Azure Durable Functions 中的災害復原和地理分散
Microsoft 致力於確保 Azure 服務皆能持續可用。 不過仍然可能會發生計畫外的服務中斷。 如果您的應用程式需要復原功能,Microsoft 建議您設定應用程式以進行異地備援。 此外,客戶應該要建立災害復原計畫來處理區域服務中斷。 災害復原計劃相當重要的一部分,是準備在主要複本變得無法使用的情況下,容錯移轉到您應用程式和儲存體的次要複本。
在 Durable Functions 中,所有狀態預設均保存於 Azure 儲存體中。 工作中樞是協調流程和實體所使用之 Azure 儲存體資源的邏輯容器。 只有在協調器、活動及實體函式都屬於相同的工作中樞時,才能彼此互動。 此文件將在描述讓這些 Azure 儲存體資源保持高可用性的案例時參考工作中樞。
注意
此文章中的指導方針假設您使用預設 Azure 儲存體提供者,來儲存 Durable Functions 執行階段狀態。 不過,您可以設定在他處儲存狀態的替代儲存體提供者,例如 SQL Server 資料庫。 您可能需要針對替代儲存體提供者提供不同的災害復原和地理分散策略。 如需替代儲存提供者的詳細資訊,請參閱 Durable Functions 儲存體提供者文件。
協調流程和實體可以使用用戶端函式來觸發,這類函式本身可透過 HTTP 或其中一個支援的其他 Azure Functions 觸發程序類型來觸發。 您也可以使用內建的 HTTP API 來加以觸發。 為了簡單起見,此文章將著重於涉及 Azure 儲存體和 HTTP 型函式觸發程序的案例,以及增加可用性且可將災害復原活動期間的停機時間降到最低的選項。 我們將不會明確涵蓋其他觸發程序類型,例如服務匯流排或 Azure Cosmos DB 觸發程序。
下列案例是以主動-被動設定為基礎,因為其是以 Azure 儲存體的使用量為依據。 此模式包含將備份 (被動) 函式應用程式部署至不同的區域。 流量管理員將監視主要 (主動) 函數應用程式的 HTTP 可用性。 它會在主要函式應用程式失敗時,容錯移轉至備份函式應用程式。 如需詳細資訊,請參閱 Azure 流量管理員的優先順序流量路由方法。
注意
- 提議的主動-被動組態可確保用戶端永遠能透過 HTTP 觸發新的協調流程。 不過,作為讓兩個函數應用程式在儲存體中共用相同工作中樞的結果,將會在這兩者之間散發一些背景儲存體交易。 因此,此設定會讓次要函數應用程式產生一些額外的輸出成本。
- 基礎儲存體帳戶和工作中樞均建立於主要區域中,並由兩個函式應用程式所共用。
- 在透過 HTTP 啟用的情況下,所有重複部署的函數應用程式都必須共用相同的函式存取金鑰。 Functions 執行階段會公開管理 API ,讓取用者能以程式設計方式新增、刪除和更新功能鍵。 您也可以使用 Azure Resource Manager API (英文) 來管理金鑰。
案例 1 - 具有共用儲存體的負載平衡計算
如果 Azure 中的計算基礎結構失敗,函式應用程式可能會無法使用。 為了將這類停機的可能性降到最低,此案例會使用部署到不同區域的兩個函式應用程式。 流量管理員已設定為要偵測主要函式應用程式中的問題,並自動將流量重新導向至次要區域中的函式應用程式。 此函式應用程式會共用相同的 Azure 儲存體帳戶和工作中樞。 因此,函式應用程式的狀態並未遺失,而且工作可以正常繼續。 一旦健康情況還原到主要區域,Azure 流量管理員就會自動啟動對該函式應用程式的路由要求。
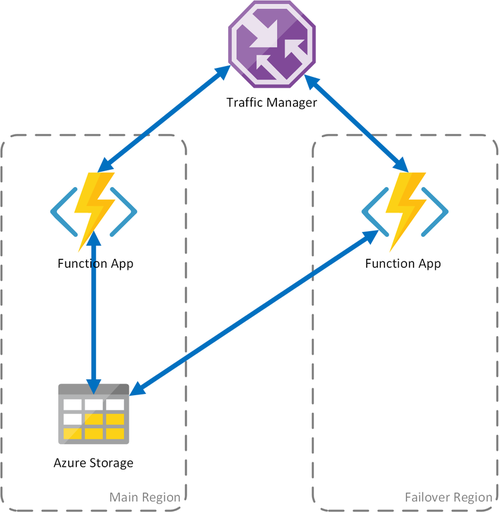
使用此部署案例時有幾個好處:
- 如果計算基礎結構失敗,工作能夠在容錯移轉區域中繼續,而不會遺失資料。
- 流量管理員會自動負責自動容錯移轉至狀況良好的函數應用程式。
- 流量管理員會在中斷情況解決之後,自動重新建立對主要函式應用程式的流量。
不過,使用此案例時,請考慮:
- 如果使用專用的 App Service 方案部署函數應用程式,則在容錯移轉資料中心中複寫計算基礎結構會增加成本。
- 此案例涵蓋計算基礎結構的中斷,但儲存體帳戶仍然會是函式應用程式的單一失敗點。 如果發生儲存體中斷,應用程式就會遭遇停機狀況。
- 如果已容錯移轉函式應用程式,則會增加延遲時間,因為它會跨區域存取其儲存體帳戶。
- 從不同的所在區域存取儲存體服務,會因為網路傳出流量而造成較高的成本。
- 此案例取決於流量管理員。 考量到流量管理員的運作方式,在取用 Durable Function 的用戶端應用程式需要從流量管理員再次查詢函式應用程式位址之前,可能會經過一些時間。
注意
從 Durable Functions 延伸模組 v2.3.0 開始,可以使用相同的儲存體帳戶和工作中樞設定,同時安全地執行兩個函數應用程式。 第一個啟動的應用程式將取得應用程式層級的 Blob 租用,以防止其他應用程式從工作中樞佇列中竊取訊息。 如果第一個應用程式停止執行,其租用將會過期且可由第二個應用程式取得,其將會繼續處理工作中樞訊息。
在 v2.3.0 之前,設定為使用相同儲存體帳戶的函數應用程式將同時處理訊息和更新儲存體成品,因而產生更高的整體延遲和輸出成本。 如果未來對主要和複本應用程式部署不同的程式碼 (即使是暫時),則協調流程也可能因為協調器函式在這兩個應用程式中不一致而無法正確執行。 因此,建議所有基於災害復原目的需要進行地理分散的應用程式,都使用 v2.3.0 或更高版本的 Durable 延伸模組。
案例 2 - 具有區域性儲存體的負載平衡計算
先前的案例只涵蓋計算基礎結構中的失敗案例。 如果儲存體服務失敗,它會導致函式應用程式中斷。 為了確保 Durable Functions 能夠連續作業,此案例會使用已部署函式應用程式的每個區域的本機儲存體帳戶。
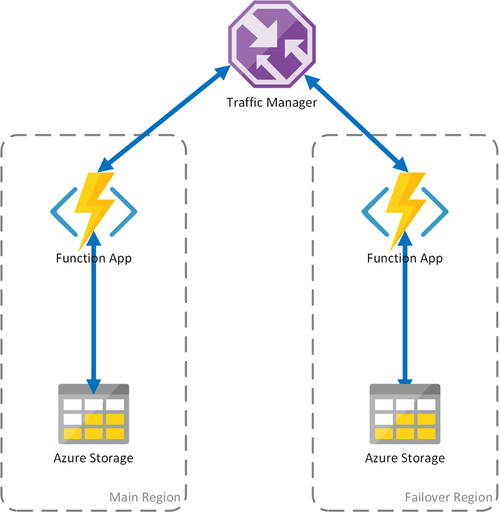
這種方法可改善前一個案例:
- 如果函式應用程式失敗,則流量管理員會負責容錯移轉到次要區域。 不過,因為函式應用程式依賴自己的儲存體帳戶,所以 Durable Functions 會繼續運作。
- 在容錯移轉期間,因為函數應用程式與儲存體帳戶共置,所以容錯移轉區域中不會有額外的延遲。
- 儲存層失敗將導致 Durable Functions 中發生失敗,進而觸發重新導向容錯移轉區域。 同樣地,因為函式應用程式和儲存體依區域隔離,所以 Durable Functions 會繼續運作。
此案例的重要考量:
- 如果使用專用的 App Service 方案部署函數應用程式,則在容錯移轉資料中心中複寫計算基礎結構會增加成本。
- 目前的狀態不會容錯移轉,這表示在主要區域復原之前,現有的協調流程和實體將會暫停且無法使用。
總言之,第一個和第二個案例之間的取捨是能夠保留延遲並將輸出成本降至最低,但在停機期間將無法使用現有的協調流程和實體。 這些取捨是否可接受,取決於應用程式的需求。
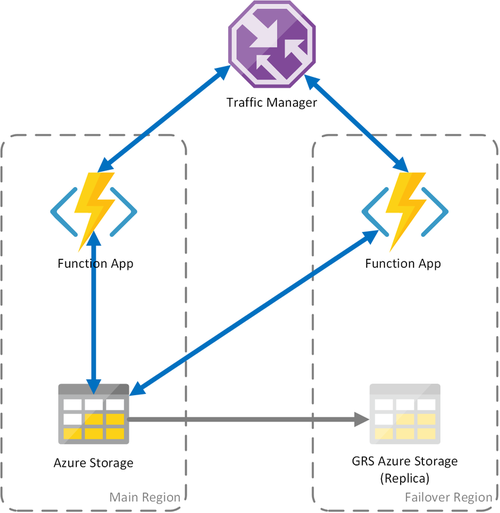
案例 3 - 具有 GRS 共用儲存體的負載平衡計算
此案例是修改自第一個案例,並實作共用儲存體帳戶。 主要差異在於建立的儲存體帳戶已啟用異地複寫。 在功能上,此案例提供與案例 1 相同的優點,但它還有額外的資料復原優點:
- 異地備援儲存體 (GRS) 和讀取權限異地備援儲存體 (RA-GRS) 可為儲存體帳戶提供最大的可用性。
- 如果儲存體服務發生區域性中斷,您可以手動起始容錯移轉至次要複本。 在區域因嚴重災害而遺失的極端情況下,Microsoft 可能會起始區域容錯移轉。 在此情況下,您不需要採取任何動作。
- 發生容錯移轉時,Durable Functions 的狀態將保留為儲存體帳戶的最後一次複寫 (通常每隔幾分鐘會發生一次) 的狀態。
如同其他案例,此案例有一些重要考量:
- 容錯移轉至複本可能需要一些時間。 在容錯移轉完成且 Azure 儲存體 DNS 記錄更新之前,函數應用程式將遭遇中斷。
- 使用異地複寫儲存體帳戶的成本於是增加。
- GRS 複寫會以非同步方式複製您的資料。 有些最新交易可能會因為複寫程序延遲而遺失。
注意
如案例 1 中所述,強烈建議使用此策略部署的函數應用程式使用 v2.3.0 或更高版本的 Durable Functions 延伸模組。
如需詳細資訊,請參閱 Azure 儲存體的災害復原和儲存體帳戶容錯移轉文件。