重要
此文件已淘汰,且可能不再更新。 不再支援此內容中所提及的產品、服務或技術。 請參閱 日期時間模式。
Databricks Runtime 7.0 中的 Date 和 Timestamp 數據類型大幅變更。 本文說明:
-
Date類型和其相關的行事曆。 -
Timestamp型別及其與時區的關聯性。 它也說明 Databricks Runtime 7.0 所使用之 Java 8 中新時間 API 中時區位移解析的詳細數據,以及細微的行為變更。 - 用來建構日期和時間值的 API。
- 收集 Apache Spark 驅動程式上日期和時間對象的常見陷阱和最佳做法。
日期和行事曆
Date 是年份、月和日字段的組合,例如 (year=2012、month=12、day=31)。 不過,年、月和日字段的值有條件約束,以確保日期值在真實世界中是有效的日期。 例如,月份的值必須是從 1 到 12,日的值必須是從 1 到 28,29,30 或 31(視年份和月份而定),依此而定。
Date 類型不會考慮時區。
日曆
Date 欄位的約束由多種可能的日曆之一所定義。 有些,例如 農曆,只會在特定區域中使用。 有些,例如 朱利安歷,只會在歷史上使用。 事實上的國際標準是公曆 ,幾乎在世界各地用於民事用途。 它於1582年推出,並延長支援範圍至1582年之前的日期。 這個延長行事曆稱為 Proleptic 公曆。
Databricks Runtime 7.0 使用 Proleptic 公曆,此行事歷已由 Pandas、R 和 Apache Arrow 等其他數據系統使用。 Databricks Runtime 6.x 及以下使用朱利安和公曆的組合:針對 1582 之前的日期,使用朱利安日曆,用於使用公曆 1582 后的日期。 這是繼承自舊版 java.sql.Date API,此 API 在 Java 8 中由 java.time.LocalDate取代,其使用 Proleptic 公曆。
時間戳和時區
Timestamp 類型會擴充 Date 類型,加入新的欄位:小時、分鐘、秒(可以有小數部分),以及全域時間帶(會話範圍設定)。 它定義了一個具體的時間點。 例如,(year=2012、month=12、day=31、hour=23、minute=59、second=59.123456)與會話時區 UTC+01:00。 將時間戳值寫入像 Parquet 這樣的非文字數據來源時,這些值只作為沒有時區資訊的時間點(例如以 UTC 表示的時間戳)。 如果您在不同的會話時區寫入並讀取時間戳值,您可能會看到小時、分鐘和秒欄位的值不同,但它們是相同的具體時間時刻。
小時、分和秒欄位有標準範圍:0–23 表示小時,0-59 代表分鐘和秒。 Spark 支援秒數的小數部分,精確度可達微秒。 分數的有效範圍是從 0 到 999,999 微秒。
在任何具體瞬間,視時區而定,您可以觀察許多不同的時鐘值:
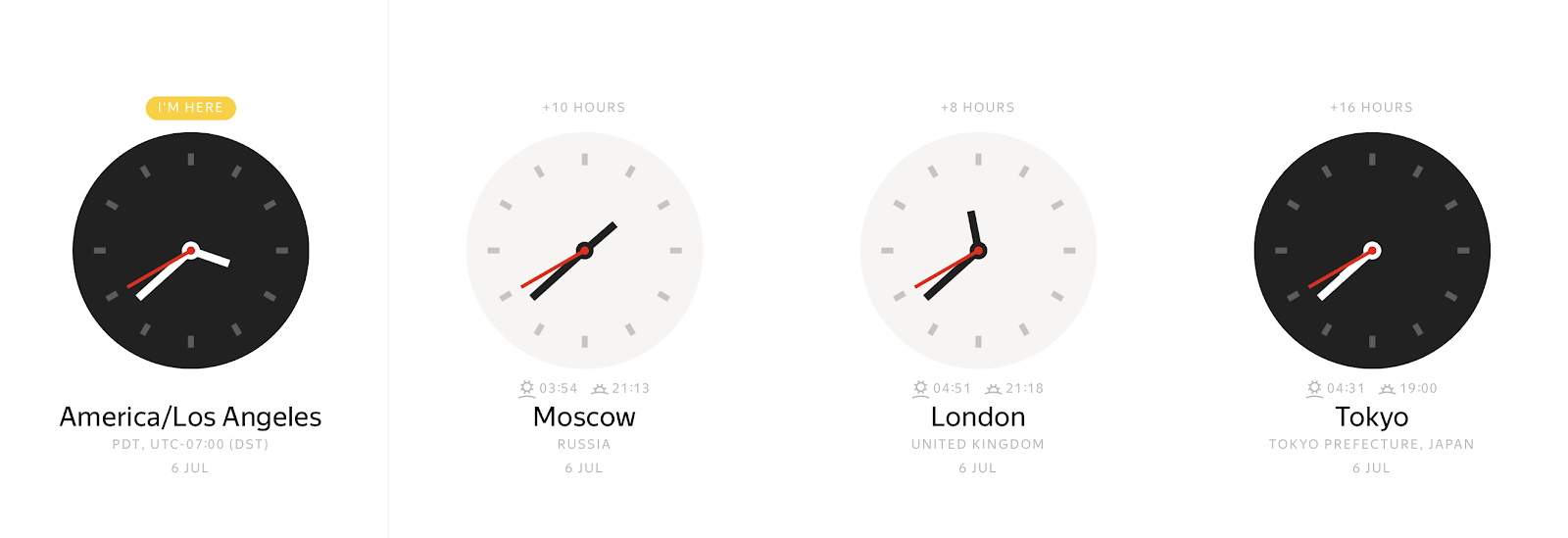
相反地,掛鐘時間值可以代表許多不同的時刻。
時區偏移 可讓您明確地將本機時間戳系結至瞬間時間。 通常,時區位移定義為格林威治標準時間(GMT)或 UTC+0 的時差(國際標準時間)。 時區資訊的這種表示法會消除模棱兩可,但並不方便。 大多數人偏好指出位置,例如 America/Los_Angeles 或 Europe/Paris。 這個來自區域位移的額外抽象層次讓生活更加便利,但也帶來了複雜性。 例如,您現在必須維護特殊時區資料庫,才能將時區名稱對應至位移。 由於 Spark 在 JVM 上執行,因此會將對應委派給 Java 標準連結庫,該連結庫會從 Internet Assigned Numbers Authority Time Zone Database (IANA TZDB) 載入數據。 此外,Java 標準庫中的映射機制有一些細微差別,會影響 Spark 的行為。
自從 Java 8,JDK 公開了一個不同的 API 用於日期與時間的處理以及時區偏移的解析,Databricks Runtime 7.0 使用這個 API。 雖然時區名稱與位移的對應具有相同的來源 IANA TZDB,但在 Java 8 和更新版本與 Java 7 中實作的方式不同。
例如,請檢視 America/Los_Angeles 時區中 1883 年之前的時間戳:1883-11-10 00:00:00。 今年從其他人中脫穎而出,因為1883年11月18日,所有北美鐵路都改用了新的標準時間系統。 使用 Java 7 時間 API,您可以在本地時間戳記下獲取時區位移:-08:00
java.time.ZoneId.systemDefault
res0:java.time.ZoneId = America/Los_Angeles
java.sql.Timestamp.valueOf("1883-11-10 00:00:00").getTimezoneOffset / 60.0
res1: Double = 8.0
對等的 Java 8 API 會傳回不同的結果:
java.time.ZoneId.of("America/Los_Angeles").getRules.getOffset(java.time.LocalDateTime.parse("1883-11-10T00:00:00"))
res2: java.time.ZoneOffset = -07:52:58
1883年11月18日之前,北美的一天時間是當地事務,大多數城市和城鎮使用某種形式的當地太陽時間,由著名的時鐘(例如,在教堂尖頂上,或在珠寶商的窗戶)維護。 這就是為什麼你看到如此奇怪的時區位移。
此範例示範 Java 8 函式更精確,並考慮來自 IANA TZDB 的歷程記錄數據。 切換至 Java 8 時間 API 之後,Databricks Runtime 7.0 會從自動改善中獲益,並更精確地解析時區位移。
Databricks Runtime 7.0 也切換至 Timestamp 類型的 Proleptic 公曆。
ISO SQL:2016 標準宣告時間戳的有效範圍是從 0001-01-01 00:00:00 到 9999-12-31 23:59:59.999999。 Databricks Runtime 7.0 完全符合標準,並支援此範圍中的所有時間戳。 相較於 Databricks Runtime 6.x 和以下版本,請注意下列子範圍:
-
0001-01-01 00:00:00..1582-10-03 23:59:59.999999。 Databricks Runtime 6.x 和以下版本會使用 Julian 行事曆,且不符合標準。 Databricks Runtime 7.0 修正此問題,並在取得年、月、日等時間戳的內部作業中套用 Proleptic Gregorian 行事曆。由於不同的行事曆,Databricks Runtime 6.x 和以下部分日期不存在於 Databricks Runtime 7.0 中。 例如,1000-02-29 不是有效的日期,因為 1000 不是公曆中的閏年。 此外,Databricks Runtime 6.x 和以下版本會將時區名稱解析為此時間戳範圍的區域位移不正確。 -
1582-10-04 00:00:00..1582-10-14 23:59:59.999999。 這是 Databricks Runtime 7.0 中本機時間戳的有效範圍,相較於 Databricks Runtime 6.x 及之前的版本,這些版本中並不存在這類時間戳。 -
1582-10-15 00:00:00..1899-12-31 23:59:59.999999。 Databricks Runtime 7.0 會使用 IANA TZDB 的歷史數據正確解析時區位移。 相較於 Databricks Runtime 7.0,Databricks Runtime 6.x 和更早版本在某些情況下,可能會錯誤地解析時區名稱的區域偏移,如上述範例所示。 -
1900-01-01 00:00:00..2036-12-31 23:59:59.999999。 Databricks Runtime 7.0 和 Databricks Runtime 6.x 和以下都符合 ANSI SQL 標準,並在日期時間作業中使用公曆,例如取得當月日期。 -
2037-01-01 00:00:00..9999-12-31 23:59:59.999999。 Databricks Runtime 6.x 及更早的版本可能會錯誤地解析時區位移和夏令時間位移。 Databricks Runtime 7.0 不支援。
將時區名稱對應至位移的另一個層面是因日光節約時間(DST)或切換到另一個標準時區位移而可能發生的本機時間戳重疊。 例如,在 2019 年 11 月 3 日,02:00:00,美國大多數州將時鐘倒退 1 小時到 01:00:00。 本機時間戳 2019-11-03 01:30:00 America/Los_Angeles 可以對應至 2019-11-03 01:30:00 UTC-08:00 或 2019-11-03 01:30:00 UTC-07:00。 如果您未指定位移,而且只要設定時區名稱(例如 2019-11-03 01:30:00 America/Los_Angeles),Databricks Runtime 7.0 會採用先前的位移,通常對應到“summer”。 行為與 Databricks Runtime 6.x 及更低版本不同,而這些版本採用了「冬季」位移。 在時間間隙的情況下,當時鐘向前跳動時,沒有有效的偏移量。 對於典型的一小時日光節約時間變更,Spark 會將這類時間戳移至對應至「夏季」時間的下一個有效時間戳。
如上述範例所示,時區名稱與位移的對應模棱兩可,而且不是一對一。 在可能的情況下,建構時間戳時,建議您指定確切的時區位移,例如 2019-11-03 01:30:00 UTC-07:00。
ANSI SQL 和 Spark SQL 時間戳格式
ANSI SQL 標準會定義兩種類型的時間戳:
-
TIMESTAMP WITHOUT TIME ZONE或TIMESTAMP:本機時間戳為 (YEAR、MONTH、DAY、HOUR、MINUTE、SECOND)。 這些時間戳不會系結至任何時區,而且是時鐘時間戳。 -
TIMESTAMP WITH TIME ZONE:將時間戳分區為 (YEAR、MONTH、DAY、HOUR、MINUTE、SECOND、TIMEZONE_HOUR、TIMEZONE_MINUTE)。 這些時間戳代表與每個值相關聯的 UTC 時區 + 時區位移(以小時和分鐘為單位)的瞬間。
TIMESTAMP WITH TIME ZONE 的時區位移不會影響時間戳所代表的實體時間點,因為該時間點完全以其他時間戳元件指定的UTC時間瞬間表示。 相反地,時區位移只會影響顯示時間戳值的預設行為、日期/時間元件擷取(例如,EXTRACT),以及其他需要知道時區的作業,例如將月份新增至時間戳。
Spark SQL 會將時間戳類型定義為 TIMESTAMP WITH SESSION TIME ZONE,這是字段的組合(YEAR、MONTH、DAY、HOUR、MINUTE、SECOND、SESSION TZ),其中 YEAR 透過 SECOND 字段識別 UTC 時區中的時間瞬間,以及 SESSION TZ 從 SQL config spark.sql.session.timeZone 取得的位置。 工作階段時區可以設定為:
- 時區偏移
(+|-)HH:mm。 此表單可讓您明確定義實體時間點。 - 時區名稱,格式為區域識別碼
area/city,例如America/Los_Angeles。 這種形式的時區資訊存在一些之前提到的問題,例如本地時間戳的重疊。 不過,每個 UTC 時間瞬間明確與任何區域識別碼的一個時區位移相關聯,因此,每個具有區域標識符型時區的時間戳都可以明確轉換成具有區域位移的時間戳。 根據預設,會話時區會設定為 Java 虛擬機的預設時區。
Spark TIMESTAMP WITH SESSION TIME ZONE 與下列不同:
-
TIMESTAMP WITHOUT TIME ZONE,因為此類型的值可以對應至多個實體時間瞬間,但TIMESTAMP WITH SESSION TIME ZONE的任何值都是具象的實體時間瞬間。 SQL 類型可以使用所有會話的一個固定時區位移來模擬,例如 UTC+0。 在此情況下,您可以將 UTC 的時間戳視為本機時間戳。 -
TIMESTAMP WITH TIME ZONE,因為根據 SQL 標準,列的數據值可以有不同的時區偏移。 Spark SQL 不支援。
您應該注意到,與全域 (會話範圍) 時區相關聯的時間戳不是Spark SQL新發明的時間戳。 例如 Oracle 的 RDBMS 會為時間戳提供類似的類型:TIMESTAMP WITH LOCAL TIME ZONE。
構建日期和時間戳記
Spark SQL 提供一些方法來建構日期和時間值:
- 不含參數的預設建構函式:
CURRENT_TIMESTAMP()和CURRENT_DATE()。 - 從其他原始的 Spark SQL 基本類型,例如
INT、LONG和STRING - 從外部類型例如 Python 的日期時間或 Java 類別
java.time.LocalDate/Instant。 - 從 CSV、JSON、Avro、Parquet、ORC 等數據源進行反序列化。
Databricks Runtime 7.0 中引進的函式 MAKE_DATE 採用三個參數:YEAR、MONTH和 DAY,並建構 DATE 值。 所有輸入參數都會盡可能隱含地轉換成 INT 類型。 函式會檢查產生的日期是否為 Proleptic 公曆中的有效日期,否則會傳回 NULL。 例如:
spark.createDataFrame([(2020, 6, 26), (1000, 2, 29), (-44, 1, 1)],['Y', 'M', 'D']).createTempView('YMD')
df = sql('select make_date(Y, M, D) as date from YMD')
df.printSchema()
root
