Azure Front Door
Azure API 管理
Azure Kubernetes Service (AKS)
Azure 應用程式閘道
Dynamics 365
雲端解決方案的成功取決於其可靠性。 可靠性可以廣泛定義為系統在指定的環境條件下在指定時間內如預期運作的機率。 網站可靠性工程 (SRE) 是建立可調整且高度可靠軟體系統的一組原則和做法。 SRE 在數位服務設計期間使用,以確保更高的可靠性。
如需 SRE 策略的詳細資訊,請參閱 AZ-400:開發網站可靠性工程 (SRE) 策略。
潛在使用案例
本文中的概念適用於:
- 以 API 為基礎的雲端服務。
- 公開的 Web 應用程式。
- IoT 型或事件型工作負載。
架構

下載此架構的 PowerPoint 檔案。
此處所考慮的架構是可調整 API 平台的架構。 該解決方案包含多個微服務,使用各種資料庫與儲存服務,包括如 Dynamics 365 和 Microsoft 365 等軟體即服務(SaaS)解決方案。
本文探討一種解決方案,能處理高階市場與電子商務的應用案例,以展示圖中所示的區塊。 使用案例如下:
- 產品流覽。
- 註冊和登入。
- 檢視新聞文章等內容。
- 訂單和訂用帳戶管理。
Web 應用程式、行動應用程式,甚至服務應用程式等用戶端應用程式會透過統一存取路徑 https://api.contoso.com取用 API 平台服務。
元件
- Azure Front Door 針對解決方案的所有要求,提供安全的統一進入點。 如需更多資訊,請參閱路由架構概觀。
- Azure API 管理 提供所有已發佈 API 的治理層。 您可以使用 Azure API 管理 原則在 API 層上套用其他功能,例如存取限制、快取和數據轉換。 API 管理 支援標準層和進階層中的自動調整。
- Azure Kubernetes Service (AKS) 是開放原始碼 Kubernetes 叢集的 Azure 實作。 由於託管的 Kubernetes 服務,Azure 會處理重要的工作,例如健康情況監控和維護。 因為 Azure 管理 Kubernetes API 伺服器,你只需要管理和維護代理節點。 在此架構中,所有微服務都會部署在 AKS 中。
- Azure 應用程式閘道 是應用程式傳遞控制器服務。 它會在應用層第 7 層運作,並具有各種負載平衡功能。 應用程式閘道 輸入控制器 (AGIC) 是 Kubernetes 應用程式,可讓 Azure Kubernetes Service (AKS) 客戶使用 Azure 原生 應用程式閘道 L7 負載平衡器向因特網公開雲端軟體。 v2 SKU 支援自動調整和區域備援。
- Azure 儲存體、Azure Data Lake Storage、Azure Cosmos DB 和 Azure SQL 可以儲存結構化和非結構化內容。 您可以使用自動調整輸送量來建立 Azure Cosmos DB 容器和資料庫。
- Microsoft Dynamics 365 是Microsoft的軟體即服務(SaaS)供應專案,為客戶服務、銷售、行銷和金融提供數個商務應用程式。 在此架構中,Dynamics 365 主要用於管理產品目錄和客戶服務管理。 縮放單位提供 Dynamics 365 應用程式的復原能力。
- Microsoft 365(先前稱為 Office 365 )會作為企業內容管理系統,其建置在 Microsoft 365 中的 Microsoft 365 SharePoint 上。 它用來建立、管理及發佈內容,例如媒體資產和檔。
替代項目
由於此解決方案使用可高度擴充的微服務架構,因此請考慮計算平面的這些替代方案:
適當的可靠性
解決方案所需的可靠性程度取決於商務內容。 零售店店開放 14 小時,且在該範圍內有系統使用量尖峰,其需求與接受所有小時訂單的在線業務不同。 您可以量身打造 SRE 做法,以達到適當的可靠性層級。
可靠性是使用 服務等級目標(服務等級目標 (SLO)來定義及測量可靠性的目標層級。 達到目標層級可確保消費者滿意。 SLO 目標可能會根據業務需求而發展或變更。 不過,服務擁有者應持續針對 SLO 測量可靠性,以偵測問題並採取更正動作。 SLO 通常定義為一段時間內的百分比成就。
另一個重要詞彙是 服務等級指標 (服務等級指標 (SLI)),這是用來計算 SLO 的計量。 SLA 是以衍生自客戶取用服務時所擷取之數據的深入解析為基礎。 從客戶的觀點來看,一律會測量 SLA。
SLO 和 SLA 一律會交手,而且通常會以反覆的方式定義。 SLO 是由主要商務目標所驅動,而 SLA 則由實作服務時可能測量的專案所驅動。
下圖顯示被監測指標、SLI 與 SLO 之間的關係:
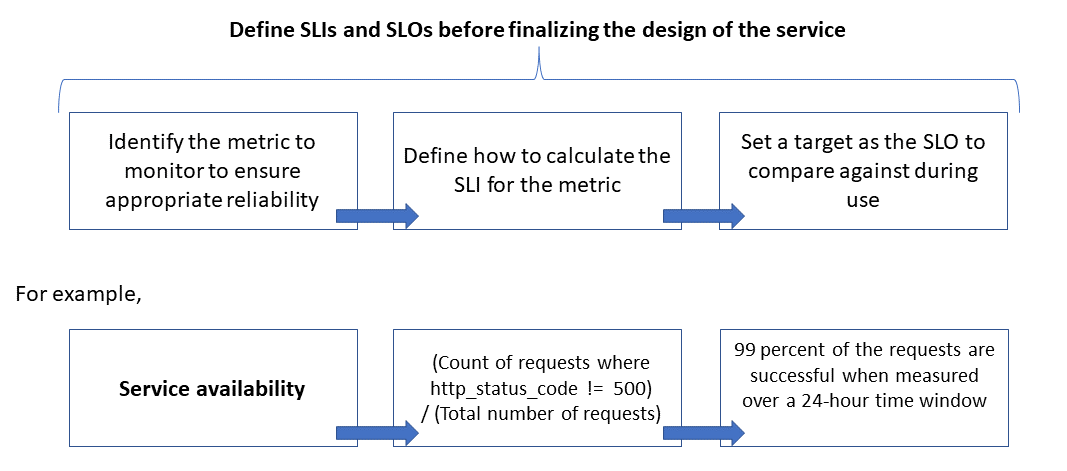
欲了解更多此流程資訊,請參閱定義 SLI 指標以計算 SLO。
模型化規模和效能預期
對於軟體系統,效能通常是指系統在指定時間內執行動作時的整體回應性,而延展性是系統處理增加用戶負載的能力,而不會損害效能。
如果基礎資源以動態方式提供,以支援增加負載,系統就會被視為可調整。 雲端應用程式必須針對規模設計,而且流量量有時難以預測。 季節性尖峰可能會增加規模需求,特別是當服務處理多個租使用者的要求時。
設計應用程式是很好的作法,讓雲端資源視需要自動相應增加和減少,以符合負載。 基本上,系統應該透過以累加方式布建或配置資源,以符合需求,來適應工作負載增加。 延展性不僅與計算實例有關,也與數據儲存和傳訊基礎結構等其他元素有關。
本文說明如何藉由對工作負載案例進行規模和效能模型化,以及使用結果來定義監視、SLA 和 SLO,以確保雲端應用程式的適當可靠性。
考量
如需建置可調整且可靠應用程式的指引,請參閱 Azure Welled Framework 的可靠性與效能效率要素。
本文探討如何套用延展性和效能模型化技術,以微調解決方案架構和設計。 這些技術可識別交易流程的變更,以獲得最佳用戶體驗。 根據您的技術決策,根據解決方案的非功能需求。 程序:
- 識別延展性需求。
- 將預期的負載模型化。
- 定義使用者案例的 SLA 和 SLO。
