自動識別並轉譯多語言內容
重要
由於 Azure 媒體服務 淘汰公告,Azure AI 影片索引器會宣告 Azure AI 影片索引器功能調整。 請參閱 Azure 媒體服務 (AMS) 淘汰 的相關變更,以瞭解 Azure AI 影片索引器帳戶的意義。 請參閱準備AMS淘汰:VI更新和移轉指南。
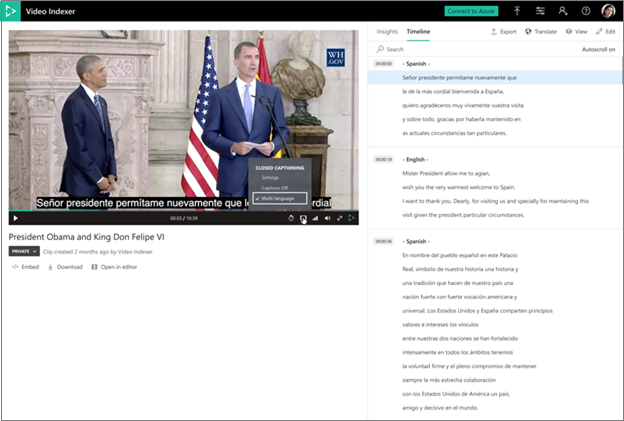
Azure AI 影片索引器支援多語言內容中的自動語言識別和轉譯。 此程式牽涉到自動識別音訊不同區段的口語,傳送要轉譯的媒體檔案每個區段,並將轉譯結合回一個統一轉譯。
選擇使用入口網站編製索引的多語系識別
您可以在上傳和編製影片索引時選擇 多語言偵測 。 或者,您可以在重新編製影片索引時選擇 多語言偵測 。 下列步驟說明如何重新編製索引:
流覽至 Azure AI 影片索引器 網站並登入。
移至 [連結 庫 ] 頁面,並將滑鼠停留在您想要重新編製索引的影片名稱上。
在右下角,選取 [ 重新編製影片 索引] 按鈕。
在 [重新編制影片索引] 對話框中,從 [影片來源語言] 下拉式方塊中選擇多語言偵測。
- 當影片編製索引為多語言時,使用者即可檢視哪些區段會以何種語言轉譯。
- 從多語言文字記錄完整提供所有語言的翻譯。
- 所有其他深入解析都會以在音訊中偵測到最多的語言顯示。
- 播放程式上的關閉 標題 也可使用多種語言。
選擇使用 API 編製索引的多語系識別
使用 API 編製或 重新編製 影片索引時,請選擇 multi-language detection 參數中的 sourceLanguage 選項。
模型輸出
模型會擷取一個清單中影片中偵測到的所有語言
"sourceLanguage": null,
"sourceLanguages": [
"es-ES",
"en-US"
],
此外,轉譯區段中的每個實例都包含其轉譯的語言
{
"id": 136,
"text": "I remember well when my youth Minister took me to hear Doctor King I was a teenager.",
"confidence": 0.9343,
"speakerId": 1,
"language": "en-US",
"instances": [
{
"adjustedStart": "0:21:10.42",
"adjustedEnd": "0:21:17.48",
"start": "0:21:10.42",
"end": "0:21:17.48"
}
]
},
指導方針與限制
- 包含您所選取語言以外的音訊會產生非預期的結果。
- 偵測每個語言的最社區段長度為15秒。
- 語言偵測位移平均為3秒。
- 語音必須是連續的。 語言之間的頻繁交替可能會影響模型的效能。
- 非原生說話者的語音可能會影響模型的效能(例如,當說話者使用他們的第一種語言,並切換到另一種語言時)。
- 此模型的設計目的是使用合理的音訊原音辨識自發的對話語音(不是語音命令、唱歌等)。
- 專案建立和編輯不適用於多語言影片。
- 使用多語言偵測時,無法使用自定義語言模型。
- 不支援新增關鍵詞。
- 導出的已關閉 標題 檔案中未包含語言指示。
- API 中的更新文字記錄不支援多種語言檔案。
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應