這很重要
您是否正在尋找一種適用於高擴展性場景的資料庫解決方案,且具有 99.999% 可用性的服務等級協定(SLA)、即時自動擴展,以及跨多個區域的自動容錯切換? 請考慮 適用於 NoSQL 的 Azure Cosmos DB。
您是否想要實作線上分析處理 (OLAP) 圖表或移轉現有的 Apache Gremlin 應用程式? 考慮使用 Microsoft Fabric 中的 Graph (部分機器翻譯)。
本文提供使用圖形資料模型的建議。 在資料發展過程中,這些最佳做法是確保圖形資料庫系統的可擴縮性和效能的重要關鍵。 對大規模圖形而言,有效率的資料模型尤其重要。
需求
本指南中所述的程序是以下列假設為依據:
- 已識別問題空間中的實體。 這些實體是要讓每個要求以不可分割方式方式使用。 換句話說,也就是資料庫系統的設計目的,並不是為了使用多個問題要求來擷取單一實體的資料。
- 我們已經了解資料庫系統有讀取和寫入需求。 這些需求主導了圖形資料模型所需的最佳化作業。
- 已經充分了解 Apache 屬性圖形標準的原則 (英文)。
需要圖形資料庫時機為何?
如果資料網域中的實體和關聯性具有以下任何特性,就非常適合使用圖形資料庫解決方案:
- 實體是透過敘述性的關聯性緊密連結的。 此案例的優點是關聯性會保存在儲存體中。
- 這具有循環關聯性或是自我參考的實體。 使用關聯式或文件資料庫時,此模式通常是一個挑戰。
- 實體之間具有動態發展的關聯性。 此模式特別適用於具有許多層級的階層式或樹狀結構資料。
- 實體之間有多對多關聯性。
- 其中有對實體與關聯性雙方的寫入和讀取需求。
如果符合上述準則,圖形資料庫方法可能就會提供查詢複雜度、資料模型可擴縮性,以及查詢效能等優點。
下一個步驟是決定圖形將要用於分析或交易用途。 如果該圖形要用於大量計算和資料處理工作負載,就值得探索 Cosmos DB Spark 連接器和 GraphX 程式庫。
如何使用圖形物件
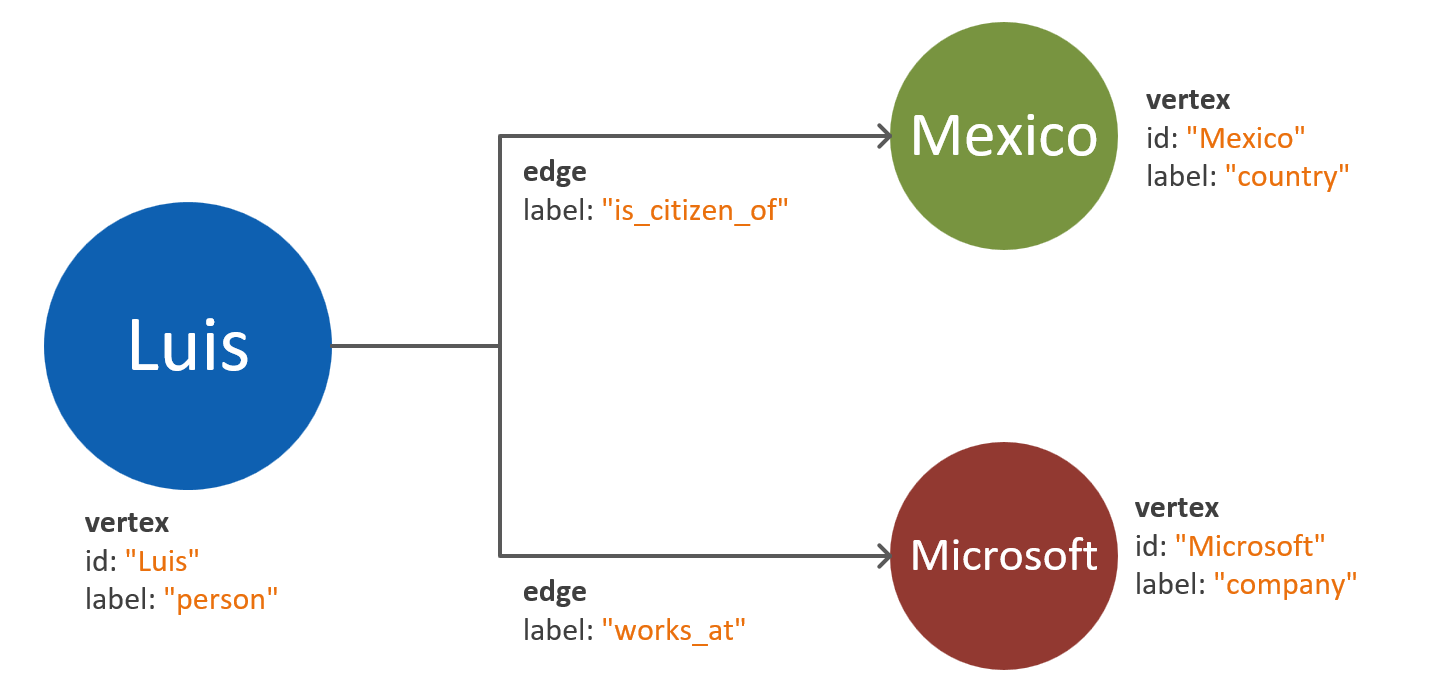
Apache 屬性圖形標準 (英文) 定義了兩種類型的物件:「頂點」和「邊緣」。
以下是圖形物件中各屬性的最佳做法:
| Object | 屬性 | 類型 | 注意 |
|---|---|---|---|
| 頂點 | ID | String | 每個分割區唯一強制執行。 如果插入時未提供值,則會儲存自動產生的 GUID。 |
| 頂點 | 標籤 | String | 這個屬性是用來定義頂點所代表的實體類型。 如果未提供值,請使用預設值 [頂點]。 |
| 頂點 | 屬性 | 字串、布林值、數值 | 個別屬性的清單會以索引鍵/值組的方式儲存在每個頂點中。 |
| 頂點 | 資料分割索引鍵 | 字串、布林值、數值 | 這個屬性定義了頂點和其傳出邊緣的儲存位置。 深入了解資料分割。 |
| 邊緣 | ID | String | 每個分割區唯一強制執行。 預設為自動產生。 邊緣通常不需要使用識別碼進行唯一擷取。 |
| 邊緣 | 標籤 | String | 這個屬性是用來定義兩個頂點之間的關聯性類型。 |
| 邊緣 | 屬性 | 字串、布林值、數值 | 個別屬性的清單會以索引鍵/值組的方式儲存在每個邊緣中。 |
附註
邊緣不需要分割區索引鍵值,因為系統會根據其來源頂點自動指派該值。 若要深入了解,請參閱在 Azure Cosmos DB 中使用資料分割圖表。
實體和關聯性模型指導方針
以下指導方針可協助您對 Azure Cosmos DB for Apache Gremlin 圖形資料庫進行資料模型化。 這些指導方針會假設已有現有的資料網域定義和對資料庫的查詢。
附註
以下為建議步驟。 在考慮將最終模型投入生產前,您應該先評估並測試該模型。 此外,下列建議為 Azure Cosmos DB 的 Gremlin API 實作專屬。
建立頂點和屬性模型
圖形資料模型的第一個步驟是將每個已識別的實體對應至頂點物件。 所有實體到頂點的一對一對應應為初始步驟,因此很可能會有所變更。
一個常見的陷阱是將單一實體的多個屬性作為個別的頂點來對應。 請考量以下範例,範例中將同一個實體以兩種不同的方式表示:
以頂點為基礎的屬性:在這個方法中,實體使用了三個個別的頂點和兩個邊緣來描述其屬性。 雖然這種方法可能會減少冗餘,但會增加模型複雜度。 模型複雜度增加可能會導致增加延遲增加、提升查詢複雜度,以及增加計算成本。 此模型也代表在進行資料分割時將面臨挑戰。
屬性內嵌頂點:這個方法會利用索引鍵/值組清單來代表頂點內部實體的所有屬性。 這種方法降低了模型的複雜度,從而導致更簡單的查詢和更具經濟效益的遍訪。

附註
上圖顯示簡化的圖形模型,該模型僅比較分割實體屬性的兩種方式。
屬性內嵌頂點模式通常會提供效能更高且可調整的方法。 新圖形資料模型的預設方法應傾向採用此模式。
但在某些情況下,參考屬性可能會帶來優點。 例如,如果參考的屬性經常更新。 使用個別的頂點來代表不斷變更的屬性,將更新所需的寫入作業數量降到最低。
邊緣方向的關聯性模型
建立頂點的模型之後,可以新增邊緣來表示它們之間的關聯性。 需要評估的第一個層面是關聯性方向。
使用 out() 或 outE() 函式時,邊緣有後面接著周遊的預設方向。 這個自然方向可產生有效率的作業,因為所有頂點在儲存時都會包含它們的傳出邊緣。
使用 in() 函式沿邊緣反方向周遊一律會導致跨分割區查詢。 深入了解圖表分割。 如果需要頻繁周遊 in() 函式,請在兩個方向上新增邊緣。
您可以透過在 .to() Gremlin 步驟中使用 .from() 或 .addE() 述詞來判斷邊緣方向。 或使用適用於 Gremlin API 的大量執行程式文件庫。
附註
邊緣預設具有方向。
關聯性標籤
使用描述性的關聯性標籤可以提升邊緣解析作業的效率。 您可以透過以下方式套用此模式:
- 使用非一般術語來標記關聯性。
- 利用關聯性名稱建立來源頂點的標籤與目標頂點的標籤之間的關聯。
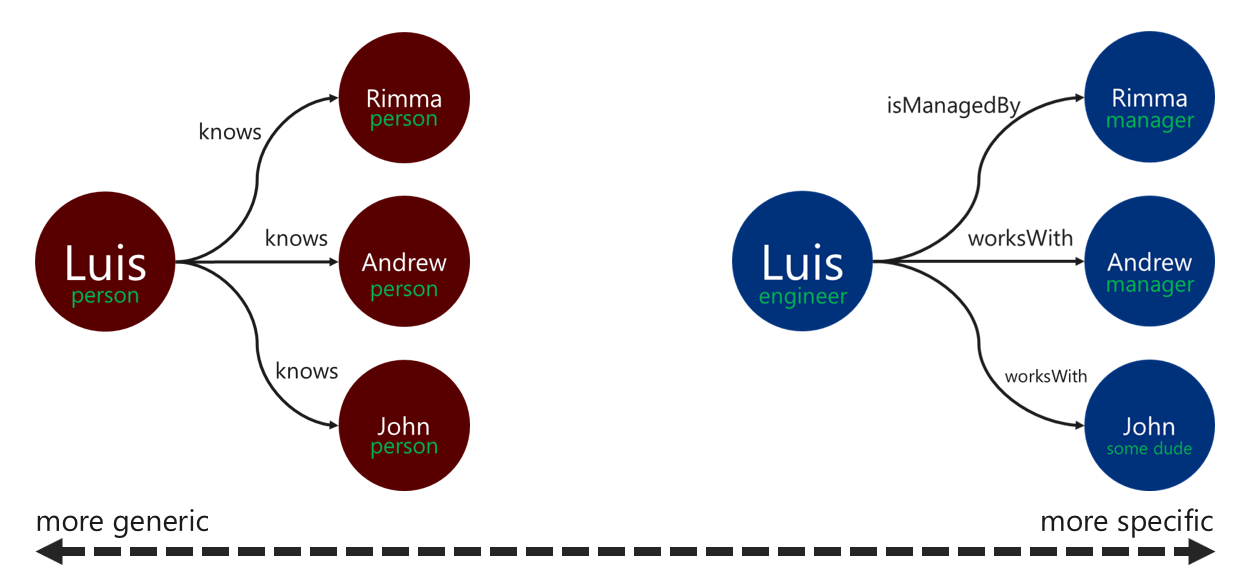
周遊程式用以篩選邊緣的標籤越具體越好。 此決策也會對查詢成本產生重大影響。 您隨時都可以使用 executionProfile 步驟來評估查詢成本。