在 Azure 中的雲端規模分析中使用 Azure Databricks
Azure Databricks 是針對 Microsoft Azure 雲端服務 平臺優化的數據分析平臺。 Azure Databricks 提供兩個環境來開發需要大量數據的應用程式:
Azure Databricks SQL 可讓您在 Data Lake 上執行快速臨機操作 SQL 查詢。
Azure Databricks 資料科學 & Engineering(有時稱為「工作區」)是以 Apache Spark 為基礎的分析平臺。 它與 Azure 整合,可提供單鍵設定、簡化的工作流程,以及互動式工作區,讓數據工程師、數據科學家和機器學習工程師之間能夠共同作業。
針對雲端規模分析,我們將著重於 Azure Databricks 資料科學 與工程。
概觀
針對您部署的每個數據登陸區域,您可以選擇部署兩個共用工作區。 一個用於數據無從驗證擷取,另一個用於分析。
- 用於擷取和處理的 Azure Databricks 工程工作區會透過 Azure 服務主體連線到 Azure Data Lake。 它是由數據無從驗證擷取所呼叫。
- Azure Databricks 分析工作區可以布建給所有數據科學家和數據作業小組。 此工作區會使用 Microsoft Entra 傳遞驗證連線到 Azure Data Lake。 您會在數據登陸區域中與所有可存取工作區的用戶共用 Azure Databricks 分析和數據科學工作區。
如果您有與數據無關的擷取引擎,Azure Databricks 工程工作區會同時使用在 Azure 元數據服務資源群組中建立的 Azure 金鑰保存庫 實例,以從原始擷取管線執行數據擷取管線。
Azure Databricks 分析工作區應具有需要您建立高並行叢集的叢集原則。 這種類型的叢集可讓 Data Lake 使用 Microsoft Entra 認證傳遞來探索。 如需詳細資訊,請參閱 Azure Data Lake 儲存體 中的訪問控制和數據湖組態。
設定 Azure Databricks
Azure Databricks 部署部分是透過 Azure Resource Manager 範本和 YAML 腳本以參數為基礎,但也需要一些手動介入來設定所有工作區。
所有 Azure Databricks 工作區都應該使用進階方案,其提供下列必要功能:
- 最佳化自動調整計算
- Microsoft Entra 認證傳遞驗證
- 條件式驗證
- Notebook、叢集、作業及資料表的角色型存取控制
- 稽核記錄
若要配合雲端規模分析,建議所有工作區都已設定下列預設部署選項:
- Azure Databricks 工作區會連線到數據登陸區域中的外部 Apache Hive 中繼存放區實例。
- 將每個工作區設定為在 databricks-monitoring-rg 中將 Databricks 診斷記錄傳送至 Azure Log Analytics
- 實作叢集原則,以限制根據一組規則建立叢集的能力。 如需詳細資訊,請參閱 管理叢集原則。
- 定義多個叢集原則。 在上架程式中,指派數據登陸區域作業小組使用的每個目標群組許可權。 根據預設,叢集建立許可權只會提供給作業小組。 不同的小組或群組獲授與使用叢集原則的許可權。
- 使用叢集原則搭配 Azure Databricks 集區,藉由維護一組閑置且可供使用的實例,以減少叢集的啟動和自動調整時間。 如需詳細資訊,請參閱 集區。
- 從 Azure 金鑰保存庫 實例擷取所有 Azure Databricks 作業秘密,例如 SPN 認證和 連接字串。
