快速入門:自定義文字分類
使用本文開始建立自定義文字分類專案,您可以在其中定型文字分類的自定義模型。 模型是經過定型以執行特定工作的人工智慧軟體。 在此系統中,模型會分類文字,並透過學習標記的數據來定型。
自訂文字分類支援兩種類型的專案:
- 單一標籤分類 - 您可以為資料集中的每個檔案指派單一類別。 例如,電影腳本只能分類為「浪漫」或「喜劇」。
- 多重標籤分類 - 您可以為資料集中的每個檔案指派多個類別。 例如,電影腳本可以分類為 「Comedy」 或 「Romance」 和 「Comedy」。
在本快速入門中,您可以使用提供的範例數據集來建置多標籤分類,您可以在其中將電影腳本分類成一或多個類別,也可以使用單一卷標分類數據集,將科學論文的抽象概念分類為其中一個定義的定義域。
必要條件
- Azure 訂用帳戶 - 免費建立一個訂用帳戶。
建立新的 Azure AI 語言資源和 Azure 儲存體帳戶
使用自訂文字分類前,您必須建立 Azure AI 語言資源,因為此資源提供建立專案和開始訓練模型必要的認證。 您也需要 Azure 記憶體帳戶,您可以在其中上傳將用來建置模型的數據集。
重要
若要快速開始使用,建議您使用本文中提供的步驟來建立新的 Azure AI 語言資源。 使用本文中的步驟,可讓您同時建立語言資源和記憶體帳戶,這比稍後執行更容易。
如果您有 想要使用的現有資源 ,則必須將它連線到記憶體帳戶。
從 Azure 入口網站 建立新的資源
移至 Azure 入口網站以建立新的 Azure AI 語言資源。
在出現的視窗中,從自定義功能選取 [自定義文字分類與自定義具名實體辨識 ]。 選取畫面底部的 [繼續建立您的資源]。

使用下列詳細數據建立語言資源。
名稱 必要值 訂用帳戶 您的 Azure 訂閱。 資源群組 將包含您資源的資源群組。 您可以使用現有的 ,或建立新的。 區域 其中 一個支持的區域。 例如「美國西部 2」。 名稱 資源的名稱。 定價層 其中 一個支持的定價層。 您可以使用免費 (F0) 層來嘗試服務。 如果您收到一則訊息,指出「您的登入帳戶不是所選記憶體帳戶資源群組的擁有者」,您的帳戶必須先在資源群組上指派擁有者角色,才能建立語言資源。 請連絡您的 Azure 訂用帳戶擁有者以取得協助。
您可以搜尋您的資源群組,並遵循其相關聯訂用帳戶的連結來判斷您的 Azure 訂用帳戶擁有者。 接下來:
- 選取 [存取控制 (IAM)] 索引標籤
- 選取 [角色指派]
- 依 [角色: 擁有者] 進行篩選。
在 [ 自定義文字分類與自定義具名實體辨識 ] 區段中,選取現有的記憶體帳戶,或選取 [ 新增記憶體帳戶]。 請注意,這些值可協助您開始使用,而不一定 是您想要在生產環境中使用的記憶體帳戶值 。 若要避免在建置項目時延遲,請連線到與語言資源位於相同區域中的記憶體帳戶。
儲存體 帳戶值 建議值 儲存體帳戶名稱 任何名稱 Storage account type 標準 LRS 請確定 已核取負責任 AI 通知 。 選取頁面底部的 [檢閱 + 建立] 。

將範例數據上傳至 Blob 容器
建立 Azure 記憶體帳戶並將其連線到您的語言資源之後,您必須將檔從範例數據集上傳至容器的根目錄。 這些檔稍後將用來定型模型。
下載多重標籤分類專案的範例數據集。
開啟 .zip 檔案,並解壓縮包含文件的資料夾。
提供的範例數據集包含大約 200 份檔,每個檔都是電影的摘要。 每個檔案都屬於下列一或多個類別:
- “神秘”
- “戲劇”
- “驚悚片”
- “喜劇”
- “Action”
在 Azure 入口網站 中,流覽至您所建立的記憶體帳戶,然後加以選取。 您可以按一下 [儲存體帳戶],然後在 [篩選任何欄位] 中輸入儲存體帳戶名稱來執行此動作。
如果您的資源群組未顯示,請確定 [訂用帳戶等於] 篩選條件已設定為 [全部]。
在您的儲存體帳戶中,從左側功能表中 [資料儲存體] 的下方選取 [容器]。 在出現的畫面中,選取 [+ 容器]。 提供容器名稱 example-data ,並保留預設 的公用存取層級。

建立容器之後,請加以選取。 然後選取 [上傳] 按鈕,以選取您稍早下載的
.txt和.json檔案。


建立自訂文字分類專案
設定您的資源和記憶體容器之後,請建立新的自定義文字分類專案。 專案是一個工作區域,可根據您的數據建置自定義ML模型。 您的專案只能由您和其他人存取所使用之語言資源。
登入 Language Studio。 隨即會出現一個視窗,讓您選取您的訂用帳戶和語言資源。 選取您的語言資源。
在 Language Studio 的 [ 分類文字 ] 區段下,選取 [ 自定義文字分類]。

從項目頁面的頂端功能表中選取 [建立新專案 ]。 建立專案可讓您標記數據、定型、評估、改善和部署模型。
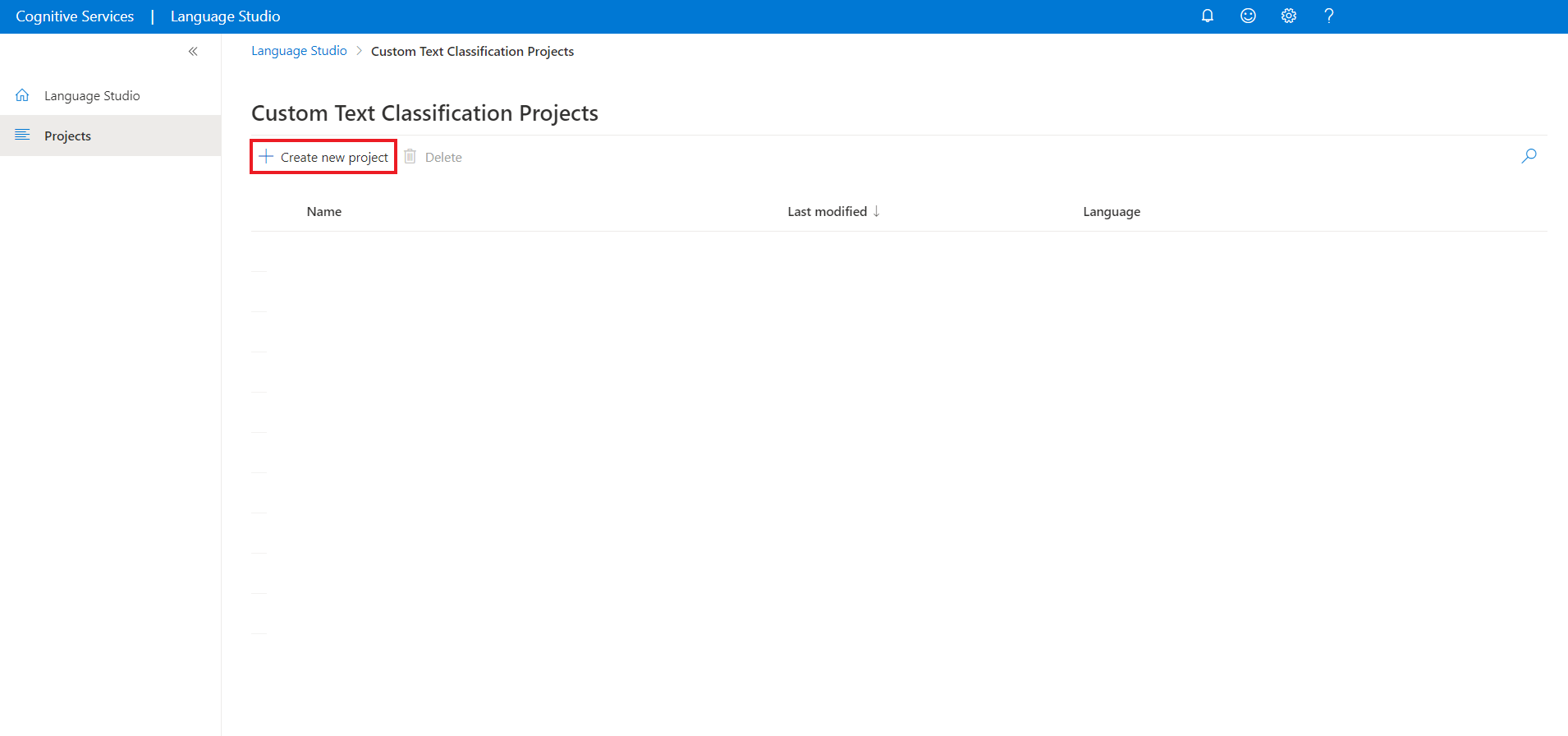
按兩下 [ 建立新專案] 之後,會出現一個視窗讓您連線記憶體帳戶。 如果您已連線記憶體帳戶,您會看到已連線的記憶體帳戶。 如果沒有,請從出現的下拉式清單中選擇儲存體帳戶,然後選取 [連線儲存體帳戶];這會為您的儲存體帳戶設定必要角色。 如果您未在記憶體帳戶上指派為 擁有者 ,此步驟可能會傳回錯誤。
注意
- 您只需要針對您使用的每個新語言資源執行此步驟一次。
- 如果您將記憶體帳戶連線到您的語言資源,稍後就無法中斷連線,此程式將無法復原。
- 您只能將語言資源連線到一個記憶體帳戶。

選取項目類型。 您可以建立多 標籤分類 專案,其中每個檔可以屬於一或多個類別,或是 每個檔只能屬於一個類別的單一標籤分類 專案。 稍後無法變更選取的類型。 深入瞭解 項目類型

輸入項目資訊,包括專案中檔的名稱、描述和語言。 如果您使用 範例數據集,請選取 [英文]。 您稍後將無法變更項目的名稱。 選取 [下一步]。
提示
您的數據集不需要完全使用相同的語言。 您可以有多個檔,每個檔都有不同的支持語言。 如果您的資料集包含不同語言的檔,或當您在運行時間預期來自不同語言的文字時,請在輸入專案的基本資訊時選取 [啟用多語系數據集 ] 選項。 此選項稍後可從 [項目設定] 頁面啟用。
選取您已上傳數據集的容器。
注意
如果您已標示資料,則請確定其遵循支援的格式,然後選取 [是,我的文件已加上標籤,而且我有已格式化的 JSON 標籤檔案],然後從下方的下拉式功能表選取標籤檔案。
如果您使用其中一個範例資料集,請使用包含
webOfScience_labelsFile或movieLabels的 JSON 檔案。 然後選取下一步。檢閱您輸入的數據,然後選取 [ 建立專案]。




定型您的模型
一般而言,在您建立項目之後,請繼續 開始標記您在容器中已連線至專案的檔 。 在本快速入門中,您已匯入範例加上標籤的數據集,並使用範例 JSON 卷標檔案初始化專案。
若要從 Language Studio 內開始訓練您的模型:
從左側功能表中選取 [訓練作業 ]。
從頂端功能表中選取 [啟動訓練作業 ]。
選取 [定型新的模型 ],然後在文本框中輸入模型名稱。 您也可以 選取此選項並選擇您想要從下拉功能表覆寫的模型,以覆寫現有的模型 。 覆寫已定型的模型是不可復原的,但在您部署新模型之前,不會影響已部署的模型。

選取數據分割方法。 您可以選擇 [從定型數據 自動分割測試集],其中系統會根據指定的百分比,在定型集與測試集之間分割已標記的數據。 或者,您可以使用手動分割定型和測試數據,只有在您在數據標記期間已將檔新增至測試集時,才會啟用此選項。 如需數據分割的詳細資訊,請參閱 如何定型模型 。
選取 [ 訓練] 按鈕。
如果您從清單中選取 [定型作業識別碼],則會顯示側邊窗格,您可以在其中檢查此作業的 [定型進度]、[作業狀態] 和其他詳細資料。
注意
- 只有成功完成的定型作業才會產生模型。
- 根據標籤資料的大小,定型模型所需的時間可能需要幾分鐘到數小時的時間。
- 您一次只能執行一個定型作業。 除非執行中的作業完成,否則無法在同一個專案內啟動其他定型作業。

部署模型
一般而言,在定型模型之後,您會檢閱其 評估詳細數據 ,並 在必要時進行改進 。 在本快速入門中,您只會部署模型,並讓它可供您在 Language Studio 中試用,或者您可以呼叫 預測 API。
若要從 Language Studio 內部署模型:
從左側功能表中選取 [部署模型 ]。
選取 [新增部署] 以啟動新的部署作業。
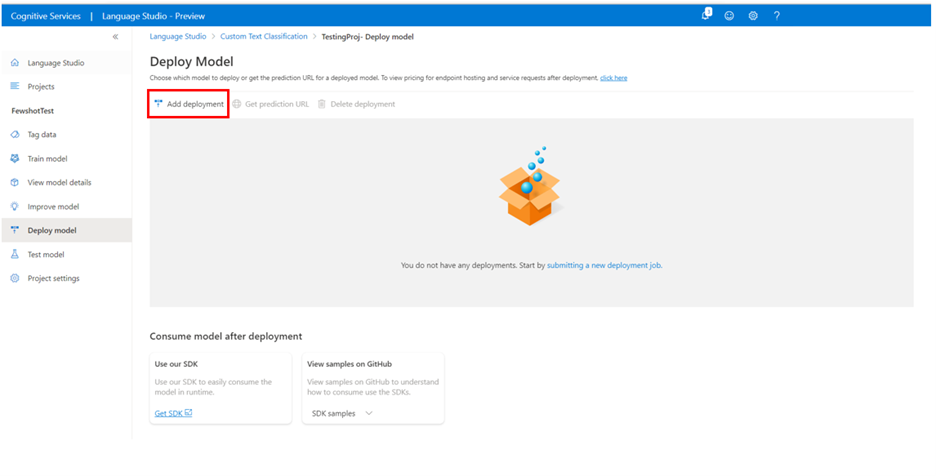
選取 [建立新的部署] 以建立新的部署 ,並從下方的下拉式清單中指派定型的模型。 您也可以 選取此選項,然後從下列下拉式清單中選取要指派給它的定型模型,以覆寫現有的部署 。
注意
覆寫現有的部署不需要變更預測 API 呼叫,但您得到的結果會以新指派的模型為基礎。

選取 [部署] 以動部署作業。
部署成功之後,到期日會出現在它旁邊。 部署到期 是當部署的模型無法用於預測時,通常發生在 定型組態到期后的 12 個月。


測試您的模型
部署模型之後,您就可以開始使用模型,透過 預測 API 來分類文字。 在本快速入門中 ,您將使用 Language Studio 提交自定義文字分類工作,並將結果可視化。 在稍早下載的範例數據集中,您可以找到一些可在此步驟中使用的測試檔。
若要在 Language Studio 中測試已部署的模型:
從畫面左側的功能表中選取 [測試部署 ]。
選取您要測試的部署。 您只能測試指派給部署的模型。
針對多語系專案,選取您使用語言下拉式清單測試的文字語言。
從下拉式清單中選取您想要查詢/測試的部署。
輸入您想要在要求中提交的文字,或上傳
.txt要使用的檔。 如果您使用其中一個範例資料集,則您可以使用其中一個包含的 .txt 檔案。選取頂端功能表中的 [執行測試]。
在 [ 結果] 索引標籤中,您可以看到文字的預測類別。 您也可以在 [JSON] 索引標籤下 檢視 JSON 回應。下列範例適用於單一標籤分類專案。 多重標籤分類專案可以傳回結果中的多個類別。


清除專案
當您不再需要專案時,可以使用 Language Studio 刪除專案。 選取頂端的 [自訂文字分類],然後選取您想要刪除的專案。 選取頂端功能表中的 [刪除] 以刪除專案。
必要條件
- Azure 訂用帳戶 - 免費建立一個訂用帳戶。
建立新的 Azure AI 語言資源和 Azure 儲存體帳戶
使用自訂文字分類前,您必須建立 Azure AI 語言資源,因為此資源提供建立專案和開始訓練模型必要的認證。 您也需要 Azure 記憶體帳戶,您可以在其中上傳將用於建置模型的數據集。
重要
若要快速開始使用,建議您使用本文提供的步驟來建立新的 Azure AI 語言資源,這可讓您建立語言資源,同時建立及/或連接儲存體帳戶,此做法會比稍後執行更容易。
如果您有 想要使用的現有資源 ,則必須將它連線到記憶體帳戶。
從 Azure 入口網站 建立新的資源
移至 Azure 入口網站以建立新的 Azure AI 語言資源。
在出現的視窗中,從自定義功能選取 [自定義文字分類與自定義具名實體辨識 ]。 選取畫面底部的 [繼續建立您的資源]。
使用下列詳細數據建立語言資源。
名稱 必要值 訂用帳戶 您的 Azure 訂閱。 資源群組 將包含您資源的資源群組。 您可以使用現有的 ,或建立新的。 區域 其中 一個支持的區域。 例如「美國西部 2」。 名稱 資源的名稱。 定價層 其中 一個支持的定價層。 您可以使用免費 (F0) 層來嘗試服務。 如果您收到一則訊息,指出「您的登入帳戶不是所選記憶體帳戶資源群組的擁有者」,您的帳戶必須先在資源群組上指派擁有者角色,才能建立語言資源。 請連絡您的 Azure 訂用帳戶擁有者以取得協助。
您可以搜尋您的資源群組,並遵循其相關聯訂用帳戶的連結來判斷您的 Azure 訂用帳戶擁有者。 接下來:
- 選取 [存取控制 (IAM)] 索引標籤
- 選取 [角色指派]
- 依 [角色: 擁有者] 進行篩選。
在 [ 自定義文字分類與自定義具名實體辨識 ] 區段中,選取現有的記憶體帳戶,或選取 [ 新增記憶體帳戶]。 請注意,這些值可協助您開始使用,而不一定 是您想要在生產環境中使用的記憶體帳戶值 。 若要避免在建置項目時延遲,請連線到與語言資源位於相同區域中的記憶體帳戶。
儲存體 帳戶值 建議值 儲存體帳戶名稱 任何名稱 Storage account type 標準 LRS 請確定 已核取負責任 AI 通知 。 選取頁面底部的 [檢閱 + 建立] 。
將範例數據上傳至 Blob 容器
建立 Azure 記憶體帳戶並將其連線到您的語言資源之後,您必須將檔從範例數據集上傳至容器的根目錄。 這些檔稍後將用來定型模型。
下載多重標籤分類專案的範例數據集。
開啟 .zip 檔案,並解壓縮包含文件的資料夾。
提供的範例數據集包含大約 200 份檔,每個檔都是電影的摘要。 每個檔案都屬於下列一或多個類別:
- “神秘”
- “戲劇”
- “驚悚片”
- “喜劇”
- “Action”
在 Azure 入口網站 中,流覽至您所建立的記憶體帳戶,然後加以選取。 您可以按一下 [儲存體帳戶],然後在 [篩選任何欄位] 中輸入儲存體帳戶名稱來執行此動作。
如果您的資源群組未顯示,請確定 [訂用帳戶等於] 篩選條件已設定為 [全部]。
在您的儲存體帳戶中,從左側功能表中 [資料儲存體] 的下方選取 [容器]。 在出現的畫面中,選取 [+ 容器]。 提供容器名稱 example-data ,並保留預設 的公用存取層級。
建立容器之後,請加以選取。 然後選取 [上傳] 按鈕,以選取您稍早下載的
.txt和.json檔案。
取得您的資源金鑰和端點
移至 Azure 入口網站 中的資源概觀頁面
從左側的功能表中,選取 [金鑰] 和 [ 端點]。 您將針對 API 要求使用端點和金鑰

建立自訂文字分類專案
設定您的資源和記憶體容器之後,請建立新的自定義文字分類專案。 專案是一個工作區域,可根據您的數據建置自定義ML模型。 您的專案只能由您和其他人存取所使用之語言資源。
觸發匯入專案作業
使用下列 URL、標頭和 JSON 主體提交 POST 要求,以匯入您的卷標檔案。 請確定您的標籤檔案遵循 接受的格式。
如果具有相同名稱的項目已經存在,則會取代該專案的數據。
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
專案名稱。 此值區分大小寫。 | myProject |
{API-VERSION} |
您正在呼叫的 API 版本。 此處參考的值適用於發行的最新版本。 深入瞭解其他可用的 API 版本 | 2022-05-01 |
標頭
使用下列標頭來驗證您的要求。
| 機碼 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
資源的索引鍵。 用於驗證 API 要求。 |
本文
在您的要求中使用下列 JSON。 以您自己的值取代下方的佔位元值。
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectKind": "customMultiLabelClassification",
"description": "Trying out custom multi label text classification",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"settings": {}
},
"assets": {
"projectKind": "customMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class2"
}
]
}
]
}
}
| 索引鍵 | 預留位置 | 值 | 範例 |
|---|---|---|---|
| api-version | {API-VERSION} |
您正在呼叫的 API 版本。 這裡所使用的版本必須是 URL 中的相同 API 版本。 深入瞭解其他可用的 API 版本 | 2022-05-01 |
| projectName | {PROJECT-NAME} |
項目的名稱。 此值區分大小寫。 | myProject |
| projectKind | customMultiLabelClassification |
您的項目種類。 | customMultiLabelClassification |
| language | {LANGUAGE-CODE} |
字串,指定專案中所用文件的語言代碼。 如果您的專案是多語系專案,請選擇大部分文件的語言代碼。 若要深入瞭解多語系支援,請參閱 語言支援 。 | en-us |
| 多語種 | true |
布爾值,可讓您在數據集中具有多種語言的檔,而且當您的模型部署時,您可以使用任何支援的語言查詢模型(不一定包含在定型檔中。 若要深入瞭解多語系支援,請參閱 語言支援 。 | true |
| storageInputContainerName | {CONTAINER-NAME} |
您已上傳檔的 Azure 記憶體容器名稱。 | myContainer |
| 類別 | [] | 數位列,其中包含您在項目中擁有的所有類別。 這些是您想要將檔分類成的類別。 | [] |
| 文件 | [] | 數位列,其中包含您專案中的所有檔,以及為此檔加上標籤的類別。 | [] |
| location | {DOCUMENT-NAME} |
記憶體容器中檔的位置。 由於所有檔都在容器的根目錄中,因此這應該是檔名稱。 | doc1.txt |
| 資料集 | {DATASET} |
在定型前分割時,本檔會移至的測試集。 如需數據分割的詳細資訊,請參閱 如何定型模型 。 此欄位Train的可能值為 與 。 Test |
Train |
傳送 API 要求之後,您會收到 202 回應,指出作業已正確提交。 在響應標頭中,擷 operation-location 取值。 格式如下:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} 是用來識別您的要求,因為這項作業是異步的。 您將使用此網址來取得匯入作業狀態。
此要求可能發生的錯誤案例:
- 選取的資源沒有 記憶體帳戶的適當許可權 。
- 指定的
storageInputContainerName不存在。 - 使用無效的語言程式代碼,或者如果語言代碼類型不是字串,則為 。
multilingualvalue 是字串,而不是布爾值。
取得匯入作業狀態
使用下列 GET 要求來取得匯入項目的狀態。 以您自己的值取代下方的佔位元值。
要求 URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
項目的名稱。 此值區分大小寫。 | myProject |
{JOB-ID} |
用來尋找模型定型狀態的標識碼。 此值位於 location 您在上一個步驟中收到的標頭值。 |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
您正在呼叫的 API 版本。 此處參考的值適用於發行的最新版本。 深入瞭解其他可用的 API 版本 | 2022-05-01 |
標頭
使用下列標頭來驗證您的要求。
| 機碼 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
資源的索引鍵。 用於驗證 API 要求。 |
定型您的模型
一般而言,在您建立項目之後,請繼續並開始 標記您在容器中已連線至項目的檔 。 在本快速入門中,您已匯入範例標記數據集,並使用範例 JSON 卷標檔案初始化專案。
開始訓練您的模型
匯入項目之後,您就可以開始定型模型。
使用下列 URL、標頭和 JSON 主體提交 POST 要求,以提交定型作業。 以您自己的值取代下方的佔位元值。
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
項目的名稱。 此值區分大小寫。 | myProject |
{API-VERSION} |
您正在呼叫的 API 版本。 此處參考的值適用於發行的最新版本。 深入瞭解其他可用的 API 版本 | 2022-05-01 |
標頭
使用下列標頭來驗證您的要求。
| 機碼 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
資源的索引鍵。 用於驗證 API 要求。 |
要求本文
在您的要求本文中使用下列 JSON。 模型會在定型完成後提供 {MODEL-NAME} 。 只有成功的定型作業才會產生模型。
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| 索引鍵 | 預留位置 | 值 | 範例 |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
成功定型之後,將會指派給您模型的模型名稱。 | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
這是 將用來定型模型的模型版本 。 | 2022-05-01 |
| evaluationOptions | 在定型和測試集之間分割數據的選項。 | {} |
|
| kind | percentage |
分割方法。 可能的值為 percentage 或 manual。 如需詳細資訊,請參閱 如何定型模型 。 |
percentage |
| trainingSplitPercentage | 80 |
要包含在定型集中的標記數據百分比。 建議值為 80。 |
80 |
| testingSplitPercentage | 20 |
要包含在測試集中的標記數據百分比。 建議值為 20。 |
20 |
注意
trainingSplitPercentage只有在 設定為 percentage 且這兩個百分比的總和應等於 100 時Kind,才需要 和 testingSplitPercentage 。
傳送 API 要求之後,您會收到 202 回應,指出作業已正確提交。 在響應標頭中,擷 location 取值。 格式如下:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} 用來識別您的要求,因為這項作業是異步的。 您可以使用此網址來取得定型狀態。
取得訓練作業狀態
訓練可能需要10到30分鐘的時間。 您可以使用下列要求持續輪詢定型作業的狀態,直到順利完成為止。
使用下列 GET 要求來取得模型定型進度的狀態。 以您自己的值取代下方的佔位元值。
要求 URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
項目的名稱。 此值區分大小寫。 | myProject |
{JOB-ID} |
用來尋找模型定型狀態的標識碼。 此值位於 location 您在上一個步驟中收到的標頭值。 |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
您正在呼叫的 API 版本。 此處參考的值適用於發行的最新版本。 若要深入瞭解其他可用的 API 版本,請參閱 模型生命週期 。 | 2022-05-01 |
標頭
使用下列標頭來驗證您的要求。
| 機碼 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
資源的索引鍵。 用於驗證 API 要求。 |
回應本文
傳送要求之後,您會收到下列回應。
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
部署模型
一般而言,在定型模型之後,您會檢閱其 評估詳細數據 ,並 在必要時進行改進 。 在本快速入門中,您只會部署模型,並讓它可供您在 Language Studio 中試用,或者您可以呼叫 預測 API。
提交部署作業
使用下列 URL、標頭和 JSON 主體提交 PUT 要求,以提交部署作業。 以您自己的值取代下方的佔位元值。
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
項目的名稱。 此值區分大小寫。 | myProject |
{DEPLOYMENT-NAME} |
部署的名稱。 此值區分大小寫。 | staging |
{API-VERSION} |
您正在呼叫的 API 版本。 此處參考的值適用於發行的最新版本。 深入瞭解其他可用的 API 版本 | 2022-05-01 |
標頭
使用下列標頭來驗證您的要求。
| 機碼 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
資源的索引鍵。 用於驗證 API 要求。 |
要求本文
在要求的主體中使用下列 JSON。 使用您要指派給部署的模型名稱。
{
"trainedModelLabel": "{MODEL-NAME}"
}
| 索引鍵 | 預留位置 | 值 | 範例 |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
模型名稱會指派給您的部署。 您只能指派已成功定型的模型。 此值區分大小寫。 | myModel |
傳送 API 要求之後,您會收到 202 回應,指出作業已正確提交。 在響應標頭中,擷 operation-location 取值。 格式如下:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} 用來識別您的要求,因為這項作業是異步的。 您可以使用此網址來取得部署狀態。
取得部署作業狀態
使用下列 GET 要求來查詢部署作業的狀態。 您可以使用您從上一個步驟收到的 URL,或將下列佔位元值取代為您自己的值。
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
項目的名稱。 此值區分大小寫。 | myProject |
{DEPLOYMENT-NAME} |
部署的名稱。 此值區分大小寫。 | staging |
{JOB-ID} |
用來尋找模型定型狀態的標識碼。 這是您在 location 上一個步驟中收到的標頭值。 |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
您正在呼叫的 API 版本。 此處參考的值適用於發行的最新版本。 深入瞭解其他可用的 API 版本 | 2022-05-01 |
標頭
使用下列標頭來驗證您的要求。
| 機碼 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
資源的索引鍵。 用於驗證 API 要求。 |
回應本文
傳送要求之後,您會收到下列回應。 請持續輪詢此端點, 直到狀態 參數變更為「成功」為止。 您應該會取得程序 200 代碼,以指出要求是否成功。
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
分類文字
成功部署模型之後,您就可以開始使用模型,透過 預測 API 來分類文字。 在稍早下載的範例數據集中,您可以找到一些可在此步驟中使用的測試檔。
提交自定義文字分類工作
使用此 POST 要求啟動文字分類工作。
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
您正在呼叫的 API 版本。 此處參考的值適用於發行的最新版本。 若要深入瞭解其他可用的 API 版本,請參閱 模型生命週期 。 | 2022-05-01 |
標頭
| 機碼 | 數值 |
|---|---|
| Ocp-Apim-Subscription-Key | 提供此 API 存取權的金鑰。 |
本文
{
"displayName": "Classifying documents",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| 索引鍵 | 預留位置 | 值 | 範例 |
|---|---|---|---|
displayName |
{JOB-NAME} |
您的作業名稱。 | MyJobName |
documents |
[{},{}] | 要執行工作的檔案清單。 | [{},{}] |
id |
{DOC-ID} |
檔名稱或識別碼。 | doc1 |
language |
{LANGUAGE-CODE} |
指定檔案語言代碼的字串。 如果未指定此金鑰,服務會假設專案建立期間選取的專案默認語言。 如需支援的語言代碼清單,請參閱 語言支援 。 | en-us |
text |
{DOC-TEXT} |
要執行工作的檔工作。 | Lorem ipsum dolor sit amet |
tasks |
我們想要執行的工作清單。 | [] |
|
taskName |
CustomMultiLabelClassification | 工作名稱 | CustomMultiLabelClassification |
parameters |
要傳遞至工作的參數清單。 | ||
project-name |
{PROJECT-NAME} |
專案名稱。 此值區分大小寫。 | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
部署的名稱。 此值區分大小寫。 | prod |
回應
您會收到指出成功的 202 回應。 在回應 標頭中,擷取 operation-location。
operation-location 格式如下:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
您可以使用此 URL 來查詢工作完成狀態,並在工作完成時取得結果。
取得工作結果
使用下列 GET 要求來查詢文字分類工作的狀態/結果。
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
您要呼叫的 API 版本。 這裏參考的值適用於最新發行 的模型版本 。 | 2022-05-01 |
標頭
| 機碼 | 數值 |
|---|---|
| Ocp-Apim-Subscription-Key | 提供此 API 存取權的金鑰。 |
回應本文
回應將會是 JSON 檔,其中包含下列參數。
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxxxx-xxxxx-xxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "customMultiClassificationTasks",
"taskName": "Classify documents",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "{DOC-ID}",
"classes": [
{
"category": "Class_1",
"confidenceScore": 0.0551877357
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
清除資源
當您不再需要專案時,可以使用下列 DELETE 要求加以刪除。 將佔位元值取代為您自己的值。
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
專案名稱。 此值區分大小寫。 | myProject |
{API-VERSION} |
您正在呼叫的 API 版本。 此處參考的值適用於發行的最新版本。 深入瞭解其他可用的 API 版本 | 2022-05-01 |
標頭
使用下列標頭來驗證您的要求。
| 機碼 | 數值 |
|---|---|
| Ocp-Apim-Subscription-Key | 資源的索引鍵。 用於驗證 API 要求。 |
傳送 API 要求之後,您會收到 202 指出成功的回應,這表示您的專案已刪除。 成功的呼叫結果,其中包含 Operation-Location 用來檢查作業狀態的標頭。
下一步
建立自訂文字分類模型之後,您可以:
當您開始建立自己的自定義文字分類專案時,請使用操作說明文章進一步深入瞭解如何開發模型: