根本原因分析的異常診斷
Kusto 查詢語言 (KQL) 具有內建的異常偵測和預測功能,可檢查異常行為。 偵測到這類模式之後,就可以執行根本原因分析(RCA),以減輕或解決異常狀況。
診斷程式很複雜且冗長,並由領域專家完成。 此程式包括:
- 從不同時間範圍擷取和聯結更多數據
- 尋找多個維度上值分佈的變更
- 繪製更多變數圖表
- 以領域知識和直覺為基礎的其他技術
由於這些診斷案例很常見,因此機器學習外掛程式可讓您更輕鬆地進行診斷階段,並縮短 RCA 的持續時間。
下列三個 機器學習 外掛程式都會實作叢集演算法:autocluster、 basket和 diffpatterns。 autocluster和 basket 外掛程式會叢集單一記錄集,而diffpatterns外掛程式會叢集兩個記錄集之間的差異。
叢集單一記錄集
常見案例包含特定準則所選取的數據集,例如:
- 顯示異常行為的時段
- 高溫裝置讀數
- 持續時間長命令
- 熱門消費使用者
您想要快速且簡單的方式來尋找資料中的常見模式(區段)。 模式是數據集的子集,其記錄在多個維度上共用相同的值(類別數據行)。
下列查詢會建置並顯示一周期間服務例外狀況的時間序列,以十分鐘間隔為單位:
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m
| render timechart with(title="Service exceptions over a week, 10 minutes resolution")
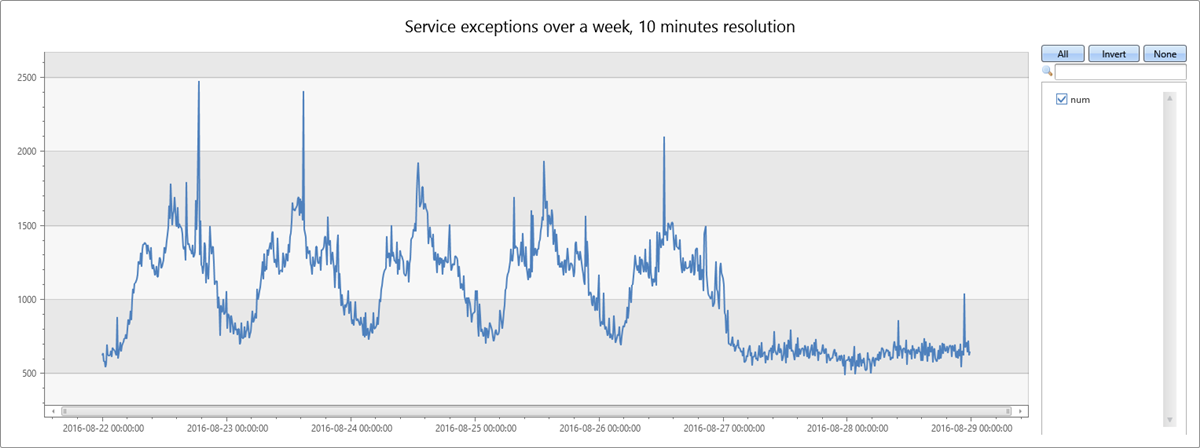
服務例外狀況計數會與整體服務流量相互關聯。 您可以清楚地看到工作日的每日模式,星期一到星期五。 服務例外狀況計數在中午增加,夜間計數會下降。 週末會顯示平低計數。 您可以使用 時間序列異常偵測來偵測例外狀況尖峰。
數據的第二個尖峰發生在週二下午。 下列查詢可用來進一步診斷和驗證其是否尖峰。 此查詢會在 1 分鐘間隔中,以 8 小時的較高解析度重新繪製圖表周圍的尖峰。然後,您可以研究其框線。
let min_t=datetime(2016-08-23 11:00);
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to min_t+8h step 1m
| render timechart with(title="Zoom on the 2nd spike, 1 minute resolution")
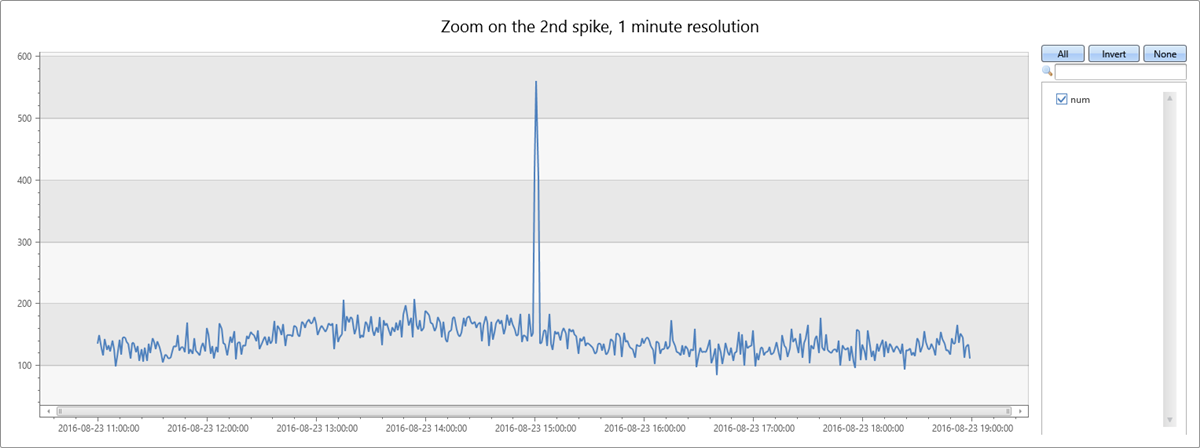
您會看到從 15:00 到 15:02 的窄兩分鐘尖峰。 在下列查詢中,計算此兩分鐘視窗中的例外狀況:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| count
| 計數 |
|---|
| 972 |
在下列查詢中,範例 20 個例外狀況超過 972:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| take 20
| PreciseTimeStamp | 區域 | ScaleUnit | DeploymentId | 追蹤點 | ServiceHost |
|---|---|---|---|---|---|
| 2016-08-23 15:00:08.7302460 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:09.9496584 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 8d257da1-7a1c-44f5-9acd-f9e02ff507fd |
| 2016-08-23 15:00:10.5911748 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:12.2957912 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | f855fcef-ebfe-405d-aaf8-9c5e2e43d862 |
| 2016-08-23 15:00:18.5955357 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 9d390e07-417d-42eb-bebd-793965189a28 |
| 2016-08-23 15:00:20.7444854 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 6e54c1c8-42d3-4e4e-8b79-9bb076ca71f1 |
| 2016-08-23 15:00:23.8694999 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 36109 | 19422243-19b9-4d85-9ca6-bc961861d287 |
| 2016-08-23 15:00:26.4271786 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 36109 | 3271bae4-1c5b-4f73-98ef-cc117e9be914 |
| 2016-08-23 15:00:27.8958124 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 904498 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:32.9884969 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007007 | d5c7c825-9d46-4ab7-a0c1-8e2ac1d83ddb |
| 2016-08-23 15:00:34.5061623 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:37.4490273 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | f2ee8254-173c-477d-a1de-4902150ea50d |
| 2016-08-23 15:00:41.2431223 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 103200 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:47.2983975 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 423690590 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:50.5932834 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 2a41b552-aa19-4987-8cdd-410a3af016ac |
| 2016-08-23 15:00:50.8259021 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 0d56b8e3-470d-4213-91da-97405f8d005e |
| 2016-08-23 15:00:53.2490731 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 36109 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:57.0000946 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 64038 | cb55739e-4afe-46a3-970f-1b49d8ee7564 |
| 2016-08-23 15:00:58.2222707 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | 8215dcf6-2de0-42bd-9c90-181c70486c9c |
| 2016-08-23 15:00:59.9382620 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | 451e3c4c-0808-4566-a64d-84d85cf30978 |
使用 autocluster() 進行單一記錄集叢集
雖然只有不到一千個例外狀況,但還是很難找到常見的區段,因為每個數據行中都有多個值。 您可以使用 autocluster() 外掛程式來立即擷取一份常見區段的簡短清單,並在尖峰的兩分鐘內尋找有趣的叢集,如下列查詢所示:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate autocluster()
| SegmentId | 計數 | Percent | 區域 | ScaleUnit | DeploymentId | ServiceHost |
|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 1 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | |
| 2 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 3 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | |
| 4 | 55 | 5.65843621399177 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc |
您可以從上述結果中看到,最佔主導地位的區段包含 65.74% 的總例外狀況記錄和共用四個維度。 下一個區段比較不常見。 它只包含 9.67% 的記錄,並共用三個維度。 其他區段也比較不常見。
Autocluster 會使用專屬演算法來採礦多個維度,並擷取有趣的區段。 「有趣」表示每個區段都有記錄集和功能集的重要涵蓋範圍。 區段也會不同,這表示每個區段都與其他區段不同。 其中一或多個區段可能與 RCA 程序相關。 若要將區段檢閱和評量降到最低,自動叢集只會擷取小型區段清單。
使用購物籃() 進行單一記錄集叢集
您也可以使用外掛程式, basket() 如下列查詢所示:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate basket()
| SegmentId | 計數 | Percent | 區域 | ScaleUnit | DeploymentId | 追蹤點 | ServiceHost |
|---|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec | |
| 1 | 642 | 66.0493827160494 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | ||
| 2 | 324 | 33.3333333333333 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 0 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 3 | 315 | 32.4074074074074 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 16108 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 4 | 328 | 33.7448559670782 | 0 | ||||
| 5 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | ||
| 6 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | ||
| 7 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | ||
| 8 | 167 | 17.1810699588477 | scus | ||||
| 9 | 55 | 5.65843621399177 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | ||
| 10 | 92 | 9.46502057613169 | 10007007 | ||||
| 11 | 90 | 9.25925925925926 | 10007006 | ||||
| 12 | 57 | 5.8641975308642 | 00000000-0000-0000-0000-000000000000 |
購物籃會實作專案集採礦的 「Apriori」 演算法。 它會擷取記錄集涵蓋範圍高於閾值 (預設值 5%) 的所有區段。 您可以看到已使用類似區段來擷取更多區段,例如區段 0、1 或 2、3。
這兩個外掛程式都強大且易於使用。 其限制是,它們會以沒有標籤的未監督方式將單一記錄集叢集。 目前還不清楚擷取的模式是否描述選取的記錄集、異常記錄或全域記錄集的特性。
將兩個記錄集之間的差異叢集
外掛程式diffpatterns()克服和basket的限制autocluster。 Diffpatterns 會取得兩個記錄集,並擷取不同的主要區段。 一組通常會包含正在調查的異常記錄集。 其中一個是由 autocluster 和 basket進行分析。 另一個集合包含參考記錄集基準。
在下列查詢中, diffpatterns 會在尖峰的兩分鐘內尋找有趣的叢集,這與基準內的叢集不同。 當尖峰啟動時,基準視窗會定義為15:00之前的8分鐘。 您可以延伸二進位資料行 (AB),並指定特定記錄屬於基準或異常集合。 Diffpatterns 會實作監督式學習演算法,其中兩個類別標籤是由異常與基準旗標 (AB) 所產生。
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
let min_baseline_t=datetime(2016-08-23 14:50);
let max_baseline_t=datetime(2016-08-23 14:58); // Leave a gap between the baseline and the spike to avoid the transition zone.
let splitime=(max_baseline_t+min_peak_t)/2.0;
demo_clustering1
| where (PreciseTimeStamp between(min_baseline_t..max_baseline_t)) or
(PreciseTimeStamp between(min_peak_t..max_peak_t))
| extend AB=iff(PreciseTimeStamp > splitime, 'Anomaly', 'Baseline')
| evaluate diffpatterns(AB, 'Anomaly', 'Baseline')
| SegmentId | CountA | CountB | PercentA | PercentB | PercentDiffAB | 區域 | ScaleUnit | DeploymentId | 追蹤點 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 639 | 21 | 65.74 | 1.7 | 64.04 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | |
| 1 | 167 | 544 | 17.18 | 44.16 | 26.97 | scus | |||
| 2 | 92 | 356 | 9.47 | 28.9 | 19.43 | 10007007 | |||
| 3 | 90 | 336 | 9.26 | 27.27 | 18.01 | 10007006 | |||
| 4 | 82 | 318 | 8.44 | 25.81 | 17.38 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 5 | 55 | 252 | 5.66 | 20.45 | 14.8 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | |
| 6 | 57 | 204 | 5.86 (機器翻譯) | 16.56 | 10.69 |
最佔主導地位的區段是 所擷取的 autocluster相同區段。 它在兩分鐘的異常時段的涵蓋範圍也是 65.74%。 不過,在 8 分鐘基準視窗的涵蓋範圍只有 1.7%。 差異為 64.04%。 這種差異似乎與異常尖峰有關。 若要確認此假設,下列查詢會將原始圖表分割成屬於此有問題的區段的記錄,以及來自其他區段的記錄。
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| extend seg = iff(Region == "eau" and ScaleUnit == "su7" and DeploymentId == "b5d1d4df547d4a04ac15885617edba57"
and ServiceHost == "e7f60c5d-4944-42b3-922a-92e98a8e7dec", "Problem", "Normal")
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m by seg
| render timechart
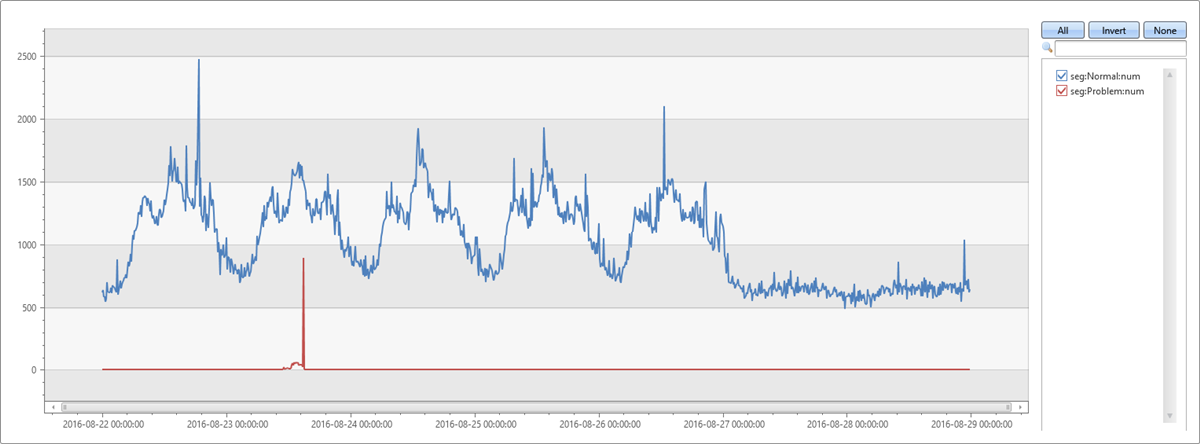
此圖表可讓我們查看週二下午的尖峰是因為使用外掛程式探索 diffpatterns 到此特定區段的例外狀況。
摘要
機器學習 外掛程式對許多案例很有説明。 和 basket 會autocluster實作不受監督的學習演算法,而且很容易使用。 Diffpatterns 會實作受監督式學習演算法,雖然較為複雜,但它對於擷取 RCA 的差異區段更為強大。
這些外掛程式會在臨機操作案例和自動近乎即時的監視服務中以互動方式使用。 時間序列異常偵測接著診斷程式。 此程式已高度優化,以符合必要的效能標準。
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應