Azure SQL 中的加速資料庫復原
適用於:![]() Azure SQL 資料庫
Azure SQL 資料庫 ![]() Azure SQL 受控執行個體
Azure SQL 受控執行個體
加速資料庫復原 (ADR) 是一項 SQL Server 資料庫引擎功能,透過重新設計 SQL Server 的資料庫引擎復原處理程序來大幅提升資料庫可用性,尤其是長時間執行的交易。
ADR 目前可用於 Azure SQL 資料庫、Azure SQL 受控執行個體、Azure Synapse Analytics 中的資料庫,以及 Azure VM 上的 SQL Server (從 SQL Server 2019 開始)。 如需 SQL Server 中 ADR 的相關資訊,請參閱管理加速資料庫復原。
注意
Azure SQL 資料庫和 Azure SQL 受控執行個體預設會啟用 ADR。 Azure SQL 資料庫和 Azure SQL 受控執行個體不支援停用 ADR。
概觀
ADR 的主要優點為:
快速且一致的資料庫復原
使用 ADR,長時間執行的交易便不會影響整體復原時間,可快速且一致地進行資料庫復原,不論系統內使用中的交易數或其大小為何。
瞬間交易回復
使用 ADR,交易回復會在瞬間完成,不論交易處於使用中狀態的時間長度,或是已執行的更新數為何。
積極性記錄截斷
使用 ADR,交易記錄會積極地進行截斷,即使有使用中的長時間執行交易,它也能防止其失去控制。
標準資料庫復原處理程序
資料庫復原遵循 ARIES 復原模型且由三個階段組成,如下圖所示,圖表之後的文字進行了更詳細地說明。
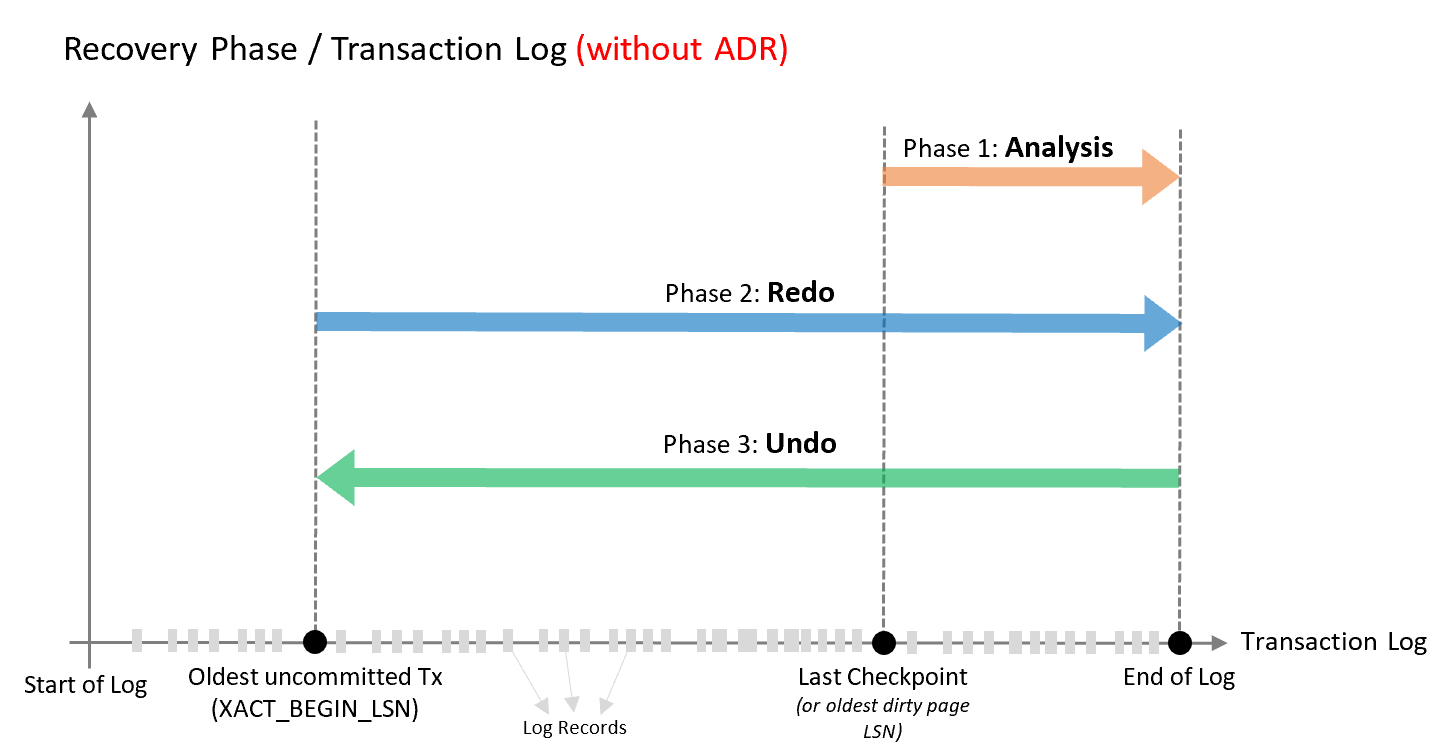
分析階段
從最後一次成功的檢查點 (或是最舊的中途分頁 LSN) 的開頭順向掃描交易記錄至結尾,以判斷資料庫停止時每個交易的狀態。
重做階段
從最舊的未提交交易開始,順向掃描交易記錄至結尾,藉由重做所有已提交的作業,讓資料庫回到當機時的狀態。
復原階段
針對當機時處於使用中狀態的每個交易,向後周遊記錄,復原此交易所執行的作業。
