本文說明容器化工作負載如何在 Azure Stack Edge Pro GPU 裝置上共用 GPU。 此方法牽涉到啟用多程序服務 (MPS),然後透過 IoT Edge 部署來指定 GPU 工作負載。
先決條件
在您開始前,請確定:
您可以存取已 啟用 且已 設定計算的 Azure Stack Edge Pro GPU 裝置。 您擁有 Kubernetes API 端點,而且已將此端點新增至
hosts用戶端上將會存取裝置的檔案。您可以存取具有 支援作業系統的用戶端系統。 如果使用 Windows 用戶端,系統應該執行 PowerShell 5.0 或更新版本來存取該裝置。
在本機系統上
json儲存下列部署。 您將使用此檔案的資訊來執行 IoT Edge 部署。 此部署是基於 NVIDIA 公開提供的簡單 CUDA 容器。{ "modulesContent": { "$edgeAgent": { "properties.desired": { "modules": { "cuda-sample1": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" }, "cuda-sample2": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" } }, "runtime": { "settings": { "minDockerVersion": "v1.25" }, "type": "docker" }, "schemaVersion": "1.1", "systemModules": { "edgeAgent": { "settings": { "image": "mcr.microsoft.com/azureiotedge-agent:1.0", "createOptions": "" }, "type": "docker" }, "edgeHub": { "settings": { "image": "mcr.microsoft.com/azureiotedge-hub:1.0", "createOptions": "{\"HostConfig\":{\"PortBindings\":{\"443/tcp\":[{\"HostPort\":\"443\"}],\"5671/tcp\":[{\"HostPort\":\"5671\"}],\"8883/tcp\":[{\"HostPort\":\"8883\"}]}}}" }, "type": "docker", "status": "running", "restartPolicy": "always" } } } }, "$edgeHub": { "properties.desired": { "routes": { "route": "FROM /messages/* INTO $upstream" }, "schemaVersion": "1.1", "storeAndForwardConfiguration": { "timeToLiveSecs": 7200 } } }, "cuda-sample1": { "properties.desired": {} }, "cuda-sample2": { "properties.desired": {} } } }
驗證 GPU 驅動程式、CUDA 版本
首要步驟需要確認您的裝置正在執行必要的 GPU 驅動程式和 CUDA 版本。
執行以下命令:
Get-HcsGpuNvidiaSmi在 NVIDIA smi 輸出中,記下您裝置上的 GPU 版本和 CUDA 版本。 如果您執行 Azure Stack Edge 2102 軟體,此版本會對應至下列驅動程式版本:
- GPU 驅動程式版本:460.32.03
- CUDA 版本:11.2
以下為範例輸出:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Tue Feb 23 10:34:01 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 0000041F:00:00.0 Off | 0 | | N/A 40C P8 15W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>請讓此工作階段保持開啟,因為您將用它來檢視整篇文章中的 NVIDIA smi 輸出。
進行無內容共用的部署
您現在可以在多進程服務未執行且沒有內容共用時,在裝置上部署應用程式。 此部署會透過 Azure 入口網站在裝置上所存在的 iotedge 命名空間中進行。
在 IoT Edge 命名空間中建立使用者
首先,您會建立將連線到 iotedge 命名空間的使用者。 IoT Edge 模組會部署在 iotedge 命名空間中。 如需詳細資訊,請參閱裝置上的 Kubernetes 命名空間。
請遵循下列步驟來建立使用者,並向使用者授與 iotedge 命名空間的存取權。
在
iotedge命名空間中建立新的使用者。 執行以下命令:New-HcsKubernetesUser -UserName <user name>以下為範例輸出:
[10.100.10.10]: PS>New-HcsKubernetesUser -UserName iotedgeuser apiVersion: v1 clusters: - cluster: certificate-authority-data: ===========================//snipped //======================// snipped //============================= server: https://compute.myasegpudev.wdshcsso.com:6443 name: kubernetes contexts: - context: cluster: kubernetes user: iotedgeuser name: iotedgeuser@kubernetes current-context: iotedgeuser@kubernetes kind: Config preferences: {} users: - name: iotedgeuser user: client-certificate-data: ===========================//snipped //======================// snipped //============================= client-key-data: ===========================//snipped //======================// snipped ============================ PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=複製以純文字顯示的輸出。 將輸出儲存為本機電腦上使用者設定檔的 資料夾中的
.kube檔 (沒有副檔名),例如C:\Users\<username>\.kube。向您建立的使用者授與
iotedge命名空間的存取權。 執行以下命令:Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName <user name>以下為範例輸出:
[10.100.10.10]: PS>Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName iotedgeuser [10.100.10.10]: PS>
如需詳細指示,請參閱在您的 Azure Stack Edge Pro GPU 裝置上透過 kubectl 連線至 Kubernetes 叢集並加以管理。
透過入口網站來部署模組
透過 Azure 入口網站部署 IoT Edge 模組。 您將部署執行 n 體模擬的公開可用的 NVIDIA CUDA 範例模組。
確定 IoT Edge 服務正在您的裝置上執行。

選取右窗格中的 [IoT Edge] 圖格。 移至 [IoT Edge] > [屬性]。 在右窗格中,選取與裝置相關聯的 IoT 中樞資源。
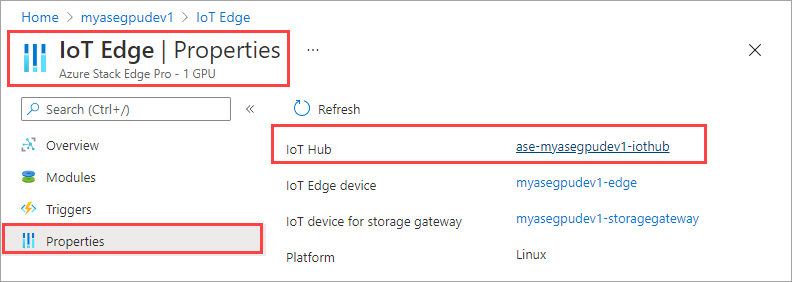
在 IoT 中樞資源中,移至 [自動裝置管理] > [IoT Edge]。 在右窗格中,選取與裝置相關聯的 IoT Edge 裝置。
![移至 [IoT Edge]。](media/azure-stack-edge-gpu-deploy-iot-edge-gpu-sharing/gpu-sharing-deploy-3.png)
選取 [設定模組]。
![移至 [設定模組]。](media/azure-stack-edge-gpu-deploy-iot-edge-gpu-sharing/gpu-sharing-deploy-4.png)
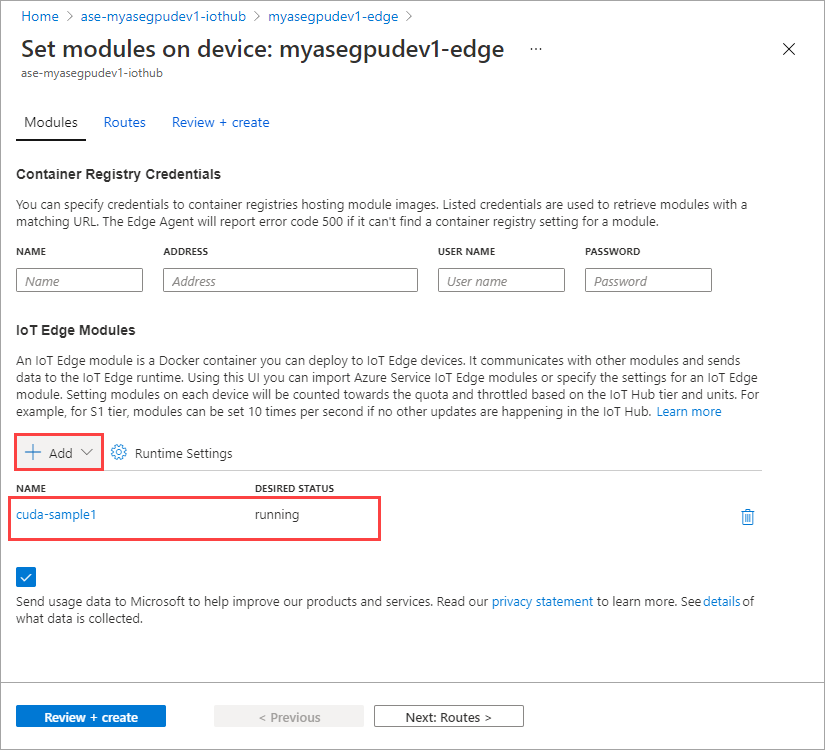
選取 [+ 新增] > [+ IoT Edge 模組]。
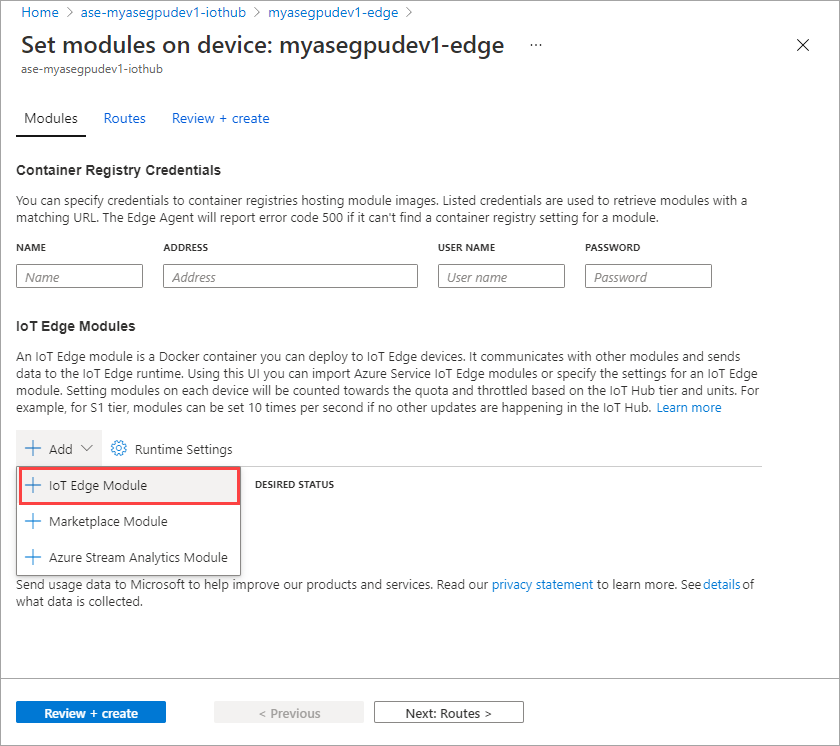
在 [模組設定] 索引標籤上,提供 [IoT Edge 模組名稱] 和 [映像 URI]。 將 [映像提取原則] 設定為 [建立時]。
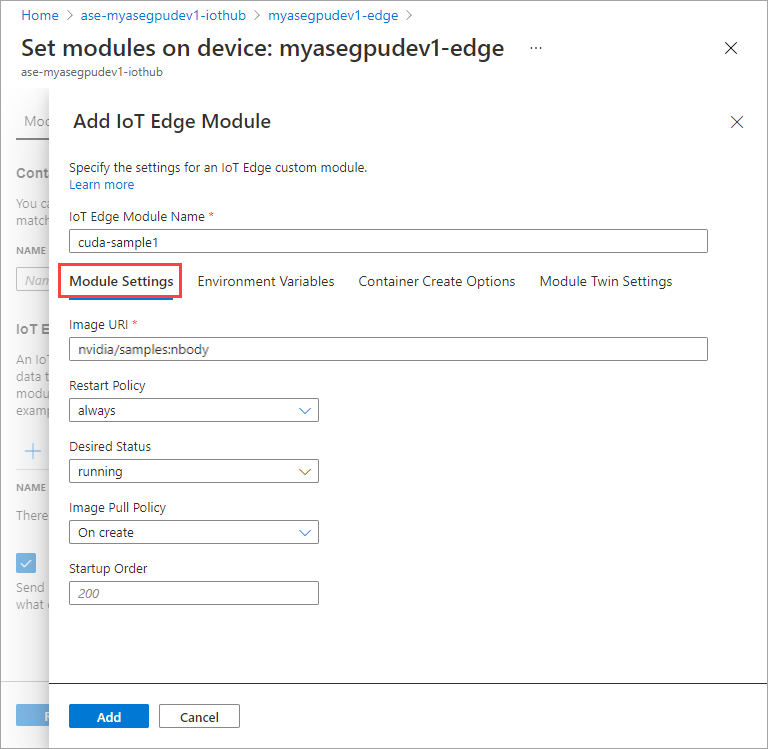
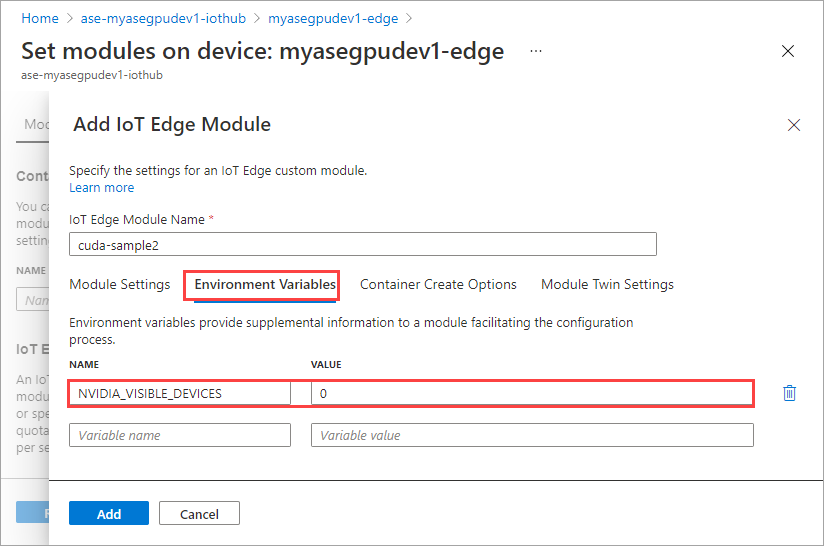
在 [環境變數] 索引標籤上,將 [NVIDIA_VISIBLE_DEVICES] 指定為 [0]。
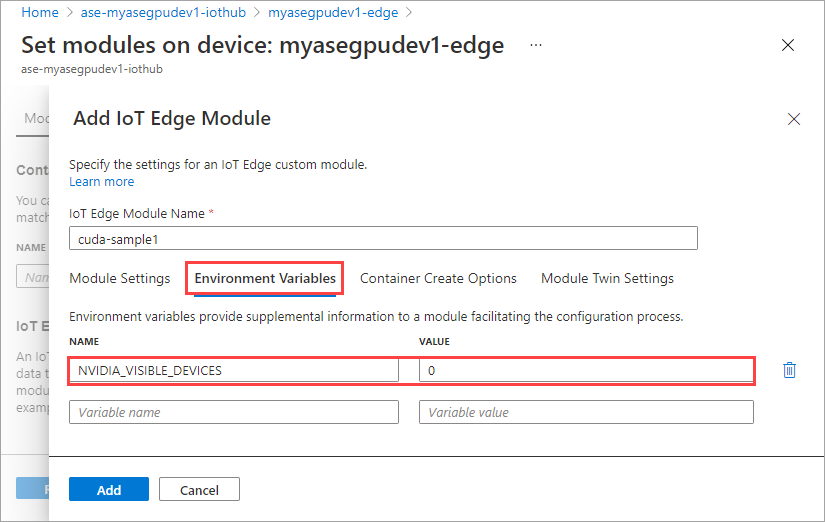
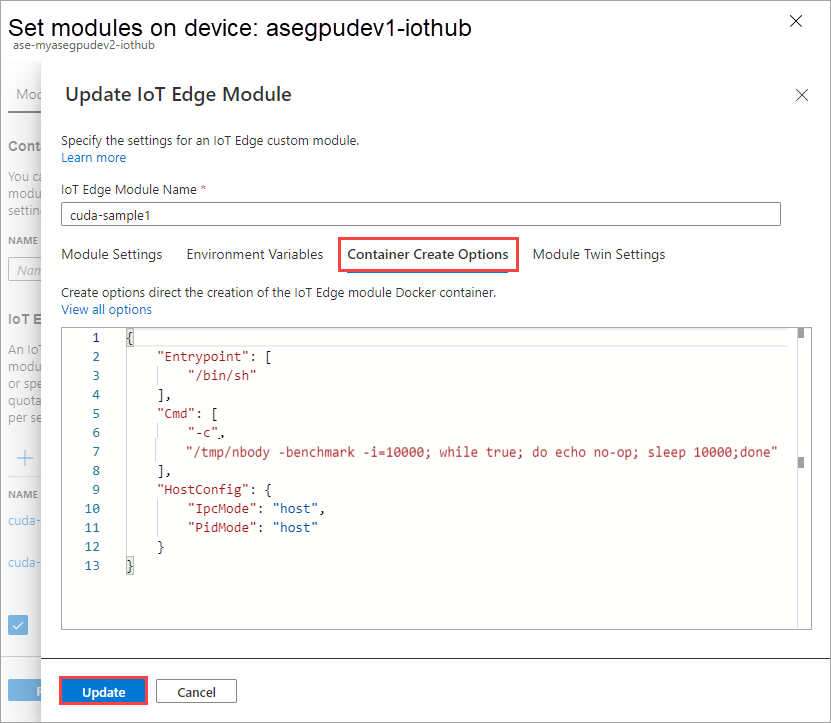
在 [容器建立選項] 索引標籤上,提供下列選項:
{ "Entrypoint": [ "/bin/sh" ], "Cmd": [ "-c", "/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done" ], "HostConfig": { "IpcMode": "host", "PidMode": "host" } }選項會顯示如下:
選取 [新增]。
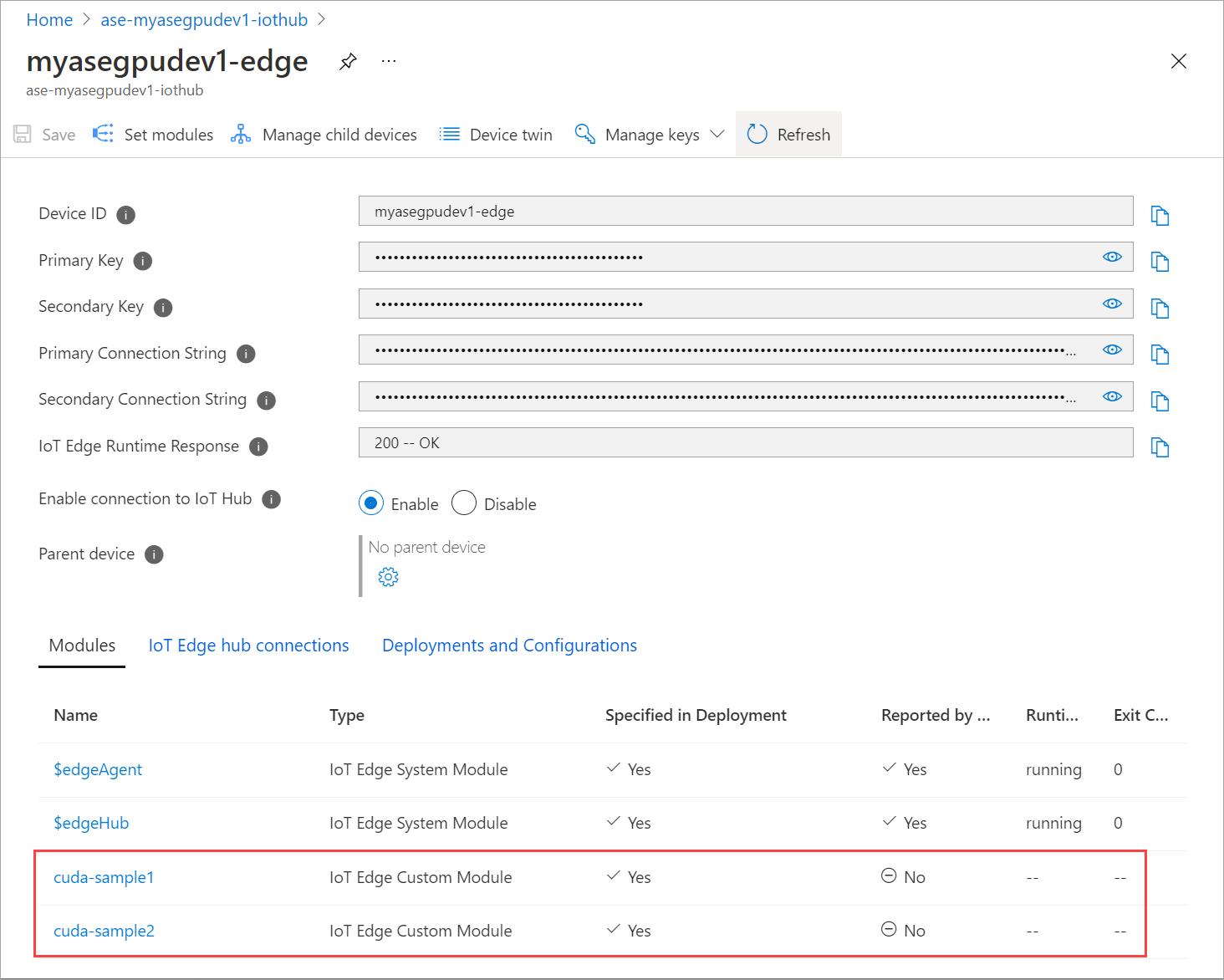
您新增的模組應該會顯示為 [執行中]。
重複所有步驟,以新增您在新增第一個模組時所遵循的模組。 在此範例中,請將模組的名稱提供為
cuda-sample2。
使用與這兩個模組相同的環境變數將會共用相同的 GPU。
使用您為第一個模組提供的相同容器建立選項,然後選取 [新增]。

在 [設定模組] 頁面上,選取 [檢閱 + 建立],然後選取 [建立]。
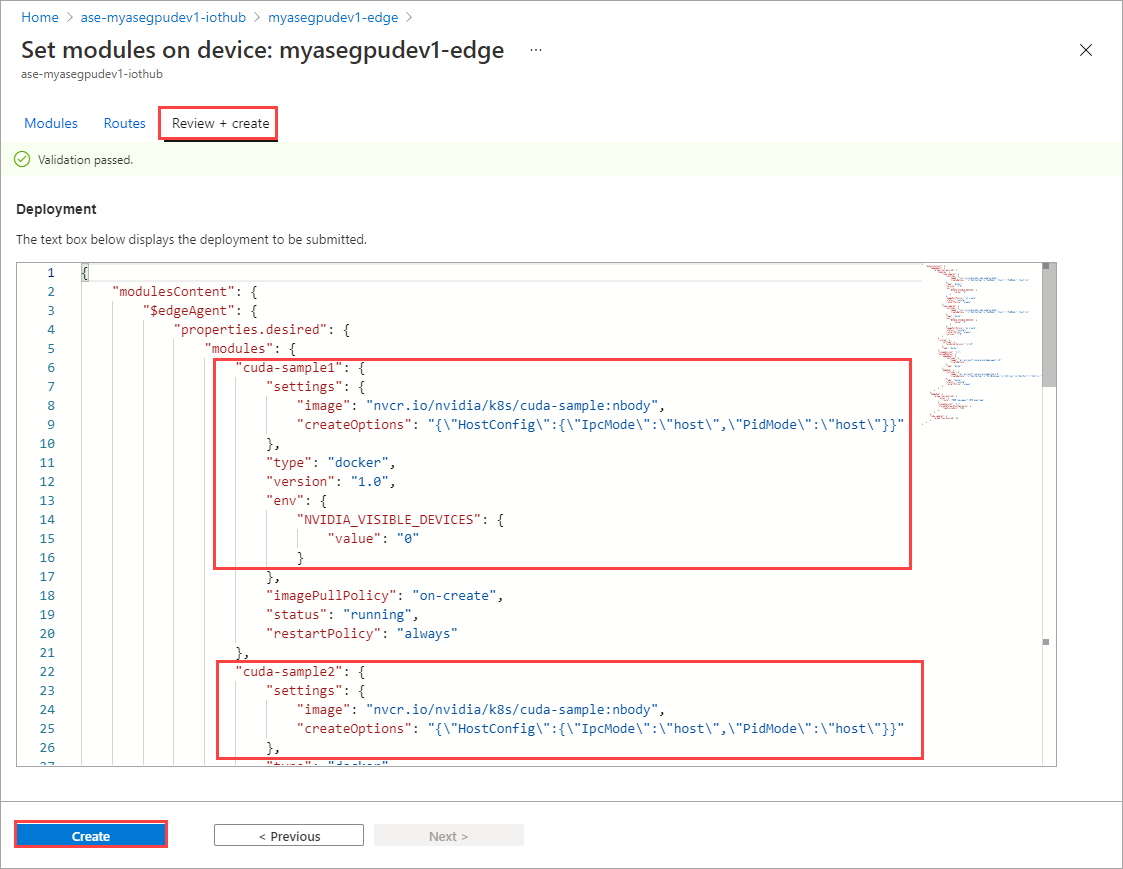
這兩個模組的 [執行階段狀態] 現在應該會顯示為 [執行中]。

監視工作負載部署
開啟新的 PowerShell 工作階段。
列出在
iotedge命名空間中執行的 Pod。 執行以下命令:kubectl get pods -n iotedge以下為範例輸出:
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-ssng8 2/2 Running 0 5s cuda-sample2-6db6d98689-d74kb 2/2 Running 0 4s edgeagent-79f988968b-7p2tv 2/2 Running 0 6d21h edgehub-d6c764847-l8v4m 2/2 Running 0 24h iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 6d21h PS C:\WINDOWS\system32>有兩個 Pod,
cuda-sample1-97c494d7f-lnmns與cuda-sample2-d9f6c4688-2rld9在您的裝置上執行。雖然這兩個容器都在執行 n 體模擬,但請檢視來自 NVIDIA smi 輸出的 GPU 使用率。 請移至裝置的 PowerShell 介面並執行
Get-HcsGpuNvidiaSmi。以下是兩個容器執行 n 體模擬時的範例輸出:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:31:16 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 52C P0 69W / 70W | 221MiB / 15109MiB | 100% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 188342 C /tmp/nbody 109MiB | | 0 N/A N/A 188413 C /tmp/nbody 109MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>如您所見,GPU 0 上的 n 主體模擬有兩個執行中的容器。 您也可以檢視其對應的記憶體使用量。
模擬完成後,NVIDIA smi 輸出會顯示裝置上沒有執行中的程序。
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:54:48 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>n 主體模擬完成後,請檢視記錄以了解部署的詳細資料,以及完成模擬所需的時間。
以下是第一個容器的範例輸出:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample1-869989578c-ssng8 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170171.531 ms = 98.590 billion interactions per second = 1971.801 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>以下是第二個容器的範例輸出:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-d74kb cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170054.969 ms = 98.658 billion interactions per second = 1973.152 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>停止模組部署。 在您裝置的 IoT 中樞資源內:
移至 [自動裝置部署] > [IoT Edge]。 選取與您裝置對應的 IoT Edge 裝置。
移至 [設定模組],然後選取模組。
![選取 [設定模組]。](media/azure-stack-edge-gpu-deploy-iot-edge-gpu-sharing/stop-module-deployment-1.png)
在 [模組] 索引標籤上,選取模組。

在 [模組設定] 索引標籤上,將 [需要的狀態] 設定為 [已停止]。 選取 [更新]。
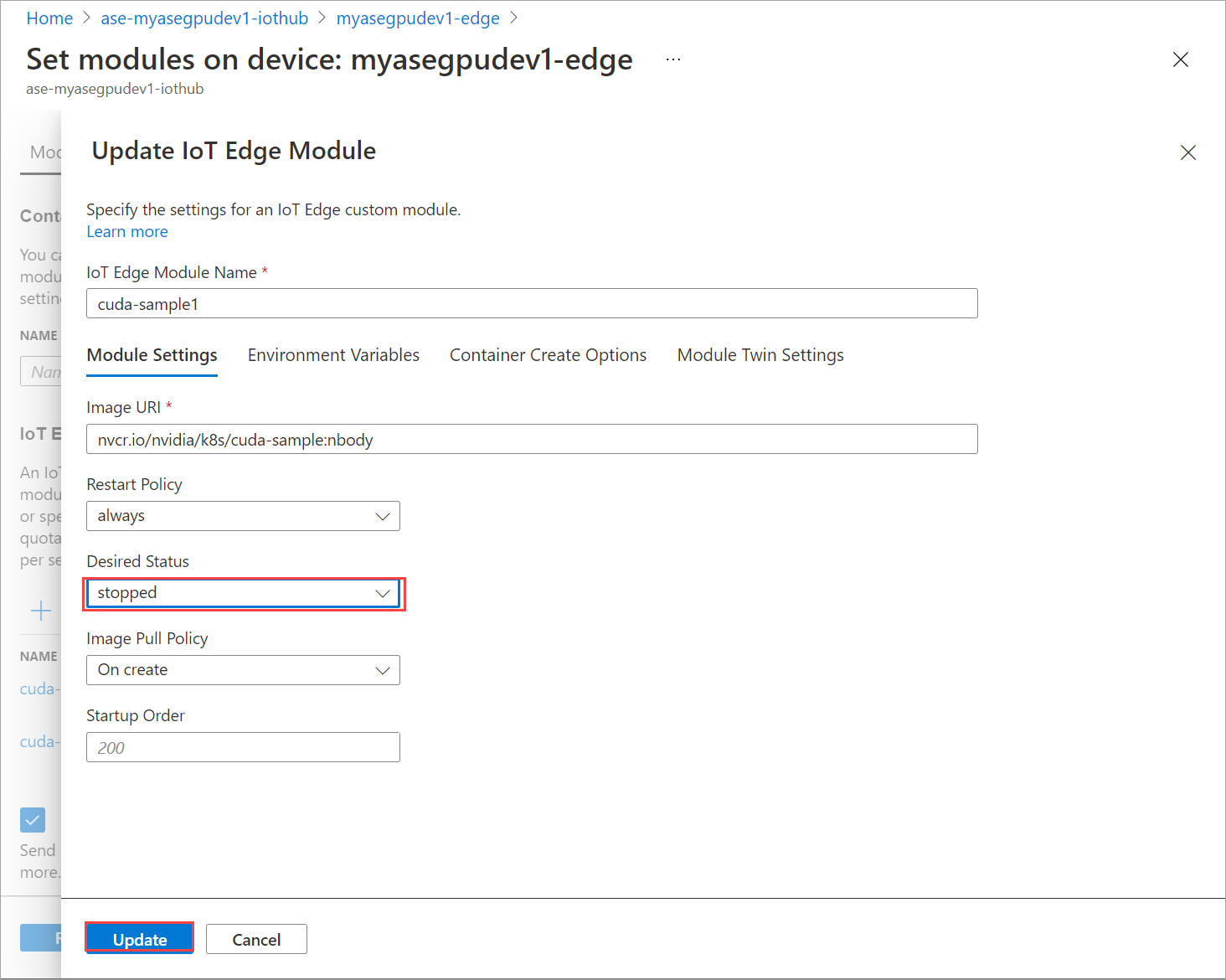
重複步驟以停止裝置上所部署的第二個模組。 選取 [檢閱 + 建立],然後選取 [建立]。 這應該會更新部署。

重新整理 [設定模組] 頁面多次。 直到模組的 [執行階段狀態] 顯示為 [已停止]。
進行有內容共用的部署
當您的裝置上執行 MPS 時,您現在可以在兩個 CUDA 容器上部署 n 主體模擬。 首先要在裝置上啟用 MPS。
若要在您的裝置上啟用 MPS,請執行
Start-HcsGpuMPS命令。[10.100.10.10]: PS>Start-HcsGpuMPS K8S-1HXQG13CL-1HXQG13: Set compute mode to EXCLUSIVE_PROCESS for GPU 0000191E:00:00.0. All done. Created nvidia-mps.service [10.100.10.10]: PS>從裝置的 PowerShell 介面取得 NVIDIA smi 輸出。 您可以看到
nvidia-cuda-mps-server程序或 MPS 服務正在裝置上執行。以下為範例輸出:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:37:39 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 36C P8 9W / 70W | 28MiB / 15109MiB | 0% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmi部署您稍早停止的模組。 透過 [設定模組] 將 [需要的狀態] 設定為 [執行中]。
以下是範例輸出:
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-2zxh6 2/2 Running 0 44s cuda-sample2-6db6d98689-fn7mx 2/2 Running 0 44s edgeagent-79f988968b-7p2tv 2/2 Running 0 5d20h edgehub-d6c764847-l8v4m 2/2 Running 0 27m iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 5d20h PS C:\WINDOWS\system32>您可以看到模組已部署到裝置上且正在執行。
部署模組時,n 主體模擬也會開始在兩個容器上執行。 以下是在第一個容器上完成模擬時的範例輸出:
PS C:\WINDOWS\system32> kubectl -n iotedge logs cuda-sample1-869989578c-2zxh6 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155256.062 ms = 108.062 billion interactions per second = 2161.232 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>以下是在第二個容器上完成模擬時的範例輸出:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-fn7mx cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155366.359 ms = 107.985 billion interactions per second = 2159.697 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>當兩個容器都執行 n 主體模擬時,從裝置的 PowerShell 介面取得 NVIDIA smi 輸出。 以下是輸出範例。 有三個程序,
nvidia-cuda-mps-server程序 (類型 C) 對應至 MPS 服務,/tmp/nbody程序 (類型 M + C) 對應至模組所部署的 n 主體工作負載。[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:59:44 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 54C P0 69W / 70W | 242MiB / 15109MiB | 100% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 56832 M+C /tmp/nbody 107MiB | | 0 N/A N/A 56900 M+C /tmp/nbody 107MiB | | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmi