使用適用於 MongoDB 的 Azure Cosmos DB 虛擬核心產生 AI 增強型公告
在本指南中,我們會示範如何使用我們的個人化 AI 助理 Heelie,建立與觀眾產生共鳴的動態廣告內容。 我們利用適用於 MongoDB 虛擬核心的 Azure Cosmos DB,利用 向量相似度搜尋 功能,以語意方式分析和比對清查描述與廣告主題。 使用 OpenAI 內嵌產生清查描述的向量,可大幅增強其語意深度,以達成此程式。 然後,這些向量會儲存並在適用於 MongoDB 的 Cosmos DB 虛擬核心資源內編製索引。 產生廣告的內容時,我們會向量化廣告主題,以尋找最相符的清查專案。 接著是擷取增強世代(RAG)程式,其中頂級比賽會傳送給OpenAI製作引人入勝的廣告。 您可以在 GitHub 存放庫中取得應用程式的整個程式代碼基底,以供參考。
功能
- 向量相似性搜尋:使用適用於 MongoDB 虛擬核心的 Azure Cosmos DB 強大的向量相似性搜尋來改善語意搜尋功能,讓您更輕鬆地根據廣告內容尋找相關的清查專案。
- OpenAI 內嵌:利用 OpenAI 的尖端內嵌來產生清查描述的向量。 此方法允許在清查和廣告內容之間進行更細微且語意豐富的相符專案。
- 內容產生:採用 OpenAI 的進階語言模型來產生吸引人的趨勢焦點廣告。 此方法可確保內容不僅相關,而且吸引目標物件。
必要條件
- Azure OpenAI:讓我們設定 Azure OpenAI 資源。 應用程式目前只能存取此服務。 您可以填妥 https://aka.ms/oai/access 的表單,以申請 Azure OpenAI 的存取權。 存取權之後,請完成下列步驟:
- 適用於 MongoDB 的 Cosmos DB 虛擬核心資源:請遵循本 快速入門 指南,免費建立適用於 MongoDB 的 Azure Cosmos DB 虛擬核心資源。
- 記下聯機詳細數據。
- Python 環境 (>= 3.9 版)與套件,例如
numpy、openai、pymongopython-dotenv、、azure-core、、azure-cosmostenacity和gradio。 - 下載數據檔,並將其儲存在指定的數據資料夾中。
執行腳本
在深入探討產生 AI 增強式廣告的精彩部分之前,我們需要設定環境。 此設定牽涉到安裝必要的套件,以確保腳本能順利執行。 以下是讓所有項目準備就緒的逐步指南。
1.1 安裝必要的套件
首先,我們需要安裝一些 Python 套件。 開啟終端機並執行下列命令:
pip install numpy
pip install openai==1.2.3
pip install pymongo
pip install python-dotenv
pip install azure-core
pip install azure-cosmos
pip install tenacity
pip install gradio
pip show openai
1.2 設定 OpenAI 和 Azure 用戶端
安裝必要的套件之後,下一個步驟會涉及為腳本設定 OpenAI 和 Azure 用戶端,這對驗證對 OpenAI API 和 Azure 服務的要求至關重要。
import json
import time
import openai
from dotenv import dotenv_values
from openai import AzureOpenAI
# Configure the API to use Azure as the provider
openai.api_type = "azure"
openai.api_key = "<AZURE_OPENAI_API_KEY>" # Replace with your actual Azure OpenAI API key
openai.api_base = "https://<OPENAI_ACCOUNT_NAME>.openai.azure.com/" # Replace with your OpenAI account name
openai.api_version = "2023-06-01-preview"
# Initialize the AzureOpenAI client with your API key, version, and endpoint
client = AzureOpenAI(
api_key=openai.api_key,
api_version=openai.api_version,
azure_endpoint=openai.api_base
)
解決方案架構

2.建立內嵌和設定 Cosmos DB
設定環境和OpenAI客戶端之後,我們會移至 AI 增強式廣告產生專案的核心部分。 下列程式代碼會從產品的文字描述建立向量內嵌,並在適用於 MongoDB 的 Azure Cosmos DB 虛擬核心中設定我們的資料庫,以儲存和搜尋這些內嵌。
2.1 建立內嵌
若要產生吸引人的廣告,我們必須先了解庫存中的專案。 我們藉由從專案描述建立向量內嵌,以機器可以理解和處理的形式擷取其語意意義,以執行此動作。 以下說明如何使用 Azure OpenAI 為專案描述建立向量內嵌:
import openai
def generate_embeddings(text):
try:
response = client.embeddings.create(
input=text, model="text-embedding-ada-002")
