已啟用 Azure Arc 的高可用性 SQL 受控執行個體
已啟用 Azure Arc 的 SQL 受控執行個體會以容器化應用程式的形式部署到 Kubernetes 上。 其會使用 Kubernetes 建構,例如 StatefulSet 和永續性儲存體來提供內建:
- 健康狀態監視
- 失敗偵測
- 自動容錯移轉以維護服務健康情況。
為了提升可靠性,您也可以設定已啟用 Azure Arc 的 SQL 受控執行個體,以搭配具有高可用性設定的額外複本進行部署。 Arc 資料服務資料控制器會管理:
- 監視
- 失敗偵測
- Automatic failover
已啟用 Arc 的資料服務會提供這項服務,而不需使用者介入。 此服務:
- 設定可用性群組
- 設定資料庫鏡像端點
- 將資料庫新增至可用性群組
- 協調容錯移轉和升級。
本文件會探索這兩種類型的高可用性。
已啟用 Azure Arc 的 SQL 受控執行個體會根據 SQL 受控執行個體是部署為「一般用途」服務層級或「業務關鍵」服務層級,來提供不同層級的高可用性。
一般用途服務層級中的高可用性
在一般用途服務層級中,只有一個複本可用,而且是透過 Kubernetes 協調流程來達到高可用性。 例如,如果包含受控執行個體容器映像的 Pod 或節點當機,Kubernetes 會嘗試建立另一個 Pod 或節點,並連結至相同的永續性儲存體。 在此期間,應用程式將無法使用 SQL 受控執行個體。 應用程式在新的 Pod 啟動之後,需要重新連線並重試交易。 如果使用 load balancer 的服務類型,則應用程式可以重新連線到相同的主要端點,且 Kubernetes 會將連線重新導向新的主要端點。 如果服務類型為 nodeport,則應用程式必須重新連線到新的 IP 位址。
驗證內建高可用性
若要驗證 Kubernetes 提供的內建高可用性,您可以:
- 刪除現有的受控執行個體的 Pod
- 確認 Kubernetes 從此動作復原
在復原期間,Kubernetes 會啟動另一個 Pod 並連結至永續性儲存體。
必要條件
- Kubernetes 叢集必須具有共用的遠端儲存體
- 搭配單一複本部署之已啟用 Azure Arc 的 SQL 受控執行個體 (預設)
檢視 Pod。
kubectl get pods -n <namespace of data controller>刪除受控執行個體 Pod。
kubectl delete pod <name of managed instance>-0 -n <namespace of data controller>例如:
user@pc:/# kubectl delete pod sql1-0 -n arc pod "sql1-0" deleted檢視 Pod 以確認受控執行個體正在復原。
kubectl get pods -n <namespace of data controller>例如:
user@pc:/# kubectl get pods -n arc NAME READY STATUS RESTARTS AGE sql1-0 2/3 Running 0 22s
在 Pod 內的所有容器都復原之後,您可以連線到受控執行個體。
業務關鍵服務層級中的可用性
在業務關鍵服務層級中,除了 Kubernetes 協調流程原生提供的內容之外,適用於 Azure Arc 的 SQL 受控執行個體還提供自主可用性群組。 自主可用性群組是以 SQL Server Always On 技術為基礎。 其提供較高層級的可用性。 使用「業務關鍵」服務層級部署之已啟用 Azure Arc 的 SQL 受控執行個體,可以搭配 2 或 3 個複本來部署。 這些複本一律會彼此保持同步。
使用自主可用性群組時,任何 Pod 損毀或節點失敗對應用程式而言都是透明的。 自主可用性群組提供至少一個其他 Pod,其中包含主要 Pod 的所有資料且已準備好進行連線。
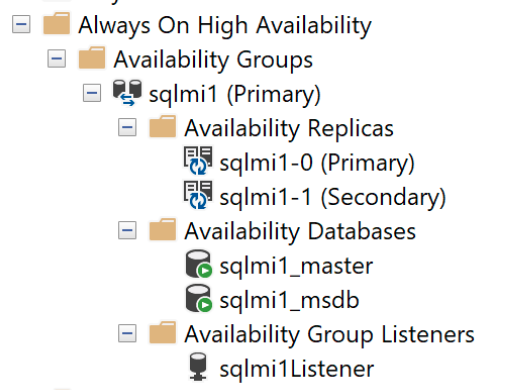
自主可用性群組
可用性群組會將一或多個使用者資料庫繫結至邏輯群組,以便在發生容錯移轉時,整個資料庫群組會以單一單位的形式容錯移轉至次要複本。 可用性群組只會複寫使用者資料庫中的資料,但不會複寫系統資料庫中的資料,例如登入、權限或代理程式作業。 自主可用性群組包括來自系統資料庫的中繼資料,例如 msdb 和 master 資料庫。 在主要複本中建立或修改登入時,系統也會在次要複本中自動加以建立。 同樣地,在主要複本中建立或修改代理程式作業時,次要複本也會收到那些變更。
已啟用 Azure Arc 的 SQL 受控執行個體採用此自主可用性群組的概念,並新增 Kubernetes 運算子,以便大規模加以部署及管理。
自主可用性群組提供的功能:
使用多個複本部署時,會建立名稱與已啟用 Arc 的 SQL 受控執行個體相同的單一可用性群組。 根據預設,自主 AG 具有三個複本,包括主要複本。 可用性群組的所有 CRUD 作業都是在內部進行管理,包括建立可用性群組,或將複本聯結至所建立的可用性群組。 您無法在執行個體中建立更多可用性群組。
所有資料庫都會自動新增至可用性群組,包括所有使用者和系統資料庫 (例如
master和msdb)。 此功能提供跨可用性群組複本的單一系統檢視。 如果您直接連線到執行個體,請注意containedag_master和containedag_msdb資料庫。containedag_*資料庫代表可用性群組內的master和msdb。系統會自動佈建外部端點來連接到可用性群組中的資料庫。
<managed_instance_name>-external-svc這個端點扮演可用性群組接聽程式的角色。
使用 Azure 入口網站,搭配多個複本部署已啟用 Azure Arc 的 SQL 受控執行個體
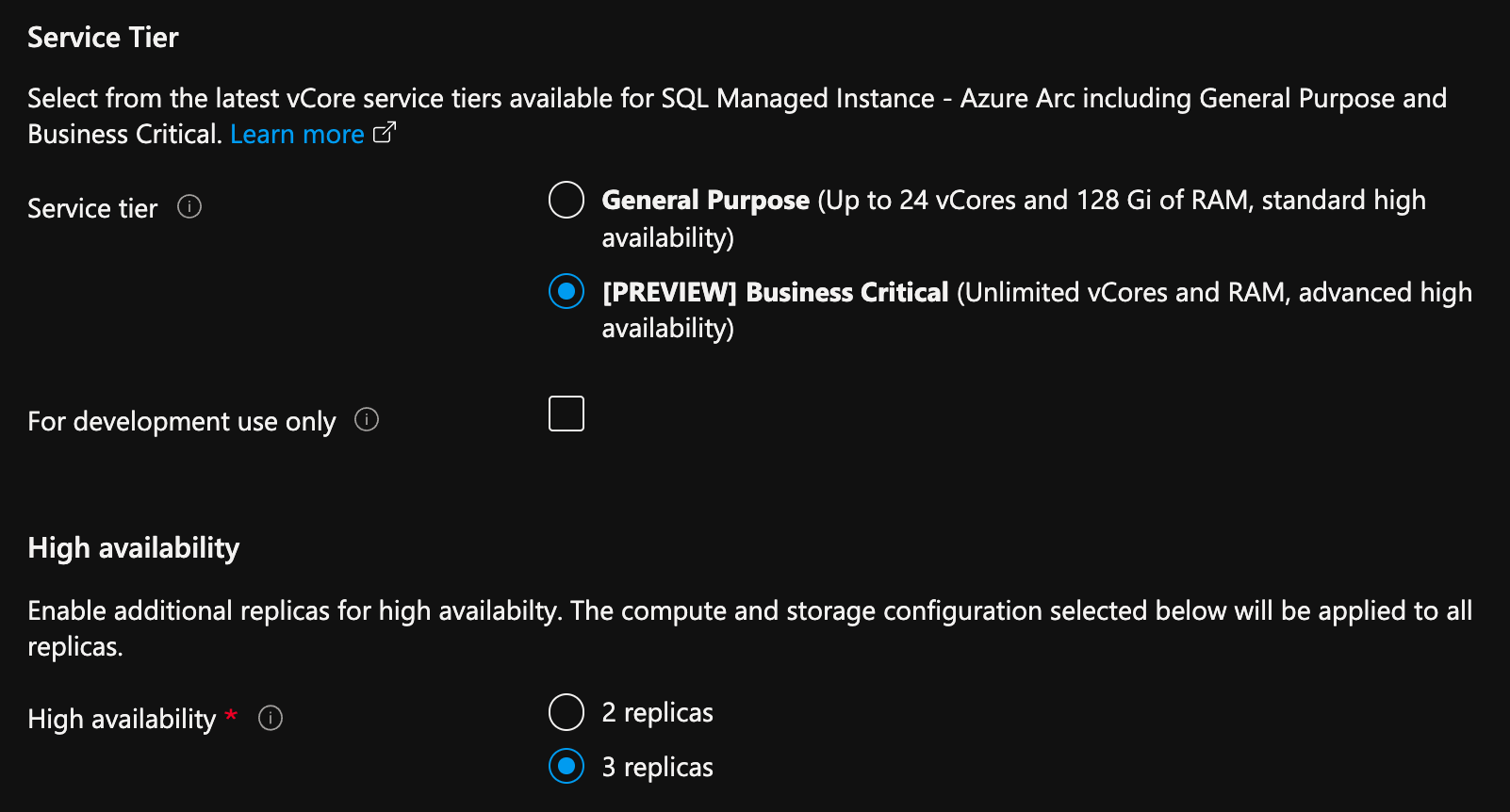
從 Azure 入口網站,在「建立已啟用 Azure Arc 的 SQL 受控執行個體」頁面上:
- 選取 [計算 + 儲存體] 底下的 [設定計算 + 儲存體]。 入口網站會顯示進階設定。
- 在 [服務層級] 底下,選取 [業務關鍵]。
- 如果是用於開發用途,請選取 [僅供開發使用]。
- 在 [高可用性] 底下,選取 [2 個複本] 或 [3 個複本]。
使用 Azure CLI 部署多個複本
在「業務關鍵」服務層級中部署已啟用 Azure Arc 的 SQL 受控執行個體時,部署會建立多個複本。 佈建期間會自動完成在那些執行個體之間安裝及設定自主可用性群組的工作。
例如,下列命令會建立具有 3 個複本的受控執行個體。
間接連接模式:
az sql mi-arc create -n <instanceName> --k8s-namespace <namespace> --use-k8s --tier <tier> --replicas <number of replicas>
範例:
az sql mi-arc create -n sqldemo --k8s-namespace my-namespace --use-k8s --tier BusinessCritical --replicas 3
直接連接模式:
az sql mi-arc create --name <name> --resource-group <group> --location <Azure location> –subscription <subscription> --custom-location <custom-location> --tier <tier> --replicas <number of replicas>
範例:
az sql mi-arc create --name sqldemo --resource-group rg --location uswest2 –subscription xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --custom-location private-location --tier BusinessCritical --replcias 3
根據預設,所有複本都會設定為同步模式。 這表示主要執行個體上的任何更新都會同步複寫至每個次要執行個體。
檢視及監視可用性狀態
在部署完成之後,請從 SQL Server Management Studio 連線至主要端點。
確認並擷取主要複本的端點,並從 SQL Server Management Studio 加以連線。
例如,如果使用 service-type=loadbalancer 部署 SQL 執行個體,請執行下列命令以擷取要連線到的目標端點:
az sql mi-arc list --k8s-namespace my-namespace --use-k8s
或
kubectl get sqlmi -A
取得主要和次要端點和 AG 狀態
使用 kubectl describe sqlmi 或 az sql mi-arc show 命令來檢視主要和次要端點,以及可用性狀態。
範例:
kubectl describe sqlmi sqldemo -n my-namespace
or
az sql mi-arc show --name sqldemo --k8s-namespace my-namespace --use-k8s
範例輸出︰
"status": {
"endpoints": {
"logSearchDashboard": "https://10.120.230.404:5601/app/kibana#/discover?_a=(query:(language:kuery,query:'custom_resource_name:sqldemo'))",
"metricsDashboard": "https://10.120.230.46:3000/d/40q72HnGk/sql-managed-instance-metrics?var-hostname=sqldemo-0",
"mirroring": "10.15.100.150:5022",
"primary": "10.15.100.150,1433",
"secondary": "10.15.100.156,1433"
},
"highAvailability": {
"healthState": "OK",
"mirroringCertificate": "-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----"
},
"observedGeneration": 1,
"readyReplicas": "2/2",
"state": "Ready"
}
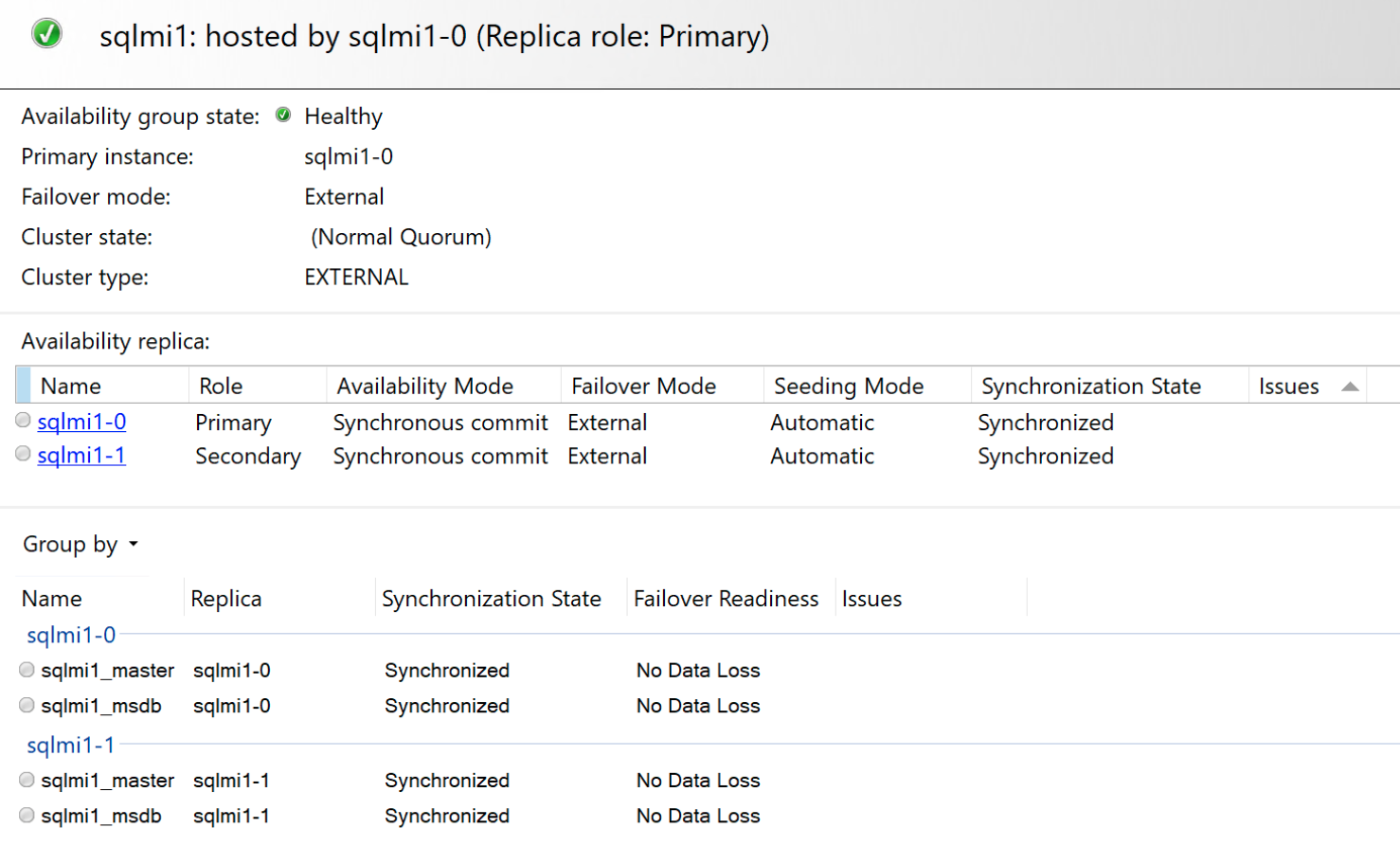
您可以使用 SQL Server Management Studio 連線至主要端點,並確認 DMV 為:
SELECT * FROM sys.dm_hadr_availability_replica_states
以及自主可用性儀表板:
容錯移轉案例
不同於 SQL Server Always On 可用性群組,自主可用性群組是受控的高可用性解決方案。 因此,相較於 SQL Server Always On 可用性群組所提供的一般模式,容錯移轉模式會受到限制。
在兩個複本設定或三個複本設定中部署業務關鍵服務層級 SQL 受控執行個體。 每個設定的失敗影響和後續復原性都有所不同。 三個複本執行個體能提供比兩個複本執行個體更高層級的可用性和復原。
在兩個複本設定中,當兩個節點狀態都是 SYNCHRONIZED 時,如果主要複本變成無法使用,則次要複本會自動升級為主要複本。 當失敗的複本變成可用時,便會為其更新所有暫止的變更。 如果複本之間有連線問題,則主要複本可能不會認可任何交易,因為每個交易都必須在兩個複本上認可,才能將成功狀態傳回主要複本。
在三個複本設定中,交易必須在至少 3 個複本的 2 個複本中認可,才能將成功訊息傳回應用程式。 發生失敗時,在 Kubernetes 嘗試復原失敗的複本時,會自動將其中一個次要複本升級為主要複本。 當複本變成可用時,其會自動與自主可用性群組聯結,並同步處理暫止的變更。 如果複本之間有連線問題,且有超過 2 個複本不同步時,主要複本將不會認可任何異動。
注意
建議在三個複本設定 (而不是在兩個複本設定) 中部署業務關鍵 SQL 受控執行個體,以達到近乎零的資料遺失。
若要從主要複本容錯移轉至其中一個次要複本,針對規劃的事件,請執行下列命令:
如果您連線到主要複本,您可以使用下列 T-SQL 將 SQL 執行個體容錯移轉至其中一個次要複本:
ALTER AVAILABILITY GROUP current SET (ROLE = SECONDARY);
如果您連線到次要複本,您可以使用下列 T-SQL 將所需的次要複本升級為主要複本。
ALTER AVAILABILITY GROUP current SET (ROLE = PRIMARY);
慣用的主要複本
您也可以使用 AZ CLI 將特定複本設定為主要複本,如下所示:
az sql mi-arc update --name <sqlinstance name> --k8s-namespace <namespace> --use-k8s --preferred-primary-replica <replica>
範例:
az sql mi-arc update --name sqldemo --k8s-namespace my-namespace --use-k8s --preferred-primary-replica sqldemo-3
注意
Kubernetes 會嘗試設定慣用的複本,但並不保證。
將資料庫還原到多複本執行個體
若要將資料庫還原到可用性群組,還需要執行其他步驟。 下列步驟示範如何將資料庫還原到受控執行個體,並將其新增至可用性群組。
建立新的 Kubernetes 服務來公開主要執行個體外部端點。
判斷裝載主要複本的 Pod。 連線至受控執行個體並執行:
SELECT @@SERVERNAME查詢會傳回裝載主要複本的 Pod。
若您的 Kubernetes 叢集使用
NodePort服務,請執行下列命令以將 Kubernetes 服務建立至主要執行個體。 將<podName>取代為上一個步驟所傳回的伺服器名稱、將<serviceName>取代為所建立 Kubernetes 服務的慣用名稱。kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePort針對 LoadBalancer 服務,請執行相同的命令,但所建立的服務類型會是
LoadBalancer。 例如:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancer以下是這個命令針對 Azure Kubernetes Service 執行的範例,其中裝載主要複本的 Pod 是
sql2-0:kubectl -n arc-cluster expose pod sql2-0 --port=1533 --name=sql2-0-p --type=LoadBalancer取得所建立 Kubernetes 服務的 IP:
kubectl get services -n <namespaceName>將資料庫還原至主要執行個體端點。
將資料庫備份檔案新增至主要執行個體容器。
kubectl cp <source file location> <pod name>:var/opt/mssql/data/<file name> -c <serviceName> -n <namespaceName>範例
kubectl cp /home/WideWorldImporters-Full.bak sql2-1:var/opt/mssql/data/WideWorldImporters-Full.bak -c arc-sqlmi -n arc執行下列命令來還原資料庫備份檔案。
RESTORE DATABASE test FROM DISK = '/var/opt/mssql/data/<file name>.bak' WITH MOVE '<database name>' to '/var/opt/mssql/data/<file name>.mdf' ,MOVE '<database name>' to '/var/opt/mssql/data/<file name>_log.ldf' ,RECOVERY, REPLACE, STATS = 5; GO範例
RESTORE Database WideWorldImporters FROM DISK = '/var/opt/mssql/data/WideWorldImporters-Full.BAK' WITH MOVE 'WWI_Primary' TO '/var/opt/mssql/data/WideWorldImporters.mdf', MOVE 'WWI_UserData' TO '/var/opt/mssql/data/WideWorldImporters_UserData.ndf', MOVE 'WWI_Log' TO '/var/opt/mssql/data/WideWorldImporters.ldf', MOVE 'WWI_InMemory_Data_1' TO '/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1', RECOVERY, REPLACE, STATS = 5; GO將資料庫新增至可用性群組。
若要將資料庫新增至 AG,必須以完整復原模式加以執行,且必須擷取記錄備份。 執行下方的 TSQL 陳述式,以將還原的資料庫新增至可用性群組。
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>下列範例會新增已在執行個體上還原的資料庫
WideWorldImporters:ALTER DATABASE WideWorldImporters SET RECOVERY FULL; BACKUP DATABASE WideWorldImporters TO DISK='/var/opt/mssql/data/WideWorldImporters.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE WideWorldImporters
重要
作為最佳做法,您應該執行下列命令來刪除上面所建立的 Kubernetes 服務:
kubectl delete svc sql2-0-p -n arc
限制
已啟用 Azure Arc 的 SQL 受控執行個體可用性群組具有與巨量資料叢集可用性群組相同的限制。 如需詳細資訊,請參閱部署高可用性 SQL Server 巨量資料叢集。
相關內容
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應