Azure Cosmos DB 是一個無從驗證結構描述的資料庫,可讓您逐一查看應用程式,而不需處理結構描述或索引管理。 根據預設,Azure Cosmos DB 會自動為容器中的所有項目編製索引,而不需要界定任何結構描述或設定次要索引。
本文說明 Azure Cosmos DB 如何編製數據索引,以及其如何使用索引來改善查詢效能。 建議您先完成本節,再探索如何自訂索引編製原則。
從項目到樹狀結構
每次在容器時儲存項目時,其內容都會投射為 JSON 文件,然後轉換成樹狀結構標記法。 此轉換表示該項目的每個屬性都會呈現為樹狀結構中的某個節點。 會建立虛擬根節點做為該項目中所有第一層屬性的父系。 分葉節點包含項目所攜帶的實際純量值。
以下列項目為例:
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
此樹狀代表範例 JSON 項目:
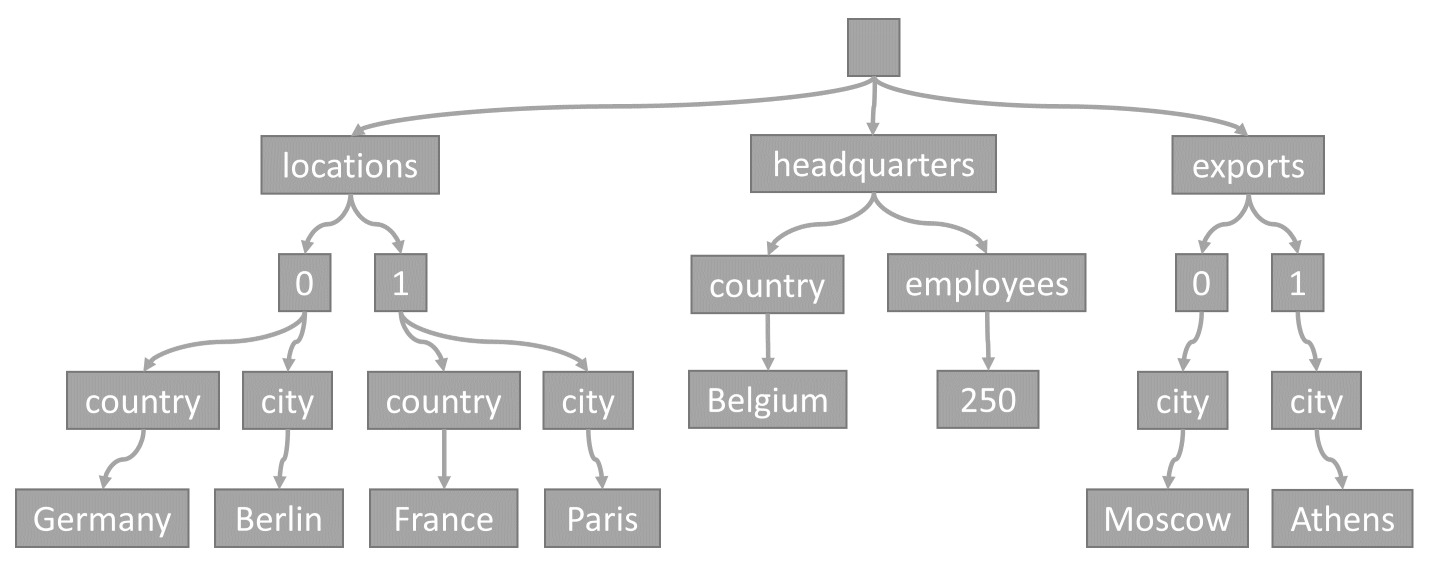
請注意陣列在樹狀結構中的編碼方式:陣列中的每個項目都會取得中繼節點,並標示陣列內該項目的索引 (0、1 等)。
從樹狀結構到屬性路徑
Azure Cosmos DB 會將項目轉換成樹狀結構,因為它可讓系統使用這些樹狀結構內的路徑來參考屬性。 若要取得屬性的路徑,可以將樹狀結構從根節點移至該屬性,並串連每個周遊節點的標籤。
以下是上述範例項目中每個屬性的路徑:
-
/locations/0/country:“德國” -
/locations/0/city:“柏林” -
/locations/1/country: "法國" -
/locations/1/city:“巴黎” -
/headquarters/country:“比利時” -
/headquarters/employees: 250 -
/exports/0/city:“莫斯科” -
/exports/1/city:“雅典”
寫入項目時,Azure Cosmos DB 會有效地為每個屬性的路徑和其對應的值編制索引。
索引類型
Azure Cosmos DB 目前支援三種索引。 在定義編製索引原則時,您可以設定這些索引類型。
範圍索引
範圍索引是以排序好的樹狀結構型結構為基礎。 範圍索引類型用於:
相等查詢:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")陣列元素的相等比對
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")範圍查詢:
SELECT * FROM container c WHERE c.property > 'value'附註
適用於
>、<、>=、<=、!=檢查屬性是否存在:
SELECT * FROM c WHERE IS_DEFINED(c.property)字串系統函式:
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")ORDER BY查詢:SELECT * FROM container c ORDER BY c.propertyJOIN查詢:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
範圍索引可以用於純量值 (字串或數字)。 新建立的容器所套用的預設索引編製原則,會對任何字串或數字強制執行範圍索引。 若要瞭解如何設定範圍索引,請參閱 在 Azure Cosmos DB 中管理索引編製原則。
附註
ORDER BY依單一屬性排序的子句一律需要範圍索引,如果參考的路徑沒有範圍索引,就會失敗。 同樣地, ORDER BY 依多個屬性排序的查詢 一律 需要複合索引。
空間索引
空間 索引可對地理空間對象進行有效率的查詢,例如點、線條、多邊形和多多邊形。 這些查詢會使用ST_DISTANCE、 ST_WITHINST_INTERSECTS關鍵詞。 以下是一些使用空間索引類型的範例:
地理空間距離查詢:
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40查詢中的地理空間:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })地理空間交集查詢:
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
空間索引可用於格式正確的 GeoJSON 物件。 目前支援點、折線、多邊形和多重多邊形。 若要瞭解如何設定空間索引,請參閱 在 Azure Cosmos DB 中管理索引編製原則。
複合索引
複合式索引可提高在多個欄位上執行作業時的效率。 複合式索引類型用於:
多種屬性的
ORDER BY查詢:SELECT * FROM container c ORDER BY c.property1, c.property2具有篩選條件和
ORDER BY的查詢。 如果將篩選條件屬性加入至ORDER BY子句,這類查詢就可使用複合式索引。SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2在兩個或多個屬性上具有篩選條件的查詢,其中至少有一個屬性是相等篩選:
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
只要一個篩選述詞使用其中一個索引類型,查詢引擎就會先評估該值,再掃描其餘部分。 例如,如果您有 SQL 查詢,例如 SELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu"):
此查詢會先使用索引篩選出 firstName = "Andrew" 的項目。 接著會透過後續管道傳遞所有 firstName = "Andrew" 項目,以評估 CONTAINS 篩選器述詞。
使用執行 CONTAINS 等完整掃描的函式時,您可以加速查詢並避免完整容器掃描。 您可以新增更多使用索引的篩選述詞來加速這些查詢。 篩選子句的順序並不重要。 查詢引擎會找出哪些述詞篩選條件更嚴格,並據以執行查詢。
若要瞭解如何設定複合索引,請參閱 在 Azure Cosmos DB 中管理索引編製原則。
向量索引
使用 系統函式執行向量搜尋時,VectorDistance索引可提升效率。 使用向量索引時,向量搜尋的延遲明顯較低、輸送量較高,RU 耗用量較少。 適用於 NoSQL 的 Azure Cosmos DB 支援大小在 4,096 個維度下的任何向量內嵌(文字、影像、多模式等)。
若要瞭解如何設定向量索引,請參閱 向量索引編製原則範例。
ORDER BY向量搜尋查詢:SELECT TOP 10 * FROM c ORDER BY VectorDistance(c.vector1, c.vector2)在向量搜索中預測相似度分數:
SELECT TOP 10 c.name, VectorDistance(c.vector1, c.vector2) AS SimilarityScore FROM c ORDER BY VectorDistance(c.vector1, c.vector2)相似度分數的範圍篩選條件。
SELECT TOP 10 * FROM c WHERE VectorDistance(c.vector1, c.vector2) > 0.8 ORDER BY VectorDistance(c.vector1, c.vector2)
重要
目前,在建立之後,向量原則和向量索引是不可變的。 若要進行變更,請建立新的集合。
索引使用情形
查詢引擎可以使用五種方式來評估查詢篩選條件,從效率最高到效率最低的方式排序:
- 索引搜尋
- 精確索引掃描
- 展開的索引掃描
- 完整索引掃描
- 完整掃描
當您為屬性路徑編製索引時,查詢引擎會自動盡可能有效率地使用索引。 除了將新的屬性路徑編製索引之外,您不需要設定任何內容來最佳化查詢使用索引的方式。 查詢的 RU 費用結合了索引使用的 RU 費用和載入項目的 RU 費用。
下表摘要說明在 Azure Cosmos DB 中使用索引的不同方式:
| 索引查閱類型 | 描述 | 常見範例 | 來自索引使用方式的 RU 費用 | 從交易資料存放區載入項目時的 RU 費用 |
|---|---|---|---|---|
| 索引搜尋 | 唯讀所需的索引值,並只從交易資料存放區載入相符的項目 | 等號比較篩選條件,IN | 每個等號比較篩選條件的常數 | 根據查詢結果中的項目數增加 |
| 精確索引掃描 | 索引值的二進位搜尋,只會從交易資料存放區載入相符的項目 | 範圍比較 (>、<、< = 或 > =)、StartsWith | 相當於索引搜尋,會根據索引屬性的基數而稍微增加 | 根據查詢結果中的項目數增加 |
| 展開的索引掃描 | 最佳化索引值的搜尋 (但效率比二進位搜尋低),而且只會從交易資料存放區載入相符的項目 | StartsWith (不區分大小寫)、StringEquals (不區分大小寫) | 會根據索引屬性的基數而稍微增加 | 根據查詢結果中的項目數增加 |
| 完整索引掃描 | 讀取不同的索引值組,只會從交易資料存放區載入相符的項目 | Contains、EndsWith、RegexMatch、LIKE | 會根據索引屬性的基數而線性增加 | 根據查詢結果中的項目數增加 |
| 完整掃描 | 從交易資料存放區載入所有項目 | 上方、下方 | N/A | 根據容器中的項目數增加 |
撰寫查詢時,您應該使用篩選述詞,並盡可能有效率地運用索引。 例如,如果 StartsWith 或 Contains 適用於使用案例,您應該選擇 StartsWith,因為其會執行精確的索引掃描,而不是完整的索引掃描。
索引使用方式詳細資料
本節涵蓋查詢如何使用索引的更多詳細數據。 若要瞭解如何開始使用 Azure Cosmos DB,不需要此程度的細節,但已為感興趣的使用者詳細記錄。 我們將參考本文件稍早所共用的範例項目:
範例項目:
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
Azure Cosmos DB 使用反向索引。 索引的運作方式是將每個 JSON 路徑對應至包含該值的項目集合。 項目識別碼映射會在容器的許多不同索引頁面上出現。 以下是包含兩個範例項目之容器的反向索引樣本圖:
| 路徑 | 值 | 專案識別碼的清單 |
|---|---|---|
| /locations/0/country | 德國 | 1 |
| /locations/0/country | 愛爾蘭 | 2 |
| /地點/0/城市 | 柏林 | 1 |
| /地點/0/城市 | 都柏林 | 2 |
| /locations/1/country | 法國 | 1 |
| /locations/1/city | 巴黎 | 1 |
| /總部/國家 | 比利時 | 1, 2 |
| /總部/員工 | 200 | 2 |
| /總部/員工 | 250 | 1 |
反向索引有兩個重要的屬性:
- 針對指定的路徑,值會以遞增順序排序。 因此,查詢引擎可以輕鬆地從索引中提供
ORDER BY的服務。 - 針對指定的路徑,查詢引擎可以掃描一組不同的可能值,以識別有結果的索引頁面。
查詢引擎可以用四種不同的方式來利用反向索引:
索引搜尋
請考慮以下查詢:
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'
查詢述詞 (篩選有任何位置的國家或地區為「法國」的項目) 會比對下列圖表中反白顯示的路徑:
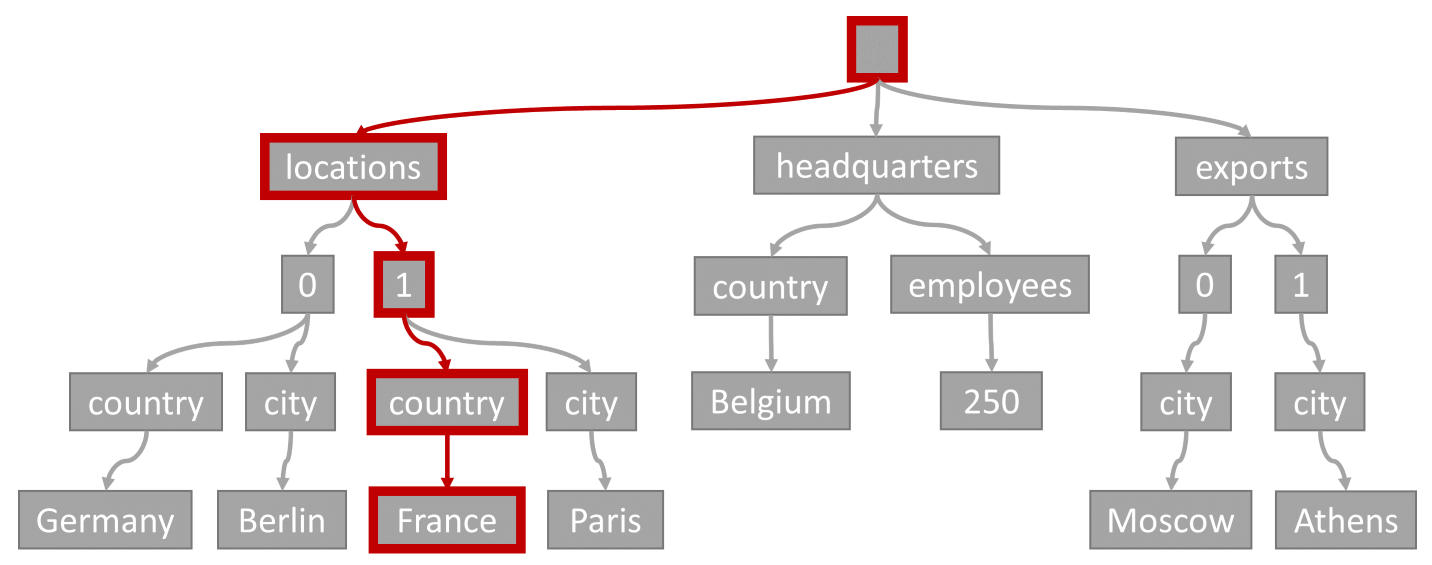
由於這個查詢有相等的篩選條件,因此在遍歷這個樹狀結構之後,我們可以快速識別包含查詢結果的索引頁面。 在此情況下,查詢引擎會讀取包含項目 1 的索引頁面。 索引搜尋是最有效率的索引使用方式。 使用索引搜尋時,我們只會讀取必要的索引頁,並只載入查詢結果中的項目。 因此,不論資料量總計為何,索引查閱時間和來自索引查閱的 RU 費用非常低。
精確索引掃描
請考慮以下查詢:
SELECT *
FROM company
WHERE company.headquarters.employees > 200
可以使用 headquarters/employees 路徑的精確索引掃描來評估查詢述詞 (篩選有超過 200 名員工的項目)。 進行精確的索引掃描時,查詢引擎一開始會先對一組不同的可能值進行二進位搜尋,以找出 200 路徑值 headquarters/employees 的位置。 由於每個路徑的值會以遞增順序排序,因此查詢引擎很容易就能進行二進位搜尋。 在查詢引擎找到值 200 之後,其就會開始讀取所有剩餘的索引頁面 (以遞增方向進行)。
因為查詢引擎可以進行二進位搜尋,以避免掃描不必要的索引頁,所以精確的索引掃描通常會有相當於索引搜尋作業的延遲和 RU 費用。
展開的索引掃描
請考慮以下查詢:
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
可以使用 headquarters/country 路徑的展開索引掃描來評估查詢述詞 (篩選總部在地區開頭為 "United" 但不區分大小寫的項目)。 進行展開索引掃描的作業具有最佳化,可協助避免掃描每個索引頁的需要,但比精確索引掃描的二進位搜尋稍微昂貴。
例如,在評估不區分大小寫的 StartsWith 時,查詢引擎會檢查索引是否有不同的大寫和小寫值組合。 這項最佳化可讓查詢引擎避免讀取大部分的索引頁面。 不同的系統函數有不同的最佳化,可用來避免讀取每個索引頁,因此這些功能廣泛分類為展開的索引掃描。
完整索引掃描
請考慮以下查詢:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
可以使用headquarters/country路徑的索引掃描來評估查詢述詞 (篩選出總部位於包含「United」的地區的項目)。 與精確索引掃描不同的是,完整索引掃描一律會透過一組不同的可能值進行掃描,以找出有結果的索引頁。 在此情況下,CONTAINS 會在索引上執行。 索引掃描的索引查閱時間和 RU 費用會隨著路徑基數的增加而上升。 換句話說,查詢引擎需要掃描的可能相異值越多,執行完整索引掃描所需的延遲和 RU 費用就愈多。
例如,請考慮兩個屬性:town 和 country。 城鎮的基數為 5,000,而 country 的基數為 200。 以下是兩個範例查詢,每個查詢都有一個CONTAINS系統函式,能對town屬性執行完整索引掃描。 第一個查詢使用的 RU 會比第二個查詢多,因為城鎮的基數高於 country。
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
完整掃描
在某些情況下,查詢引擎可能無法使用索引來評估查詢篩選。 在此情況下,查詢引擎將需要從交易式存放區載入所有項目,才能評估查詢篩選。 完整掃描不會使用索引,其 RU 費用會隨資料大小總計呈線性增加。 幸好需要完整掃描的作業非常罕見。
沒有已定義向量索引的向量搜尋查詢
如果您未定義向量索引原則且在 VectorDistance 子句中使用 ORDER BY 系統函式,這會導致進行完整掃描,並且 RU 費用將高於定義了向量索引原則的情況。 同樣地,如果您使用 VectorDistance 搭配設定為 true 的暴力破解布林值,而且沒有針對向量路徑定義的 flat 索引,便會執行完整掃描。
使用複雜篩選條件運算式的查詢
在先前的範例中,我們只考慮具有簡單篩選運算式的查詢(例如,只有單一等號或範圍篩選器的查詢)。 實際上,大部分的查詢都有更複雜的篩選條件運算式。
請考慮以下查詢:
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
若要執行此查詢,查詢引擎必須在 headquarters/employees 上執行索引搜尋並在 headquarters/country 上執行完整索引掃描。 查詢引擎具有內部啟發學習法,其會使用此學習法來盡可能有效率地評估查詢篩選條件運算式。 在此情況下,查詢引擎會先執行索引搜尋,以避免讀取不必要索引頁的需求。 例如,如果只有 50 個項目符合等號比較篩選條件,則查詢引擎只需要在包含這 50 個項目的索引頁上評估 CONTAINS。 整個容器的完整索引掃描不是必要的。
純量彙總函式的索引使用率
使用彙總函式的查詢必須完全依賴索引。
在某些情況下,索引可能會傳回誤判為真。 例如,在 CONTAINS 索引上評估時,索引中的相符項目數目可能會超過查詢結果的數目。 查詢引擎會載入所有索引相符項目、評估載入項目上的篩選條件,然後只傳回正確的結果。
對於大部分的查詢,載入錯誤的正面索引比對對索引使用率不會產生任何明顯影響。
例如,請考慮下列查詢:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
CONTAINS 系統函數可能會傳回一些誤判為真的相符項目,因此查詢引擎將需要確認每個載入的項目是否符合篩選條件運算式。 在此範例中,查詢引擎可能只需要載入幾個額外的項目,因此對索引使用率和 RU 費用的影響微乎其微。
然而,使用彙總函式的查詢必須完全依賴索引才能使用索引。 例如,可試想具有 COUNT 彙總的下列查詢:
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
如同在第一個範例中,CONTAINS 系統函數可能會傳回一些誤判為真的相符項目。 不過,與查詢 SELECT * 不同的是,COUNT 查詢無法在載入的項目上評估篩選條件運算式,以驗證所有索引是否相符。
COUNT 查詢必須依賴索引,因此,如果篩選條件運算式可能傳回誤判為真的相符項目,則查詢引擎會使用完整掃描。
具有下列彙總函式的查詢必須完全依賴索引,因此評估某些系統函數需要完整掃描。