注意
Azure 應用程式 Insights 是 Azure 監視器的一部分,是功能強大的應用程式效能管理 (APM) 工具,可讓您輕鬆地與應用程式整合,以傳送遙測和分析應用程式特定的計量。 它也提供現成可用的儀錶板和計量總管,可供您用來分析數據以探索商務需求。
擷取延展性
假設這些尖峰負載計量:
- 使用 API 平臺的取用者數目:150 萬
- 每小時活躍消費者(150萬人中佔30%):45萬人
- 每個活動的負載百分比:
- 產品流覽:75%
- 註冊包括配置檔建立和登入:10%
- 訂單和訂用帳戶的管理:10%
- 內容檢視:5%
針對平臺所裝載的 API,負載會產生下列調整需求,在一般尖峰負載下:
- 產品微服務:每秒約 500 個要求 (RPS)
- 分析微服務:大約100個 RPS
- 訂單和付款微服務:約100個 RPS
- 內容微服務:約 50 個 RPS
這些規模需求不會考慮季節性和隨機尖峰,以及特殊事件期間的尖峰,例如營銷促銷。 在尖峰期間,某些用戶活動的規模需求高達正常尖峰負載的 10 倍。 當您為微服務做出設計選擇時,請記住這些條件約束和期望。
定義 SLI 計量以計算 SLO
SLI 計量表示服務提供令人滿意體驗的程度,而且可以表示為良好事件與事件總數的比例。
針對 API 服務,事件是指在執行期間擷取作為遙測或已處理數據的應用程式特定計量。 此範例具有下列 SLI 計量:
| 計量 | 說明 |
|---|---|
| 可用性 | 要求是否由 API 服務 |
| 延遲 | API 處理要求並傳回回復的時間 |
| 輸送量 | API 所處理的要求數目 |
| 成功率 | API 成功處理的要求數目 |
| 錯誤率 | API 所處理要求的錯誤數目 |
| 時效性 | 使用者收到 API 上讀取作業的最新資料次數,儘管基礎數據存放區以特定寫入延遲更新 |
注意
請務必識別對您解決方案而言很重要的任何其他 SLA。
以下是 SLA 的範例:
- (成功完成的要求數目少於 1,000 毫秒) / (要求數目)
- (傳回三秒內任何發佈至目錄的產品搜尋結果數目) /(搜尋數目)
定義 SLA 之後,請判斷要擷取哪些事件或遙測來測量它們。 例如,若要測量可用性,您可以擷取事件,以指出 API 服務是否成功處理要求。 針對 HTTP 型服務,成功或失敗會以 HTTP 狀態代碼表示。 API 設計和實作必須提供適當的程式代碼。 一般而言,SLI 計量是 API 實作的重要輸入。
針對雲端式系統,您可以使用資源可用的診斷和監視支援來取得一些計量。 Azure 監視器是收集、分析及處理雲端服務遙測的完整解決方案。 根據您的 SLI 需求,可以擷取更多監視數據來計算計量。
使用百分位數分佈
某些 SLA 是使用百分位數分配技術來計算。 如果有極端值可能會扭曲其他技術,例如平均值或中位數分佈,這會提供更好的結果。
例如,假設計量是 API 要求的延遲,而三秒是最佳效能的臨界值。 一小時 API 要求的已排序回應時間顯示,很少有要求需要超過三秒的時間,而且大多數在閾值限制內接收回應。 這是系統的預期行為。
百分位數分佈的目的是排除間歇性問題所造成的極端值。 例如,如果適當的服務回應位於第90個或第95個百分位數,則會將SLO視為符合。
選擇適當的測量期間
定義 SLO 的測量期間非常重要。 它必須擷取活動,而不是閑置,結果才能對用戶體驗有意義。 視您想要監視和計算 SLI 計量的方式而定,此視窗可以是 5 分鐘到 24 小時。
建立效能治理程式
API 的效能必須從一開始管理,直到它已被取代或淘汰為止。 必須建立健全的治理流程,確保效能問題能及早被發現並修正,避免造成影響業務的重大停機。
以下是效能治理的元素:
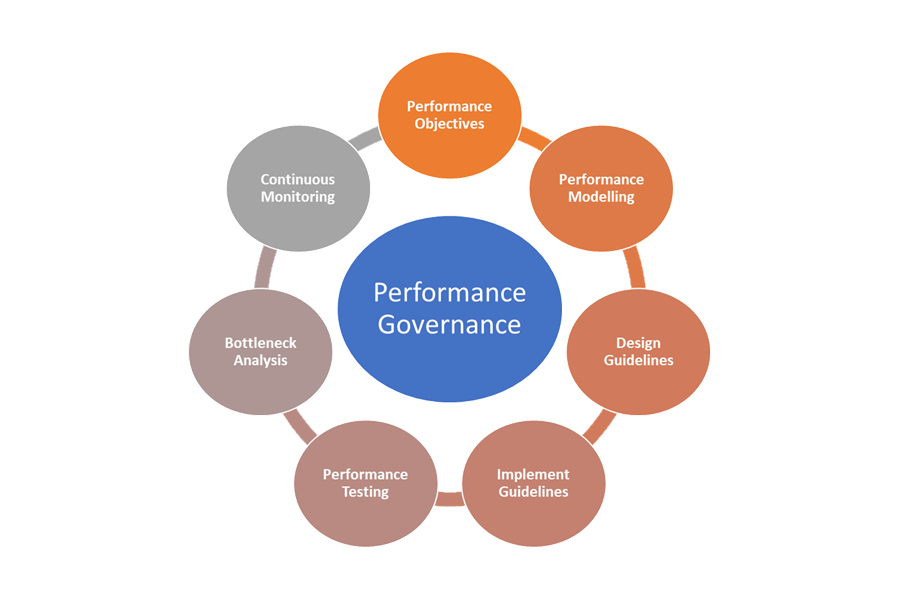
- 效能目標: 定義商務案例的理想效能 SLO。
- 效能模型化: 識別業務關鍵工作流程和交易,並進行模型化,以瞭解效能相關的影響。 在細微層級擷取這項資訊,以取得更精確的預測。
- 設計指導方針: 準備效能設計指導方針,並建議適當的商務工作流程修改。 請確定小組了解這些指導方針。
- 實作指導方針: 實作解決方案元件的效能設計指導方針,包括用來擷取計量的檢測。 進行效能設計檢閱。 請務必使用不同小組的架構待辦項目來追蹤所有這些專案。
- 效能測試: 根據負載配置檔分佈進行負載和壓力測試,以擷取與平臺健康情況相關的計量。 您也可以針對有限的負載進行這些測試,以基準檢驗解決方案基礎結構需求。
- 瓶頸分析: 使用程式碼檢查和程式代碼檢閱來識別、分析及移除各種元件的效能瓶頸。 識別支援尖峰負載所需的水準或垂直縮放增強功能。
- 持續監視: 在DevOps程式中建立持續監視和警示基礎結構。 請確定相關小組在回應時間與基準相比大幅降級時收到通知。
- 效能控管: 建立由定義完善的程式與小組組成的效能控管,以維持效能 SLA。 在每個版本之後追蹤合規性,以避免因為組建升級而降低任何效能。 定期進行檢閱,以評估是否有任何增加的負載,以識別解決方案升級。
請務必在解決方案開發過程中重複這些步驟,做為漸進式詳細說明程式的一部分。
追蹤待處理專案中的效能目標和期望
追蹤您的效能目標,以協助確保達到這些目標。 擷取細微且詳細的使用者劇本以追蹤。這有助於確保開發小組將效能治理活動設為高優先順序。
建立目標解決方案的理想 SLO
以下是考慮 API 平台解決方案的範例期望 SLO:
- 在一秒內回應一天內所有 READ 要求的 95%。
- 在三秒內,回應 95% 的所有 CREATE 和 UPDATE 要求。
- 在五秒內回應 99% 的所有要求,且沒有任何失敗。
- 在五分鐘內成功回應一天中所有要求的99.9%。
- 在尖峰一小時時段錯誤期間,要求少於百分之一。
SLO 可以量身打造,以符合特定應用程式需求。 不過,務必要有足夠細微的粒度,以確保可靠性。
測量以記錄數據為基礎的初始 SLO
當 API 服務正在使用時,會自動建立監視記錄。 假設一週的數據顯示以下結果:
- 要求:123,456
- 成功要求:123,204
- 第90個百分位數延遲:497毫秒
- 第 95 個百分位數延遲:870 毫秒
- 第99個百分位數延遲:1,024毫秒
此資料會產生下列初始 SLA:
- 可用性 = (123,204 / 123,456) = 99.8%
- 延遲 = 至少 90% 的要求在 500 毫秒內提供服務
- 延遲 = 大約 98% 的要求在 1000 毫秒內提供服務
假設在規劃期間,期望延遲 SLO 目標是在 500 毫秒內處理 90% 的要求,且成功率在一周內為 99%。 使用記錄數據,您可以輕鬆地識別是否符合 SLO 目標。 如果您執行此類型的分析數周,您可以開始查看 SLO 合規性的趨勢。
技術風險降低的指引
使用下列建議做法檢查清單來降低延展性和效能風險:
- 調整和效能的設計。
- 請確定您擷取每個使用者案例和工作負載的規模需求,包括季節性和尖峰。
- 進行效能模型化以識別系統條件約束和瓶頸
- 管理技術債務。
- 執行廣泛的效能計量追蹤。
- 例如,請考慮在開發預備環境中使用腳本來執行 K6.io、空手道和 JMeter 等工具,包括 50 到 100 RPS。 這會在記錄中提供資訊,以偵測設計和實作問題。
- 將自動化測試腳本整合為持續部署 (CD) 程式的一部分,以偵測建置中斷。
- 有生產思維。
- 調整健康情況統計數據所指出的自動調整臨界值。
- 偏好水平縮放技術而不是垂直。
- 主動調整以處理季節性。
- 偏好以通道為基礎的部署。
- 使用錯誤預算來實驗。
定價
可靠性、效能效率與成本優化也一併著手。 架構中使用的 Azure 服務有助於降低成本,因為它們會自動調整以容納變更的用戶負載。
針對 AKS,您一開始可以針對節點集區使用標準大小的 VM。 然後,您可以在開發或生產環境使用期間監視資源需求,並據以調整。
成本優化是 Azure 良好架構架構Microsoft要素。 如需詳細資訊,請參閱成本最佳化支柱的概觀。 若要估計 Azure 產品和組態的成本,請使用 定價計算機。
參與者
本文由 Microsoft 維護。 原始投稿人如下。
主要作者:
- Subhajit Chatterjee |首席軟體工程師
下一步
- Azure 文件
- Microsoft Azure Well-Architected 框架
- 微服務架構樣式
- 向外延展的設計
- 為您的應用程式選擇 Azure 計算服務
- Azure Kubernetes Service 上的微服務架構
- Azure Front Door 是什麼?
- 關於 API 管理
- 什麼是應用程式閘道輸入控制器?
- Azure Kubernetes 服務
- 自動調整規模和區域備援應用程式閘道 v2
- 自動調整叢集以符合 Azure Kubernetes Service (AKS) 的應用程式需求 (部分機器翻譯)
- 使用自動調整輸送量來建立 Azure Cosmos DB 容器和資料庫
- Microsoft Dynamics 365 文件
- Microsoft 365 文件
- 網站可靠性工程檔
- AZ-400:開發網站可靠性工程 (SRE) 策略
- 具有區域備援的基準 Web 應用程式