embeddings = response.data[0].embedding
return embeddings
except Exception as e:
print(f"An error occurred: {e}")
return None
embeddings = generate_embeddings("Shoes for San Francisco summer")
if embeddings is not None:
print(embeddings)
函式會採用文字輸入,例如產品描述,並使用 client.embeddings.create OpenAI API 中的 方法來產生該文字的向量內嵌。 我們在這裡使用 text-embedding-ada-002 模型,但您可以根據您的需求選擇其他模型。 如果程式成功,它會列印產生的內嵌;否則,它會藉由列印錯誤訊息來處理例外狀況。
3.連線並設定適用於 MongoDB 的 Cosmos DB 虛擬核心
隨著我們的內嵌準備就緒,下一個步驟是將其儲存並編製索引到支援向量相似性搜尋的資料庫中。 適用於 MongoDB 的 Azure Cosmos DB 虛擬核心非常適合此工作,因為它的目的是為了儲存您的事務數據,並在一個地方執行向量搜尋。
3.1 設定連線
為了連線到 Cosmos DB,我們使用 pymongo 連結庫,這可讓我們輕鬆地與 MongoDB 互動。 下列代碼段會建立與適用於 MongoDB 的 Cosmos DB 虛擬核心實例的連線:
import pymongo
# Replace <USERNAME>, <PASSWORD>, and <VCORE_CLUSTER_NAME> with your actual credentials and cluster name
mongo_conn = "mongodb+srv://<USERNAME>:<PASSWORD>@<VCORE_CLUSTER_NAME>.mongocluster.cosmos.azure.com/?tls=true&authMechanism=SCRAM-SHA-256&retrywrites=false&maxIdleTimeMS=120000"
mongo_client = pymongo.MongoClient(mongo_conn)
將、 <PASSWORD>和 <VCORE_CLUSTER_NAME> 分別取代<USERNAME>為您的實際 MongoDB 使用者名稱、密碼和虛擬核心叢集名稱。
4.在 Cosmos DB 中設定資料庫和向量索引
建立 Azure Cosmos DB 連線之後,後續步驟會涉及設定資料庫和集合,然後建立向量索引以啟用有效率的向量相似性搜尋。 讓我們逐步解說這些步驟。
4.1 設定資料庫和集合
首先,我們會在Cosmos DB實例內建立資料庫和集合。 方法如下:
DATABASE_NAME = "AdgenDatabase"
COLLECTION_NAME = "AdgenCollection"
mongo_client.drop_database(DATABASE_NAME)
db = mongo_client[DATABASE_NAME]
collection = db[COLLECTION_NAME]
if COLLECTION_NAME not in db.list_collection_names():
# Creates a unsharded collection that uses the DBs shared throughput
db.create_collection(COLLECTION_NAME)
print("Created collection '{}'.\n".format(COLLECTION_NAME))
else:
print("Using collection: '{}'.\n".format(COLLECTION_NAME))
4.2 建立向量索引
若要在集合中執行有效率的向量相似性搜尋,我們需要建立向量索引。 Cosmos DB 支援不同類型的 向量索引,在這裡我們將討論兩個:IVF 和 HNSW。
IVF
IVF 代表反向檔案索引,是預設向量索引演算法,可在所有叢集層上運作。 這是近似近鄰 (ANN) 方法,會使用叢集來加速搜尋數據集中的類似向量。 若要建立IVF索引,請使用下列命令:
db.command({
'createIndexes': COLLECTION_NAME,
'indexes': [
{
'name': 'vectorSearchIndex',
'key': {
"contentVector": "cosmosSearch"
},
'cosmosSearchOptions': {
'kind': 'vector-ivf',
'numLists': 1,
'similarity': 'COS',
'dimensions': 1536
}
}
]
});
重要
每個向量屬性只能建立一個索引。 也就是說,您無法建立多個指向相同向量屬性的索引。 如果您想要變更索引類型(例如,從 IVF 變更為 HNSW),您必須先卸除索引,才能建立新的索引。
HNSW
HNSW 代表「階層式導覽小型世界」(Hierarchical Navigable Small World),這是將向量分割成叢集和子叢集的圖形型資料結構。 使用 HNSW,您可以使用更快的速度和更高的精確度來執行最接近的鄰近搜尋。 HNSW 是近似的 (ANN) 方法。 以下是設定方式:
db.command(
{
"createIndexes": "ExampleCollection",
"indexes": [
{
"name": "VectorSearchIndex",
"key": {
"contentVector": "cosmosSearch"
},
"cosmosSearchOptions": {
"kind": "vector-hnsw",
"m": 16, # default value
"efConstruction": 64, # default value
"similarity": "COS",
"dimensions": 1536
}
}
]
}
)
注意
HNSW 索引僅適用於 M40 叢集層和更新版本。
5.將數據插入集合
現在,將包含描述及其對應向量內嵌的清查數據插入新建立的集合中。 若要將數據插入集合中,我們會使用 insert_many() 連結庫所提供的 pymongo 方法。 方法可讓我們一次將多個檔插入集合中。 我們的數據會儲存在 JSON 檔案中,我們會載入並插入資料庫。
從 GitHub 存放 庫下載shoes_with_vectors.json 檔案,並將其儲存在 data 專案資料夾內的目錄中。
data_file = open(file="./data/shoes_with_vectors.json", mode="r")
data = json.load(data_file)
data_file.close()
result = collection.insert_many(data)
print(f"Number of data points added: {len(result.inserted_ids)}")
6. 適用於 MongoDB 虛擬核心的 Cosmos DB 向量搜尋
成功上傳數據后,我們現在可以套用向量搜尋的強大功能,以根據查詢尋找最相關的專案。 我們稍早建立的向量索引可讓我們在數據集內執行語意搜尋。
6.1 進行向量搜尋
為了執行向量搜尋,我們會定義接受 vector_search 查詢和要傳回結果數目的函式。 函式會使用 generate_embeddings 我們稍早定義的函式來產生查詢的向量,然後使用 Cosmos DB $search 的功能,根據其向量內嵌來尋找最接近的相符專案。
# Function to assist with vector search
def vector_search(query, num_results=3):
query_vector = generate_embeddings(query)
embeddings_list = []
pipeline = [
{
'$search': {
"cosmosSearch": {
"vector": query_vector,
"numLists": 1,
"path": "contentVector",
"k": num_results
},
"returnStoredSource": True }},
{'$project': { 'similarityScore': { '$meta': 'searchScore' }, 'document' : '$$ROOT' } }
]
results = collection.aggregate(pipeline)
return results
6.2 執行向量搜尋查詢
最後,我們會使用特定查詢執行向量搜尋函式,並處理結果以顯示它們:
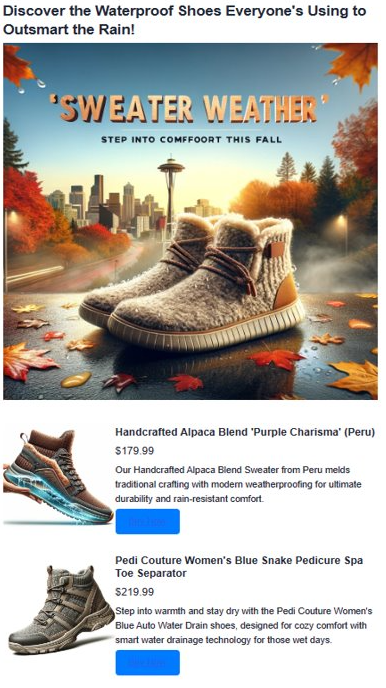
query = "Shoes for Seattle sweater weather"
results = vector_search(query, 3)
print("\nResults:\n")
for result in results:
print(f"Similarity Score: {result['similarityScore']}")
print(f"Title: {result['document']['name']}")
print(f"Price: {result['document']['price']}")
print(f"Material: {result['document']['material']}")
print(f"Image: {result['document']['img_url']}")
print(f"Purchase: {result['document']['purchase_url']}\n")
7.使用 GPT-4 和 DALL 產生廣告內容。E
我們結合所有開發元件來製作吸引人的廣告,採用 OpenAI 的 GPT-4 來製作文字和 DALL·影像的 E 3。 連同向量搜尋結果,它們會形成完整的廣告。 我們也介紹 Heelie,我們的智慧助理,負責建立吸引人的廣告標語。 透過即將推出的程序代碼,您會看到 Heelie 運作情形,增強我們的廣告建立程式。
from openai import OpenAI
def generate_ad_title(ad_topic):
system_prompt = '''
You are Heelie, an intelligent assistant for generating witty and cativating tagline for online advertisement.
- The ad campaign taglines that you generate are short and typically under 100 characters.
'''
user_prompt = f'''Generate a catchy, witty, and short sentence (less than 100 characters)
for an advertisement for selling shoes for {ad_topic}'''
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
response = client.chat.completions.create(
model="gpt-4",
messages=messages
)
return response.choices[0].message.content
def generate_ad_image(ad_topic):
daliClient = OpenAI(
api_key="<DALI_API_KEY>"
)
image_prompt = f'''
Generate a photorealistic image of an ad campaign for selling {ad_topic}.
The image should be clean, with the item being sold in the foreground with an easily identifiable landmark of the city in the background.
The image should also try to depict the weather of the location for the time of the year mentioned.
The image should not have any generated text overlay.
'''
response = daliClient.images.generate(
model="dall-e-3",
prompt= image_prompt,
size="1024x1024",
quality="standard",
n=1,
)
return response.data[0].url
def render_html_page(ad_topic):
# Find the matching shoes from the inventory
results = vector_search(ad_topic, 4)
ad_header = generate_ad_title(ad_topic)
ad_image_url = generate_ad_image(ad_topic)
with open('./data/ad-start.html', 'r', encoding='utf-8') as html_file:
html_content = html_file.read()
html_content += f'''<header>
<h1>{ad_header}</h1>
</header>'''
html_content += f'''
<section class="ad">
<img src="{ad_image_url}" alt="Base Ad Image" class="ad-image">
</section>'''
for result in results:
html_content += f'''
<section class="product">
<img src="{result['document']['img_url']}" alt="{result['document']['name']}" class="product-image">
<div class="product-details">
<h3 class="product-title" color="gray">{result['document']['name']}</h2>
<p class="product-price">{"$"+str(result['document']['price'])}</p>
<p class="product-description">{result['document']['description']}</p>
<a href="{result['document']['purchase_url']}" class="buy-now-button">Buy Now</a>
</div>
</section>
'''
html_content += '''</article>
</body>
</html>'''
return html_content
8. 把它全部放在一起
為了讓廣告產生互動,我們採用 Python 連結庫 Gradio 來建立簡單的 Web UI。 我們會定義UI,讓使用者輸入廣告主題,然後動態產生並顯示產生的廣告。
import gradio as gr
css = """
button { background-color: purple; color: red; }
<style>
</style>
"""
with gr.Blocks(css=css, theme=gr.themes.Default(spacing_size=gr.themes.sizes.spacing_sm, radius_size="none")) as demo:
subject = gr.Textbox(placeholder="Ad Keywords", label="Prompt for Heelie!!")
btn = gr.Button("Generate Ad")
output_html = gr.HTML(label="Generated Ad HTML")
btn.click(render_html_page, [subject], output_html)
btn = gr.Button("Copy HTML")
if __name__ == "__main__":
demo.launch()
輸出