dcountif() (聚合函數)
估計述詞評估為true的數據列相異值數目。
Null 值會被忽略,且不會納入計算。
注意
此函式會與 summarize 運算子搭配使用。
語法
dcountif(expr, 述詞, [, 精確度])
深入瞭解 語法慣例。
參數
| 姓名 | 類型 | 必要 | 描述 |
|---|---|---|---|
| expr | string |
✔️ | 用於匯總計算的表達式。 |
| 謂語 | string |
✔️ | 用來篩選數據列的表達式。 |
| 準確性 | int |
速度與精確度之間的控制。 如果未指定,則預設值為 1。 如需支援的值,請參閱 估計精確度 。 |
傳回
針對述詞評估為true的數據列,傳回expr相異值的估計值。
提示
dcountif() 如果所有數據列都未傳遞 Predicate 表達式,可能會傳回錯誤。
範例
此範例顯示每個狀態中發生多少類型的嚴重風暴事件。
StormEvents
| summarize DifferentFatalEvents=dcountif(EventType,(DeathsDirect + DeathsIndirect)>0) by State
| where DifferentFatalEvents > 0
| order by DifferentFatalEvents
顯示的結果數據表只包含前10個數據列。
| 州/省 | DifferentFatalEvents |
|---|---|
| 加利福尼亞州 | 12 |
| 德克薩斯州 | 12 |
| 奧克拉荷馬州 | 10 |
| 伊利諾州 | 9 |
| 堪薩斯州 | 9 |
| 紐約州 | 9 |
| 紐澤西州 | 7 |
| 華盛頓州 | 7 |
| 密西根州 | 7 |
| 密蘇里州 | 7 |
| ... | ... |
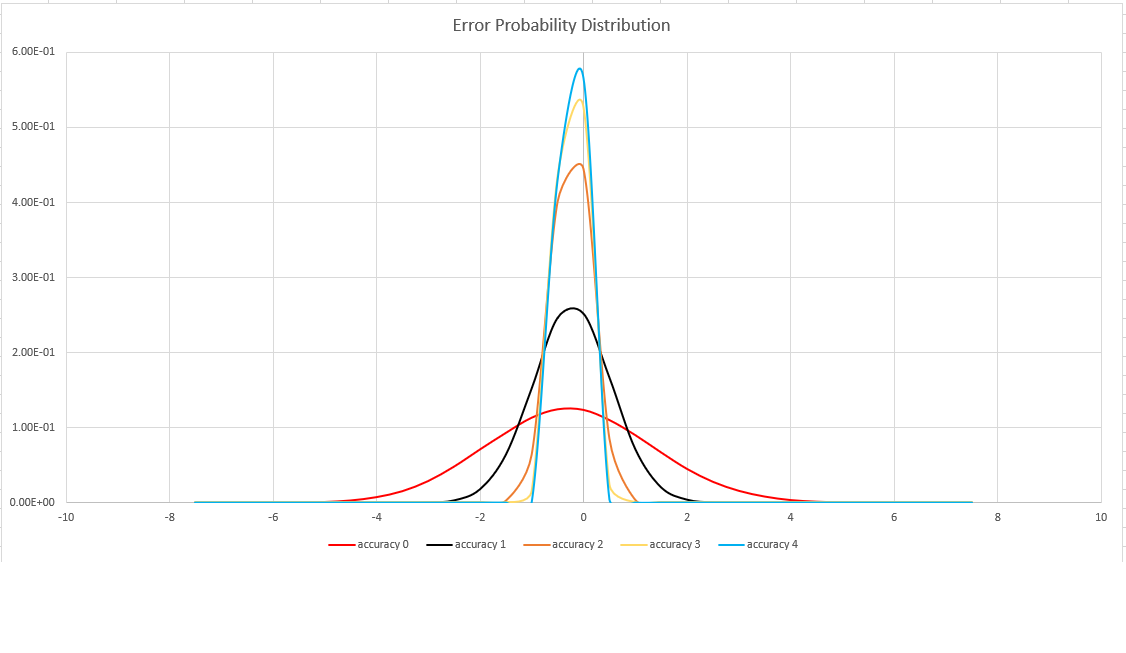
估計的正確性
此函式會使用 HyperLogLog (HLL) 演算法的變體,它會對集合基數執行隨機估計。 此演算法提供「旋鈕」,可用來平衡每個記憶體大小的正確性和運行時間:
| 正確性 | 錯誤 ≤ | 項目計數 |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0.8 | 214 |
| 2 | 0.4 | 216 |
| 3 | 0.28 | 217 |
| 4 | 0.2 | 218 |
注意
「進入計數」數據行是 HLL 實作中的 1 位元節計數器數目。
如果設定基數夠小,演算法會包含一些用於執行完美計數(零錯誤)的布建:
- 當精確度層級為
1時,會傳回 1000 個值 - 當精確度層級為
2時,會傳回8000個值
錯誤系結是概率的,而不是理論系結。 此值是誤差分佈的標準偏差(sigma),而 99.7% 的估計會有 3 x sigma 以下的相對誤差。
下圖顯示相對估計誤差的機率分佈函數,以百分比表示所有支援的精確度設定:
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應