根據這項設計,SQL Server 資料庫引擎從非預期重新啟動復原所需時間 (大約) 會和當機時系統中時間最長之作用中交易的大小成比例。 復原需要回復所有未完成的交易。 所需時間與交易執行的工作和其已使用時間成比例。 因此,在有長時間執行的交易 (例如大量插入作業或針對大型資料表的索引建置作業) 時,SQL Server 復原處理程序可能需要相當長的時間才能完成。
此外,根據此設計,取消大型交易也可能會耗費相當長的時間,因為它會使用與上述相同的撤銷復原階段。
此外,SQL Server 資料庫引擎在有長時間執行交易時無法截斷交易記錄,因為復原和回復處理程序需要它們對應的記錄檔記錄。 由於此 SQL Server 資料庫引擎的設計,一些客戶過去常常面臨的問題是交易記錄的大小變得非常大,佔用了大量的磁碟機空間。
加速資料庫復原處理程序
ADR 藉由完全重新設計 SQL Server 資料庫引擎的復原處理程序來解決上述問題:
- 透過避免從最舊使用中交易的開頭進行掃描,或是掃描至開頭,來固定時間或使其能夠立即完成。 使用 ADR,只會從最後一次成功的檢查點 (或是最舊的中途分頁記錄序號 [LSN]) 開始處理交易記錄。 因此,復原時間不會受到長時間執行的交易影響。
- 將所需的交易記錄空間減至最小,因為不再需要處理整個交易的記錄。 因此,可在進行檢查點和備份時積極地截斷交易記錄。
從高層級而言,ADR 會透過對所有實體資料庫修改建立版本,並只復原邏輯作業 (其數量有限且可以立即進行復原) 來快速地進行資料庫復原。 任何在當機時處於使用中狀態的交易都會標記為中止,因此並行使用者查詢可以略過任何由這些交易產生的版本。
ADR 復原處理序與目前復原處理序具有相同的三個階段。 這些階段與 ADR 運作的方式如下圖所示,圖表之後的文字進行了更詳細地解釋。
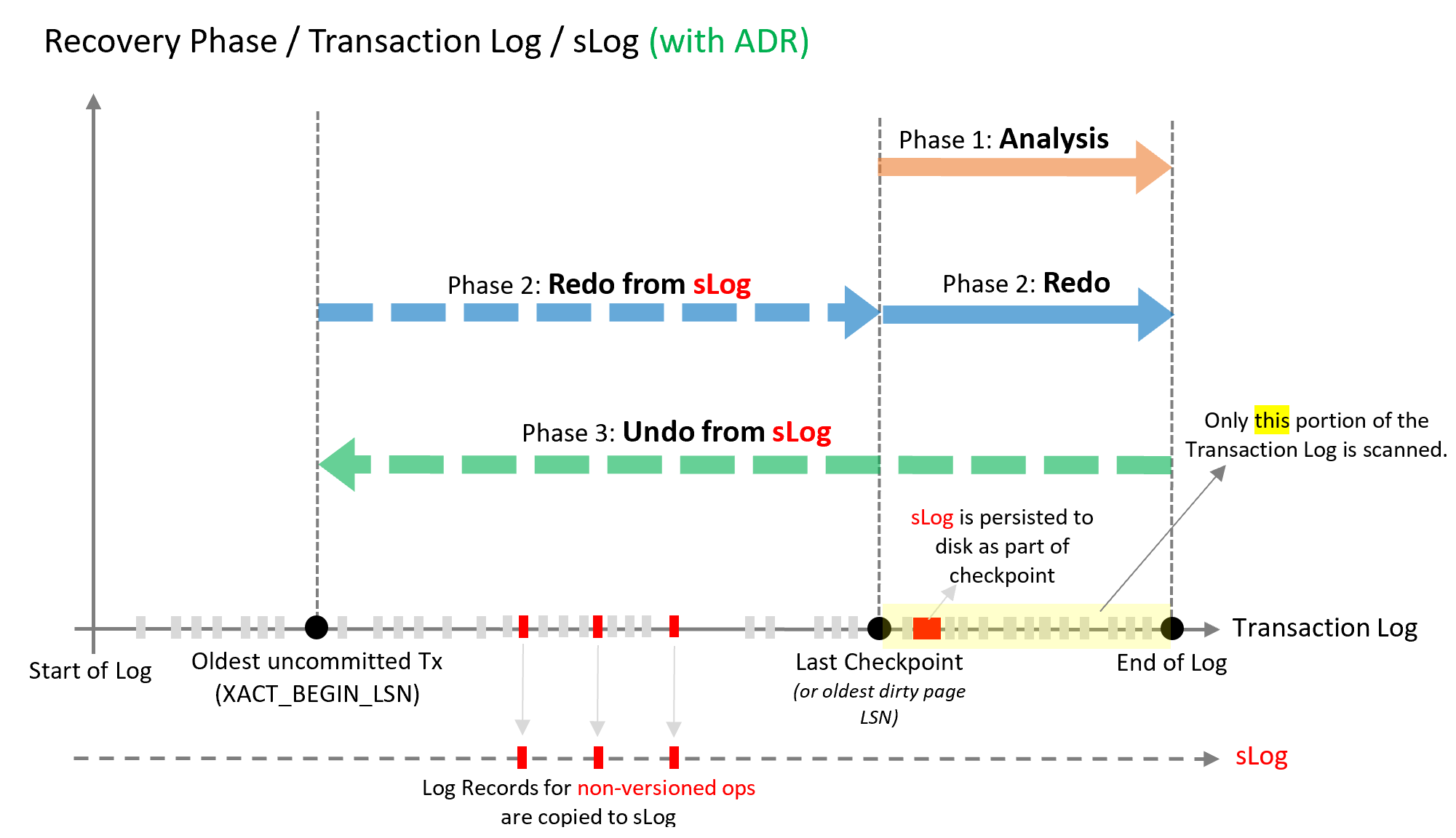
分析階段
該處理程序與之前的處理程序相同,但會另外重新建構 SLOG 並複製未建立版本作業的記錄檔記錄。
重做階段
分為兩個階段 (P)
階段 1
從 SLOG 重做 (最舊的未認可交易至最後一個檢查點)。 重做是快速的作業,因為只需要處理來自 SLOG 的幾個記錄。
階段 2
從最後一個檢查點 (而非最舊的未認可交易) 開始自交易記錄重做
復原階段
使用 ADR 的復原階段會搭配邏輯還原來使用 SLOG 以復原未建立版本的作業及持續版本存放區 (PVS),以幾乎立即的方式來完成執行資料列版本式復原。
ADR 復原元件
ADR 的四個關鍵元件為:
持續版本存放區 (PVS)
持續版本存放區是一種新的 SQL Server 資料庫引擎機制,用於保存資料庫本身產生的資料列版本,而非傳統的
tempdb版本存放區。 PVS 可隔離資源並改善可讀取次要的可用性。邏輯還原
邏輯還原是非同步的處理程序,負責執行資料列層級版本式復原,為所有建立版本的作業提供即時的交易回復和復原。 邏輯還原的實現方式如下:
- 追蹤所有中止的交易,並將其標記為對其他交易隱藏。
- 針對所有使用者交易使用 PVS 執行復原,而不是逐個掃描交易記錄並撤銷更改。
- 在交易中止後立即釋出所有鎖定。 由於中止只涉及標記記憶體中的變更,因此該處理程序非常高效,不需要長時間保持鎖定。
SLOG
SLOG 是一種次要的記憶體內部記錄資料流,可儲存未建立版本作業的記錄檔記錄 (例如中繼資料快取無效判定、取得鎖定等)。 SLOG 是:
- 體積小並位於記憶體內部
- 透過在檢查點處理序期間進行序列化來保存在磁碟上
- 在交易認可時定期截斷
- 透過只處理未建立版本的作業來加速重做和復原
- 透過只保留需要的記錄檔記錄來啟用積極性交易記錄截斷
清除工具
清除工具是一種非同步處理序,會定期喚醒並清理不需要的分頁版本。
加速資料庫復原 (ADR) 模式
以下類型的工作負載最能從 ADR 中受益:
- 建議對長時間執行的交易使用 ADR。
- 針對曾經歷使用中交易造成交易記錄大幅成長的工作負載,建議使用 ADR。
- 若因長時間執行復原 (例如非預期的重新啟動或手動交易回復) 而導致工作負載長期無法使用資料庫,則建議使用 ADR。
加速資料庫復原的最佳做法
避免在資料庫中執行長時間交易。 儘管 ADR 的目標之一是加速因重做長時間活動交易而導致的資料庫復原,但長時間執行的交易可能會延遲版本清理並增大 PVS 的大小。
使用資料定義變更或 DDL 作業來避免大型交易。 ADR 會使用 SLOG (系統記錄檔資料流) 機制來追蹤復原時所使用的 DDL 作業。 僅在交易處於使用中時,才會使用 SLOG。 SLOG 具有檢查點,因此避免使用 SLOG 的大型交易可協助改善整體效能。 這些案例可能會導致 SLOG 佔用更多空間:
多個 DDL 皆是在一個交易中執行。 例如,在一個交易中執行快速建立和卸除暫存資料表。
資料表中包含大量已修改的資料分割/索引。 例如,在這類資料表上的 DROP TABLE (卸除資料表) 作業需要大量的 SLOG 記憶體保留,這會延遲截斷交易記錄,並延遲復原/重做作業。 您可採用因應措施,個別並漸進刪除索引,然後刪除資料表。 如需有關 SLOG 的詳細資訊,請參閱 ADR 復原元件。
避免或減少不必要的中止狀況。 高中止率會影響 PVS 清除工具並造成較低的 ADR 效能。 中止的原因可能源自高比率的鎖死、重複的索引鍵或其他條件約束違規。
sys.dm_tran_aborted_transactionsDMV 會顯示 SQL Server 執行個體上的所有已中止交易。nested_abort資料行表示交易已認可,但部分交易已中止 (儲存點或巢狀交易),這可能會封鎖 PVS 清除程序。 如需詳細資訊,請參閱 sys.dm_tran_aborted_transactions (Transact-SQL)。若要在工作負載之間或維護期間手動啟動 PVS 清除程序,請使用
sys.sp_persistent_version_cleanup。 如需詳細資訊,請參閱 sys.sp_persistent_version_cleanup。
若發現問題,無論是儲存體使用方式、高中止交易與其他因素,請參閱針對 SQL Server 上的加速資料庫復原 (ADR) 進行疑難排解。