重要
這些指示適用於舊版資料存取模式。 Databricks 建議使用 Unity 目錄外部位置進行數據存取。 請參閱 使用 Unity Catalog 連接到雲端物件存儲。
本文說明如何管理工作區中 SQL 倉儲的資料存取屬性。
重要
變更這些設定會重新啟動所有執行中的 SQL 倉儲。
設定服務主體
要使用服務主體設定 SQL 資料倉庫對 Azure Data Lake Storage 儲存體帳戶的存取權限,請依照以下步驟操作:
註冊一個Microsoft Entra ID(前稱Azure Active Directory)應用程式並記錄以下屬性:
- Application(用戶端)ID:唯一識別Microsoft Entra ID應用程式的ID。
- Directory(租戶)ID:用於唯一識別 Microsoft Entra ID 實例的 ID,在 Azure Databricks 中被稱為目錄(租戶)ID。
- 用戶端密碼:針對此應用程式註冊建立的客戶端密碼值。 應用程式會使用此秘密字串來證明其身分識別。
在您的記憶體帳戶上,為在上一個步驟註冊的應用程式新增角色指派,以授與記憶體帳戶的存取權。
建立一個由 Azure Key Vault 支援或 Databricks 作用域的秘密範圍,詳見管理秘密範圍,並記錄作用域名稱屬性的值:
- 範圍名稱:所建立秘密範圍的名稱。
若使用 Azure Key Vault,請在 Azure Key Vault 建立秘密,使用 Value 欄位的 Client secret。 保留您選擇的秘密名稱記錄。
- 機密名稱:所建立的 Azure Key Vault 機密的名稱。
如果使用 Databricks 支援的範圍, 請使用 Databricks CLI 建立新的秘密 ,並用它來儲存您在步驟 1 中取得的客戶端密碼。 記下您在此步驟中輸入的秘密金鑰記錄。
- 密鑰:使用 Databricks 支援建立的密鑰。
注意
您可以選擇性地建立額外的秘密,以儲存在步驟 1 取得的用戶端識別碼。
點擊工作區頂端列中的使用者名稱,然後從下拉式清單中選取 [設定]。
點擊 計算 標籤。
點擊管理旁的SQL 倉儲。
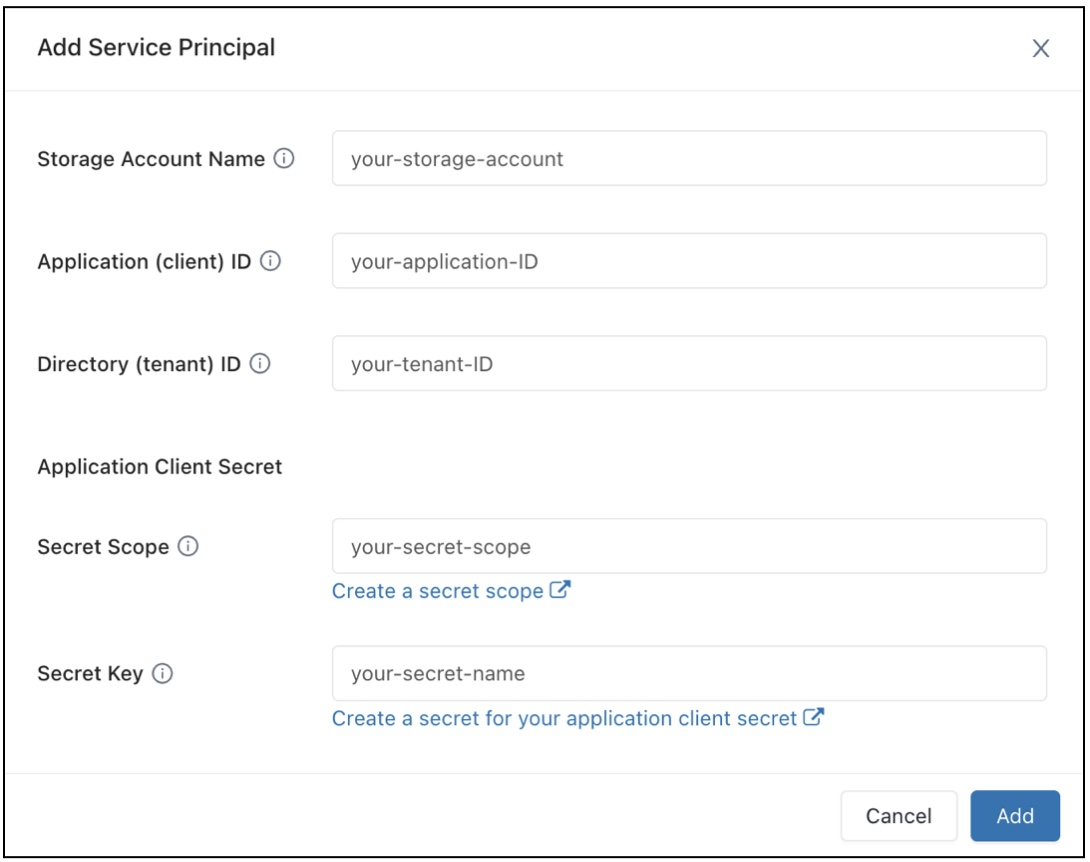
在 [數據存取組態] 字段中,按兩下 [ 新增服務主體 ] 按鈕。
請設定你的Azure Data Lake Storage儲存帳號的屬性。
按一下新增。
您會看到新的項目已新增至 [資料存取組態] 文字框中。
按一下 儲存。
您也可以直接編輯 [資料存取設定] 的文字方塊條目。
設定 SQL 倉儲的數據存取屬性
若要設定具有數據存取屬性的所有倉儲:
點擊工作區頂端列中的使用者名稱,然後從下拉式清單中選取 [設定]。
點擊 計算 標籤。
點擊管理旁的SQL 倉儲。
在 [ 資料存取組態 ] 文本框中,指定包含 中繼存放區屬性的機碼/值組。
重要
若要將 Spark 組態屬性設定為秘密的值,而不將秘密值公開至 Spark,請將值設定為
{{secrets/<secret-scope>/<secret-name>}}。 將<secret-scope>替換為秘密範圍,並將<secret-name>替換為秘密名稱。 值必須以{{secrets/開頭,並以}}結尾。 如需此語法的詳細資訊,請參閱 管理秘密。按一下 儲存。
您也可以使用 Databricks Terraform 提供者 和 databricks_sql_global_config來設定數據存取屬性。
支援的屬性
對於結尾
*為 的項目,支援該前置詞內的所有屬性。例如,
spark.sql.hive.metastore.*表示spark.sql.hive.metastore.jars和spark.sql.hive.metastore.version都受到支援,以及任何以spark.sql.hive.metastore開頭的其他屬性。對於值包含敏感性資訊的屬性,您可以將敏感性資訊儲存在 秘密 中,並使用下列語法將屬性的值設定為秘密名稱:
secrets/<secret-scope>/<secret-name>。
SQL 倉儲支援下列屬性:
spark.sql.hive.metastore.*spark.sql.warehouse.dirspark.hadoop.datanucleus.*spark.hadoop.fs.*spark.hadoop.hive.*spark.hadoop.javax.jdo.option.*spark.hive.*
如需如何設定這些屬性的詳細資訊,請參閱 外部 Hive 中繼存放區。