使用 Spark 連接器加速即時巨量資料分析
適用於: ![]() Azure SQL 資料庫
Azure SQL 資料庫 ![]() Azure SQL 受控執行個體
Azure SQL 受控執行個體
注意
自 2020 年 9 月起,此連接器不會主動維護。 不過,現在已提供適用於 SQL Server 和 Azure SQL 的 Apache Spark 連接器,其支援 Python 和 R 繫結,並提供了更容易使用的介面來大量插入資料,以及其他許多改進功能。 我們強烈建議您評估和使用新的連接器,而不是這個連接器。 舊連接器的相關資訊 (此頁面) 僅保留以供封存之用。
Spark 連接器可讓 Azure SQL 資料庫、Azure SQL 受控執行個體和 SQL Server 中的資料庫作為 Spark 作業的輸入資料來源和輸出資料接收器。 它可讓您在巨量資料分析中使用即時交易資料,並保存特定查詢或報告的結果。 相較於內建 JDBC 連接器,此連接器可讓您將資料大量插入資料庫。 它能以 10 倍到 20 倍的速度提升效能,以超過逐個資料列插入的效能。 Spark 連接器支援使用 Microsoft Entra ID (先前稱為 Azure Active Directory) 進行驗證,以連線至 Azure SQL 資料庫和 Azure SQL 受控執行個體,讓您能夠使用 Microsoft Entra 帳戶從 Azure Databricks 連線資料庫。 它提供內建 JDBC 連接器的類似介面。 您可以輕鬆地移轉現有的 Spark 作業,以使用此新連接器。
注意
Microsoft Entra ID 先前稱為 Azure Active Directory (Azure AD)。
下載並組建 Spark 連接器
先前從此頁面連結到的舊連接器的 GitHub 存放庫不會主動維護。 相反地,我們強烈建議您評估和使用新的連接器。
官方支援的版本
| 元件 | 版本 |
|---|---|
| Apache Spark | 2.0.2 或更新版本 |
| Scala | 2.10 或更新版本 |
| Microsoft JDBC Driver for SQL Server | 6.2 或更新版本 |
| Microsoft SQL Server | SQL Server 2008 或更新版本 |
| Azure SQL Database | 支援 |
| Azure SQL 受控執行個體 | 支援 |
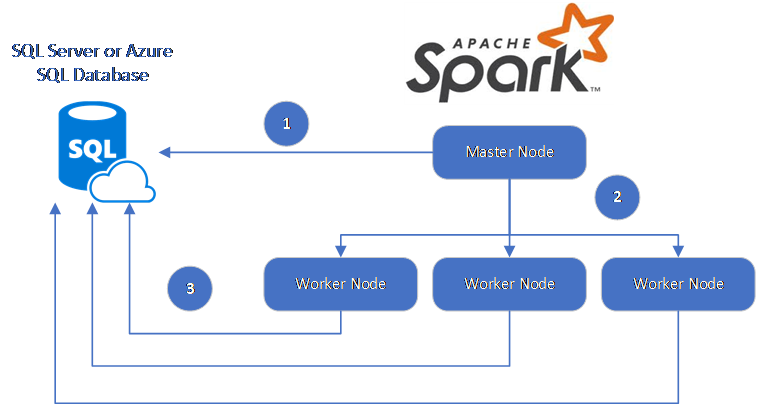
Spark 連接器會利用適用於 SQL Server 的 Microsoft JDBC 驅動程式在 Spark 背景工作角色節點和資料庫之間移動資料:
資料流程如下:
- Spark 主要節點會連線到 SQL Database 或 SQL Server 中的資料庫,並從特定資料表或使用特定的 SQL 查詢載入資料。
- Spark 主要節點會將資料散發至背景工作角色節點以進行轉換。
- 背景工作角色節點會連線到連線到 SQL Database 和 SQL Server 的資料庫,並將資料寫入該資料庫。 使用者可以選擇使用逐個資料列插入或大量插入。
下圖說明此資料流程。
組建 Spark 連接器
連接器專案目前使用 maven。 若要在沒有相依性的情況下組建連接器,您可以執行:
- mvn clean package
- 從發行資料夾下載最新版本的 JAR
- 包括 SQL Database Spark JAR
使用 Spark 連接器連線並讀取資料
您可以從 Spark 作業連線到 SQL Database 和 SQL Server 中的資料庫,以讀取或寫入資料。 您也可以在 SQL Database 和 SQL Server 的資料庫中執行 DML 或 DDL 查詢。
從 Azure SQL 和 SQL Server 讀取資料
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
使用指定的 SQL 查詢從 Azure SQL 和 SQL Server 讀取資料
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
寫入資料到 Azure SQL 和 SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Aquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
在 Azure SQL 和 SQL Server 中執行 DML 或 DDL 查詢
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
使用 Microsoft Entra 驗證從 Spark 連線
您可以使用 Microsoft Entra 驗證連線到 SQL Database 和 SQL 受控執行個體。 使用 Microsoft Entra 驗證集中管理資料庫使用者的身分識別,並作為 SQL 驗證的替代驗證。
使用 ActiveDirectoryPassword 驗證模式連線
安裝需求
如果您使用 ActiveDirectoryPassword 驗證模式,您必須下載 microsoft-authentication-library-for-java 及其相依性,並將其包括在 Java 組建路徑中。
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
使用存取權杖連線
安裝需求
如果您使用以存取權杖為基礎的驗證模式,您必須下載 microsoft-authentication-library-for-java 及其相依性,並將其包括在 Java 組建路徑中。
請參閱使用 Microsoft Entra 驗證,了解如何取得 Azure SQL 資料庫或 Azure SQL 受控執行個體中的資料庫的存取權杖。
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.windows.net",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
使用大量插入寫入資料
傳統的 jdbc 連接器會使用逐個資料列插入的方式將資料寫入資料庫。 您可以使用 Spark 連接器,利用大量插入將資料寫入 Azure SQL 和 SQL Server。 當載入大型資料集或將資料載入使用資料行存放區索引的資料表時,它會大幅改善寫入效能。
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
下一步
如果您尚未下載 Spark 連接器,請從 azure-sqldb-spark GitHub repository 下載 Spark 連接器,並探索存放庫中的其他資源:
您也可以檢閱 Apache Spark SQL、DataFrame 和資料集指南和 Azure Databricks 文件。