資料網格協助組織從集中式的資料湖泊或資料倉儲轉向基於四個原則的領域驅動的分析資料分散化:網域擁有權、資料即產品、自助服務資料平臺及聯邦計算治理。 資料網格 提供了分散式資料擁有權的優勢,以及提升的資料品質與治理,能加速組織的業務進程並更快實現價值。
數據網格實作
典型的數據網格實作包含網域小組與建置數據管線的數據工程師。 小組會維護作業和分析資料存放區,例如資料湖、資料倉儲或資料湖倉。 他們將管線作為 資料產品 發佈,供其他領域小組或資料科學小組使用。 其他小組會使用中央數據控管平臺來取用數據產品,如下圖所示。
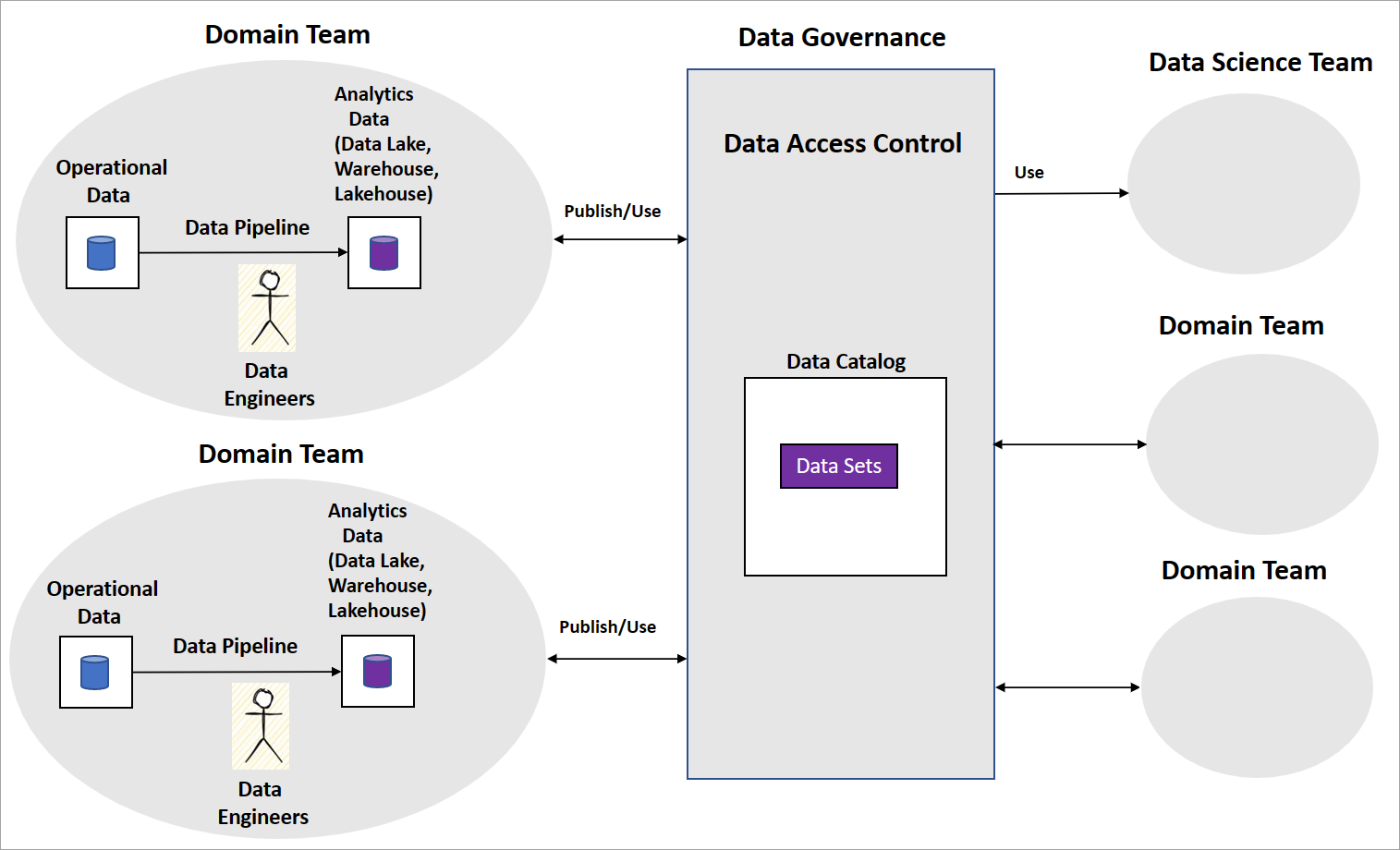
數據網格清楚說明數據產品如何為商業智慧提供已轉換和匯總的數據集。 但這並不明確說明組織應採用以建置 AI/ML 模型的方法。 也沒有關於如何建構其數據科學小組、AI/ML 模型治理,以及如何在網域小組之間共用 AI/ML 模型或功能的指導。
下一節概述組織可用來在數據網格內開發 AI/ML 功能的幾個策略。 您會看到關於領域驅動的特徵工程或特徵網絡策略的建議。
適用於數據網格的 AI/ML 策略
其中一個常見的策略是組織採用數據科學小組作為數據取用者。 這些小組會根據使用案例存取數據網格中的各種網域數據產品。 他們會執行數據探索和特徵工程,以開發和建置 AI/ML 模型。 在某些情況下,網域小組也會使用其數據和其他小組的數據產品來擴充和衍生新功能,來開發自己的 AI/ML 模型。
特徵工程 是模型建置的核心,通常很複雜,而且需要領域專業知識。 此策略可能很耗時,因為數據科學小組需要分析各種數據產品。 他們可能沒有完整的領域知識來建置高品質的功能。 缺乏領域知識可能會導致網域小組之間的功能工程工作重複。 此外,AI/ML 模型重現性等問題,因為整個小組的功能集不一致。 隨著發行新版本的數據產品,數據科學或網域小組需要持續重新整理功能。
另一個策略是讓網域小組以開放式類神經網路交換(ONNX)等格式發行 AI/ML 模型,但這些結果是黑匣子,而且跨網域結合 AI/ML 模型或功能會很困難。
是否有方法可分散跨網域和數據科學小組建置的 AI/ML 模型,以解決挑戰? 建議的領域驅動特徵工程或特徵網格策略是一個選項。
領域驅動特徵工程或特徵網格
領域驅動特徵工程或特徵網格策略提供在數據網格設定中建置 AI/ML 模型的非集中式方法。 下圖顯示策略,以及如何解決數據網格的四個主要原則。
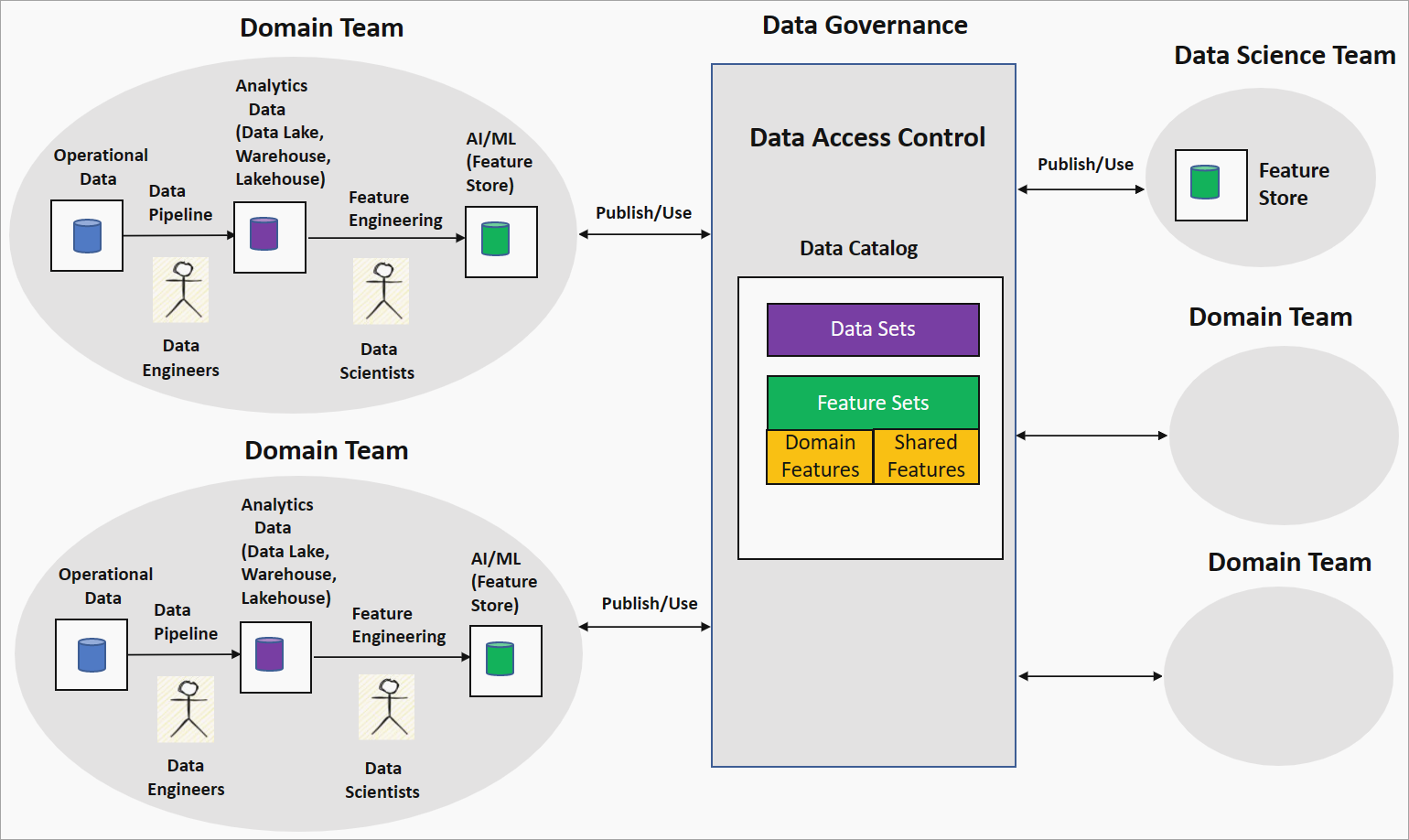
網域團隊的網域擁有權功能工程
在此策略中,組織會將數據科學家與網域小組中的數據工程師配對,讓他們在乾淨且已轉換的數據上進行探索分析,例如在數據湖中。 工程生成的特徵會儲存至特徵存放區。 功能存放區是一種數據存放庫,可提供定型和推斷的功能,並協助追蹤功能版本、元數據和統計數據。 這項功能可讓領域小組中的數據科學家與領域專家密切合作,並讓功能隨著網域中的數據變更而重新整理。
數據做為產品:功能集
網域小組所產生的功能,稱為網域或本機功能,會發佈至數據控管平臺中的數據目錄做為功能集。 這些數據科學小組或其他網域小組會取用這些功能集來建置 AI/ML 模型。 在 AI/ML 模型開發期間,數據科學或領域小組可以結合領域功能來產生新功能,稱為共用或全域功能。 這些共用功能會發佈回功能集目錄以供取用。
自助數據平臺和同盟計算治理:功能標準化和品質
此策略可能會導致針對功能工程管線採用不同的技術堆疊,以及網域小組之間的功能定義不一致。 自助數據平台原則可確保網域小組使用通用基礎結構和工具來建置功能工程管線,並強制執行訪問控制。 同盟計算治理原則可透過全域標準化確保功能集的互操作性,並檢查功能品質。
使用領域驅動特徵工程或功能網格策略,為組織提供分散式 AI/ML 模型建置方法,以協助縮短開發 AI/ML 模型的時間。 此策略有助於讓功能在整個網域小組之間保持一致。 它可避免重複工作,併產生更精確的 AI/ML 模型高品質功能,進而提升業務價值。
Azure 中的數據網格實作
本文說明如何在數據網格中運作 AI/ML 的概念,但未涵蓋用來建置這些策略的工具或架構。 Azure 具備功能存放區選擇,例如 Azure Databricks 功能存放區,以及 LinkedIn 的 Feathr。 您可以開發 Microsoft Purview 自定義連接器來管理和管理功能存放區。