什麼是 Azure Cosmos DB 分析存放區?
適用於:![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Gremlin
Gremlin
重要
Microsoft Fabric 中的鏡像 (預覽版) 現在可在 NoSql API 中取得。 這項功能提供 Azure Synapse Link 的所有功能,具有更佳的分析效能、能夠將資料資產與 Fabric OneLake 整合,並以 Delta Parquet 格式開啟對 OneLake 資料的存取權。 如果您考慮使用 Azure Synapse Link,建議您嘗試鏡像以評估您組織的整體適合度。 若要開始使用鏡像,請按一下這裡。
若要開始使用 Azure Synapse Link,請造訪「開始使用 Azure Synapse Link」
Azure Cosmos DB 分析存放區是完全隔離的資料行存放區,可讓您針對 Azure Cosmos DB 中的操作資料進行大規模分析,而不會對交易式工作負載造成任何影響。
Azure Cosmos DB 交易存放區無從驗證結構描述,可讓您逐一查看交易應用程式,而不需處理結構描述或索引管理。 相較之下,Azure Cosmos DB 分析存放區會進行結構描述,以針對分析查詢效能進行最佳化。 本文將會詳細說明何謂分析式儲存體。
大規模分析操作資料的挑戰
Azure Cosmos DB 容器中的多模型操作資料會在內部儲存於以索引資料列為基礎的「交易存放區」中。 資料列存放區格式旨在加速交易讀取及寫入 (以毫秒為單位的回應時間) 和操作查詢。 如果您的資料集變得龐大,要在以這種格式儲存的資料上進行複雜的分析查詢,將可能會耗用大量的經佈建輸送量。 高度耗用經佈建輸送量會影響即時應用程式和服務所使用的交易式工作負載效能。
在過去,若要分析大量資料,會從 Azure Cosmos DB 的交易存放區中擷取操作資料,並加以儲存在不同的資料層中。 例如,資料會以適當的格式儲存在資料倉儲或 Data Lake 中。 此資料稍後會用於大規模分析,並使用計算引擎 (例如 Apache Spark 叢集) 進行分析。 分析與操作資料分離會延遲分析師想要使用最新資料的速度。
相較於只處理新內嵌的操作資料,ETL 管線在處理操作資料的更新時,也會變得很複雜。
資料行導向的分析存放區
Azure Cosmos DB 分析存放區可解決傳統 ETL 管線所發生的複雜性和延遲挑戰。 Azure Cosmos DB 分析存放區可以將您的操作資料自動同步處理到個別的資料行存放區。 資料行存放區格式適用於要以最佳化方式執行的大規模分析查詢,從而改善這類查詢的延遲。
您現在可以使用 Azure Synapse Link,直接從 Azure Synapse Analytics 連結至 Azure Cosmos DB 分析存放區,來建置無 ETL HTAP 解決方案。 其可讓您針對操作資料執行接近即時的大規模分析。
分析存放區的功能
當您在 Azure Cosmos DB 容器上啟用分析存放區時,會根據您容器中的操作資料,在內部建立新的資料行存放區。 此資料行存放區會與該容器的資料列導向交易存放區分開保存,此存放區會位於內部訂用帳戶中完全由 Azure Cosmos DB 管理的儲存體帳戶中。 客戶不需要花時間管理儲存體。 您的操作資料插入、更新和刪除作業會自動同步處理到分析存放區。 您不需要變更摘要或 ETL 來同步處理資料。
適用於操作資料分析工作負載的資料行存放區
分析工作負載通常包含所選取欄位的匯總和連續掃描。 資料分析存放區會以資料行為主的順序儲存,允許在適用的情況下將每個欄位的值序列化在一起。 此格式可減少掃描或計算特定欄位之統計資料所需的 IOPS。 其可大幅改善掃描大型資料集的查詢回應時間。
例如,如果您的操作表格採用下列格式:
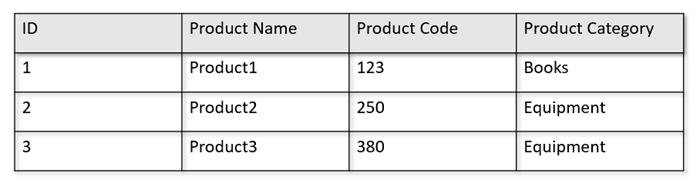
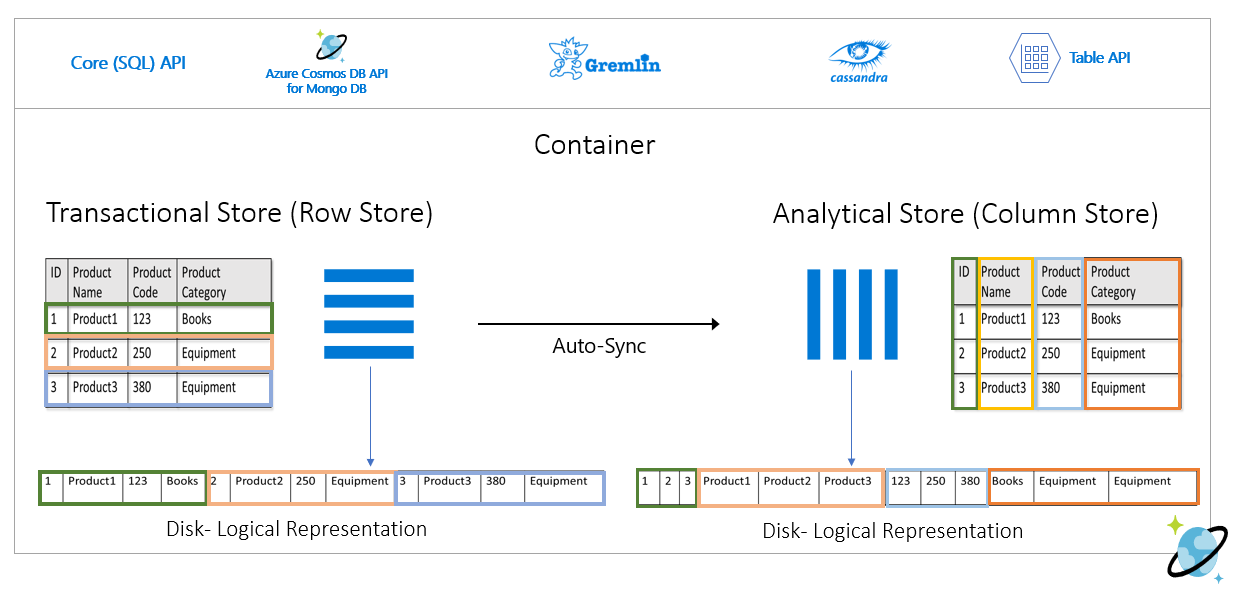
資料列存放區會在磁片上以序列化格式 (每一列) 保存上述資料。 此格式可加速交易讀取、寫入和操作查詢,例如「傳回 Product 1 的相關資訊」。 不過,當資料集擴增,且如果您想要對資料執行複雜的分析查詢,則可能會所費不貲。 例如,如果您想要取得「在不同的業務單位和月份,名為「設備」類別中的產品銷售趨勢」,則必須執行複雜查詢。 在此資料集上進行大量掃描,則佈建的輸送量可能會所費不貲,且也可能會影響驅動您即時應用程式和服務的交易工作負載效能。
分析存放區是一種資料行存放區,較適合這類查詢,因為其會將類似的資料欄位序列化在一起,並減少磁碟 IOPS。
下圖顯示 Azure Cosmos DB 中的交易資料列存放區與分析資料行存放區:
分析工作負載的低耦合效能
由於分析存放區與交易存放區分開,因此不會因分析查詢而影響您交易工作負載的效能。 分析存放區不需要配置個別的要求單位 (RU)。
自動同步
自動同步是指 Azure Cosmos DB 的完全受控功能,會近乎即時地將操作資料的插入、更新、刪除作業從交易存放區自動同步到分析存放區。 自動同步處理的延遲通常在 2 分鐘以內。 在具有大量容器的共用輸送量資料庫中,個別容器的自動同步延遲可能會較高,最多需要 5 分鐘的時間。
在每次執行自動同步處理流程結束時,您的交易資料將立即可供 Azure Synapse Analytics 執行階段使用:
Azure Synapse Analytics Spark 集區可以讀取所有資料,包括最新的更新、透過 Spark 資料表的自動更新,或透過會讀取資料最後狀態的
spark.read命令。Azure Synapse Analytics SQL 無伺服器集區可以讀取所有資料,包括從自動更新的檢視表所取得最近的更新,或是搭配會讀取資料最新狀態的
SELECT與OPENROWSET命令一起使用。
注意
即使您的交易存留時間 (TTL) 小於 2 分鐘,交易資料仍會同步處理至分析存放區。
注意
請注意,如果您刪除容器,也會一併刪除分析存放區。
可擴縮性和彈性
Azure Cosmos DB 交易存放區會使用水平資料分割,彈性地縮放儲存體和輸送量,而不需要停機。 交易存放區中的水平資料分割會提供自動同步的可擴縮性和彈性,以確保資料近乎即時地同步到分析存放區。 無論交易流量輸送量為何 (不論為 1000 個作業/秒或 100 萬個作業/秒),都會進行資料同步,且不會影響交易存放區中佈建的輸送量。
自動處理架構更新
Azure Cosmos DB 交易存放區無從驗證結構描述,可讓您逐一查看交易應用程式,而不需處理結構描述或索引管理。 相較之下,Azure Cosmos DB 分析存放區會進行結構描述,以針對分析查詢效能進行最佳化。 透過自動同步功能,Azure Cosmos DB 會透過交易存放區的最新更新來管理結構描述推斷。 還會管理現成分析存放區中的結構描述表示,包括處理嵌套的巢狀資料類型。
隨著結構描述演進,會在一段時間內新增新的屬性,而分析存放區會自動在交易存放區的所有歷程記錄結構描述中呈現集合聯集的結構描述。
注意
在分析存放區的內容中,我們將下列結構視為屬性:
- JSON 「元素」或 以
:分隔的字串-值組。 - JSON 物件 (以
{和}分隔)。 - JSON 陣列 (以
[和]分隔)。
結構描述條件約束
當您啟用分析存放區以自動推斷並正確地表示結構描述時時,下列條件約束將適用於 Azure Cosmos DB 中的操作資料:
文件結構描述的所有巢狀層級上都有 1000 個屬性的上限,而巢狀深度的上限為 127。
- 只有前 1000 個屬性會顯示在分析存放區中。
- 只有前 127 個巢狀層級會顯示在分析存放區中。
- JSON 文件的第一個層級是其
/根層級。 - 文件內第一個層級中的屬性將會以資料行表示。
範例案例:
- 如果您文件的第一層有 2000 個屬性,同步程序將會顯示其中前 1000 個屬性。
- 如果您的文件有各包含 200 個屬性的五個層級,則同步程序將會顯示所有屬性。
- 如果您的文件有 10 個層級,每個層級各有 400 個屬性,則同步程序將完全顯示前兩個層級,以及顯示第三個層級的一半。
下列假設文件中包含了四個屬性和三個層級。
- 層級為
root、myArray和myArray內的巢狀結構。 - 屬性為
id、myArray、myArray.nested1和myArray.nested2。 - 分析存放區會顯示出兩個資料行:
id和myArray。 您可以使用 Spark 或 T SQL 函數以將巢狀結構公開為資料行。
- 層級為
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
雖然 JSON 文件 (以及 Azure Cosmos DB 集合/容器) 會區分大小寫,但分析存放區並不會區分大小寫。
- 在同一份文件中:在不區分大小寫的狀況下,相同層級中的屬性名稱必須是獨一無二的。 例如,下列 JSON 文件在相同層級中有 "Name" 和 "name"。 雖然這是有效的 JSON 檔,但它並不符合唯一性條件約束,因此無法在分析存放區中完整表示。 在此範例中,以不區分大小寫的方式進行比較時,"Name" 和 "name" 是相同的。 由於系統先碰到了它,所以只有
"Name": "fred"會在分析存放區中表示出來。 而"name": "john"則完全不會呈現。
{"id": 1, "Name": "fred", "name": "john"}- 在不同的文件中:在同一層級中有著屬性和名稱完全相同,但大小寫不同的項目,則將會使用先首次出現的名稱格式,在相同的資料行內表示。 例如,下列 JSON 文件中在相同層級上具有
"Name"和"name"。 因為第一個文件格式是"Name",所以它會被用來代表分析存放區中的屬性名稱。 換句話說,分析存放區中的資料行名稱就是"Name"。"fred"和"john"都將表示在"Name"資料行中。
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}- 在同一份文件中:在不區分大小寫的狀況下,相同層級中的屬性名稱必須是獨一無二的。 例如,下列 JSON 文件在相同層級中有 "Name" 和 "name"。 雖然這是有效的 JSON 檔,但它並不符合唯一性條件約束,因此無法在分析存放區中完整表示。 在此範例中,以不區分大小寫的方式進行比較時,"Name" 和 "name" 是相同的。 由於系統先碰到了它,所以只有
集合的第一份文件會定義初始分析存放區結構描述。
- 具有比初始結構描述更多屬性的文件,將會在分析存放區中產生新的資料行。
- 資料行無法移除。
- 刪除集合中的所有文件並不會重設分析存放區結構描述。
- 沒有結構描述版本控制。 從交易式存放區推斷出的最新版本,即會是您將在分析存放區中看到的內容。
目前 Azure Synapse Spark 無法讀取名稱中包含某些特殊字元的屬性,詳細如下所示。 Azure Synapse SQL 無伺服器集群則不受影響。
- :
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- "
注意
當您達到此限制,系統也會在傳回的 Spark 錯誤訊息中列出空白字元。 但我們新增了對於空白字元的特殊處理方式,請參閱下列項目中的詳細資料。
- 如果您有使用上述字元的屬性名稱,替代方案為:
- 事先變更您的資料模型以避免使用這些字元。
- 由於我們目前不支援重設結構描述,您可以變更應用程式來新增具有類似名稱的備援屬性,以避免這些字元。
- 使用「變更摘要」來建立容器的具體化檢視,而不在屬性名稱中使用這些字元。
- 使用
dropColumnSpark 選項來忽略受影響的資料行,並將所有其他資料行載入到資料框架中。 語法為:
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- Azure Synapse Spark 現在支援在名稱中帶有空格的屬性。 若要這樣做,您必須使用
allowWhiteSpaceInFieldNamesSpark 選項將受影響的資料行載入到資料框架中,並保留原始名稱。 語法為:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
下列 BSON 資料類型不受支援,且不會在分析存放區中表示出來:
- Decimal128
- 規則運算式
- DB 指標
- JavaScript
- 符號
- MinKey/MaxKey
在使用遵循 ISO 8601 UTC 標準的日期時間字串時,請預期會有下列行為:
- Azure Synapse 中的 Spark 集區會將這些資料行表示為
string。 - Azure Synapse 中的 SQL 無伺服器集區會將這些資料行表示為
varchar(8000)。
- Azure Synapse 中的 Spark 集區會將這些資料行表示為
UNIQUEIDENTIFIER (guid)類型的屬性在分析存放區中會以string表示,而且在 SQL 中會轉換為VARCHAR,或在 Spark 中轉換成string,以取得正確的視覺效果。Azure Synapse 中的 SQL 無伺服器集區支援最多 1000 個資料行的結果集,而公開的巢狀資料行也會計入該限制。 建議您在交易資料架構和模型化中考慮這項資訊。
如果您在一或多個文件中重新命名屬性,它就會被視為新的資料行。 如果您在集合中的所有文件執行了相同的重新命名作業,則所有資料都會遷移至新的資料行,而舊資料行會以
NULL值表示。
結構描述表示法
分析存放區中有兩種結構描述表示法,適用於資料庫帳戶中的所有容器。 這兩者會在查詢體驗的簡單性,以及更多元的多型結構描述分欄式標記法的方便性之間進行取捨。
- 妥善定義的結構描述表示法,在適用於 NoSQL 和 Gremlin 的 API 帳戶中,這是預設選項。
- 完整精確度結構描述表示法,在適用於 MongoDB 的 API 帳戶中,這是預設選項。
妥善定義的結構描述表示法
妥善定義的結構描述表示法會在交易式存放區中,建立無從驗證結構描述的簡單表格式呈現。 採用妥善定義的結構描述表示法時有下列考量:
- 所有的文件都需要與定義了基底結構描述和屬性的第一份文件有著相同的類型。 唯一的例外是:
- 從
NULL到任何其他資料類型。 第一個非 null 的出現項目會定義資料行資料類型。 任何未遵循第一個非 null 資料類型的文件都不會在分析存放區中表示出來。 - 從
float變更為integer。 所有文件都會在分析存放區中表示出來。 - 從
integer變更為float。 所有文件都會在分析存放區中表示出來。 不過,若要使用 Azure Synapse SQL 無伺服器集區讀取此資料,您必須使用 WITH 子句來將資料行轉換成varchar。 在這個初始轉換之後,您可以再次將它轉換成數字。 請查看下列範例,其中 num 初始值為整數,而第二個值為浮點數。
- 從
SELECT CAST (num as float) as num
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = '<your-connection',
OBJECT = 'IntToFloat',
SERVER_CREDENTIAL = 'your-credential'
)
WITH (num varchar(100)) AS [IntToFloat]
未遵循基底結構描述資料類型的屬性將不會表示在分析存放區中。 例如,請參考以下文件:第一個定義了分析存放區基底結構描述。 第二個文件,其中
id為"2",不具有 妥善定義的架構,因為屬性"code"是字串,而第一份文件中"code"則是數字。 在此情況下,分析存放區會在容器存留期間將"code"的資料類型註冊為integer。 第二個文件仍會包含在分析存放區中,但它的"code"屬性不會包含在內。{"id": "1", "code":123}{"id": "2", "code": "123"}
注意
上述條件不適用於 NULL 屬性。 例如,{"a":123} and {"a":NULL} 仍妥善定義。
注意
如果您將文件 "1" 的 "code" 更新為交易式存放區中的字串,上述條件亦不會變更。 在分析存放區中,"code" 將會保留為 integer,因為我們目前不支援結構描述重設。
- 陣列類型必須包含單一重複的類型。 例如,
{"a": ["str",12]}不是妥善定義的結構描述,因為陣列中混合包含了整數和字串類型。
注意
如果 Azure Cosmos DB 分析存放區遵循妥善定義的結構描述標記法,而某些項目違反上述規格,則這些項目將不會包含在分析存放區中。
妥善定義的架構會對不同的類型會有不同的行為:
- Azure Synapse 中的 Spark 集區會將這些值表示為
undefined。 - Azure Synapse 中的 SQL 無伺服器集區會將這些值表示為
NULL。
- Azure Synapse 中的 Spark 集區會將這些值表示為
對於明確的
NULL值會有不同的行為:- Azure Synapse 中的 Spark 集區會將這些值讀取為
0(零),而一旦資料行具有非 null 值,就會讀取為undefined。 - Azure Synapse 中的 SQL 無伺服器集區會將這些值讀取為
NULL。
- Azure Synapse 中的 Spark 集區會將這些值讀取為
對於遺漏的資料行會有不同的行為:
- Azure Synapse 中的 Spark 集區會將這些資料行表示為
undefined。 - Azure Synapse 中的 SQL 無伺服器集區會將這些資料行表示為
NULL。
- Azure Synapse 中的 Spark 集區會將這些資料行表示為
表示挑戰的因應措施
使用不正確結構描述的舊文件可用來建立容器的分析存放區基底結構描述。 根據上述所有規則,您可能會在使用 Azure Synapse Link 查詢分析存放區時收到值為 NULL 的特定屬性。 刪除或更新有問題的文件並無幫助,因為目前不支援重設基底結構描述。 可能的解決方案包括:
- 將資料遷移至新的容器,並確定所有文件都有正確的結構描述。
- 放棄結構描述錯誤的屬性,並以另一個名稱新增在所有文件中都具有正確結構描述的新屬性。 範例:您在 Orders 容器中有數十億份文件,其中 status 屬性是字串。 但該容器中的第一份文件具有以整數定義的 status。 因此,其中一份文件的 status 會正確表示,而所有其他文件都會出現
NULL。 您可以將 status2 屬性新增至所有文件,並開始使用該屬性,而不是使用原始屬性。
完整精確度的結構描述表示法
完整精確度結構描述表示法專門設計用來在無從驗證結構描述操作資料中,全面掌握多型結構描述。 在此結構描述表示法中,即使違反了妥善定義的結構描述條件約束 (也就是不能混合檔案類型欄位,也不能混合檔案類型陣列),也不會從分析存放區卸除任何項目。
若要這麼做,可將操作資料的分葉屬性轉譯成 JSON key-value 組合形式的分析存放區,其中資料類型是 key,而屬性內容是 value。 此 JSON 物件表示法可讓查詢沒有歧異,而且您可以個別分析每個資料類型。
換句話說,在完整精確度的結構描述表示法中,每個文件中每個屬性的每個資料類型都會在該屬性的 JSON 物件中產生 key-value 組合。 每個組合都會視為上限為 1000 個屬性中的其中一個。
例如,假設交易式存放區中有下列範例文件:
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
巢狀物件 address 是文件根層級中的屬性,而且會以資料行表示。 address 物件中的每個分葉屬性都會以 JSON 物件表示:{"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}。
與妥善定義的結構描述表示法不同,完整精確度方法允許資料類型的變化。 如果上述範例集合中的下一份文件具有字串形式的 streetNo,其會在分析存放區中表示為 "streetNo":{"string":15850}。 在妥善定義的結構描述方法中,這將不會表示出來。
適用於完整精確度結構描述的資料類型對應
以下是分析存放區中 MongoDB 資料類型及其表示法的對應表,以完整精確度結構描述呈現。 下方的對應不適用於 NoSQL API 帳戶。
| 原始資料類型 | 尾碼 | 範例 |
|---|---|---|
| Double | ".float64" | 24.99 |
| 陣列 | ".array" | ["a", "b"] |
| 二進位 | ".binary" | 0 |
| 布林值 | ".bool" | True |
| Int32 | ".int32" | 123 |
| Int64 | ".int64" | 255486129307 |
| NULL | ".NULL" | NULL |
| String | ".string" | "ABC" |
| 時間戳記 | ".timestamp" | Timestamp(0, 0) |
| ObjectId | ".objectId" | ObjectId("5f3f7b59330ec25c132623a2") |
| 文件 | ".object" | {"a": "a"} |
對於明確的
NULL值會有不同的行為:- Azure Synapse 中的 Spark 集區會將這些值讀取為
0(零)。 - Azure Synapse 中的 SQL 無伺服器集區會將這些值讀取為
NULL。
- Azure Synapse 中的 Spark 集區會將這些值讀取為
對於遺漏的資料行會有不同的行為:
- Azure Synapse 中的 Spark 集區會將這些資料行表示為
undefined。 - Azure Synapse 中的 SQL 無伺服器集區會將這些資料行表示為
NULL。
- Azure Synapse 中的 Spark 集區會將這些資料行表示為
對於
timestamp值會有不同的行為:- Azure Synapse 中的 Spark 集區會將這些值讀取為
TimestampType、DateType或Float。 這取決於範圍和時間戳記的產生方式。 - Azure Synapse 中的 SQL 無伺服器集區會將這些值讀取為
DATETIME2,範圍介於0001-01-01到9999-12-31之間。 超出此範圍的值不受支援,而且會導致查詢的執行失敗。 如果這符合您的案例,您可以:- 從查詢中移除資料行。 若要保留表示法,您可以建立與該資料行互為鏡像,但在支援範圍內的新屬性。 並在您的查詢中使用。
- 使用分析存放區的異動資料擷取 (無需任何 RU 成本),在其中一個支援的接收器內將資料轉換成新的格式並載入。
- Azure Synapse 中的 Spark 集區會將這些值讀取為
搭配 Spark 使用完整精確度結構描述
載入至 DataFrame 時,Spark 會以資料行的形式管理每個資料類型。 讓我們假設集合中包含下列文件。
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
雖然第一份文件有數字形式的 rating 和 utc 格式的 timestamp,但第二份文件有字串形式的 rating 和 timestamp。 假設此集合已載入 DataFrame,而且沒有任何資料轉換,則 df.printSchema() 的輸出為:
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
在妥善定義的結構描述表示法中,第二份文件的 rating 和 timestamp 不會表示出來。 在完整精確度結構描述中,您可以使用下列範例個別存取每個資料類型的每個值。
在下列範例中,我們可使用 PySpark 來執行彙總:
df.groupBy(df.item.string).sum().show()
在下列範例中,我們可使用 PySQL 來執行另一個彙總:
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
搭配 SQL 使用完整精確度結構描述
您可以使用下列語法範例,搭配上述 Spark 範例的相同文件:
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
您若要實作轉換,可以使用 cast、convert 或其他任何 T-SQL 函式來操作資料。 您也可以使用檢視來隱藏複雜的資料類型結構。
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
使用 MongoDB _id 欄位
MongoDB _id 欄位是 MongoDB 中每個集合的基礎,原始為十六進位標記法。 如上表所示,完整精確度結構描述將會保留其特性,並在 Azure Synapse Analytics 中產生其視覺化的挑戰。 若要取得正確的視覺效果,您必須依照下列步驟轉換 _id 資料類型:
在 Spark 中使用 MongoDB _id 欄位
下列範例適用於 Spark 2.x 和 3.x 版本:
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
在 SQL 中使用 MongoDB _id 欄位
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET('CosmosDB',
'Your-account;Database=your-database;Key=your-key',
HTAP) WITH (_id VARCHAR(1000)) as HTAP
使用 MongoDB id 欄位
MongoDB 容器中的 id 屬性會自動覆寫在分析存放區中的 "_id" 屬性 Base64 表示法。 "id" 欄位適用於 MongoDB 應用程式的內部使用。 目前唯一的因應措施是將 "id" 屬性重新命名為 "id" 以外的項目。
NoSQL 或 Gremlin API 帳戶的完整精確度結構描述
您可以在第一次啟用 Azure Cosmos DB 帳戶的 Synapse Link 時設定結構描述類型,藉此在適用於 NoSQL 的 API 帳戶上使用完整精確度結構描述,而不是使用預設選項。 以下是變更預設結構描述表示法類型的相關考量:
- 目前,如果您使用 Azure 入口網站在 NoSQL API 帳戶中啟用 Synapse Link,則會啟用妥善定義的結構描述。
- 目前,如果您想要搭配 NoSQL 或 Gremlin API 帳戶使用完整精確度結構描述,您必須使用相同 CLI 或 PowerShell 命令中在帳戶層級上進行設定,才能在帳戶層級啟用 Synapse Link。
- 目前適用於 Azure Cosmos DB for MongoDB 無法進行此種對於結構描述表示法的變更作業。 所有 MongoDB 帳戶都具有完整精確度結構描述表示法類型。
- 上述完整精確度結構描述資料類型對應對於使用 JSON 資料類型的 NoSQL API 帳戶無效。 例如,
float和integer值會在分析存放區中以num的形式表示。 - 您無法將結構描述表示法從「妥善定義」為重設為「完整精確度」,反之亦然。
- 目前,即使資料庫帳戶中尚未啟用 Synapse Link,分析存放區中的容器結構描述也會在容器建立時進行定義。
- 在啟用 Synapse Link 之前建立的容器或圖形,且帳戶層級具有完整精確度結構描述,則會具有妥善定義的結構描述。
- 在啟用 Synapse Link 之後建立的容器或圖形,且帳戶層級有完整精確度結構描述,則會具有完整精確度結構描述。
使用 Azure CLI 或 PowerShell 在帳戶上啟用 Synapse Link 時,必須同時決定要使用何種結構描述表示法類型。
使用 Azure CLI 時:
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
注意
在上述命令中,將 create 取代為現有帳戶的 update。
使用 PowerShell 時:
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
注意
在上述命令中,將 New-AzCosmosDBAccount 取代為現有帳戶的 Update-AzCosmosDBAccount。
分析存留時間 (TTL)
分析 TTL (ATTL) 指出容器的資料應在分析存放區中保留的時間長度。
當使用除了 NULL 和 0 以外的值設定 ATTL 時,變會啟用分析存放區。 在啟動後,插入、更新、刪除操作資料會自動從交易存放區同步至分析存放區,不論交易式 TTL (TTTL) 組態為何。 對於此交易資料在分析存放區中的保留,可以透過 AnalyticalStoreTimeToLiveInSeconds 屬性在容器層級進行控制。
可能的 ATTL 組態設定如下:
如果值設定為
0:分析存放區已停用,且不會將數據從交易存放區複寫到分析存放區。 請開啟支援案例,以停用容器中的分析存放區。如果值設定為
null:分析存放區已停用。 如果null已設定,則不會發生任何事,且會保留先前的值。如果值設定為
-1:分析存放區會保留所有歷程記錄資料,而不論交易存放區中的資料保留期。 此設定表示分析存放區具有無限的操作資料保留期如果值設為任何的正整數
n數字:項目將會在交易存放區的上次修改時間n秒之後,在分析存放區中到期。 如果您想要在分析存放區中,將操作資料保留一段有限的時間,不論交易存放區中的資料保留期,都可以利用此設定
考慮事項:
- 使用 ATTL 值啟用分析存放區之後,稍後可將其更新為其他有效的值。
- 雖然 TTTL 可以在容器或項目層級設定,但 ATTL 目前只能在容器層級設定。
- 您可以在容器層級設定 ATTL >= TTTL,從而在分析存放區中達到更長的操作資料保留期。
- 您可以設定 ATTL = TTTL,來建立分析存放區鏡像交易存放區。
- 如果您的 ATTL 大於 TTTL,到了某個時間點後,您將會有只存在於分析存放區中的資料。 此資料為唯讀。
- 目前我們不會從分析存放區刪除任何資料。 如果您將 ATTL 設定為任何正整數,則資料不會包含在您的查詢中,而且不會向您收取費用。 但是,如果您將 ATTL 變更回
-1,則所有資料都會再次顯示,您將會開始支付所有資料量的費用。
如何啟用容器上的分析存放區:
在 Azure 入口網站中,當 ATTL 選項開啟時,其預設值為 -1。 您可以藉由流覽至 [資料總管] 下的 [容器設定],將此值變更為 'n' 秒。
您可以從 Azure 管理 SDK、Azure Cosmos DB SDK、PowerShell 或 Azure CLI,將 ATTL 選項設定為 -1 或 'n'' 秒來加以啟用。
若要進一步了解,請參閱如何在容器上設定分析 TTL。
歷程記錄資料的成本效益分析
資料分層是指針對不同案例進行最佳化之儲存體基礎結構之間的資料分離。 因此可提升端對端資料堆疊的整體效能和成本效益。 Azure Cosmos DB 現在可透過分析存放區,支援從交易存放區將資料自動分層至具有不同資料配置的分析存放區。 相較於交易存放區,使用儲存成本最佳化的分析存放區可讓您保留更長的操作資料範圍來進行歷史分析。
啟用分析存放區之後,您可以根據交易工作負載的資料保留需求,設定 transactional TTL 屬性,以在一段時間後自動從交易存放區中刪除記錄。 同樣地,analytical TTL 可讓您管理保留在分析存放區中的資料生命週期,其與交易存放區無關。 您可以啟用分析存放區及設定 TTL 屬性,順暢地分層並定義兩個存放區的資料保留期間。
注意
當 analytical TTL 設定為大於 transactional TTL 的值時,您的容器會有只存在於分析存放區中的資料。 這是唯讀資料,目前我們不支援分析存放區中的文件層級 TTL。 如果您的容器資料在未來某個時間點可能需要更新或刪除,請勿使用 大於 transactional TTL的 analytical TTL。 對於未來不需要更新或刪除的資料,建議使用這項功能。
注意
如果您的案例不需要實體刪除,您可採用邏輯刪除/更新方法。 在交易存放區中插入另一個只存在於分析存放區中,但需要邏輯刪除/更新的相同文件版本。 或許使用旗標,指出這是過期文件的刪除或更新。 這兩個版本的相同文件會共存於分析存放區中,而且您的應用程式應該只考慮最後一個版本。
復原能力
分析存放區依賴 Azure 儲存體,並提供下列保護,以防止實體失敗:
- 根據預設,Azure Cosmos DB 資料庫帳戶會在本地備援儲存體 (LRS) 帳戶中配置分析存放區。 LRS 提供在指定一年內至少 99.999999999% (11 個九) 的物件持久性。
- 如果資料庫帳戶的任何異地區域設定為區域備援,則會在區域備援儲存體 (ZRS) 帳戶中進行配置。 您必須在其 Azure Cosmos DB 資料庫帳戶的區域上啟用可用性區域,才能將該區域的分析資料儲存在區域備援儲存體中。 ZRS 提供儲存體資源在指定一年中至少 99.9999999999% (12 個 9) 的持久性。
如需 Azure 儲存體持久性的詳細資訊,請參閱此連結。
Backup
雖然分析存放區具有對實體失敗的內建保護,但在交易存放區中意外刪除或更新時,可能需要備份。 在這些情況下,您可以還原容器,並使用還原的容器來回填原始容器中的資料,或視需要完全重建分析存放區。
注意
目前不會備份分析存放區,因此無法還原。 您無法據此規劃備份原則。
因此,Synapse Link 和分析存放區具有與 Azure Cosmos DB 備份模式不同的相容性層級:
- 定期備份模式與 Synapse Link 完全相容,而這 2 個功能可以在相同的資料庫帳戶中使用。
- 使用連續備份模式資料庫帳戶的 Synapse Link 是正式發行。
- 啟用 Synapse Link 帳戶、連續備份模式處於公開預覽狀態。 目前,如果您在 Cosmos DB 帳戶中的任何集合上停用 Synapse Link,則無法移轉至連續備份。
備份原則
有兩個可能的備份原則,您需要了解如何使用這些原則,下列關於 Azure Cosmos DB 備份的詳細資料非常重要:
- 在兩種備份模式下,原始容器會在沒有分析存放區的情況下還原。
- Azure Cosmos DB 不支援從還原覆寫容器。
現在讓我們了解如何從分析存放區的觀點使用備份和還原。
還原 TTTL >= ATTL 的容器
當 transactional TTL 等於或大於 analytical TTL 時,分析存放區中的所有資料仍存在於交易存放區中。 如果是還原,您有兩種可能的情況:
- 若要使用還原的容器作為原始容器的取代項目。 若要重建分析存放區,只要在帳戶層級和容器層級啟用 Synapse Link 即可。
- 若要使用還原的容器作為資料來源來回填或更新原始容器中的資料。 在此情況下,分析存放區會自動反映資料作業。
還原 TTTL < ATTL 的容器
當 transactional TTL 小於 analytical TTL 時,某些資料只會存在於分析存放區,而不會在還原的容器中。 同樣地,您有兩種可能的情況:
- 若要使用還原的容器作為原始容器的取代項目。 在此情況下,當您在容器層級啟用 Synapse Link 時,只有交易存放區中的資料會包含在新的分析存放區中。 但請注意,只要原始容器存在,原始容器的分析存放區仍可供查詢。 您可能想要變更應用程式以查詢這兩者。
- 若要使用還原的容器作為資料來源來回填或更新原始容器中的資料:
- 分析存放區會自動反映交易存放區中資料的資料作業。
- 如果您因為
transactional TTL而重新插入先前從交易存放區中移除的資料,此資料會在分析存放區中重複。
範例:
- 容器
OnlineOrders的 TTTL 設定為一個月,而 ATTL 設定為一年。 - 當您將它還原至
OnlineOrdersNew並開啟分析存放區來重建時,交易式和分析存放區中只會有一個月的資料。 - 原始容器
OnlineOrders不會刪除,而且其分析存放區仍然可供使用。 - 新的資料只會內嵌到
OnlineOrdersNew中。 - 分析查詢將會從分析存放區進行集合聯集,而原始資料仍保持相關。
如果您想要刪除原始容器,但不想遺失其分析存放區資料,您可以將原始容器的分析存放區保存在另一個 Azure 資料服務中。 Synapse Analytics 能夠在儲存於不同位置的資料之間執行聯結。 範例:Synapse Analytics 查詢會聯結分析存放區資料與位於 Azure Blob 儲存體、Azure Data Lake 存放區等的外部資料表。
請務必注意,分析存放區中的資料與交易式存放區中存在的結構描述有所不同。 雖然您可以產生分析存放區資料的快照集,並在不產生 RU 費用的情況下將其匯出至任何 Azure 資料服務,但我們無法保證能使用此快照集來對交易式存放區進行回送。 不支援此流程。
全域散發
如果您有全域散發的 Azure Cosmos DB 帳戶,則在啟用容器的分析存放區之後,該帳戶在所有區域都將可使用。 對操作資料所做的任何變更都會在所有區域中全域複寫。 您可以對 Azure Cosmos DB 中最近區域的資料複本,有效地執行分析查詢。
資料分割
分析存放區的資料分割與交易式存放區中的資料分割完全無關。 根據預設,分析存放區中的資料不會進行資料分割。 如果您的分析查詢有常用的篩選條件,即可選擇根據這些欄位進行資料分割,獲得更佳的查詢效能。 若要深入了解,請參閱自訂資料分割簡介與如何設定自訂資料分割。
安全性
分析存放區的驗證與指定資料庫的交易存放區相同。 您可以使用主要、次要或唯讀金鑰進行驗證。 您可以利用 Synapse Studio 中的連結服務,避免將 Azure Cosmos DB 金鑰貼入 Spark 筆記本中。 針對 Azure Synapse SQL 無伺服器集群,您可以使用 SQL 認證以避免在 SQL 筆記本中貼上 Azure Cosmos DB 金鑰。 任何具有該工作區存取權限的人,都可以存取這些連結服務或 SQL 認證。 請注意,您也可以使用 Azure Cosmos DB 的唯讀金鑰。
使用私人端點進行網路隔離 - 您可以獨立控制對交易式和分析存放區中資料的網路存取。 針對 Azure Synapse 工作區中受控虛擬網路內的每個存放區,使用個別的受控私人端點進行網路隔離。 若要深入了解,請參閱如何設定分析存放區的私人端點一文。
待用資料加密 - 分析存放區加密預設為啟用。
使用客戶自控金鑰進行資料加密 - 您可以自動且透明的方式使用相同的客戶自控金鑰,在交易式和分析存放區之間順暢地加密資料。 Azure Synapse Link 僅支援使用您的 Azure Cosmos DB 帳戶受控識別來設定客戶自控金鑰。 您必須在您的 Azure Key Vault 存取原則中設定受控識別,才能在您的帳戶上啟用 Azure Synapse Link。 如需深入瞭解,請參閱「如何使用 Azure Cosmos DB 帳戶的受控識別來設定客戶自控金鑰」一文的內容。
注意
如果您將資料庫帳戶從第一方變更為系統或使用者指派的身分識別,並在資料庫帳戶中啟用 Azure Synapse Link,您將無法返回第一方身分識別,因為您無法從資料庫帳戶停用 Synapse Link。
支援多個 Azure Synapse Analytics 執行階段
分析存放區已最佳化,可提供分析工作負載的可擴縮性、彈性、效能,而不會對計算執行時間產生任何相關性。 儲存技術會進行自我管理,可將您的分析工作負載最佳化,而無須手動進行。
從 Azure Synapse Analytics 所支援的不同分析執行階段同時查詢 Azure Cosmos DB 分析存放區中的資料。 Azure Synapse Analytics 支援 Apache Spark 和無伺服器 SQL 集區,搭配 Azure Cosmos DB 分析存放區。
注意
您只能使用 Azure Synapse Analytics 執行階段從分析存放區進行讀取。 相反的情況也是如此,Azure Synapse Analytics 執行階段只能從分析存放區進行讀取。 只有自動同步處理流程可以變更分析存放區中的資料。 您可以使用內建的 Azure Cosmos DB OLTP SDK,藉由 Azure Synapse Analytics Spark 集區將資料寫回 Azure Cosmos DB 的交易式存放區。
定價
分析存放區會遵循以耗用量為基礎的定價模型,其中您需支付下列費用:
儲存體:每月保留在分析存放區中的資料量,包括分析 TTL 所定義的歷程記錄資料。
分析寫入作業:從交易存放區將完全管理的操作資料更新同步至分析存放區 (自動同步)
分析讀取作業:從 Azure Synapse Analytics Spark 集區和無伺服器 SQL 集區執行時間針對分析存放區執行的讀取作業。
分析存放區定價與交易存放區定價模式不同。 分析存放區中沒有已佈建 RU 的概念。 如需分析存放區定價模式的完整詳細資料,請參閱 Azure Cosmos DB 定價頁面。
分析存放區中的資料只能透過在 Azure Synapse Analytics 執行階段中完成的 Azure Synapse Link 來存取:Azure Synapse Apache Spark 集區和 Azure Synapse 無伺服器 SQL 集區。 如需有關存取分析存放區中資料的定價模式詳細資訊,請參閱 Azure Synapse Analytics 定價頁面。
若要取得高階成本預估值,以在 Azure Cosmos DB 容器上啟用分析存放區,從分析存放區的角度來說,您可以使用 Azure Cosmos DB 容量規劃工具,並取得分析儲存體和寫入作業成本的預估值。
分析存放區讀取作業預估並不包含在 Azure Cosmos DB 成本計算中,因為它們屬於分析式工作負載的功能。 但做為高階預估值,掃描分析存放區中 1 TB 的資料通常會產生 130,000 個分析讀取作業,並產生 $0.065 的成本。 例如,如果您使用 Azure Synapse 無伺服器 SQL 集區來執行 1 TB 的掃描,則會根據 Azure Synapse Analytics 定價頁面產生 $5.00 美元的費用。 此 1 TB 掃描的最終總成本為 $5.065。
雖然上述的估計值根據的是掃描分析存放區中的 1TB 資料而定,但套用篩選後會減少掃描的資料量,而讀取作業的確切數量則會根據取用量定價模型來判斷。 對於分析工作負載的概念證明,可針對分析讀取作業提供更精細的估計。 此估計不包含 Azure Synapse Analytics 的成本。
下一步
若要深入了解,請參閱下列文件: