本文說明在微服務架構中管理數據的考慮。 每個微服務都管理自己的資料,因此資料完整性與一致性是關鍵挑戰。
兩個服務不應該共用一個資料儲存庫。 每個服務都管理自己的私人資料庫,其他服務無法直接存取。 此規則防止服務間非預期耦合,當服務共享相同的底層資料結構時發生。 若資料結構改變,必須在所有依賴該資料庫的服務間協調變更。 將每個服務的資料儲存隔離起來,限制了變更的範圍,並維持獨立部署的敏捷性。 每個微服務也可能擁有獨特的資料模型、查詢或讀寫模式。 共享資料儲存限制了各團隊針對特定服務優化資料儲存的能力。
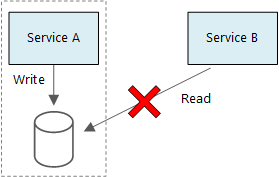
圖示左側區塊展示了服務 A 和一個資料庫。 一個標示有「write」的箭頭從服務 A 指向資料庫。 服務B位於此區域外側的右側。 一個標示已讀的箭頭指向資料庫。 這個箭頭上有一個紅色的X。
這種方法自然導致 多語持續性,也就是在同一應用程式中使用多種資料儲存技術。 某項服務可能需要文件資料庫的讀時結構功能。 其他服務可能需要關聯式資料庫管理系統(RDBMS)所提供的參照完整性。 每個團隊都可以選擇最適合其服務的方案。
備註
服務可以安全地共用同一台實體資料庫伺服器。 當服務共用相同結構,或讀寫同一組資料庫資料表時,就會產生問題。
挑戰
分散式管理資料帶來多項挑戰。 首先,冗餘可能發生在資料儲存庫之間。 同一個資料項目可能會出現在多個地方。 例如,資料可能作為交易的一部分儲存,然後存放於其他地方以便分析、報告或歸檔。 重複或分割的資料可能導致資料完整性與一致性的問題。 當資料關聯跨越多個服務時,傳統的資料管理技術無法強制執行這些關聯。
傳統資料建模遵循 「同一事實於一處」的原則。 每個實體在結構中只會出現一次。 其他實體可能會參考,但不會複製。 傳統方法的主要優點是更新會在單一地點發生,避免資料一致性問題。 在微服務架構中,你必須考慮更新如何在服務間傳播,以及當資料出現在多個地方且缺乏強一致性時,如何管理最終一致性。
管理數據的方法
沒有單一方法適用於所有案例。 請參考以下管理微服務架構資料的一般指引:
定義每個元件所需的一致性等級,並在可能的情況下偏好最終一致性。 找出系統中需要強一致性或原子性、一致性、隔離性與持久性(ACID)交易的區域。 並找出最終可接受的一致性領域。 欲了解更多資訊,請參閱 微服務使用戰術領域驅動設計(DDD)。
當你需要強烈的一致性時,請使用單一的真實來源。 某項服務可能代表某個實體的真實來源,並透過 API 公開。 其他服務可能持有自己的資料副本,或其子集,最終與主要資料一致,但不被視為真實來源。 例如,在一個電子商務系統中,當有顧客訂購服務和推薦服務時,推薦服務可能會監聽訂單服務的事件。 但如果顧客要求退款,擁有完整的交易紀錄的是訂單服務,而非推薦服務。
套用交易模式以維持各服務間的一致性。 使用像 排程代理監督者 和 補償交易 等模式,讓資料在多項服務間保持一致。 為了避免多個服務間的部分故障,你可能需要儲存一個額外的資料,來捕捉跨越多個服務的工作單元的狀態。 例如,在多步驟交易進行時,將工作專案保留在長期佇列上。
只儲存服務所需的數據。 服務可能只需要網域實體的相關信息子集。 例如,在運送有界的情境中,你需要知道哪位客戶與特定配送相關聯。 但你不需要客戶的帳單地址,因為帳戶限定上下文會管理這些資訊。 仔細的領域分析與DDD方法可強化此原則。
請考慮您的服務是否一致且鬆散結合。 如果兩個服務持續交換資訊並產生對話式 API,您可能需要重新劃定服務邊界。 合併這兩個服務或重構它們的功能。
使用 事件驅動架構風格。 在此架構風格中,服務在其公開模型或實體發生變更時會發布事件。 其他服務也可以訂閱這些活動。 例如,另一個服務可以利用這些事件建構一個更適合查詢的資料具體化視圖。
發布事件架構。 擁有事件的服務應該發布結構,以自動化事件的序列化與反序列化。 這種做法避免了出版商與訂閱者之間的緊密結合。 可以考慮 JSON 架構或像 Protobuf 或 Avro 這樣的框架。
大規模減少活動瓶頸。 在大規模情況下,事件可能成為系統的瓶頸。 可以考慮使用聚合或批次來減少總負載。
範例:選擇無人機配送應用程式的資料儲存庫
本系列先前文章以無人機配送服務為例。 欲了解更多關於情境及對應架構的資訊,請參見 「設計微服務架構」。
為了回顧,此應用程式會定義數個微服務,以排程無人機的傳遞。 當使用者安排新的配送時,客戶請求會包含有關配送的資訊,例如取件與投遞地點,以及包裹的尺寸與重量。 這項資訊會定義工作單位。
各種後端服務會使用請求中不同部分的資訊,且有不同的讀寫配置檔。

配送服務
配送服務會儲存目前排程或正在進行的每一次配送資訊。 它會監聽無人機的事件,並追蹤正在進行的配送狀態。 它也會傳送傳遞狀態更新的網域事件。
使用者在等待包裹時,經常會查看送貨狀態。 因此,傳送服務需要一個強調吞吐量(讀寫)勝過長期儲存的資料儲存。 外送服務不會做複雜的查詢或分析。 它只會取得特定配送的最新狀態。 配送服務團隊選擇 Azure Managed Redis 是因為其高讀寫效能。 Azure Managed Redis中儲存的資訊壽命很短。 交付結束後,配送歷史服務成為記錄系統。
配送歷史服務
配送歷史服務會監聽來自配送服務的投遞狀態事件。 它會將此資料儲存在長期記憶體中。 這些歷史資料支援兩種情境,每種都有不同的儲存需求。
第一種情境是彙整資料進行資料分析,以優化業務或提升服務品質。 配送歷史服務並不做實際的數據分析。 它只負責擷取和儲存資料。 在此情境下,儲存必須經過優化,以適應大型資料集的資料分析,並採用讀時套用結構(schema-on-read)方式以容納多種資料來源。 Azure Data Lake Storage 很適合這種情況,因為它是 Apache Hadoop 檔案系統,且相容於 Hadoop 分散式檔案系統(HDFS)。 它也針對資料分析情境進行效能調整。
第二種情境讓使用者在送貨結束後查詢送貨歷史。 Data Lake Storage 不支援這種情境。 為了達到最佳效能,請將時間序列資料存放在 Data Lake Storage 中,依日期分割的資料夾中。 但這種結構使得基於個別ID的查詢效率降低。 除非你也知道時間戳記,否則 ID 查詢需要掃描整個資料集。 為了解決這個問題,配送歷史服務也會在 Azure Cosmos DB 中儲存部分歷史資料,以便更快查詢。 記錄不需要無限期地留在 Azure Cosmos DB 中。 你可以在特定時間段(例如一個月)後,偶爾執行批次處理來歸檔舊的配送。 將資料進行歸檔可以降低 Azure Cosmos DB 的成本,並使資料在 Data Lake Storage 中持續可用於歷史報告。
欲了解更多資訊,請參閱 Tune Data Lake Storage 以了解效能。
套裝服務
包裹服務會儲存所有包裹的資訊。 套件服務的資料儲存庫必須符合以下要求:
- 長期儲存
- 高寫入吞吐量以處理大量套件
- 以套件 ID 進行簡單查詢,無需複雜連接或參照完整性限制
套件資料不是關聯式的,所以文件導向的資料庫運作良好。 Azure DocumentDB 可透過使用分片集合來達成高吞吐量。 套件服務團隊熟悉 MongoDB、Express.js、AngularJS 和 Node.js(MEAN)堆疊,因此他們選擇實作 Azure DocumentDB。 這個選擇讓他們能在享受全管理高效能 Azure 服務的同時,繼續使用現有的 MongoDB 經驗。