- 為每個工作區設定個別的企業應用程式,以搭配 SCIM 使用(跨網域身分識別管理的系統)。 連結至 Azure Databricks 工作區,以控制每個工作區的存取權和許可權。 如需詳細資訊,請參閱 使用 SCIM 布建使用者和群組,並 設定 Microsoft Entra ID 的 SCIM 布建。
警告
無法設定 Azure Databricks 工作區來使用 Azure Databricks SCIM 介面會影響您提供安全性控制的方式。 它會從自動化移至手動程式,並中斷所有部署 CI/CD 管線。
下列存取控制選項會針對所有 Databricks 工作區設定:
- 工作區可見性控制項:已啟用(預設值:已停用)
- 叢集可見性控制項:已啟用 (預設值:已停用)
- 作業可見性控制項:已啟用(預設值:已停用)
您可能想要為 Azure Databricks 分析工作區啟用下列選項:
- 筆記本匯出:已停用(預設值:已啟用)
- 筆記本資料表剪貼簿功能:已停用(預設值:已啟用)
- 資料表存取控制:已啟用(預設值:已停用)
- Microsoft Entra 條件式存取
部署 Azure Databricks
如果您將 Azure Databricks 工作區部署為新數據登陸區域部署的一部分。 下圖顯示在雲端規模分析中部署 Azure Databricks 環境的範例工作流程。
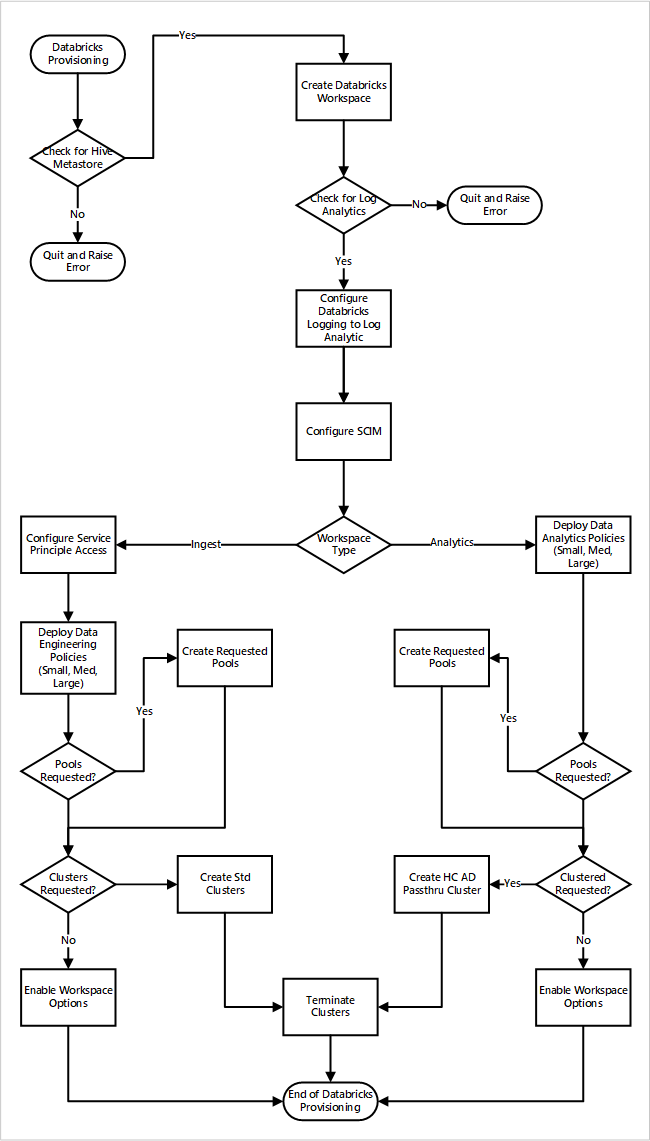
- 布建程式會先確定數據登陸區域中有 Apache Hive 中繼存放區實例。 如果找不到 Apache Hive 中繼存放區,則會結束並引發錯誤。
- 成功尋找 Apache Hive 中繼存放區後,就會建立工作區。
- 此程式會檢查數據登陸區域中的Log Analytics工作區。 如果找不到 Log Analytics 工作區,則會結束並引發錯誤。
- 針對每個工作區,它會建立 Microsoft Entra 應用程式並設定 SCIM。
針對 Azure Databricks 內嵌工作區:
- 此程式會設定具有服務主體存取權的工作區。
- 數據平臺作業小組所定義的數據工程原則會部署。
- 如果數據登陸區域作業小組已要求 Databricks 集區或叢集,則可以將其整合到部署程式中。
- 它可啟用 Azure Databricks 工程工作區專屬的工作區選項。
針對 Azure Databricks 分析工作區:
- 此程式會部署數據平臺作業小組所定義的數據分析原則。
- 如果數據登陸區域作業小組已要求 Databricks 集區或叢集,則可以將其整合到部署程式中。
- 它可啟用 Azure Databricks 工程工作區專屬的工作區選項。
外部 Hive 中繼存放區
在 Azure Databricks 工作區部署中:
- 新的全域 init 腳本會為所有叢集設定 Apache Hive 中繼存放區設定。 此腳本是由新的 全域 init 腳本 API 所管理。
新的全域 init 腳本 API 處於公開預覽狀態。 Azure Databricks 中的公開預覽功能已準備好用於生產環境,並由支援小組支援。 如需詳細資訊,請參閱 Azure Databricks 預覽版本。
- 此解決方案會使用 適用於 MySQL 的 Azure 資料庫 來儲存Apache Hive 中繼存放區實例。 此資料庫是針對其成本效益和與 Apache Hive 的高相容性而選擇的。
下一步
雲端規模分析會考慮下列指導方針來整合 Azure Databricks: