Azure Databricks 提供的舊版 MLflow 模型服務
重要
這項功能處於公開預覽狀態。
重要
- 此檔已淘汰,且可能未更新。 不再支援此內容中所提及的產品、服務或技術。
- 本文中的指引適用於舊版 MLflow 模型服務。 Databricks 建議您將模型服務工作流程移轉至模型服務,以取得增強的模型端點部署和延展性。 如需詳細資訊,請參閱 使用 Azure Databricks 的模型服務。
舊版 MLflow 模型服務可讓您將模型登錄中的機器學習模型裝載為 REST 端點,這些端點會根據模型版本及其階段的可用性自動更新。 它會使用單一節點叢集,其會在您自己帳戶下執行,其現在稱為傳統計算平面。 此計算平面包含虛擬網路及其相關聯的計算資源,例如筆記本和作業的叢集、專業和傳統 SQL 倉儲,以及舊版模型服務端點。
當您為指定的已註冊模型啟用模型服務時,Azure Databricks 會自動為模型建立唯一的叢集,並在該叢集上部署所有未封存版本的模型。 如果您停用模型的模型服務,Azure Databricks 會在發生錯誤並終止叢集時重新啟動叢集。 模型服務會自動與模型登錄同步,並部署任何新的已註冊模型版本。 您可以使用標準 REST API 要求來查詢已部署的模型版本。 Azure Databricks 會使用其標準驗證來驗證模型的要求。
雖然此服務處於預覽狀態,但 Databricks 建議其用於低輸送量和非關鍵應用程式。 目標輸送量為 200 qps,目標可用性為 99.5%,但無法保證任一項。 此外,每個要求都有 16 MB 的承載大小限制。
每個模型版本都是使用 MLflow 模型部署來部署 ,並在其相依性所指定的 Conda 環境中執行。
注意
- 只要啟用服務,叢集就會維護,即使沒有任何作用中的模型版本存在也一樣。 若要終止服務叢集,請停用已註冊模型的模型服務。
- 叢集被視為一個全用途叢集,受限於所有用途的工作負載定價。
- 全域 init 腳本 不會在提供叢集的模型上執行。
重要
Anaconda Inc. 更新了其 anaconda.org 頻道服務條款 。 根據新的服務條款,如果您依賴 Anaconda 的封裝和散發,您可能需要商業授權。 如需詳細資訊,請參閱 Anaconda Commercial Edition 常見問題 。 您使用任何 Anaconda 通道會受到其服務條款的規範。
在 v1.18 之前記錄的 MLflow 模型(Databricks Runtime 8.3 ML 或更早版本)預設會以 conda defaults 通道 (https://repo.anaconda.com/pkgs/) 記錄為相依性。 由於此授權變更,Databricks 已停止針對使用 MLflow v1.18 和更新版本記錄的模型使用 defaults 通道。 記錄的預設通道現在是 conda-forge,指向社群管理的 https://conda-forge.org/。
如果您在 MLflow v1.18 之前記錄模型,但未從模型的 conda 環境排除 defaults 通道,該模型可能相依 defaults 於您可能未預期的通道。
若要手動確認模型是否具有此相依性,您可以檢查 channel 以記錄模型封裝的 conda.yaml 檔案中的值。 例如,具有defaults通道相依性之conda.yaml模型的 可能如下所示:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
由於 Databricks 無法判斷您在與 Anaconda 的關係下是否允許使用 Anaconda 存放庫與模型互動,因此 Databricks 不會強制其客戶進行任何變更。 如果您在 Anaconda 條款下允許使用 Anaconda.com 存放庫,您就不需要採取任何動作。
如果您想要變更模型環境中所使用的通道,您可以使用新的 conda.yaml將模型重新登錄至模型登錄。 您可以藉由在 的 log_model()參數中conda_env指定通道來執行此動作。
如需 API 的詳細資訊 log_model() ,請參閱您正在使用之模型類別的 MLflow 檔, 例如 scikit-learn log_model。
如需檔案的詳細資訊 conda.yaml ,請參閱 MLflow 檔。
需求
從模型登錄提供模型
模型服務可從模型登錄取得 Azure Databricks。
啟用和停用模型服務
您可以啟用模型,以便從其 已註冊的模型頁面提供服務。
按兩下 [ 服務] 索引標籤。如果模型尚未啟用服務,則會出現 [ 啟用服務] 按鈕。
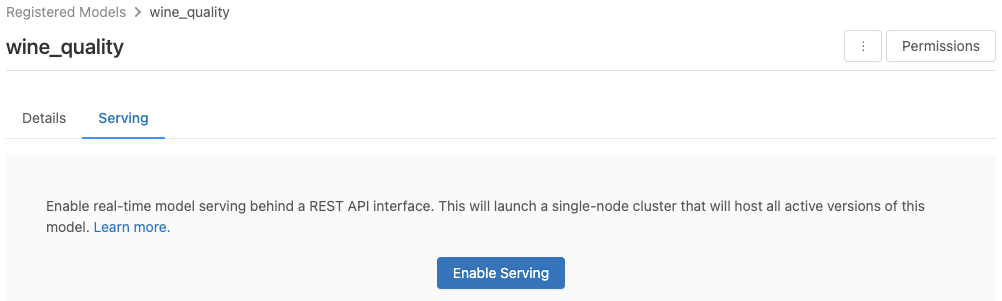
按兩下 [ 啟用服務]。 [服務] 索引標籤隨即出現, [狀態 ] 顯示為 [擱置]。 幾分鐘后, 狀態 會變更為 [就緒]。
若要停用服務模型,請按兩下 [ 停止]。
驗證模型服務
您可以從 [ 服務] 索引標籤,將要求傳送至服務模型並檢視回應。
模型版本 URI
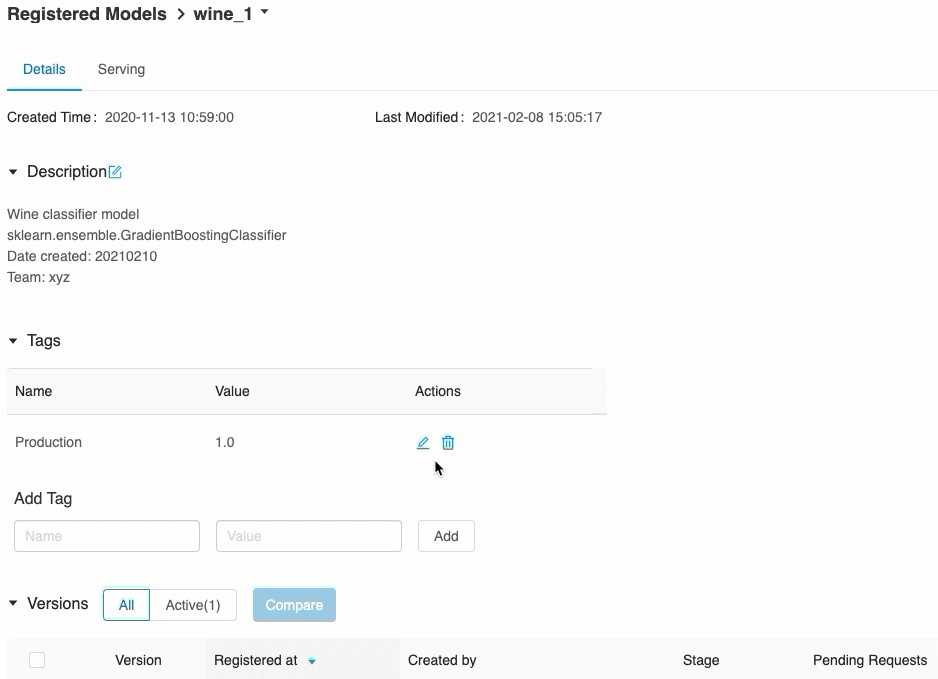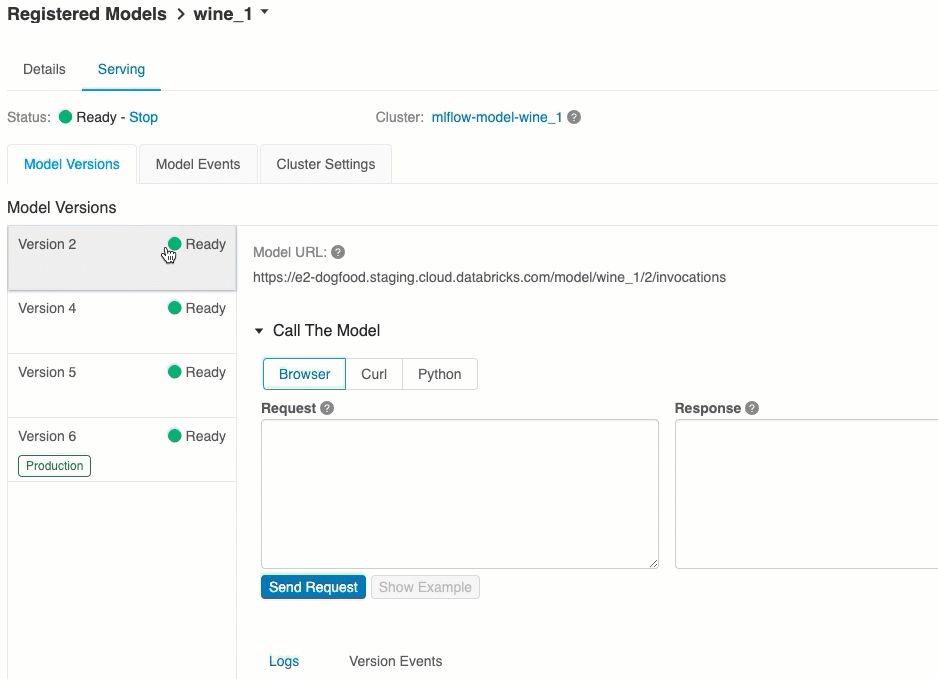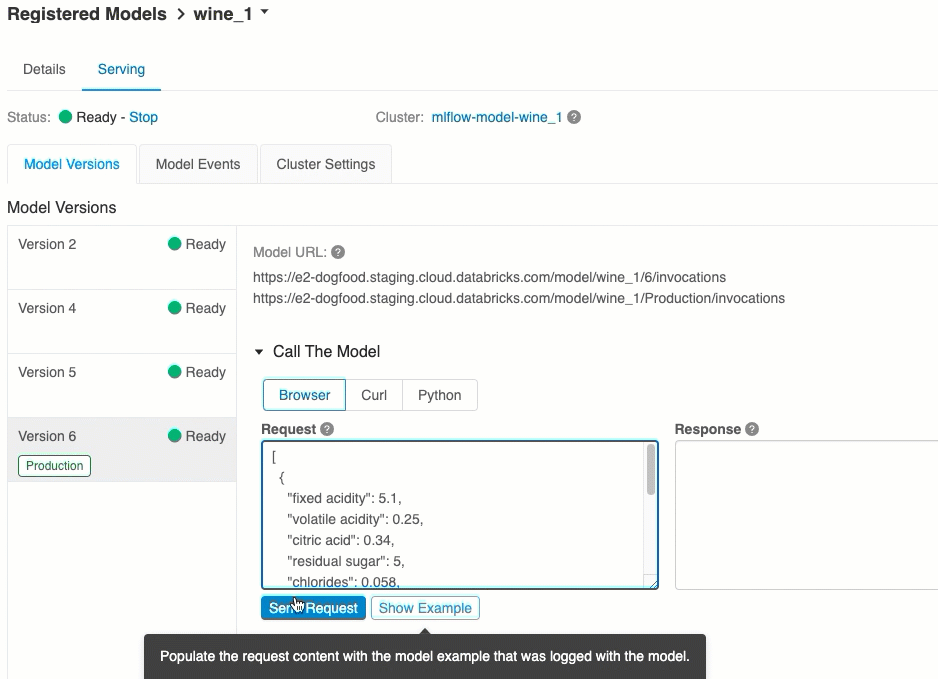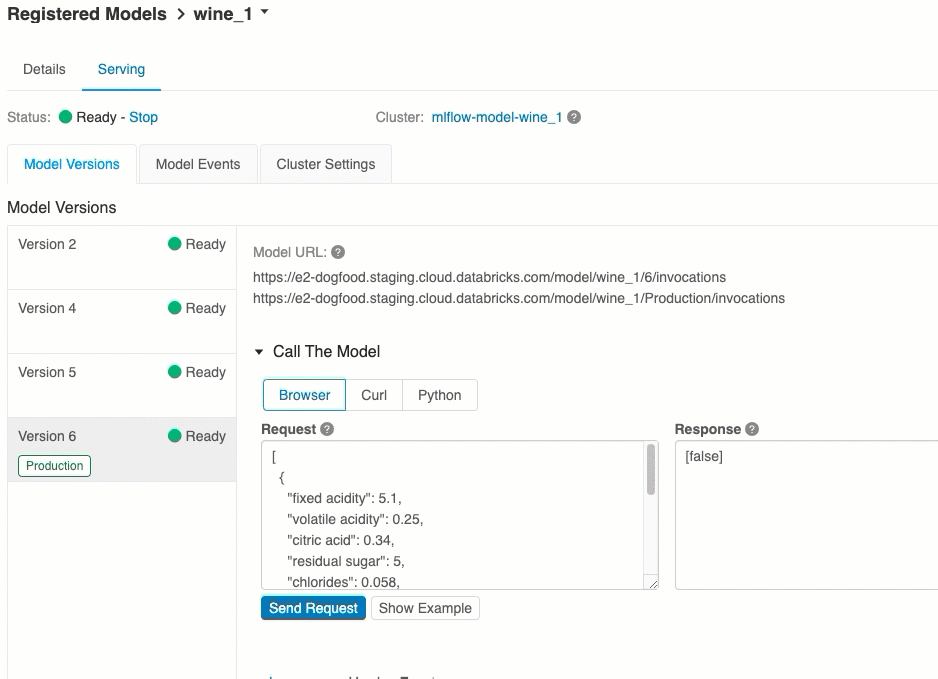
每個已部署的模型版本都會指派一或多個唯一 URI。 每個模型版本至少都會指派一個 URI,如下所示:
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
例如,若要呼叫註冊為 iris-classifier的模型第 1 版,請使用下列 URI:
https://<databricks-instance>/model/iris-classifier/1/invocations
您也可以依其階段呼叫模型版本。 例如,如果第 1 版是在 生產 階段,也可以使用此 URI 來評分:
https://<databricks-instance>/model/iris-classifier/Production/invocations
可用的模型 URI 清單會出現在服務頁面的 [模型版本] 索引標籤頂端。
管理服務的版本
所有作用中 (非封存) 模型版本都會部署,而且您可以使用 URI 進行查詢。 Azure Databricks 會在註冊時自動部署新的模型版本,並在封存時自動移除舊版本。
注意
所有已部署的模型版本都會共用相同的叢集。
管理模型訪問許可權
模型訪問許可權繼承自模型登錄。 啟用或停用服務功能需要已註冊模型的「管理」許可權。 具有讀取許可權的任何人都可以為任何已部署的版本評分。
評分已部署的模型版本
若要為已部署的模型評分,您可以使用 UI 或將 REST API 要求傳送至模型 URI。
透過UI評分
這是測試模型的最簡單且最快的方式。 您可以插入 JSON 格式的模型輸入數據,然後按兩下 [ 傳送要求]。 如果模型已記錄輸入範例(如上圖所示),請按兩下 [載入範例 ] 以載入輸入範例。
透過 REST API 要求評分
您可以使用標準 Databricks 驗證,透過 REST API 傳送評分要求。 下列範例示範搭配 MLflow 1.x 使用個人存取令牌進行驗證。
注意
作為安全性最佳做法,當您使用自動化工具、系統、腳本和應用程式進行驗證時,Databricks 建議您使用屬於 服務主體 的個人存取令牌,而不是工作區使用者。 若要建立服務主體的令牌,請參閱 管理服務主體的令牌。
假設有 MODEL_VERSION_URI 類似 https://<databricks-instance>/model/iris-classifier/Production/invocations (其中 <databricks-instance> 是 Databricks 實例的名稱)和名為 DATABRICKS_API_TOKEN的 Databricks REST API 令牌,下列範例示範如何查詢服務模型:
下列範例會反映使用 MLflow 1.x 建立之模型的評分格式。 如果您想要使用 MLflow 2.0,您需要 更新要求承載格式。
Bash
用來查詢接受數據框架輸入之模型的代碼段。
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
查詢接受張量輸入之模型的代碼段。 Tensor 輸入的格式應該如 TensorFlow 服務 API 檔中所述。
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
Python
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
Powerbi
您可以使用下列步驟在 Power BI Desktop 中為資料集評分:
開啟您想要評分的數據集。
移至 [轉換數據]。
以滑鼠右鍵按兩下左面板中,然後選取 [ 建立新查詢]。
移至 [檢視 > 進階編輯器]。
在填入適當的
DATABRICKS_API_TOKEN和MODEL_VERSION_URI之後,以下列代碼段取代查詢主體。(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPrediction使用您想要的模型名稱來命名查詢。
開啟數據集的進階查詢編輯器,並套用模型函式。
監視服務模型
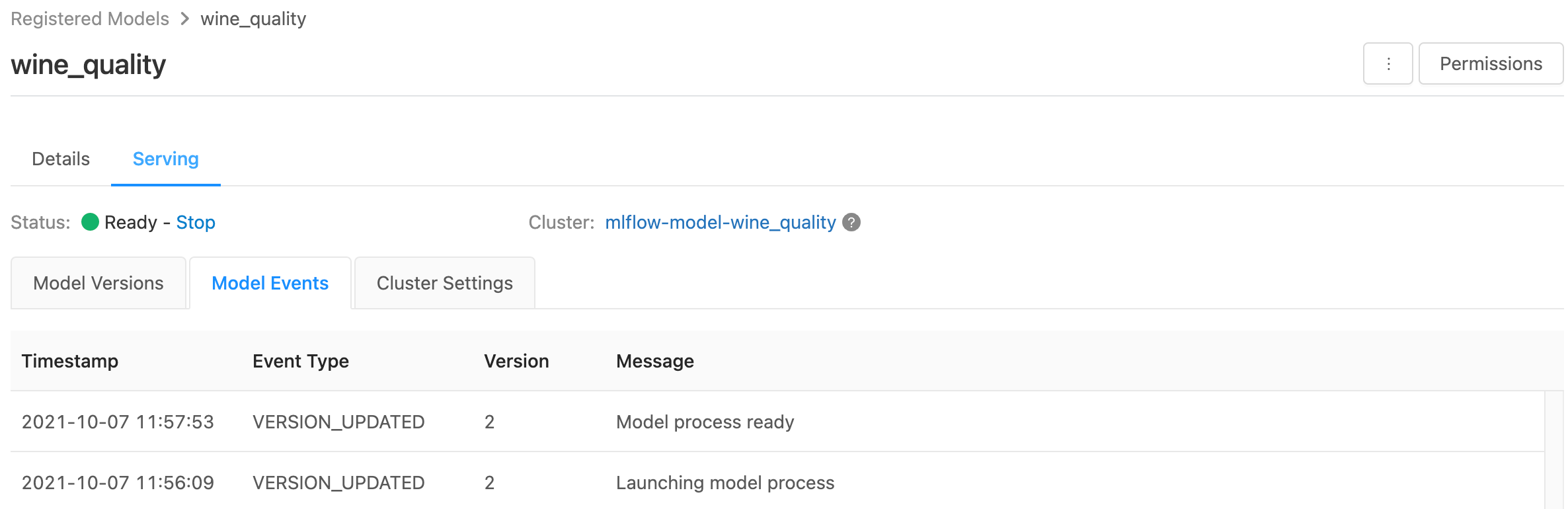
[服務] 頁面會顯示服務叢集和個別模型版本的狀態指標。
- 若要檢查服務叢集的狀態,請使用 [ 模型事件 ] 索引標籤,此索引標籤會顯示此模型所有服務事件的清單。
- 若要檢查單一模型版本的狀態,請按兩下 [ 模型版本 ] 索引標籤並捲動以檢視 [ 記錄 ] 或 [版本事件 ] 索引標籤。
自訂服務叢集
若要自定義服務叢集,請使用 [服務] 索引標籤上的 [叢集 設定] 索引標籤。
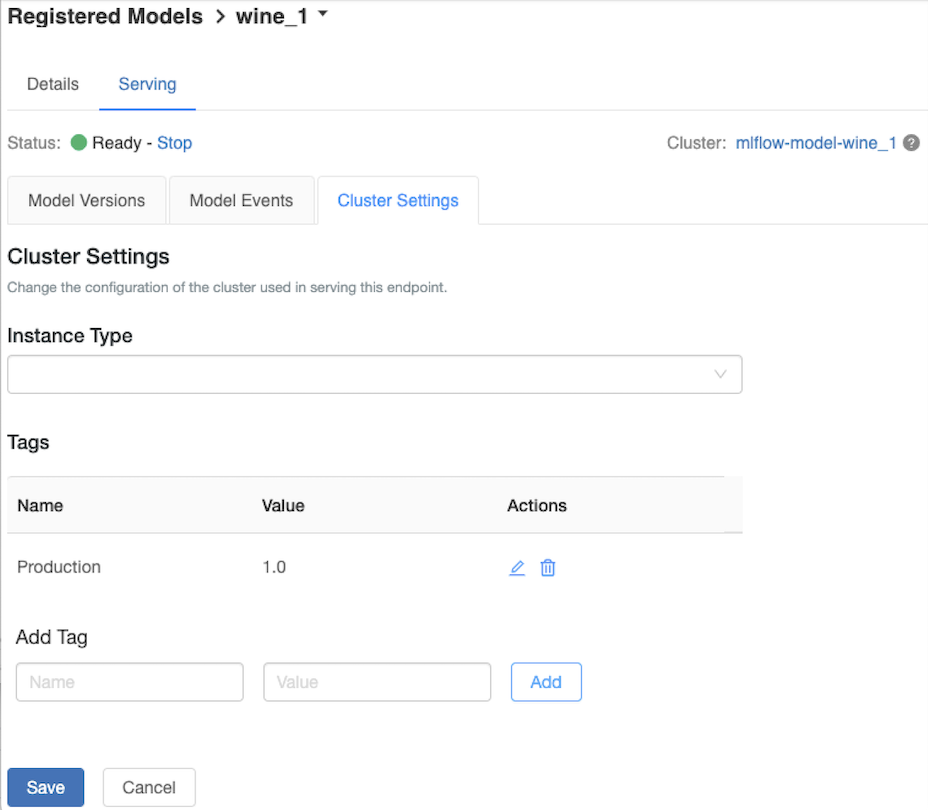
- 若要修改服務叢集的記憶體大小和核心數目,請使用 [實例類型 ] 下拉功能表來選取所需的叢集組態。 當您按兩下 [ 儲存] 時,會終止現有的叢集,並使用指定的設定建立新的叢集。
- 若要新增標籤,請在 [新增卷標] 字段中輸入名稱和值,然後按兩下 [新增]。
- 若要編輯或刪除現有的標記,請按兩下Tags資料表 [動作] 資料列中的其中一個圖示。
功能存放區整合
舊版模型服務可以自動查閱 已發佈在線商店的功能值。
.. Aws:
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Amazon DynamoDB (v0.3.8 and above)
- Amazon Aurora (MySQL-compatible)
- Amazon RDS MySQL
.. azure::
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Azure Cosmos DB (v0.5.0 and above)
- Azure Database for MySQL
已知錯誤
ResolvePackageNotFound: pyspark=3.1.0
如果模型相依於 pyspark 且使用 Databricks Runtime 8.x 來記錄,就可能發生此錯誤。
如果您看到此錯誤,請使用 conda_env 參數,在記錄模型時明確指定pyspark版本。
Unrecognized content type parameters: format
由於新的 MLflow 2.0 計分通訊協定格式,可能會發生此錯誤。 如果您看到此錯誤,您可能會使用過期的評分要求格式。 若要解決錯誤,您可以:
將評分要求格式更新為最新的通訊協定。
注意
下列範例會反映 MLflow 2.0 中引進的評分格式。 如果您想要使用 MLflow 1.x,您可以修改 API
log_model()呼叫,以在 參數中包含extra_pip_requirements所需的 MLflow 版本相依性。 這麼做可確保使用適當的評分格式。mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])Bash
查詢接受 pandas 數據框架輸入的模型。
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{ "dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2}, {"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}] }'查詢接受張量輸入的模型。 Tensor 輸入的格式應該如 TensorFlow 服務 API 檔中所述。
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'Python
import numpy as np import pandas as pd import requests def create_tf_serving_json(data): return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()} def score_model(model_uri, databricks_token, data): headers = { "Authorization": f"Bearer {databricks_token}", "Content-Type": "application/json", } data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data) data_json = json.dumps(data_dict) response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json) if response.status_code != 200: raise Exception(f"Request failed with status {response.status_code}, {response.text}") return response.json() # Scoring a model that accepts pandas DataFrames data = pd.DataFrame([{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data) # Scoring a model that accepts tensors data = np.asarray([[5.1, 3.5, 1.4, 0.2]]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)Powerbi
您可以使用下列步驟在 Power BI Desktop 中為資料集評分:
開啟您想要評分的數據集。
移至 [轉換數據]。
以滑鼠右鍵按兩下左面板中,然後選取 [ 建立新查詢]。
移至 [檢視 > 進階編輯器]。
在填入適當的
DATABRICKS_API_TOKEN和MODEL_VERSION_URI之後,以下列代碼段取代查詢主體。(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPrediction使用您想要的模型名稱來命名查詢。
開啟數據集的進階查詢編輯器,並套用模型函式。
如果您的評分要求使用 MLflow 用戶端,例如
mlflow.pyfunc.spark_udf(),請將 MLflow 用戶端升級至 2.0 版或更新版本,以使用最新的格式。 深入瞭解 MLflow 2.0 中更新的 MLflow 模型評分通訊協定。
如需伺服器所接受之輸入數據格式的詳細資訊(例如 pandas 分割導向格式),請參閱 MLflow 檔。
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應