Important
Azure Cosmos DB for PostgreSQL 已經走在退役路線上,不再建議新專案使用。 請改用下列兩項服務之一:
針對 PostgreSQL 工作負載: 使用 Azure Database For PostgreSQL 的彈性叢集功能 ,利用開源 Citus 擴充套件中包含的水平擴展與分散式 PostgreSQL 功能。 關於遷移指引,請參見 migrate to 適用於 PostgreSQL 的 Azure 資料庫 with Elastic Cluster。
對於 NoSQL 工作負載,建議使用 Azure Cosmos DB for NoSQL ,作為分散式資料庫解決方案,包含 99.999% 可用性服務水準協議(SLA)、即時自動擴展,以及跨多區域的自動故障轉移。
共置表示將相關資訊一起儲存在相同的節點上。 當不需要任何網路流量,即可存取所有必要資料時,查詢便可快速執行。 在不同的節點上共置相關資料,可讓查詢在每個節點上有效率地平行執行。
雜湊分散式資料表的資料共置
在 Azure Cosmos DB for PostgreSQL 中,如果分佈資料行中的值的雜湊值落在分片的雜湊範圍內,資料列就會儲存在該分片中。 具有相同雜湊範圍的延伸區一律放在相同的節點上。 具有相等散發資料行值的資料列一律位於跨資料表的相同節點上。 雜湊分散式資料表的概念也稱為資料列型分區化。 在結構描述型分區化中,分散式結構描述內的資料表一律會共置。
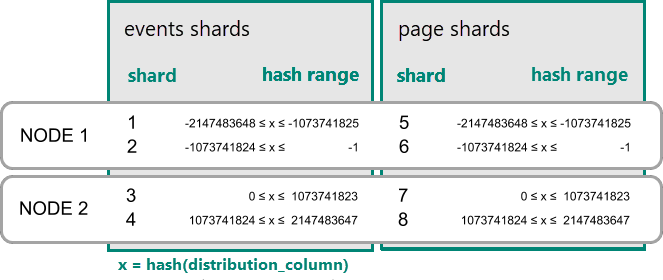
實際的共置範例
請考慮下列可能屬於多租戶 Web 分析 SaaS 的表格:
CREATE TABLE event (
tenant_id int,
event_id bigint,
page_id int,
payload jsonb,
primary key (tenant_id, event_id)
);
CREATE TABLE page (
tenant_id int,
page_id int,
path text,
primary key (tenant_id, page_id)
);
現在我們想要回答面向客戶的儀表板可能發出的查詢。 範例查詢是「針對租用戶六中以 '/blog' 開頭的所有頁面,傳回過去一週的造訪次數。」
如果我們的資料位於單一 PostgreSQL 伺服器中,我們可以輕鬆地使用 SQL 所提供的豐富關聯式作業集來表達查詢:
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
只要此查詢的工作集可放入記憶體中,單一伺服器資料表就是適當的解決方案。 讓我們考慮使用 Azure Cosmos DB for PostgreSQL 調整資料模型的機會。
按照識別碼分配資料表
單一伺服器查詢會隨著租用戶數目和每個租用戶儲存的資料成長而開始變慢。 工作集會停止放入記憶體中,而且 CPU 會變成瓶頸。
在此情況下,我們可以使用 Azure Cosmos DB for PostgreSQL,跨多個節點將資料分區。 決定延伸區時,我們需要做出的第一個且最重要選擇是散發資料行。 讓我們從針對事件資料表使用 event_id,以及針對 page_id 資料表使用 page 的幼稚選擇開始:
-- naively use event_id and page_id as distribution columns
SELECT create_distributed_table('event', 'event_id');
SELECT create_distributed_table('page', 'page_id');
當資料分散到不同的工作者時,我們無法像在單一 PostgreSQL 節點上一樣執行 JOIN。 相反地,我們需要發出兩個查詢:
-- (Q1) get the relevant page_ids
SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6;
-- (Q2) get the counts
SELECT page_id, count(*) AS count
FROM event
WHERE page_id IN (/*…page IDs from first query…*/)
AND tenant_id = 6
AND (payload->>'time')::date >= now() - interval '1 week'
GROUP BY page_id ORDER BY count DESC LIMIT 10;
之後,應用程式必須合併來自這兩個步驟的結果。
執行查詢必須在分散於節點的分區中查閱資料。
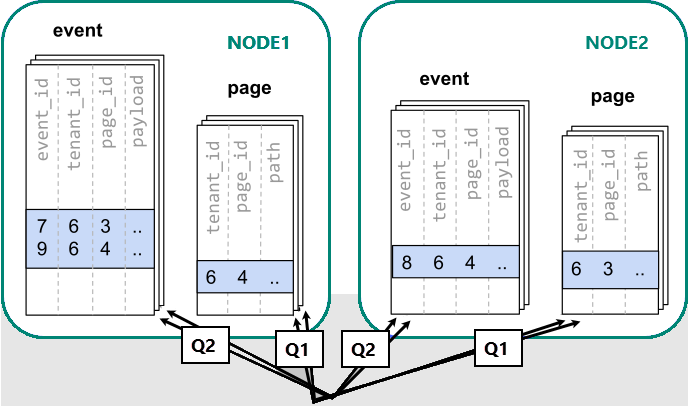
在此情況下,資料散發會產生重大缺點:
- 查詢每個延伸區和執行多個查詢的額外負荷。
- Q1 將許多資料列傳回給用戶端的額外負荷。
- Q2 變得很大。
- 若需要以多個步驟撰寫查詢,則應用程式需要變更。
資料是分散的,因此可以平行處理查詢。 只有在查詢所執行的工作量遠大於查詢許多分區的額外負荷時,才有益處。
依租用戶散發資料表
在 Azure Cosmos DB for PostgreSQL 中,具有相同分佈欄位值的資料列保證在相同節點上。 從零開始,我們可以將 tenant_id 作為分配資料欄來建立資料表。
-- co-locate tables by using a common distribution column
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with => 'event');
現在 Azure Cosmos DB for PostgreSQL 可以回答原始的單一伺服器查詢,而不需修改 (Q1):
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
由於根據 tenant_id 進行篩選和聯結,因此 Azure Cosmos DB for PostgreSQL 知道可以使用包含該特定租用戶資料的共置延伸區集來回答整個查詢。 單一 PostgreSQL 節點可以採取單一步驟回答查詢。
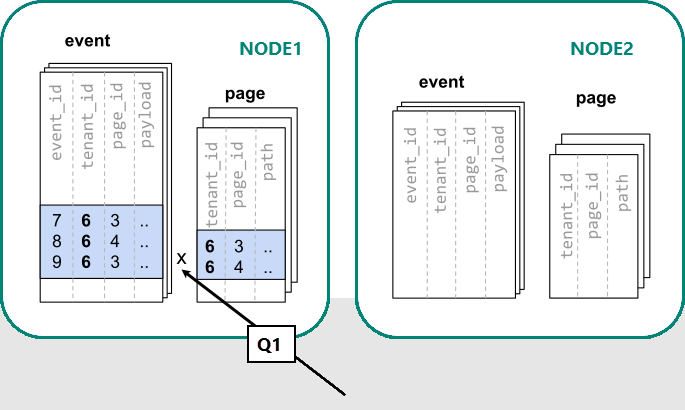
在某些情況下,必須變更查詢和資料表結構描述,以在唯一的條件約束和聯結條件中包含租用戶識別碼。 此變更通常很簡單。
下一步
- 請參閱多租用戶教學課程 (部分機器翻譯) 以了解如何共置租用戶資料。