適用於:![]() Azure SQL 資料庫
Azure SQL 資料庫
本文說明 Azure SQL Database 中資料庫的不同儲存空間類型。 雖然不常見,但本文包含可在需要明確管理已分配的檔案空間時所採取的步驟。
概觀
在 Azure SQL Database 的某些工作負載模式中,資料庫的基礎資料檔案配置可能會逐漸大於已使用資料頁數。 當使用的空間增加,之後卻將資料刪除時,就會發生這種狀況。 原因是因為在資料刪除後,並不會自動回收已配置的檔案空間。
在下列情況中,可能需要監視檔案空間使用量和壓縮資料檔案:
- 當配置給資料庫的檔案空間達到集區大小上限時,允許彈性集區中的資料空間成長。
- 允許減少單一資料庫或彈性集區的大小上限。
- 允許將單一資料庫或彈性集區變更為大小上限較低的不同服務層級或效能層級。
注意
壓縮作業不應視為一般維修作業。 因定期商務作業成長的資料和記錄檔,不需要壓縮作業。
監視檔案空間使用量
下列 API 顯示的多數儲存體空間計量,只會測量已使用的資料頁面大小:
- Azure Resource Manager 型計量 API 包括 PowerShell get-metrics
不過,下列 API 也會測量配置給資料庫和彈性集區的空間大小:
- T-SQL:sys.resource_stats
- T-SQL:sys.elastic_pool_resource_stats
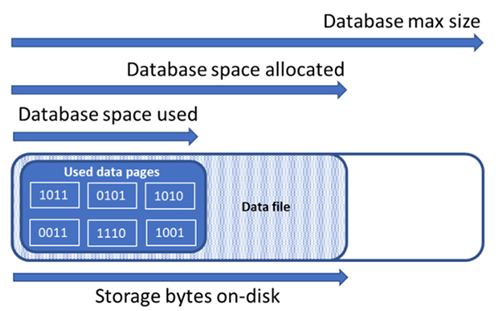
了解資料庫的儲存體空間類型
要管理資料庫的檔案空間,務必要了解下列儲存體空間數量。
| 資料庫數量 | 定義 | 註解 |
|---|---|---|
| 已使用的資料空間 | 用來儲存資料庫資料的空間量。 | 一般而言,使用的空間會在插入 (刪除) 時增加 (減少)。 在某些情況下,根據作業與任何分割中涉及的資料量和模式而定,使用的空間並不會隨插入或刪除而變更。 例如,從每個資料頁刪除一個資料列,不見得會減少使用的空間。 |
| 已配置的資料空間 | 可用以儲存資料庫資料的格式化檔案空間量。 | 配置的空間量會自動成長,但絕不會在刪除後減少。 此行為可確保未來能更快地插入,因為不需要重新格式化空間。 |
| 已配置但未使用的資料空間 | 已配置的資料空間量與已使用的資料空間之間的差異。 | 此數量代表可藉由壓縮資料檔案而回收的可用空間量上限。 |
| 資料大小上限 | 可用來儲存資料庫資料的空間量上限。 | 配置的資料空間量不得成長超過資料大小上限。 |
下圖說明資料庫的不同儲存體空間類型之間的關聯性。
**
查詢單一資料庫來取得檔案空間資訊
使用 sys.database_files 上的下列查詢,以傳回已配置的資料庫檔案空間量與已配置但未使用的空間量。 查詢結果以 MB 為單位。
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
了解彈性集區的儲存體空間類型
要管理彈性集區的檔案空間,務必要了解下列儲存體空間數量。
| 彈性集區數量 | 定義 | 註解 |
|---|---|---|
| 已使用的資料空間 | 彈性集區中的所有資料庫所使用的資料空間總和。 | |
| 已配置的資料空間 | 彈性集區中的所有資料庫所配置的資料空間總和。 | |
| 已配置但未使用的資料空間 | 已配置的資料空間量與彈性集區中的所有資料庫已使用的資料空間之間的差異。 | 此數量代表為彈性集區配置的最大空間量,該空間可藉由縮小資料庫資料檔案來回收。 |
| 資料大小上限 | 彈性池所用於所有資料庫的最大資料空間。 | 為彈性集區配置的空間不應超過彈性集區大小上限。 如果發生此狀況,則可藉由壓縮資料庫資料檔案來回收已配置但未使用的空間。 |
注意
錯誤訊息「彈性集區的儲存空間已達上限」表示資料庫物件使用的空間已達彈性集區的儲存限制。 考慮增加儲存限制,或作為短期解決方案,利用 Reclaim 未使用的分配空間中的樣本釋放資料空間。 您也應該注意壓縮資料庫檔案的潛在負面影響。 請參閱壓縮後 索引維護。
查詢彈性集區,以取得儲存體空間資訊
下列查詢可用來判斷彈性集區的儲存體空間數量。
使用的彈性集區資料空間
修改下列查詢,以傳回已使用的彈性集區資料空間量。 查詢結果以 MB 為單位。
-- Connect to master
-- Elastic pool data space used in MB
SELECT TOP 1 avg_storage_percent / 100.0 * elastic_pool_storage_limit_mb AS ElasticPoolDataSpaceUsedInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
配置的彈性集區資料空間與已配置但未使用的空間
修改以下範例,回傳一個列出彈性池中每個資料庫總分配空間與未使用空間的表格。 該表格會將資料庫從未使用空間最多的資料庫排序到未使用空間最少的資料庫。 查詢結果以 MB 為單位。
將池中每個資料庫的查詢結果相加,以確定彈性池的總分配空間。 彈性池分配的空間不應超過彈性池的最大尺寸。
重要
PowerShell Azure Resource Manager (AzureRM) 模組已於 2024 年 2 月 29 日淘汰。 所有未來的開發都應該使用 Az.Sql 模組。 建議使用者從 AzureRM 遷移至 Az PowerShell 模組,以確保持續支援和更新。 不再維護或支援 AzureRM 模組。 Az PowerShell 模組和 AzureRM 模組中命令的自變數基本上完全相同。 如需相容性的詳細資訊,請參閱 新 Az PowerShell 模組簡介。
PowerShell 腳本需要 SQL Server PowerShell 模組。 如需詳細資訊,請參閱 SQL Server PowerShell 模組。
下列 PowerShell 腳本會完成下列步驟:
- 宣告變數。 以您的值取代這些值。
- 取得彈性集區中的資料庫列表。
- 對於彈性池中的每個資料庫,取得總分配空間(MB)和已分配但未使用的空間(MB)。
- 依未使用配置空間的遞減順序顯示資料庫。
$resourceGroupName = "<resourceGroupName>"
$serverName = "<serverName>"
$poolName = "<poolName>"
$userName = "<userName>"
$password = "<password>"
# get list of databases in elastic pool
$databasesInPool = Get-AzSqlElasticPoolDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName -ElasticPoolName $poolName
$databaseStorageMetrics = @()
# for each database in the elastic pool, get the total allocated space in MB and the allocated but unused space in MB
foreach ($database in $databasesInPool) {
$sqlCommand = "SELECT DB_NAME() as DatabaseName, `
SUM(size/128.0) AS DatabaseDataSpaceAllocatedInMB, `
SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0) AS DatabaseDataSpaceAllocatedUnusedInMB `
FROM sys.database_files `
GROUP BY type_desc `
HAVING type_desc = 'ROWS'"
$serverFqdn = "tcp:" + $serverName + ".database.windows.net,1433"
$databaseStorageMetrics = $databaseStorageMetrics +
(Invoke-Sqlcmd -ServerInstance $serverFqdn -Database $database.DatabaseName `
-Username $userName -Password $password -Query $sqlCommand)
}
# display databases in descending order of unused allocated space
Write-Output "`n" "ElasticPoolName: $poolName"
Write-Output $databaseStorageMetrics | Sort -Property DatabaseDataSpaceAllocatedUnusedInMB -Descending | Format-Table
下列螢幕擷取畫面是指令碼輸出的其中一個範例:

彈性集區資料大小上限
修改下列 T-SQL 查詢,傳回上次記錄的彈性集區資料大小上限。 查詢結果以 MB 為單位。
-- Connect to master
-- Elastic pools max size in MB
SELECT TOP 1 elastic_pool_storage_limit_mb AS ElasticPoolMaxSizeInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
回收未使用的配置空間
重要
壓縮命令會在資料庫執行時影響其效能,如果可能,應該在低使用量期間執行。
壓縮資料檔案
由於可能會對資料庫效能造成影響,因此 Azure SQL Database 不會自動壓縮資料檔案。 但客戶可以隨時選擇自行壓縮資料檔案。 縮減不應是定期排程的操作,而是一次性事件,回應資料檔案使用空間大幅減少。
提示
如果一般應用程式負載導致檔案又變回原本的大小,就別浪費時間縮減資料檔案。 檔案成長事件可能會對應用程式效能造成負面影響。
在 Azure SQL Database 中,若要壓縮檔案,您可以使用 DBCC SHRINKDATABASE 或 DBCC SHRINKFILE 命令:
-
DBCC SHRINKDATABASE使用單一命令壓縮資料庫所有的資料和記錄檔。 此命令會一次壓縮一個資料檔案,所以較大的資料庫可能需要較長的時間。 此命令也可壓縮記錄檔,但這通常不是必要措施,因為 Azure SQL Database 會視需要自動壓縮記錄檔。 -
DBCC SHRINKFILE命令支援更進階的案例:- 此命令可視需要壓縮個別檔案,而不是壓縮資料庫所有的檔案。
- 每個
DBCC SHRINKFILE命令都可以與其他DBCC SHRINKFILE命令平行執行,以同時壓縮多個檔案並減少壓縮的總時間,然而在壓縮期間同時執行這些命令,會造成較高的資源使用量,並可能會封鎖使用者查詢。- 同時壓縮多個資料檔可讓您更快速地完成壓縮作業。 如果您使用並行資料檔壓縮功能,可能會發現一個壓縮請求會暫時阻塞另一個壓縮請求。
- 如果檔案結尾不包含數據,則可以藉由指定
TRUNCATEONLY自變數,更快速地減少配置的檔案大小。TRUNCATEONLY不需要在檔案內移動資料。
- 如需這些壓縮命令的詳細資訊,請參閱 DBCC SHRINKDATABASE 和 DBCC SHRINKFILE。
下列範例必須在連線至目標使用者資料庫時執行,而不是在連線至 master 資料庫時執行。
若要使用 DBCC SHRINKDATABASE 壓縮指定資料庫所有的資料和記錄檔:
-- Shrink database data space allocated.
DBCC SHRINKDATABASE (N'database_name');
在 Azure SQL 資料庫中,資料庫可能會有一或多個資料檔案,隨著資料成長自動建立。 若要判斷資料庫的檔案配置,包括每個檔案已使用和配置的大小,請使用下列範例指令碼來查詢 sys.database_files 目錄檢視:
-- Review file properties, including file_id and name values to reference in shrink commands
SELECT file_id,
name,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_file_size_mb
FROM sys.database_files
WHERE type_desc IN ('ROWS','LOG');
您只能透過 DBCC SHRINKFILE 命令,執行單一檔案的壓縮,例如:
-- Shrink database data file named 'data_0` by removing all unused at the end of the file, if any.
DBCC SHRINKFILE ('data_0', TRUNCATEONLY);
GO
請注意壓縮資料庫檔案的潛在負面影響。 如需詳細資訊,請參閱縮小後的 索引維護。
壓縮交易記錄檔
不同於資料檔案,Azure SQL Database 會自動壓縮交易記錄檔,以避免可能導致空間不足錯誤的過度空間使用量。 大多數情況下,你不需要縮小交易日誌檔案。
在進階和業務關鍵服務層級中,如果交易記錄變大,可能會大為增加本機儲存體的耗用量,達到最大本機儲存體的限制。 如果本機儲存體耗用量接近限制,客戶可以選擇使用下列範例所示的 DBCC SHRINKFILE 命令,壓縮交易記錄。 命令完成後便會立即釋出本機儲存體,而不必等待定期自動壓縮作業。
下列範例必須在連線至目標使用者資料庫時執行,而不是在連線至 master 資料庫時執行。
-- Shrink the database log file (always file_id 2), by removing all unused space at the end of the file, if any.
DBCC SHRINKFILE (2, TRUNCATEONLY);
自動壓縮
資料庫可啟用自動壓縮,做為手動壓縮資料檔案的替代方法。 不過,自動壓縮比起 DBCC SHRINKDATABASE 和 DBCC SHRINKFILE 在回收檔案空間上可能較沒效率。
自動壓縮預設為停用,建議大部分資料庫保持此設定。 如果必須啟用自動壓縮,建議您在空間管理達成目標後停用此功能,而不是永久啟用。 如需詳細資訊,請參閱 AUTO_SHRINK 的考量。
例如,當彈性池包含多個資料庫,且使用空間大幅增加且減少,導致池接近最大大小限制時,自動縮減會很有幫助。 這種情況並不常見。
若要啟用自動壓縮,請連線至您的資料庫 (非 master 資料庫) 並執行下列命令。
-- Enable auto-shrink for the current database.
ALTER DATABASE CURRENT SET AUTO_SHRINK ON;
如需有關此命令的詳細資訊,請參閱 DATABASE SET 選項。
縮小後的索引維護
完成資料檔案的壓縮作業後,索引可能會變得分散。 分段化會降低某些工作負載的讀取 I/O 吞吐量,例如使用大型掃描的查詢。 如果壓縮作業完成後發生效能降低的情形,請考慮執行索引維修來重建索引。 請記住,索引重建需要資料庫中的空閒空間,因此可能會增加分配空間,抵消縮減的效果。
如需索引維修的詳細資訊,請參閱將索引維修最佳化以改善查詢效能並降低資源耗用量。
壓縮大型資料庫
當資料庫配置的空間為數百 GB 以上時,壓縮可能需要很長的時間才能完成 (通常是以小時為單位),而多 TB 資料庫則可能需要數天才能完成。 您可以使用程序最佳化和最佳做法,讓程序更有效率,並降低對應用程式工作負載的影響。
擷取空間使用量基準
開始壓縮前,請執行下列空間使用量查詢,擷取各資料庫檔案目前已使用和配置的空間:
SELECT file_id,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
完成壓縮之後,您可以再次執行此查詢,並將結果與初始基準進行比較。
截斷資料檔案
建議您先使用 TRUNCATEONLY 參數,執行各資料檔案的壓縮。 如此一來,如果檔案結尾有任何已配置但未使用的空間,會立即移除,而不需移動任何資料。 下列範例命令會截斷 file_id 4 的資料檔案:
DBCC SHRINKFILE (4, TRUNCATEONLY);
各資料檔案執行此命令後,即可重新執行空間使用量查詢,查看已配置空間是否有任何減少。 您也可以在 Azure 入口網站中,檢視資料庫已配置的空間。
評估索引頁密度
如果截斷資料檔仍無法減少足夠的空間,則需要縮小資料檔案。 但請先判斷資料庫索引的頁面平均密度,這個步驟為選擇性但建議您採用。 對於相同的數據量,如果頁面密度很高,壓縮作業就會更快完成,因為它必須移動較少的頁面。 壓縮資料檔案前,如果部分索引的頁面密度較低,請考慮維修這些索引,增加頁面密度。 提高頁面密度能使縮減功能在已配置的儲存空間中達到更顯著的減少。
若要判斷資料庫中所有索引的頁面密度,請使用下列查詢。 頁面密度會在 avg_page_space_used_in_percent 資料行中報告。
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
壓縮資料檔案前,如果索引包含高頁面計數,但頁面密度低於 60-70%,請考慮重建或重新組織這些索引。
對於較大的資料庫,查詢頁面密度可能需要很長時間才能完成。 重建或重組大型指數也需要大量時間與資源投入。 然而,在縮水前進行指數維護可以縮短縮水時間並節省更高的空間。
如果有多個包含低頁面密度的索引,您可以在多個資料庫工作階段平行重建這些索引,加速處理程序。 不過,務必避免因此接近資料庫資源限制。 預留足夠的資源空間給可能正在執行的應用程式工作負載。 在 Azure 入口網站中監視資源耗用量(CPU、數據 IO、記錄 IO),或使用 sys.dm_db_resource_stats 檢視來進行監控。 只有在每個維度上的資源使用率仍大幅低於 100%時,才啟動額外的平行重建。 如果 CPU、資料 IO 或記錄 IO 使用率為 100%,您可以擴大資料庫,使用更多 CPU 核心並增加 IO 輸送量。
索引重建命令範例
以下是使用 ALTER INDEX 陳述式重建索引並增加索引頁面密度的範例命令:
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
此命令會初始化線上且可繼續的索引重建。 此作業允許同時工作負載在重建過程中繼續使用資料表,若因任何原因中斷,則可繼續重建。 但比起會封鎖資料表存取的離線重建,此類重建的速度較慢。 重建時,如果沒有其他工作負載需要存取資料表,請將 ONLINE 和 RESUMABLE 選項設為 OFF,並移除 WAIT_AT_LOW_PRIORITY 子句。
若要深入了解索引維修,請參閱將索引維修最佳化以改善查詢效能並降低資源耗用量。
縮減前壓縮 LOB 資料
如果資料庫包含以下內容,縮減時間可能會更長:
- LOB 資料型態如 varchar(max)、nvarchar(max)、varbinary(max)、xml 或類似的資料型態儲存在
LOB_DATA配置單元中。 -
大列 儲存在
ROW_OVERFLOW_DATA分配單元中。 - Columnstore 索引。
為了提升縮小運行效率並釋放更多空間,請先完成索引重組,並進行 LOB 壓縮。 建議對所有包含 LOB 欄或大列的索引在縮小之前先進行 LOB 壓縮。 例如:
ALTER INDEX [index_name] ON [schema_name].[table_name]
REORGANIZE WITH (LOB_COMPACTION = ON);
在縮減前重新組織或重建柱倉索引,也能提升縮減速度與效率。
壓縮多個資料檔案
如先前所述,使用資料移動壓縮須花費長時間執行。 如果資料庫有多個資料檔案,您可以平行壓縮多個資料檔案,加速處理程序。 開啟多個資料庫會話,並在 DBCC SHRINKFILE 每個會話中使用不同的 file_id 值。 類似於先前重建索引,在開始每個新的平行壓縮命令前,請確定您有足夠的資源空餘空間 (CPU、資料 IO、記錄 IO)。
下列範例命令會壓縮 file_id 4 的資料檔案,並移動檔案中的頁面,嘗試減少配置大小至 52,000 MB:
DBCC SHRINKFILE (4, 52000);
若要盡量減少檔案的配置空間,在執行陳述式時,請不要指定目標大小:
DBCC SHRINKFILE (4);
如果工作負載與壓縮同時執行,工作負載可能會在壓縮完成並截斷檔案前就開始使用壓縮所釋放出來的儲存空間。 在這種情況下,縮減無法將分配的空間減少到指定的目標大小。
為了避免這個問題,請逐步縮小每個檔案。 在指令中 DBCC SHRINKFILE ,設定目標比目前分配的檔案空間稍小,如 基準空間使用查詢結果所示。 例如,如果 file_id 4 的檔案配置空間為 200,000 MB,而您想要將其壓縮為 100,000 MB,可先將目標設為 170,000 MB:
DBCC SHRINKFILE (4, 170000);
此指令會截斷檔案,並將其分配大小減少至 170,000 MB。 接著,您可以重複此命令,先將目標設定為140,000 MB,再設定為110,000 MB,直到檔案壓縮成所需的大小為止。 如果命令完成但檔案未截斷,請嘗試較小的步驟,例如將 30,000 MB 改為 15,000 MB。
若要監視所有正在執行的壓縮工作階段的壓縮進行情況,您可以使用下列查詢:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
注意
壓縮進度可以是非線性的,即使壓縮仍在進行中,percent_complete 數據行中的值仍可能保持不變。
壓縮完成所有數據文件之後,請重新執行 空間使用量查詢(或簽入 Azure 入口網站),以判斷配置記憶體大小降低的結果。 如果已使用的空間與設定的空間之間仍有較大差異,重建索引。 索引重建可以暫時進一步增加分配空間。 然而,在重建索引後再次縮減資料檔案,應該會大幅減少分配的空間。
縮小過程中的暫時性錯誤
有時候,壓縮命令可能會失敗,並出現各種錯誤,例如逾時和死結。 一般而言,這些是暫時性錯誤,而且在相同的命令重複時不會再次發生。 如果縮小失敗且出錯,則保留迄今為止的進度。 再執行一次相同的縮小指令,繼續縮小檔案。
以下範例腳本示範如何在重試迴圈中執行縮減。 當發生逾時錯誤或死結錯誤時,迴圈會自動重試該操作,最多可設定次數。 此重試方法也適用壓縮時可能發生的許多其他錯誤。
DECLARE @RetryCount int = 3; -- adjust to configure desired number of retries
DECLARE @Delay char(12);
-- Retry loop
WHILE @RetryCount >= 0
BEGIN
BEGIN TRY
DBCC SHRINKFILE (1); -- adjust file_id and other shrink parameters
-- Exit retry loop on successful execution
SELECT @RetryCount = -1;
END TRY
BEGIN CATCH
-- Retry for the declared number of times without raising an error if deadlocked or timed out waiting for a lock
IF ERROR_NUMBER() IN (1205, 49516) AND @RetryCount > 0
BEGIN
SELECT @RetryCount -= 1;
PRINT CONCAT('Retry at ', SYSUTCDATETIME());
-- Wait for a random period of time between 1 and 10 seconds before retrying
SELECT @Delay = '00:00:0' + CAST(CAST(1 + RAND() * 8.999 AS decimal(5,3)) AS varchar(5));
WAITFOR DELAY @Delay;
END
ELSE -- Raise error and exit loop
BEGIN
SELECT @RetryCount = -1;
THROW;
END
END CATCH
END;
除了逾時和死結之外,壓縮還可能會因為某些已知問題而發生錯誤。
傳回的錯誤和緩解步驟,如下所示:
- 錯誤號碼:49503,錯誤訊息:%.*ls:頁面 %d:%d 因為是行外持久版本存儲頁面,所以無法移動。頁面扣留原因:%ls。頁面扣留時間戳記:%I64d。
此錯誤發生在存在執行時間長的活躍交易,並在持久版本儲存庫(PVS)中產生列版本時。 縮減操作無法移動包含列版本的頁面。
要緩解這種情況,你必須等到長期交易完成。 或者,你也可以識別並終止長時間運行的交易,但如果應用程式無法妥善處理交易失敗,這可能會影響應用程式。 尋找長時間運行的交易的方式之一,是在您執行壓縮命令的資料庫中運行下列查詢:
-- Transactions sorted by duration
SELECT st.session_id,
dt.database_transaction_begin_time,
DATEDIFF(second, dt.database_transaction_begin_time, CURRENT_TIMESTAMP) AS transaction_duration_seconds,
dt.database_transaction_log_bytes_used,
dt.database_transaction_log_bytes_reserved,
st.is_user_transaction,
st.open_transaction_count,
ib.event_type,
ib.parameters,
ib.event_info
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
OUTER APPLY sys.dm_exec_input_buffer(st.session_id, default) AS ib
WHERE dt.database_id = DB_ID()
ORDER BY transaction_duration_seconds DESC;
您可以使用 KILL 命令,並指定查詢結果中相關的 session_id 值,來終止交易:
KILL 4242; -- replace 4242 with the session_id value from query results
警告
終止交易可以對工作負載造成負面的影響。
一旦長時間執行的交易完成,內部背景任務會清理不再需要的資料列版本。 您可以使用下列查詢,監視 PVS 大小並量測清除進度。 在執行壓縮命令的資料庫中執行查詢:
SELECT pvss.persistent_version_store_size_kb / 1024. / 1024 AS persistent_version_store_size_gb,
pvss.online_index_version_store_size_kb / 1024. / 1024 AS online_index_version_store_size_gb,
pvss.current_aborted_transaction_count,
pvss.aborted_version_cleaner_start_time,
pvss.aborted_version_cleaner_end_time,
dt.database_transaction_begin_time AS oldest_transaction_begin_time,
asdt.session_id AS active_transaction_session_id,
asdt.elapsed_time_seconds AS active_transaction_elapsed_time_seconds
FROM sys.dm_tran_persistent_version_store_stats AS pvss
LEFT JOIN sys.dm_tran_database_transactions AS dt
ON pvss.oldest_active_transaction_id = dt.transaction_id
AND
pvss.database_id = dt.database_id
LEFT JOIN sys.dm_tran_active_snapshot_database_transactions AS asdt
ON pvss.min_transaction_timestamp = asdt.transaction_sequence_num
OR
pvss.online_index_min_transaction_timestamp = asdt.transaction_sequence_num
WHERE pvss.database_id = DB_ID();
在 persistent_version_store_size_gb 資料行中回報的 PVS 大小相較於原始大小有了大幅減少後,重新執行壓縮便應該會成功。
- 錯誤號碼:5223,錯誤訊息:%.*ls:空白頁面 %d:%d 無法解除配置。
如果有進行中的索引維修作業 (例如 ALTER INDEX),就可以發生此錯誤。 完成這些作業後,請重試壓縮命令。
如果此錯誤持續發生,可能必須重建相關的索引。 若要尋找要重建的索引,請在執行壓縮命令的相同資料庫中,執行下列查詢:
SELECT OBJECT_SCHEMA_NAME(pg.object_id) AS schema_name,
OBJECT_NAME(pg.object_id) AS object_name,
i.name AS index_name,
p.partition_number
FROM sys.dm_db_page_info(DB_ID(), <file_id>, <page_id>, default) AS pg
INNER JOIN sys.indexes AS i
ON pg.object_id = i.object_id
AND
pg.index_id = i.index_id
INNER JOIN sys.partitions AS p
ON pg.partition_id = p.partition_id;
執行此查詢前,請使用錯誤訊息中的實際值,取代 <file_id> 和 <page_id> 預留位置。 例如,如果訊息是「空白頁 1:62669 無法解除配置」,則 是 <file_id>,而 1 是 <page_id>。
重建查詢所識別的索引,並重試壓縮命令。
- 錯誤號碼:5201,錯誤訊息:DBCC SHRINKDATABASE:資料庫識別碼 %d 的檔案識別碼 %d 已跳過,因為檔案沒有足夠的可用空間可以回收。
此錯誤表示資料檔案無法進一步壓縮。 您可以移至下一個資料檔案。
相關內容
如需資料庫大小上限的相關資訊,請參閱: