Azure Cosmos DB for MongoDB 可讓您使用索引來加速查詢的效能。 本文顯示如何管理和最佳化索引,以加快資料擷取速度並提升效率。
為 MongoDB 伺服器 3.6 版和更高版本編制索引
Azure Cosmos DB for MongoDB 伺服器版本 3.6+ 會自動建立 _id 欄位及(僅在分片集合中)分片鍵的索引。 API 會對每個分區索引鍵的 _id 欄位強制執行唯一性。
API for MongoDB 的運作方式與 Azure Cosmos DB for NoSQL 不同,後者預設為編製所有欄位的索引。
編輯編製索引原則
在 Azure 入口網站的資料總管中編輯您的索引編製原則。 從資料總管中的編製索引原則編輯器新增單一欄位和萬用字元索引:
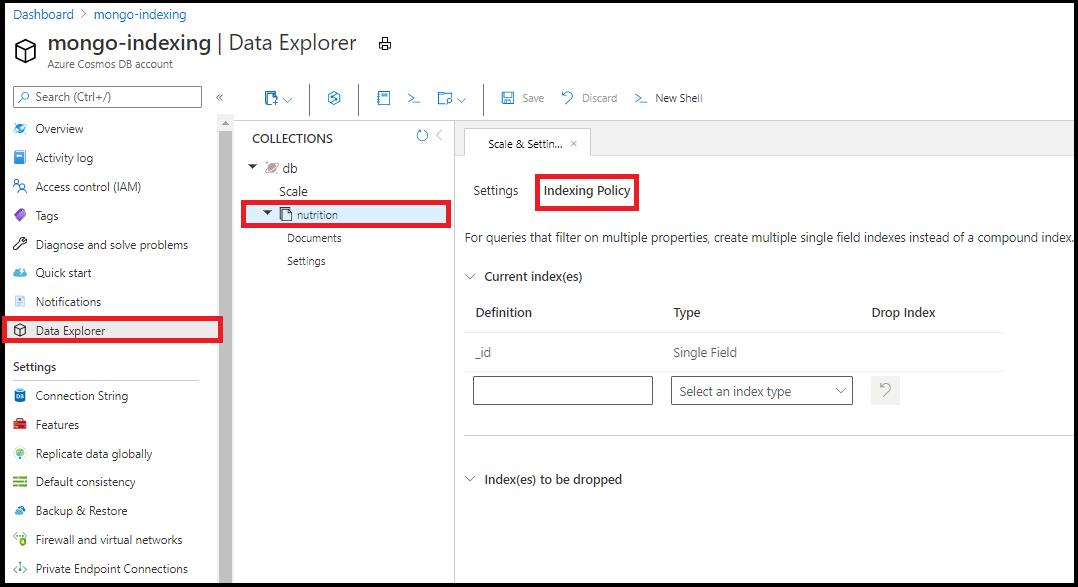
備註
您無法使用資料總管中的編制索引原則編輯器來建立複合索引。
索引類型
單一欄位
在任何單一欄位上建立索引。 單一欄位索引的排序順序不重要。 使用下列命令在欄位 name 上建立索引:
db.coll.createIndex({name:1})
在 Azure 入口網站的 name 上建立相同的單一欄位索引:
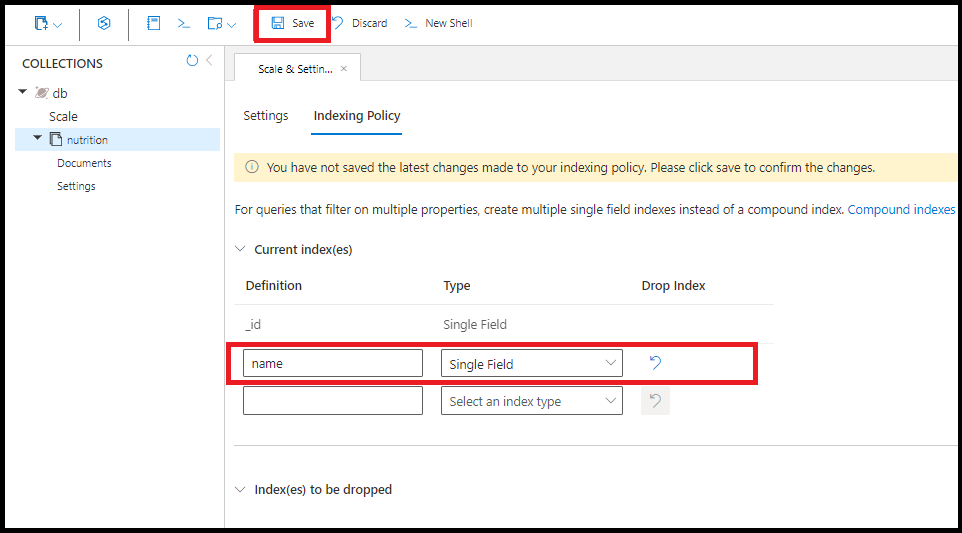
一個查詢會使用多個單一欄位索引 (如果可用)。 每個集合最多可以建立 500 個單一欄位索引。
複合索引 (MongoDB 伺服器 3.6+ 版)
在 API for MongoDB 中,將複合索引搭配會一次排序多個欄位的查詢使用。 查詢若具有多個不需要排序的篩選條件,請建立多個單一欄位索引,而不是複合索引,以節省索引成本。
複合索引或複合索引中每個欄位的單一欄位索引,都會對查詢中的篩選產生相同的效能。
由於陣列的限制,依預設不支援巢狀欄位上的複合索引。 如果巢狀欄位沒有陣列,則索引會如預期運作。 如果您的巢狀欄位在路徑上的任何位置有陣列,則會在索引中忽略該值。
例如,包含 people.dylan.age 的複合索引在此案例中會有作用,因為路徑上沒有陣列:
{
"people": {
"dylan": {
"name": "Dylan",
"age": "25"
},
"reed": {
"name": "Reed",
"age": "30"
}
}
}
相同的複合索引在此案例中無法運作,因為路徑中有陣列:
{
"people": [
{
"name": "Dylan",
"age": "25"
},
{
"name": "Reed",
"age": "30"
}
]
}
為您的資料庫帳戶啟用此功能啟用此功能,方法是啟用 'EnableUniqueCompoundNestedDocs' 功能。
備註
您無法在陣列上建立複合索引。
下列命令會在欄位 name 和 age 上建立複合索引:
db.coll.createIndex({name:1,age:1})
您可以使用複合索引,一次在多個欄位上有效率地排序,如下列範例所示:
db.coll.find().sort({name:1,age:1})
您也可以使用上述的複合索引,在所有欄位上以相反的排列順序有效率地排序查詢。 以下是範例:
db.coll.find().sort({name:-1,age:-1})
不過,複合索引中的路徑序列必須完全符合查詢。 以下是需要額外複合索引的查詢範例:
db.coll.find().sort({age:1,name:1})
多重索引鍵索引
Azure Cosmos DB 會建立多重索引鍵索引,為陣列中的內容編製索引。 如果您使用陣列值為欄位編製索引,Azure Cosmos DB 會自動為陣列中的每個元素編製索引。
地理空間索引
許多地理空間業者可受益於地理空間索引。 Azure Cosmos DB for MongoDB 支援 2dsphere 索引。 API 尚不支援 2d 索引。
以下是在 location 欄位上建立地理空間索引的範例:
db.coll.createIndex({ location : "2dsphere" })
文字索引
Azure Cosmos DB for MongoDB 不支援文字索引。 對於字串的文字搜尋查詢,請使用 Azure AI 搜尋服務與 Azure Cosmos DB 的整合。
萬用字元索引
以使用萬用字元索引來支援針對未知欄位的查詢。 想像有關於家庭資料的一個集合。
以下是該集合中範例文件的一部分:
"children": [
{
"firstName": "Henriette Thaulow",
"grade": "5"
}
]
以下是在 children 中具有不同屬性集的另一個範例:
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"pets": [
{ "givenName": "Goofy" },
{ "givenName": "Shadow" }
]
},
{
"familyName": "Merriam",
"givenName": "John",
}
]
此集合中的文件可以有許多不同的屬性。 若要為 children 陣列中的所有資料建立索引,請為每個屬性建立單獨的索引,或為整個 children 陣列建立一個萬用字元索引。
建立通配符索引
使用下列命令,在 children 內的任何屬性上建立萬用字元索引:
db.coll.createIndex({"children.$**" : 1})
- 與 MongoDB 不同的是,萬用字元索引可支援查詢述詞使用多個欄位。 若您使用單一個萬用字元索引,而不是為各屬性建立個別索引,查詢效能不會有差異。
使用萬用字元語法來建立下列索引類型:
- 單一欄位
- 地理空間
為所有屬性編制索引
使用下列命令,在所有欄位上建立萬用字元索引:
db.coll.createIndex( { "$**" : 1 } )
使用 Azure 入口網站中的資料總管來建立萬用字元索引:
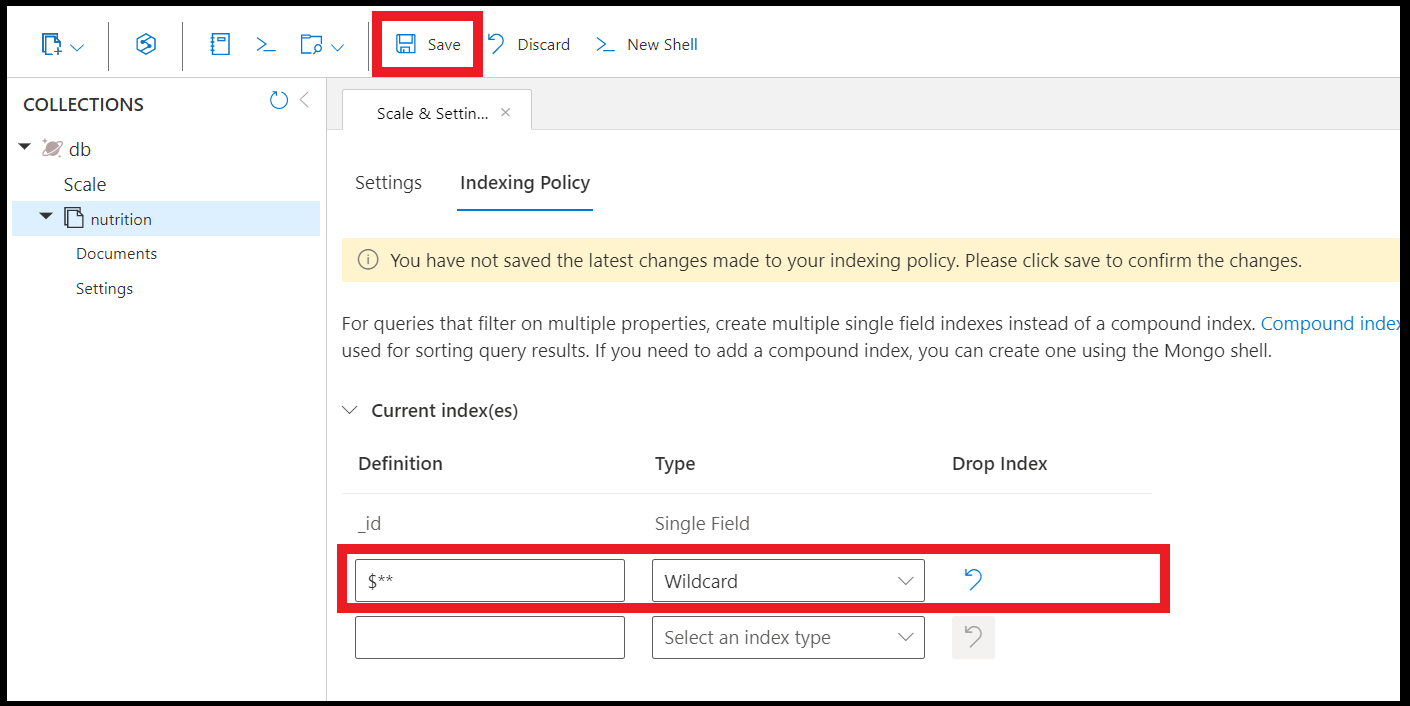
備註
如果您才剛開始開發,請從在所有欄位上的萬用字元索引開始。 此方法可簡化開發,並更輕鬆地最佳化查詢。
由於寫入和更新,具有許多欄位的文件可能會有高要求單位 (RU) 費用。 如果您有大量寫入的工作負載,請使用個別編製索引的路徑,而不是萬用字元。
限制
萬用字元索引不支援下列任何索引類型或屬性:
複合
TTL
唯一
不同於 MongoDB,在 Azure Cosmos DB for MongoDB 中,您無法使用萬用字元索引來進行下列動作:
建立包含多個特定欄位的萬用字元索引
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection " : { "children.givenName" : 1, "children.grade" : 1 } } )我們正在建立一個萬用字元索引,以排除多個特定欄位。
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection" : { "children.givenName" : 0, "children.grade" : 0 } } )
做為替代方式,可以建立多個萬用字元索引。
索引屬性
使用有線通訊協定版本 4.0 和較舊版本的帳戶通常執行下列作業。 深入了解支援的索引和索引屬性。
唯一索引
唯一索引可協助確定兩個或多文件的索引欄位值不同。
執行下列命令,在 student_id 欄位上建立唯一索引:
db.coll.createIndex( { "student_id" : 1 }, {unique:true} )
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 4
}
針對分區化集合,請提供分區 (分割區) 索引鍵來建立唯一索引。 分區集合上的所有唯一索引,都是複合索引,且其中一個欄位分區索引鍵。 分區索引鍵應該是索引定義中的第一個欄位。
執行下列命令,在 coll 和 university 欄位上建立名為 student_id 的分區集合 (以 university 做為分區索引鍵) 以及唯一索引:
db.runCommand({shardCollection: db.coll._fullName, key: { university: "hashed"}});
{
"_t" : "ShardCollectionResponse",
"ok" : 1,
"collectionsharded" : "test.coll"
}
db.coll.createIndex( { "university" : 1, "student_id" : 1 }, {unique:true});
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 3,
"numIndexesAfter" : 4
}
如果您省略前述範例中的 "university":1 子句,則會看到下列錯誤訊息:
cannot create unique index over {student_id : 1.0} with shard key pattern { university : 1.0 }
限制
集合為空白時建立唯一索引。
具有 連續備份 的 Azure Cosmos DB for MongoDB 帳戶不支援為現有的集合建立唯一索引。 對於這類帳戶,必須建立唯一索引及其集合建立,這必須且只能使用建立集合 延伸命令來完成。
db.runCommand({customAction:"CreateCollection", collection:"coll", shardKey:"student_id", indexes:[
{key: { "student_id" : 1}, name:"student_id_1", unique: true}
]});
由於陣列的限制,依預設不支援巢狀欄位上的唯一索引。 如果您的巢狀欄位沒有陣列,則索引會如預期運作。 如果您的巢狀欄位在路徑上的任何位置有陣列,則會在唯一索引中忽略該值,而且不會保留該值的唯一性。
例如,在此案例中,people.tom.age 上的唯一索引可以運作,因為路徑上沒有陣列:
{
"people": {
"tom": {
"age": "25"
},
"mark": {
"age": "30"
}
}
}
但在此案例中無法運作,因為路徑中有陣列:
{
"people": {
"tom": [
{
"age": "25"
}
],
"mark": [
{
"age": "30"
}
]
}
}
啟用 'EnableUniqueCompoundNestedDocs' 功能,即可為您的資料庫帳戶啟用此功能。
TTL 索引
若要讓文件在集合中過期,請建立存留時間 (TTL) 索引。 TTL 索引是 _ts 欄位上具有 expireAfterSeconds 值的索引。
範例:
db.coll.createIndex({"_ts":1}, {expireAfterSeconds: 10})
上述命令會刪除 db.coll 集合中超過 10 秒前修改的任何文件。
備註
_ts 是 Azure Cosmos DB 特有欄位,而且無法從 MongoDB 用戶端存取。 這是保留 (系統) 屬性,其中包含上次修改文件的時間戳記。
追蹤索引進度
Azure Cosmos DB for MongoDB API 版本 3.6 和更新版本支援 currentOp() 命令,可追蹤資料庫執行個體上的索引進度。 此命令會傳回文件,其中包含資料庫執行個體上進行中作業的相關資訊。 使用命令 currentOp 來追蹤原生 MongoDB 中所有進行中的作業。 在 Azure Cosmos DB for MongoDB 中,此命令僅會追蹤索引作業。
以下是一些範例,說明如何使用 currentOp 命令來追蹤索引進度:
取得集合的索引進度:
db.currentOp({"command.createIndexes": <collectionName>, "command.$db": <databaseName>})取得資料庫中所有集合的索引進度:
db.currentOp({"command.$db": <databaseName>})取得 Azure Cosmos DB 帳戶中所有資料庫和集合的索引進度:
db.currentOp({"command.createIndexes": { $exists : true } })
索引進度輸出的範例
索引進度詳細資料會顯示目前索引作業的進度百分比。 以下範例顯示索引進度不同階段的輸出文件格式:
在完成 60% 的 "foo" 集合和 "bar" 資料庫上,索引作業將具有下列輸出文件。
Inprog[0].progress.total欄位會將 100 顯示為目標完成百分比。{ "inprog": [ { ... "command": { "createIndexes": foo "indexes": [], "$db": bar }, "msg": "Index Build (background) Index Build (background): 60 %", "progress": { "done": 60, "total": 100 }, ... } ], "ok": 1 }如果索引作業剛在 "foo" 集合和 "bar" 資料庫上開始,則輸出文件可能會顯示 0% 進度,直到其達到可測量的層級為止。
{ "inprog": [ { ... "command": { "createIndexes": foo "indexes": [], "$db": bar }, "msg": "Index Build (background) Index Build (background): 0 %", "progress": { "done": 0, "total": 100 }, ... } ], "ok": 1 }當索引作業完成時,輸出文件會顯示空白的
inprog作業。{ "inprog" : [], "ok" : 1 }
背景索引更新
無論您為 Background 索引屬性設定什麼值,索引更新一定在背景中執行。 因為索引更新使用要求單位 (RU) 的優先順序低於其他資料庫動作,索引變更不會導致寫入、更新或刪除的停機時間。
新增索引不會影響讀取可用性。 查詢只會在索引轉換完成之後使用新索引。 在轉換期間,查詢引擎會持續使用現有的索引,因此您看到的讀取效能與開始編製索引變更之前類似。 新增索引不會承擔查詢結果不完整或不一致的風險。
如果您移除索引,並立即執行會篩選這些已捨棄索引的查詢,則結果可能會不一致且不完整,直到索引轉換完成。 查詢引擎不會針對會篩選最近移除索引的查詢提供一致或完整的結果。 多數開發人員不會捨棄索引,然後立即查詢它們,因此情況不太可能發生。
備註
您可以追蹤索引進度。
reIndex 命令
reIndex 命令會在集合上重新建立所有索引。 在少數情況下,執行 reIndex 命令可以修正查詢效能或集合中的其他索引問題。 如果您遇到索引編製問題,請嘗試使用 reIndex 命令重新建立索引。
使用下列語法執行 reIndex 命令:
db.runCommand({ reIndex: <collection> })
使用下列語法來檢查執行 reIndex 命令是否改善集合中的查詢效能:
db.runCommand({"customAction":"GetCollection",collection:<collection>, showIndexes:true})
範例輸出:
{
"database": "myDB",
"collection": "myCollection",
"provisionedThroughput": 400,
"indexes": [
{
"v": 1,
"key": {
"_id": 1
},
"name": "_id_",
"ns": "myDB.myCollection",
"requiresReIndex": true
},
{
"v": 1,
"key": {
"b.$**": 1
},
"name": "b.$**_1",
"ns": "myDB.myCollection",
"requiresReIndex": true
}
],
"ok": 1
}
如果 reIndex 可改善查詢效能,requiresReIndex 為 True。 如果 reIndex 無法改善查詢效能,系統將會省略此屬性。
移轉具有索引的集合
您只能在集合未包含任何文件時建立唯一索引。 熱門 MongoDB 移轉工具會嘗試在匯入資料之後建立唯一索引。 若要解決此問題,請手動建立對應的集合和唯一索引,而不是讓移轉工具嘗試。 您可以在命令列中使用 mongorestore 旗標,為 --noIndexRestore 實現此行為。
為 MongoDB 3.2 版編制索引
使用 MongoDB 有線通訊協定版本 3.2 的 Azure Cosmos DB 帳戶的索引編製功能和預設值不同。 在 feature-support-36.md#protocol-support 檢查您帳戶的版本,並在 upgrade-version.md 升級至版本 3.6。
如果您使用的是版本 3.2,本節會強調版本 3.6 與更新版本的主要差異。
卸除預設索引 (3.2 版)
與版本 3.6 和更新版本不同,Azure Cosmos DB for MongoDB 版本 3.2 預設會針對每個屬性進行索引。 使用下列命令,來捨棄集合 (coll) 的這些預設索引:
db.coll.dropIndexes()
{ "_t" : "DropIndexesResponse", "ok" : 1, "nIndexesWas" : 3 }
捨棄預設索引之後,請新增更多索引,就像在版本 3.6 及更新版本中一樣。
複合索引 (3.2 版)
複合索引會參考文件中的多個欄位。 若要建立複合索引,請於 upgrade-version.md 升級至版本 3.6 或 4.0。
萬用字元索引 (3.2 版)
若要建立萬用字元索引,請於 upgrade-version.md 升級至版本 4.0 或 3.6。