解決方案構想
本文說明解決方案概念。 您的雲端架構設計人員可以使用本指南,協助可視化此架構的一般實作的主要元件。 使用本文作為起點,設計符合您工作負載特定需求的架構良好解決方案。
此範例說明如何在擷取、載入和轉換 (ELT) 管線中執行累加式載入。 它會使用 Azure Data Factory 將 ELT 管線自動化。 管線會以累加方式將最新的 OLTP 資料從內部部署 SQL Server 資料庫移至 Azure Synapse。 事務數據會轉換成表格式模型以供分析。
架構

此架構是以 Enterprise BI 與 Azure Synapse 中顯示的架構為基礎,但會新增一些對於企業數據倉儲案例而言很重要的功能。
- 使用 Data Factory 自動化管線。
- 累加式載入。
- 整合多個數據源。
- 載入二進位數據,例如地理空間數據和影像。
工作流程
架構包含下列服務和元件。
資料來源
內部部署 SQL Server。 源數據位於內部部署的 SQL Server 資料庫中。 模擬內部部署環境。 Wide World Importers OLTP 範例資料庫會當做源資料庫使用。
外部數據。 數據倉儲的常見案例是整合多個數據源。 此參考架構會依年份載入包含城市人口的外部數據集,並將它與 OLTP 資料庫中的數據整合。 您可以將此數據用於深入解析,例如:「每個區域中的銷售成長是否符合或超過人口成長?
擷取和數據記憶體
Blob 記憶體。 Blob 記憶體會在將源數據載入 Azure Synapse 之前,用來作為源數據的暫存區域。
Azure Synapse。 Azure Synapse 是一種分散式系統,其設計目的是要對大型數據執行分析。 其支援大量平行處理 (MPP),因此適用於執行高效能分析。
Azure Data Factory。 Data Factory 是一項受控服務,可協調及自動化數據移動和數據轉換。 在此架構中,它會協調 ELT 程式的各個階段。
分析和報告
Azure Analysis Services。 Analysis Services 是完全受控的服務,可提供數據模型化功能。 語意模型會載入 Analysis Services。
Power BI。 Power BI 是一套商務分析工具,可用來分析商務深入解析的數據。 在此架構中,它會查詢儲存在 Analysis Services 中的語意模型。
驗證
Microsoft Entra ID 會驗證透過 Power BI 連線到 Analysis Services 伺服器的使用者。
Data Factory 也可以使用 Microsoft Entra 識別碼,使用服務主體或受控服務識別 (MSI) 向 Azure Synapse 進行驗證。
元件
- Azure Blob 儲存體
- Azure Synapse Analytics
- Azure Data Factory
- Azure Analysis Services
- Power BI
- Microsoft Entra ID
案例詳細資料
資料管線
在 Azure Data Factory 中,管線是用來協調工作的活動邏輯群組,在此案例中,將數據載入和轉換成 Azure Synapse。
此參考架構會定義執行子管線序列的父管線。 每個子管線會將數據載入一或多個數據倉儲數據表。
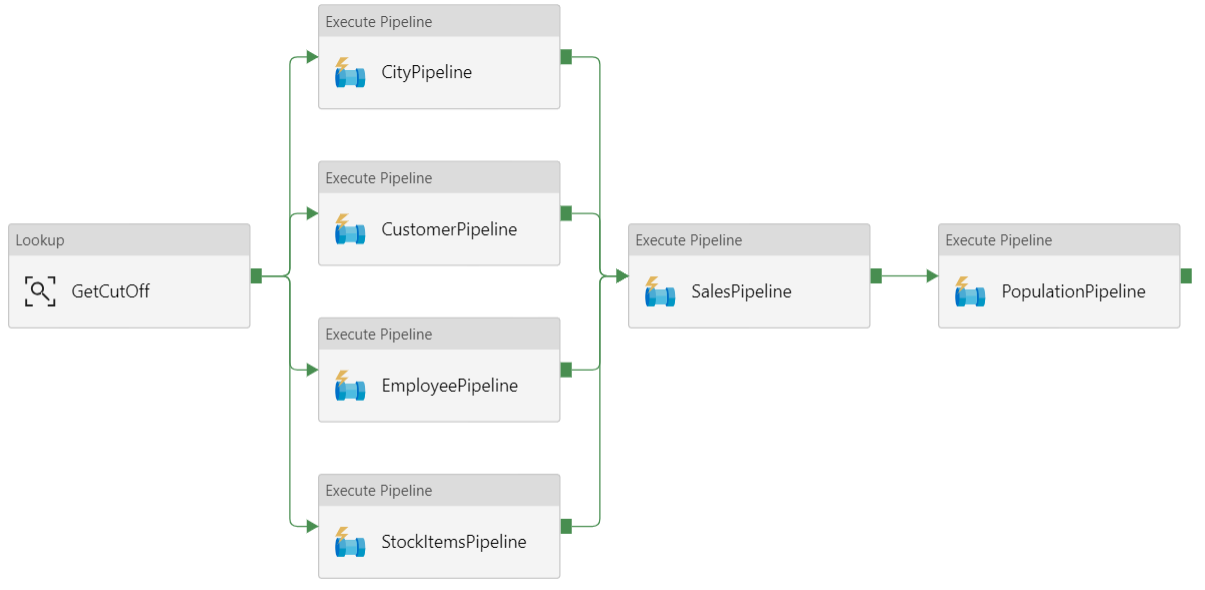
建議
累加式載入
當您執行自動化 ETL 或 ELT 程式時,只載入自上一次執行後變更的數據最有效率。 這稱為 累加式載入,而不是載入所有數據的完整負載。 若要執行累加式載入,您需要一種方式來識別哪些數據已變更。 最常見的方法是使用 高水位標記 值,這表示追蹤源數據表中某些數據行的最新值,也就是 datetime 數據行或唯一的整數數據行。
從 SQL Server 2016 開始,您可以使用 時態表。 這些是系統版本設定的數據表,可保留數據變更的完整歷程記錄。 資料庫引擎會自動記錄個別記錄數據表中每項變更的歷程記錄。 您可以將 FOR SYSTEM_TIME 子句新增至查詢,以查詢歷程記錄數據。 在內部,資料庫引擎會查詢記錄數據表,但這對應用程式而言是透明的。
注意
針對舊版 SQL Server,您可以使用 異動資料擷取 (CDC) 。 這種方法比時態表更方便,因為您必須查詢個別的變更數據表,而且記錄序號會追蹤變更,而不是時間戳。
時態表對於維度數據很有用,可能會隨著時間而變更。 事實數據表通常代表不可變的交易,例如銷售,在此情況下,保留系統版本歷程記錄並不合理。 相反地,交易通常會有一個代表交易日期的數據行,這可以用來做為浮浮水印值。 例如,在Wide World Importers OLTP 資料庫中,Sales.Invoices 和 Sales.InvoiceLines 數據表的 LastEditedWhen 欄位預設為 sysdatetime()。
以下是 ELT 管線的一般流程:
針對源資料庫中的每個數據表,追蹤上次執行 ELT 作業的截止時間。 將此資訊儲存在數據倉儲中。 (在初始設定時,所有時間都設定為 '1-1-1900'。
在數據匯出步驟期間,截斷時間會當做參數傳遞至源資料庫中的一組預存程式。 這些預存程式會查詢在截止時間后變更或建立的任何記錄。 針對 Sales 事實數據表,會使用數據
LastEditedWhen行。 針對維度數據,會使用系統版本設定的時態表。當數據遷移完成時,請更新儲存截止時間的數據表。
記錄每個 ELT 執行的譜系也很有用。 對於指定的記錄,譜系會將該記錄與產生數據的 ELT 執行產生關聯。 針對每個 ETL 執行,會為每個數據表建立新的歷程記錄,以顯示開始和結束的載入時間。 每個記錄的歷程索引鍵會儲存在維度和事實數據表中。
將數據新批次載入倉儲之後,請重新整理 Analysis Services 表格式模型。 請參閱 使用 REST API 進行異步重新整理。
資料清理
數據清理應該是 ELT 程式的一部分。 在此參考架構中,有一個不良數據來源是城市人口數據表,其中某些城市有零人口,可能是因為沒有可用的數據。 在處理期間,ELT 管線會從城市人口數據表中移除這些城市。 在臨時表上執行數據清理,而不是外部數據表。
外部資料來源
數據倉儲通常會合併來自多個來源的數據。 例如,包含人口統計數據的外部數據源。 此數據集可在 Azure Blob 記憶體中取得,做為 WorldWideImportersDW 範例的一部分。
Azure Data Factory 可以使用 Blob 記憶體連接器直接從 Blob 記憶體複製。 不過,連接器需要 連接字串 或共用存取簽章,因此無法用來複製具有公用讀取許可權的 Blob。 因應措施是,您可以使用PolyBase透過 Blob 記憶體建立外部資料表,然後將外部資料表複製到 Azure Synapse。
處理大型二進位數據
例如,在源資料庫中,City 數據表的 Location 資料行會保存 地理位置 空間數據類型。 Azure Synapse 不支援 原生地理位置 類型,因此此字段會在 載入期間轉換成 varbinary 類型。 (請參閱 不支援數據類型的因應措施。
不過,PolyBase 支援 的數據行大小 varbinary(8000)上限,這表示某些數據可能會遭到截斷。 此問題的因應措施是在匯出期間將數據分成區塊,然後重新組合區塊,如下所示:
建立 [位置] 數據行的臨時臨時表。
針對每個城市,將位置數據分割成8000位元組的區塊,導致每個城市的1 – N個數據列。
若要重新組合區塊,請使用 T-SQL PIVOT 運算符將數據列轉換成數據行,然後串連每個城市的數據行值。
挑戰在於,根據地理位置數據的大小,每個城市都會分割成不同數目的數據列。 若要讓 PIVOT 運算子運作,每個城市都必須有相同數目的數據列。 若要讓這項工作,T-SQL 查詢會執行一些技巧,以空白值填補數據列,讓每個城市在樞紐之後都有相同的數據行數目。 產生的查詢會比一次迴圈執行一個數據列的速度要快得多。
影像數據使用相同的方法。
緩時變維度
維度數據相對靜態,但可能會變更。 例如,產品可能會重新指派給不同的產品類別。 有數種方法可以處理緩時變維度。 一種稱為 類型 2 的常見技巧是每當維度變更時加入新的記錄。
為了實作 Type 2 方法,維度數據表需要其他數據行來指定指定指定記錄的有效日期範圍。 此外,源資料庫的主鍵將會重複,因此維度數據表必須具有人工主鍵。
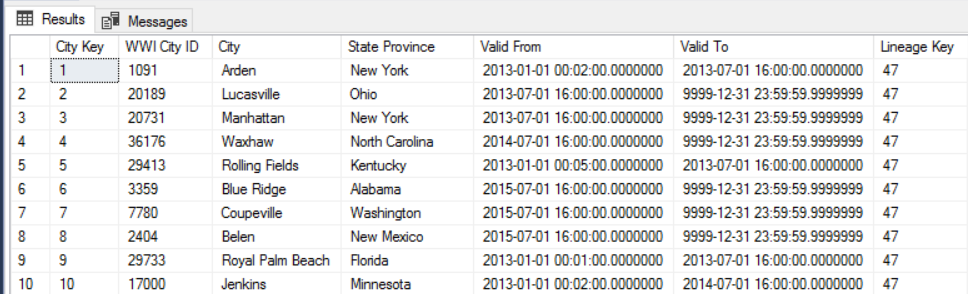
例如,下圖顯示 Dimension.City 數據表。 數據 WWI City ID 行是源資料庫的主鍵。 數據 City Key 行是在 ETL 管線期間產生的人工索引鍵。 另請注意,數據表具有 Valid From 和 Valid To 數據行,這會在每一個數據列有效時定義範圍。 目前的值 Valid To 等於 『9999-12-31』。
這種方法的優點是會保留歷程記錄數據,這對分析很有價值。 不過,這也表示相同實體會有多個數據列。 例如,以下是符合 WWI City ID = 28561 的記錄:
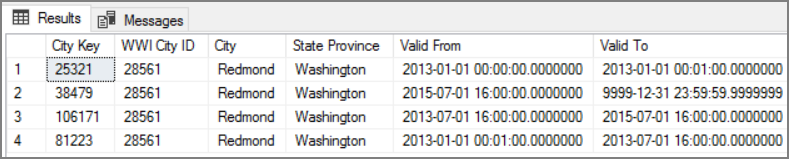
針對每個 Sales 事實,您想要將該事實與 City 維度數據表中的單一數據列產生關聯,該數據列對應至發票日期。
考量
這些考量能實作 Azure Well-Architected Framework 的要素,其為一組指導原則,可以用來改善工作負載的品質。 如需詳細資訊,請參閱 Microsoft Azure Well-Architected Framework (部分機器翻譯)。
安全性
安全性可提供保證,以避免刻意攻擊和濫用您寶貴的資料和系統。 如需詳細資訊,請參閱安全性要素的概觀。
如需其他安全性,您可以使用 虛擬網絡 服務端點,將 Azure 服務資源只保護至您的虛擬網路。 這會完全移除這些資源的公用因特網存取,只允許來自虛擬網路的流量。
使用此方法,您會在 Azure 中建立 VNet,然後為 Azure 服務建立私人服務端點。 然後,這些服務會限制為來自該虛擬網路的流量。 您也可以透過閘道從內部部署網路連線它們。
請留意以下限制:
如果服務端點已啟用 Azure 儲存體,PolyBase 就無法將數據從記憶體複製到 Azure Synapse。 此問題有風險降低。 如需詳細資訊,請參閱 搭配 Azure 記憶體使用 VNet 服務端點的影響。
若要將數據從內部部署移至 Azure 儲存體,您必須允許來自內部部署或 ExpressRoute 的公用 IP 位址。 如需詳細資訊,請參閱 保護 Azure 服務到虛擬網路。
若要讓 Analysis Services 從 Azure Synapse 讀取數據,請將 Windows VM 部署到包含 Azure Synapse 服務端點的虛擬網路。 在此 VM 上安裝 Azure 內部部署數據閘道 。 然後將 Azure Analysis 服務連線到數據閘道。
DevOps
為生產環境、開發和測試環境建立個別的資源群組。 不同的資源群組可讓您更輕鬆地管理部署、刪除測試部署,以及指派訪問許可權。
將每個工作負載放在個別的部署範本中,並將資源儲存在原始檔控制系統中。 您可以將範本一起或個別部署為 CI/CD 程式的一部分,讓自動化程式更容易。
在此架構中,有三個主要工作負載:
- 數據倉儲伺服器、Analysis Services 和相關資源。
- Azure Data Factory。
- 內部部署至雲端模擬案例。
每個工作負載都有自己的部署範本。
數據倉儲伺服器是使用 Azure CLI 命令來設定及設定,其遵循 IaC 做法的命令式方法。 請考慮使用部署腳本,並將其整合到自動化程式中。
請考慮暫存工作負載。 部署至各種階段,並在每個階段執行驗證檢查,再移至下一個階段。 如此一來,您就可以以高度控制的方式將更新推送至生產環境,並將未預期的部署問題降到最低。 使用 藍綠部署 和 Canary 發行 策略來更新即時生產環境。
有良好的復原策略來處理失敗的部署。 例如,您可以從部署歷程記錄自動重新部署先前成功的部署。 請參閱 Azure CLI 中的 --rollback-on-error 旗標參數。
建議使用 Azure 監視器 來分析數據倉儲的效能,以及整個 Azure 分析平臺,以取得整合式監視體驗。 Azure Synapse Analytics 會在 Azure 入口網站 內提供監視體驗,以顯示數據倉儲工作負載的深入解析。 監視數據倉儲時,Azure 入口網站 是建議的工具,因為它提供可設定的保留期間、警示、建議,以及計量和記錄的可自定義圖表和儀錶板。
如需詳細資訊,請參閱 Microsoft Azure Well-Architected Framework 中的 DevOps 一節。
成本最佳化
成本最佳化是關於考慮如何減少不必要的費用,並提升營運效率。 如需詳細資訊,請參閱成本最佳化要素的概觀。
使用 Azure 定價計算機來預估成本。 以下是此參考架構中使用的服務一些考慮。
Azure Data Factory
Azure Data Factory 會將 ELT 管線自動化。 管線會將數據從內部部署 SQL Server 資料庫移至 Azure Synapse。 然後,數據會轉換成表格式模型以供分析。 在此案例中,定價從每月 $0.001 活動執行開始,其中包含活動、觸發程式和偵錯執行。 該價格只是協調流程的基本費用。 您也需支付執行活動的費用,例如複製數據、查閱和外部活動。 每個活動都會個別定價。 您也需支付管線的費用,且該月內沒有相關聯的觸發程式或執行。 所有活動都會依分鐘按比例計算,並四捨五入。
範例成本分析
請考慮使用案例,其中兩個不同來源有兩個查閱活動。 一個需要 1 分 2 秒(四捨五入到 2 分鐘),另一個需要 1 分鐘,總時間 3 分鐘。 一個數據複製活動需要 10 分鐘。 一個預存程序活動需要 2 分鐘。 活動執行總計 4 分鐘。 成本的計算方式如下:
活動執行:4 * $ 0.001 = $0.004
查閱:3 * ($0.005 / 60) = $0.00025
預存程式:2 * ($0.00025 / 60) = $0.000008
數據複製:10 * ($0.25 / 60) * 4 數據整合單位 (DIU) = $0.167
- 每個管線執行的總成本:$0.17。
- 每天執行 30 天一次:$5.1 個月。
- 每天每 100 個數據表執行一次,為期 30 天:$ 510
每個活動都有相關聯的成本。 了解定價模式,並使用 ADF定價計算機 來取得解決方案,不僅針對效能優化,也針對成本優化。 啟動、停止、暫停及調整您的服務,以管理您的成本。
Azure Synapse
Azure Synapse 非常適合具有較高查詢效能和計算延展性需求的密集工作負載。 您可以選擇隨用隨付模型,或使用一年(37% 節省)或 3 年的保留方案(65% 節省)。
數據記憶體會個別收費。 災害復原和威脅偵測等其他服務也會另外收費。
如需詳細資訊,請參閱 Azure Synapse 定價。
Analysis Services (英文)
Azure Analysis Services 的定價取決於層級。 此架構的參考實作會使用 開發人員 層,建議用於評估、開發和測試案例。 其他層包括基本層,建議用於小型生產環境;任務關鍵性生產應用程式的標準層。 如需詳細資訊,請參閱 所需的適當層。
當您暫停執行個體時,不會收取任何費用。
如需詳細資訊,請參閱 Azure Analysis Services 價格。
Blob 儲存體
請考慮使用 Azure 儲存體 保留容量功能來降低記憶體的成本。 使用此模型時,如果可以承諾保留固定儲存容量一或三年,您就會獲得折扣。 如需詳細資訊,請參閱 使用保留容量優化 Blob 記憶體的成本。
如需詳細資訊,請參閱 Microsoft Azure Well-Architected Framework 中的成本一節。
下一步
- Azure Synapse Analytics 簡介
- 開始使用 Azure Synapse Analytics
- Azure Data Factory 簡介
- 什麼是 Azure Data Factory?
- Azure Data Factory 教學課程
相關資源
您可能想要檢閱下列 Azure 範例案例 ,這些案例示範使用一些相同技術的特定解決方案: