調整佈建輸送量 (RU/秒) 的最佳做法
適用於:![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
本文說明縮放資料庫或容器 (集合、資料表或圖表) 輸送量 (RU/秒) 的最佳做法和策略。 這些概念適用於針對任何 Azure Cosmos DB API 任何資源,提高佈建手動 RU/秒或自動調整最大 RU/秒。
必要條件
- 如果您不熟悉如何在 Azure Cosmos DB 中進行資料分割和縮放,建議先閱讀 Azure Cosmos DB 中的資料分割和水平縮放一文。
- 如果您打算依據 429 例外狀況來調整 RU/秒,請參閱診斷和疑難排解 Azure Cosmos DB 要求率太大 (429) 例外狀況的指引。 提高 RU/秒之前,請先找出問題的根本原因,並確認提高 RU/秒是否為適當的解決方案。
縮放 RU/秒的背景
當您傳送提高資料庫或容器 RU/秒的要求時,視所要求的 RU/秒及目前的實體分割區配置而定,擴大作業可能會立即完成或以非同步方式完成 (通常是 4-6 小時)。
- 立即擴大
- 當目前的實體分割區配置可支援您所要求的 RU/秒時,Azure Cosmos DB 即不需要分割或新增分割區。
- 因此,此作業會立即完成,RU/秒也可供使用。
- 非同步擴大
- 當要求的 RU/秒高於實體分割區配置可支援的量時,Azure Cosmos DB 即會分割現有的實體分割區。 這項作業會持續進行,直到資源具備的最低分割區數目可支援所要求的 RU/秒為止。
- 因此,可能需要一些時間才能完成作業,通常是 4-6 小時。 每個實體分割區最多可支援 10,000 RU/秒 (適用於所有 API) 的輸送量和 50 GB 的儲存體 (適用於所有 API,但 Cassandra 除外,其儲存體為 30 GB)。
注意
如果您在非同步擴大作業進行期間執行手動區域容錯移轉作業或新增/移除新的區域,則系統會暫停輸送量擴大作業。 當容錯移轉或新增/移除區域作業完成時,就會自動繼續擴大作業。
- 立即縮小
- 針對縮小作業,Azure Cosmos DB 不需要分割或新增分割區。
- 因此,此作業會立即完成,RU/秒也可供使用,
- 而這項作業的主要結果是每個實體分割區的 RU 會減少。
如何在不變更分割區配置的情況下擴大 RU/秒
步驟 1:找出目前的實體分割區數目。
瀏覽至 [見解]>[輸送量]>[Normalized RU Consumption (%) By PartitionKeyRangeID] \(依 PartitionKeyRangeID 排序的標準化 RU 使用量 (%)\)。 計算相異的 PartitionKeyRangeId 數目。
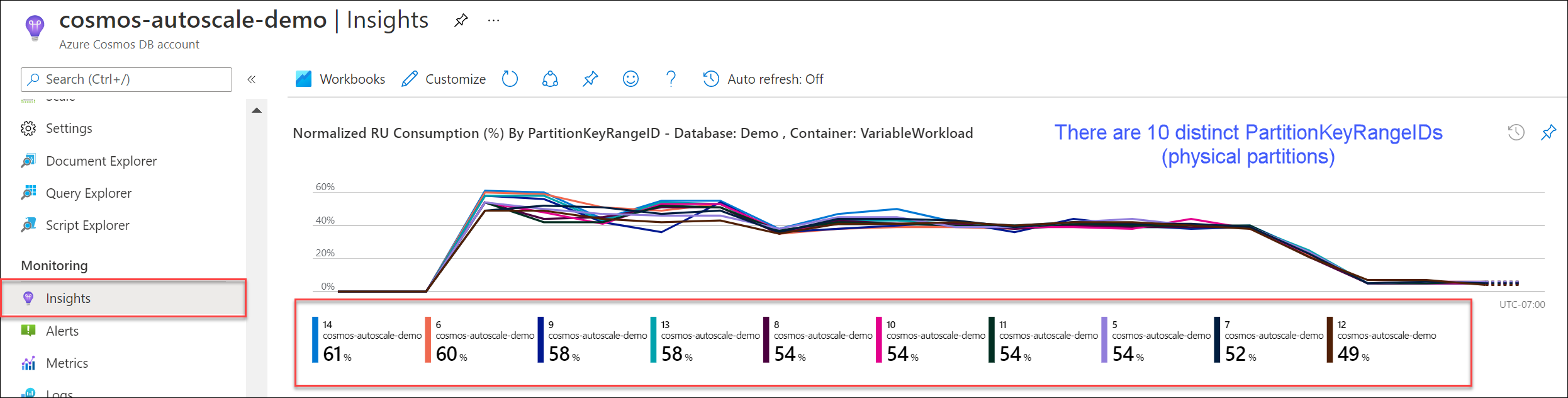
注意
圖表最多會顯示 50 個 PartitionKeyRangeId。 如果資源數超過 50,您可以使用 Azure Cosmos DB REST API 來計算分割區總數。
每個 PartitionKeyRangeId 會對應至一個實體分割區,並指派來保存某範圍可能雜湊值的資料。
Azure Cosmos DB 會根據您的分割區索引鍵,將資料分散到邏輯和實體分割區,以啟用水平縮放。 寫入資料時,Azure Cosmos DB 會使用分割區索引鍵值的雜湊,來判斷資料位於哪個邏輯和實體分割區。
步驟 2:計算預設最大輸送量
Current number of physical partitions * 10,000 RU/s 是可以擴縮的最高 RU/秒,此範圍內都不會觸發 Azure Cosmos DB 將分割區分割。 您可以從 Azure Cosmos DB 資源提供者中取得此值。 在資料庫或容器輸送量設定物件上執行 GET 要求,然後擷取 instantMaximumThroughput 屬性。 此值也可以在入口網站中資料庫或容器的 [調整和設定] 頁面中取得。
範例
假設某個現有容器具有五個實體分割區,以及 30,000 RU/秒的手動佈建輸送量。 我們可以立即將 RU/秒提高到 5 * 10,000 RU/秒 = 50,000 RU/秒。 同樣地,如果某個容器具有 30,000 RU/秒的自動調整最大 RU/秒 (可在 3000-30,000 RU/秒之間擴縮),我們就可以立即將最大 RU/秒提高至 50,000 RU/秒 (可在 5000-50,000 RU/秒之間擴縮)。
提示
如果您要擴大 RU/秒以回應要求率太大的例外狀況 (429),建議您先將 RU/秒提高到目前實體分割區配置所支援的最高 RU/秒,並評估新的 RU/秒是否足夠,之後再進一步提高。
如何確保非同步擴縮期間資料能平均散發
背景
當您將 RU/秒提高到超過目前的實體分割區數目 * 10,000 RU/秒時,Azure Cosmos DB 即會分割現有的分割區,直到新的分割區數目 = ROUNDUP(requested RU/s / 10,000 RU/s) 為止。 在分割期間,系統會將父分割區分割成兩個子分割區。
舉例來說,假設某個容器具有三個實體分割區,以及 30,000 RU/秒的手動佈建輸送量。 如果我們將輸送量提高到 45,000 RU/秒,Azure Cosmos DB 即會分割兩個現有的實體分割區,因此總共會有 ROUNDUP(45,000 RU/s / 10,000 RU/s) = 5 個實體分割區。
注意
應用程式一律可以在分割期間內嵌或查詢資料。 Azure Cosmos DB 用戶端 SDK 和服務會自動處理此案例,並確保將要求路由傳送至正確的實體分割區,所以不需要額外的使用者動作。
如果工作負載的儲存和要求量非常平均分散 (通常是由 /id 這類高基數欄位來分割),建議您在擴大時將 RU/秒設定為可讓所有分割區平均分割。
為了解原因,讓我們來看一個範例,假設某個容器具有 2 個實體分割區、20,000 RU/秒和 80 GB 的資料。
由於選擇具有高基數的良好分割區索引鍵,因此資料大致平均分散在兩個實體分割區中。 每個實體分割區大約會指派 50% 的 keyspace ,其定義為可能雜湊值的總範圍。
此外,Azure Cosmos DB 會將 RU/秒平均分散給所有實體分割區。 因此,每個實體分割區都有 10,000 RU/秒和 50% (40 GB) 的總資料量。 下圖顯示我們目前的狀態。

現在,假設我們想將 RU/秒從 20,000 RU/秒提高到 30,000 RU/秒。
如果我們單純將 RU/秒提高到 30,000 RU/秒,則只會分割其中一個分割區。 分割之後,我們會得到:
- 一個包含 50% 資料的分割區 (此分割區並未分割)
- 兩個各包含 25% 資料的分割區 (這些是從父分割區所分割出的子分割區)
因為 Azure Cosmos DB 會將 RU/秒平均分散到所有實體分割區,所以每個實體分割區仍會取得 10,000 RU/秒。 不過,我們現在知道儲存和要求散發量當中有扭曲。
在下圖中,我們看到分割區 3 和 4 (分割區 2 的子分割區) 各有 10,000 RU/秒來服務 20 GB 資料的要求,而分割區 1 具有 10,000 RU/秒來服務兩倍資料 (40 GB) 的要求。

若要維持儲存量平均分配,我們可以先擴大 RU/秒,以確保每個分割區都能分割。 然後,我們可以將 RU/秒縮小回預期的狀態。
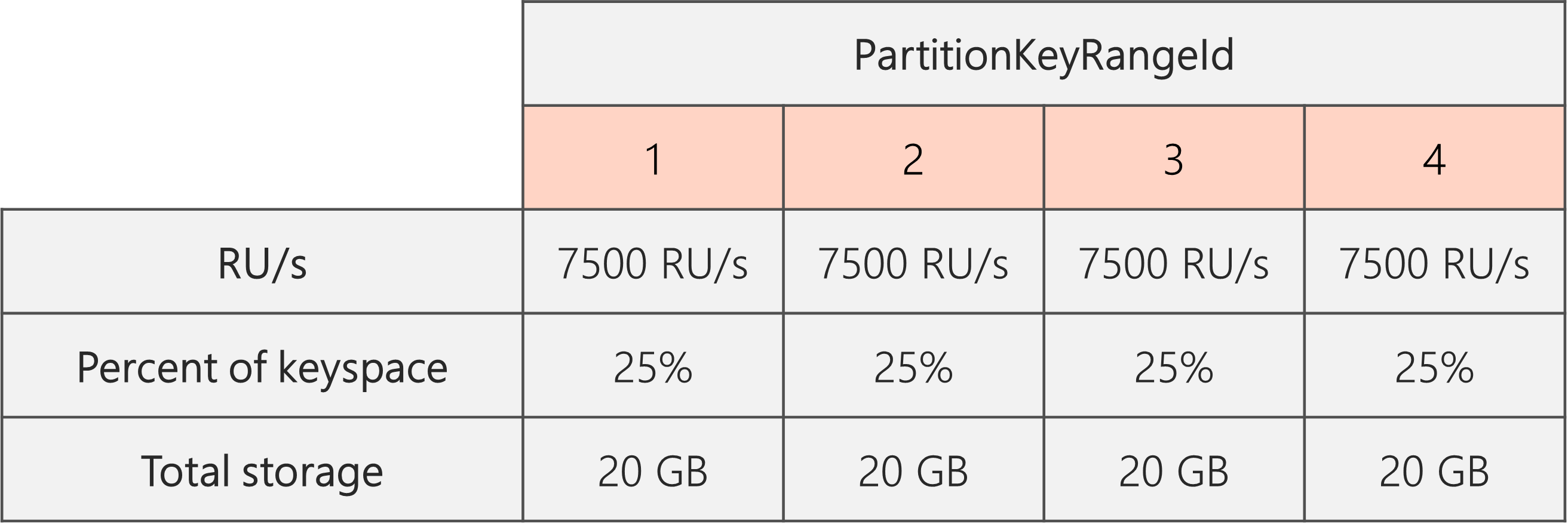
因此,如果我們一開始是使用兩個實體分割區,為了保證分割區在分割之後仍保持平均,我們必須將 RU/秒設定為最後能有四個實體分割區。 為了達到此目的,我們會先為每個分割區設定 RU/秒 = 4 * 10,000 RU/秒 = 40,000 RU/秒。 然後,在分割完成之後,我們即可將 RU/秒降低為 30,000 RU/秒。
如此一來,即為下圖所示,每個實體分割區取得 30,000 RU/秒/4 = 7500 RU/秒來服務 20 GB 資料的要求。 整體來說,我們會維持各分割區的儲存和要求量平均分配。
一般公式
步驟 1:提高您的 RU/秒,以確保所有分割區平均分割
一般來說,如果您的實體分割區起始數目是 P,而且想要設定所需的 RU/秒為 S:
將 RU/秒提高到:10,000 * P * (2 ^ (ROUNDUP(LOG_2 (S/(10,000 * P))))。 如此即可提供最接近所需值的 RU/秒,以確保所有分割區都會平均分割。
注意
當您提高資料庫或容器的 RU/秒時,可能會影響您未來可降低的 RU/秒下限。 通常,最小 RU/秒為 MAX(400 RU/秒,目前的儲存體 (GB) * 1 RU/秒,曾佈建的最高 RU/秒/100)。 例如,如果您已調整的最高 RU/秒為 100,000 RU/秒,則未來可以設定的最低 RU/秒是 1000 RU/秒。 深入了解最小 RU/秒。
步驟 2:將 RU/秒降低為所需的 RU/秒
舉例來說,假設我們有五個實體分割區,50,000 RU/秒,而且想要調整至 150,000 RU/秒。 我們應該先設定:10,000 * 5 * (2 ^ (ROUND(LOG_2(150,000/(10,000 * 5)))) = 200,000 RU/秒,然後再降低至 150,000 RU/秒。
當我們擴大至 200,000 RU/秒時,未來可以設定的最低手動 RU/秒就是 2000 RU/秒。 我們可以設定的最低自動調整 RU/秒上限為 20,000 RU/秒 (可在 2000 - 20,000 RU/秒之間擴縮)。 由於我們的目標 RU/秒是 150,000 RU/秒,因此不會受到最小 RU/秒的影響。
如何最佳化 RU/秒以進行大型資料內嵌
當您打算將大量資料移轉或內嵌至 Azure Cosmos DB 時,建議您設定容器的 RU/秒,讓 Azure Cosmos DB 預先佈建所需的實體分割區,以儲存您打算預先內嵌的資料總量。 否則,在內嵌期間,Azure Cosmos DB 可能必須進行分割區分割,這會增加資料內嵌的時間。
我們可以利用這項事實:在建立容器時,Azure Cosmos DB 會使用起點 RU/秒的啟發式公式,來計算一開始使用的實體分割區數目。
步驟 1:檢閱分割區索引鍵的選擇
遵循選擇分割區索引鍵的最佳做法,以確保移轉後的要求量和儲存量能平均分配。
步驟 2:計算您需要的實體分割區數目
Number of physical partitions = Total data size in GB / Target data per physical partition in GB
每個實體分割區最多可保存 50 GB 的儲存體 (30 GB 用於 Cassandra API)。 您應該選擇哪種 Target data per physical partition in GB 值,取決於您想要的實體分割區完善程度,以及移轉後預期的儲存量成長程度。
例如,如果您預期儲存量會持續成長,您可以選擇將值設定為 30 GB。 假設您選擇了可平均分配儲存量的良好分割區索引鍵,每個分割區將會佔用 60% 左右容量 (50 GB 中佔 30 GB)。 在寫入未來的資料時,系統可以將資料儲存在現有的實體分割區,而不需要讓服務立即新增更多實體分割區。
相反地,如果您認為儲存量不會在移轉後大幅成長,您可以選擇設定較高的值,例如 45 GB。 這表示每個分割區將會佔用 90% 左右容量 (50 GB 中佔 45 GB)。 如此可將資料分散到的實體分割區數目降至最低,也表示每個實體分割區可取得絕大多數的總佈建 RU/秒。
步驟 3:計算所有分割區一開始使用的 RU/秒數目
Starting RU/s for all partitions = Number of physical partitions * Initial throughput per physical partition.
請從具有每個實體分割區的任意目標 RU/秒數目的範例開始。
Initial throughput per physical partition= 每個實體分割區 10,000 RU/秒 (使用自動調整或共用輸送量資料庫時)Initial throughput per physical partition= 每個實體分割區 6,000 RU/秒 (使用手動輸送量時)
範例
假設我們打算內嵌 1 TB (1000 GB) 資料,並想要使用手動輸送量。 Azure Cosmos DB 中的每個實體分割區都有 50 GB 的容量。 假設我們的目標是讓分割區佔用 80% 容量 (40 GB),保留空間以供未來成長之用。
這表示,針對 1 TB 的資料,我們需要 1000 GB/40 GB = 25 個實體分割區。 為了確保得到 25 個實體分割區,如果我們使用手動輸送量,我們要先佈建 25 * 6000 RU/秒 = 150,000 RU/秒。 然後,在建立容器之後,為了讓內嵌速度更快,我們會先將 RU/秒提高到 250,000 RU/秒,再開始內嵌 (因為我們已經有 25 個實體分割區,所以內嵌會立即進行)。 這可讓每個分割區取得最多 10,000 RU/秒。
如果我們使用自動調整輸送量或共用輸送量資料庫,為了取得 25 個實體分割區,我們要先佈建 25 * 10,000 RU/秒 = 250,000 RU/秒。 由於我們已經達到可支援 25 個實體分割區的最高 RU/秒,因此不用在內嵌之前提高佈建的 RU/秒。
理論上,使用 250,000 RU/秒和 1 TB 的資料時,假設有 1 KB 文件和 10 RU 需要寫入,內嵌完成時間為:1000 GB * (1,000,000 KB/1 GB) * (1 個文件/1 KB) * (10 RU/文件) * (1 秒/250,000 RU) * (1 小時/3600 秒) = 11.1 小時。
這項計算是假設執行內嵌的用戶端可以完全佔滿輸送量,並將寫入分散到所有實體分割區的估計值。 最佳做法是,建議在用戶端上「隨機」寫入資料。 如此可確保用戶端每秒都會寫入許多不同邏輯 (也就是實體) 分割區。
完成移轉之後,我們即可降低 RU/秒,或視需要啟用自動調整。
下一步
- 監視資料庫或容器的標準化 RU/秒耗用量。
- 針對要求率太大 (429) 例外狀況進行診斷和疑難排解。
- 在資料庫或容器上啟用自動調整。