Azure Cosmos DB for Apache Cassandra 中的資料分割
適用於:![]() Cassandra
Cassandra
本文描述資料分割在 Azure Cosmos DB for Apache Cassandra 中的運作方式。
Cassandra API 會使用分割區調整 Keyspace 中的個別資料表,以符合應用程式的效能需求。 分割區是根據與資料表中每一筆記錄相關聯的分割區索引鍵值所組成。 分割區中的所有記錄都有相同的分割區索引鍵值。 Azure Cosmos DB 會在背景自動管理實體資源之間的分割區位置,以有效率地滿足資料表的可擴縮性與效能需求。 隨著應用程式的輸送量與儲存體需求增加,Azure Cosmos DB 會在更多的實體機器之間移動及平衡資料。
從開發人員的觀點而言,分割區在 Azure Cosmos DB for Apache Cassandra 的行為方式與其在原生 Apache Cassandra 中相同。 然而,幕後作業有一些差異。
Apache Cassandra 與 Azure Cosmos DB 之間的差異
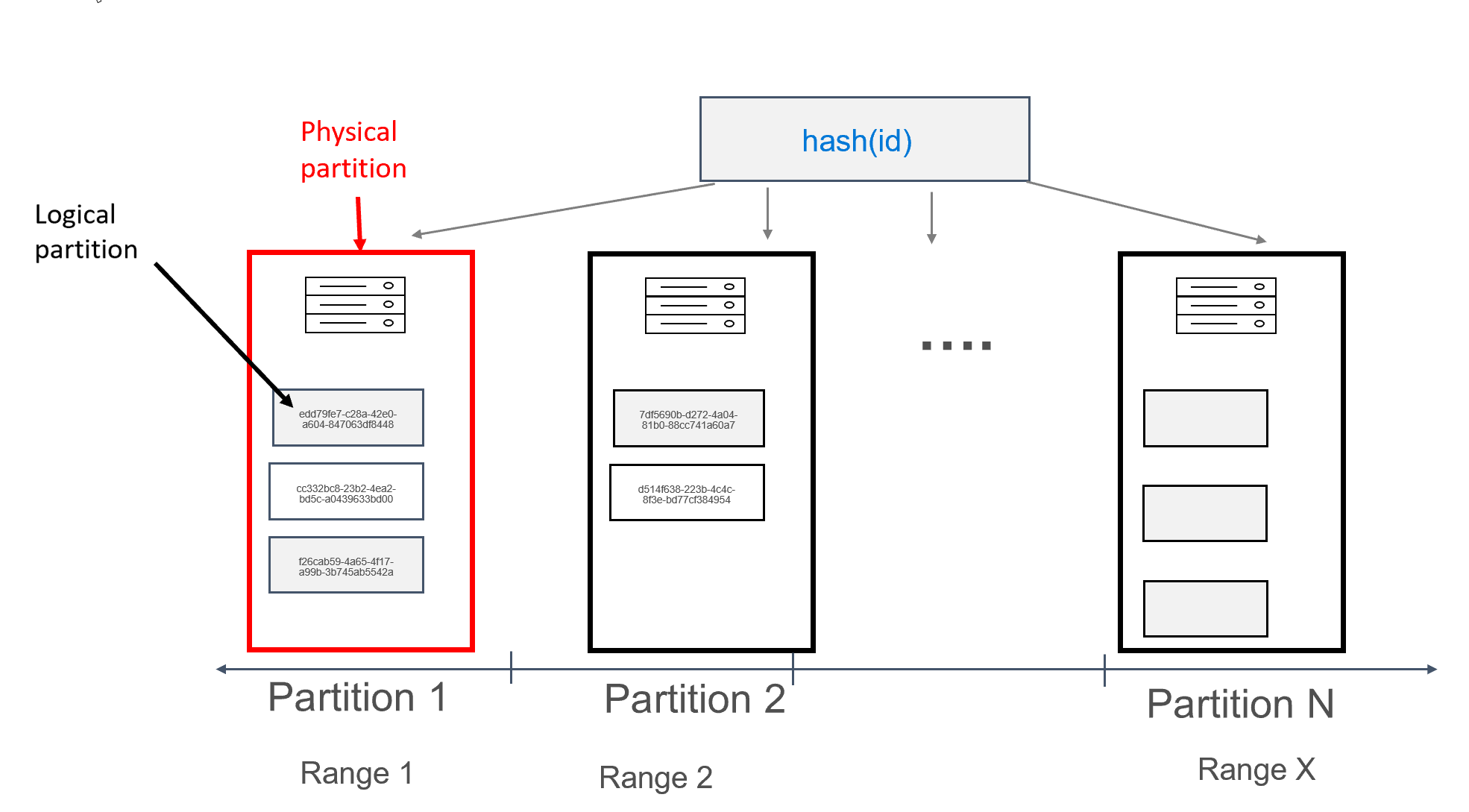
在 Azure Cosmos DB 中,已儲存分割區的每一部機器本身都稱為實體分割區。 實體分割區類似於虛擬機器;專用計算單位,或是實體資源集。 在 Azure Cosmos DB 中,此計算單位上儲存的每個分割區都稱為邏輯分割區。 若您已經熟悉 Apache Cassandra,則可透過如同思考 Cassandra 中一般分割區的方式來思考邏輯分割區。
針對可儲存在分割區中的資料大小,Apache Cassandra 建議 100 MB 的限制。 Azure Cosmos DB 的 Cassandra API 允許每個邏輯分割區最多有 20 GB,而每個實體分割區最多有 30 GB 的資料。 在 Azure Cosmos DB 中,與 Apache Cassandra 不同的是,實體分割區中可用的計算能力使用稱為要求單位的單一計量表達,這可讓您將工作負載視為每秒的要求 (讀取或寫入),而不是核心、記憶體或 IOPS。 如此便可在了解每個要求的成本之後,更快地進行容量規劃。 每個實體分割區最多可以提供 10000 個 RU 的計算。 若要深入了解可擴縮性選項,請閱讀 Cassandra API 中的彈性調整文章。
在 Azure Cosmos DB 中,每個實體分割區都包含一組複本 (也稱為「複本集」),每個分割區至少有 4 個複本。 這與 Apache Cassandra 相反,其可將複寫因數設定為 1。 然而,若具有資料的唯一節點停止運作,則會導致低可用性。 在 Cassandra API 中,一律有 4 個複寫因素 (3 個仲裁)。 Azure Cosmos DB 會自動管理複本集,而這些都必須使用 Apache Cassandra 中的各種工具進行維護。
Apache Cassandra 具有權杖的概念,也就是分割區索引鍵的雜湊。 這些權杖以 murmur3 64 位元組雜湊為基礎,其值範圍從 -2^63 到 -2^63 - 1。 此範圍在 Apache Cassandra 中通常稱為「權杖環」。 權杖環會散發到權杖範圍,而這些範圍會在原生 Apache Cassandra 叢集中的節點之間進行分割。 Azure Cosmos DB 的分割區會以類似的方式實作,但其會使用不同的雜湊演算法,且具有較大的內部權杖環。 然而,我們會對外公開與 Apache Cassandra 相同的權杖範圍,例如:-2^63 到 -2^63 - 1。
主要金鑰
Cassandra API 中的所有資料表都必須定義 primary key。 主索引鍵的語法如下所示:
column_name cql_type_definition PRIMARY KEY
假設我們想要建立一個使用者資料表,其儲存不同使用者的訊息:
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
在此設計中,我們已將 id 欄位定義為主索引鍵。 主索引鍵作為資料表中記錄的識別碼,也用作 Azure Cosmos DB 中的分割區索引鍵。 若主索引鍵是以先前描述的方式所定義,則每個分割區中只會有一筆記錄。 這會在將資料寫入資料庫時產生完美水平且可調整的散發,而且非常適合用於索引鍵/值查閱使用案例。 該應用程式應該在每次讀取資料表中的資料時提供主索引鍵,以將讀取效能最大化。
複合主索引鍵
Apache Cassandra 也有 compound keys 的概念。 複合 primary key 是由多個資料行所組成;第一個資料行是 partition key,而任何其他資料行則是 clustering keys。 compound primary key 的語法如下所示:
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
假設我們想要變更上述設計,使其能夠有效率地擷取指定使用者的訊息:
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
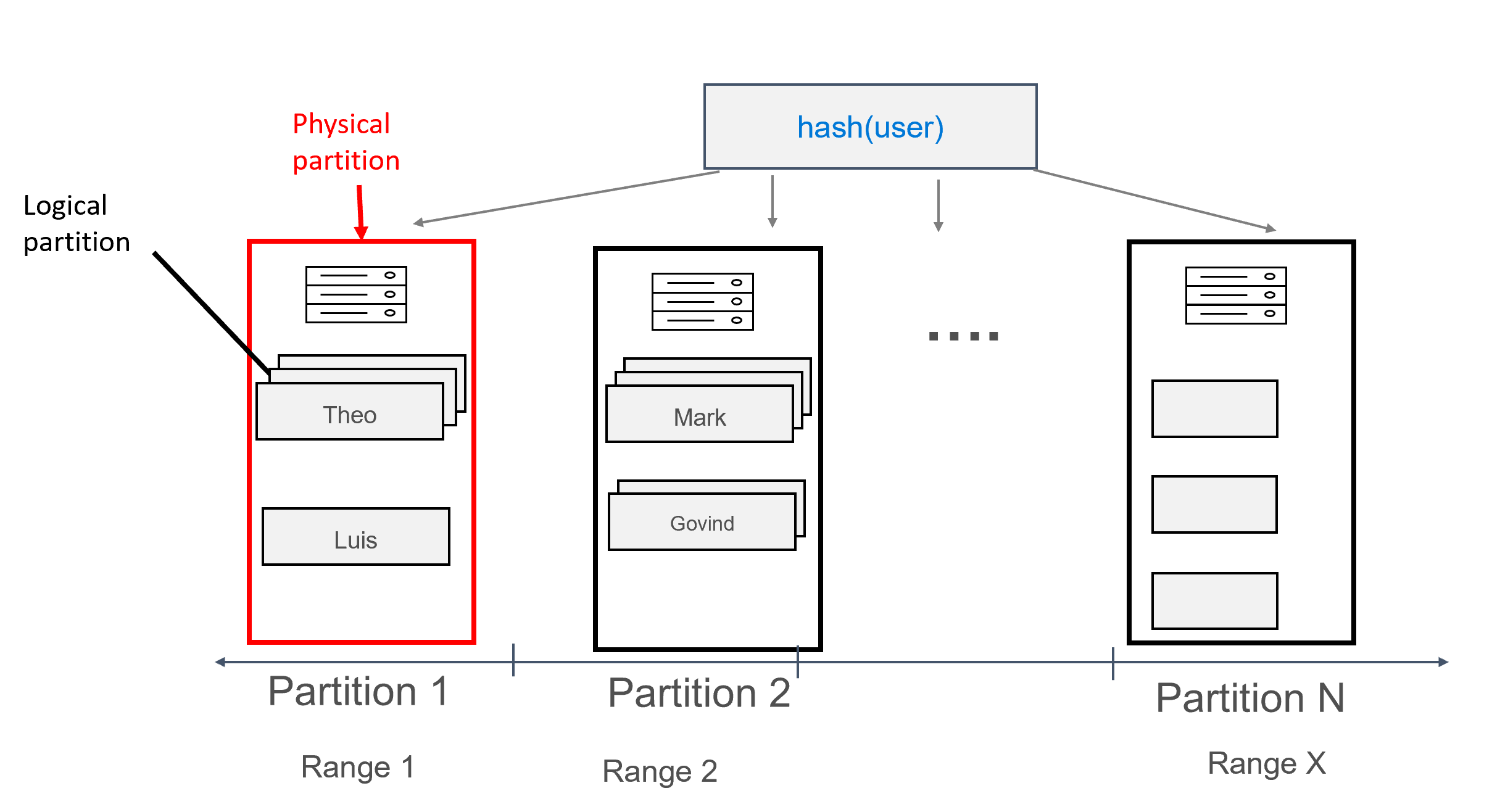
在此設計中,我們現在會將 user 定義為分割區索引鍵,並將 id 定義為叢集索引鍵。 您可以視需要定義多個叢集索引鍵,但叢集索引鍵的每個值 (或值組合) 都必須是唯一值,才能產生新增至相同分割區的多筆記錄,例如:
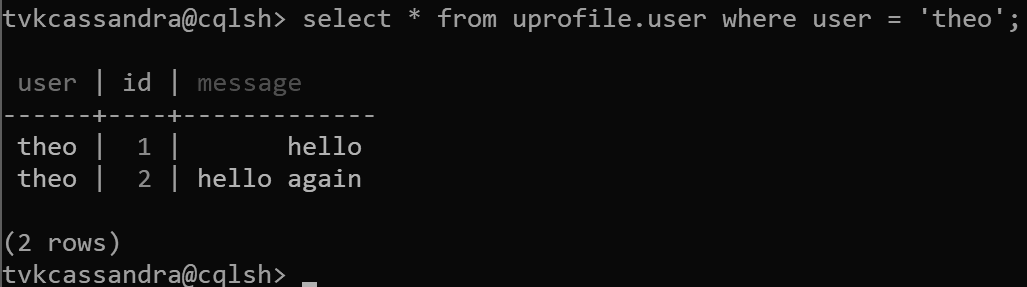
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
傳回資料時,會在 Apache Cassandra 中如預期般依叢集索引鍵排序:
警告
在具有複合主索引鍵的資料表中查詢資料時,如果您想要篩選分割區索引鍵和叢集索引鍵以外的任何其他非索引欄位,請確保您明確對分割區索引鍵新增次要索引:
CREATE INDEX ON uprofile.user (user);
根據預設,Azure Cosmos DB for Apache Cassandra 不會將索引套用至分割區索引鍵,而且此案例中的索引可能會大幅改善查詢效能。 如需詳細資訊,請參閱次要索引的文章。
有了以此方式模型化的資料,可以將多筆記錄指派給每個分割區 (依使用者分組)。 如此一來,我們就可以發出由 partition key (在此案例中為 user) 有效率地路由的查詢,以取得指定使用者的所有訊息。
複合分割區索引鍵
複合分割區索引鍵的運作方式基本上與複合索引鍵相同,唯一的差異在於您可以將多個資料行指定為複合分割區索引鍵。 複合分割區索引鍵的語法如下所示:
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
例如,您可以有下列索引鍵,其中 firstname 與 lastname 的唯一組合會形成分割區索引鍵,而 id 是叢集索引鍵:
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );