 Blob 容器新增至連線定型資料來源,以設定服務資源。
檢閱並建立專案。
將範例檔新增至標籤、建置及測試您的自定義模型。
如需建立第一個自定義擷取模型的詳細逐步解說, 請參閱如何建立自定義擷取模型。
自訂模型擷取摘要
下表比較支援的資料擷取區域:
| 模型 | 表單欄位 | 選取標記 | 結構化欄位 (資料表) | 簽章 | 區域標籤 | 重疊欄位 |
|---|---|---|---|---|---|---|
| 自訂範本 | ✔ | ✔ | ✔ | ✔ | ✔ | 不適用 |
| 自訂神經 | ✔ | ✔ | ✔ | 不適用 | * | ✔ (2024-02-29-preview) |
資料表符號:
✔ —支援
**n/a— 目前無法使用;
*-根據模型的行為不同。 使用範本模型時,會在定型時產生綜合資料。 使用類神經網路時,會選取區域中已辨識的結束文字。
提示
當您選擇這兩種模型類型時,請從自訂神經模型開始,以判斷其是否符合您的功能需求。 若要深入瞭解自訂神經模型,請參閱自訂神經。
自訂模型開發選項
下表描述與相關聯工具和客戶端連結庫搭配使用的功能。 最佳做法是,請確定您使用此處所列的相容工具。
| Document type | REST API | SDK | 標記和測試模型 |
|---|---|---|---|
| 自定義範本 v 4.0 v3.1 v3.0 | 文件智慧 3.1 | 文件智慧 SDK | Document Intelligence Studio |
| 自定義類神經 v4.0 v3.1 v3.0 | 文件智慧 3.1 | 文件智慧 SDK | Document Intelligence Studio |
| 自定義表單 v2.1 | 檔智慧 2.1 GA API | 文件智慧 SDK | 範例標籤工具 |
注意
與 2.1 API 相比,使用 3.0 API 定型的自訂範本模型有一些改善,這些改善源自於 OCR 引擎的改善。 使用 2.1 API 定型自訂範本模型的資料集仍可用來使用 3.0 API 來定型新模型。
若要得到最佳結果,請為每個文件提供一張清晰的照片或高畫質的掃描檔案。
支援的檔案格式:JPEG/JPG、PNG、BMP、TIFF 和 PDF (文字內嵌或掃描)。 建議使用文字內嵌的 PDF,以消除擷取字元和位置時可能發生的錯誤。
針對 PDF 和 TIFF 檔案,可以處理最多 2000 頁。 使用免費層訂用帳戶的情況下,只會處理前兩頁。
付費 (S0) 層的檔案大小必須小於 500 MB,免費 (F0) 層必須小於 4 MB。
影像維度必須介於 50 x 50 像素和 10,000 x 10,000 像素之間。
PDF 維度最大到 17 x 17 英吋,對應於標準 (美國 8.5 x 14) 或 A3 紙張尺寸或更小。
定型資料的大小總計為 500 個頁面以下。
如果您的 PDF 有密碼鎖定,則必須先移除鎖定才能提交。
提示
定型資料:
- 可以的話,請使用文字型 PDF 文件,而不是影像型文件。 掃描的 PDF 將視為影像處理。
- 請為每個文件提供單一表單執行個體。
- 針對填入表單,請使用欄位都已填畢的範例。
- 使用在每個欄位中具有不同值的表單。
- 如果您的表單影像品質較低,請使用較大的資料集。 例如,使用 10 到 15 個影像。
支援的語言和地區設定
如需支援語言的完整清單,請參閱 我們的 語言支援 - 自定義模型 頁面。
下一步
嘗試使用 檔智慧範例卷標工具來處理您自己的表單和檔。
完成 Document Intelligence 快速入門,並開始以您選擇的開發語言來建立文件處理應用程式。
嘗試使用 Document Intelligence Studio 處理您自己的表單和檔。
完成 Document Intelligence 快速入門,並開始以您選擇的開發語言來建立文件處理應用程式。