|-- date: date (nullable = true)
若要列印 DataFrame 內容,請呼叫 show() 操作,這將把日期轉換為執行個體上的字串,並將字串傳送至 Driver 程序以在控制台上輸出:
df.show()
+-----------+
| date|
+-----------+
| 2020-06-26|
| null|
|-0044-01-01|
+-----------+
同樣地,您可以使用 MAKE_TIMESTAMP 函式來建構時間戳值。 如同 MAKE_DATE,它會對日期欄位執行相同的驗證,並額外接受時間字段 HOUR (0-23)、MINUTE (0-59) 和 SECOND (0-60)。 SECOND 具有 Decimal(precision = 8, scale = 6) 類型,因為可以傳遞小數部分高達微秒精確度的秒數。 例如:
df = spark.createDataFrame([(2020, 6, 28, 10, 31, 30.123456), \
(1582, 10, 10, 0, 1, 2.0001), (2019, 2, 29, 9, 29, 1.0)],['YEAR', 'MONTH', 'DAY', 'HOUR', 'MINUTE', 'SECOND'])
df.show()
+----+-----+---+----+------+---------+
|YEAR|MONTH|DAY|HOUR|MINUTE| SECOND|
+----+-----+---+----+------+---------+
|2020| 6| 28| 10| 31|30.123456|
|1582| 10| 10| 0| 1| 2.0001|
|2019| 2| 29| 9| 29| 1.0|
+----+-----+---+----+------+---------+
df.selectExpr("make_timestamp(YEAR, MONTH, DAY, HOUR, MINUTE, SECOND) as MAKE_TIMESTAMP")
ts.printSchema()
root
|-- MAKE_TIMESTAMP: timestamp (nullable = true)
至於日期,請使用 show() 動作打印 ts DataFrame 的內容。 同樣地,show() 將時間戳轉換成字串,但現在它會考慮 SQL 組態所定義的工作階段時區 spark.sql.session.timeZone。
ts.show(truncate=False)
+--------------------------+
|MAKE_TIMESTAMP |
+--------------------------+
|2020-06-28 10:31:30.123456|
|1582-10-10 00:01:02.0001 |
|null |
+--------------------------+
Spark 無法建立最後一個時間戳,因為此日期無效:2019 不是閏年。
您可能會注意到上述範例中沒有時區資訊。 在此情況下,Spark 會從 SQL 組態 spark.sql.session.timeZone 取得時區,並將其套用至函式調用。 您也可以將它傳遞為 MAKE_TIMESTAMP的最後一個參數,以挑選不同的時區。 以下是範例:
df = spark.createDataFrame([(2020, 6, 28, 10, 31, 30, 'UTC'),(1582, 10, 10, 0, 1, 2, 'America/Los_Angeles'), \
(2019, 2, 28, 9, 29, 1, 'Europe/Moscow')], ['YEAR', 'MONTH', 'DAY', 'HOUR', 'MINUTE', 'SECOND', 'TZ'])
df = df.selectExpr('make_timestamp(YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, TZ) as MAKE_TIMESTAMP')
df = df.selectExpr("date_format(MAKE_TIMESTAMP, 'yyyy-MM-dd HH:mm:ss VV') AS TIMESTAMP_STRING")
df.show(truncate=False)
+---------------------------------+
|TIMESTAMP_STRING |
+---------------------------------+
|2020-06-28 13:31:00 Europe/Moscow|
|1582-10-10 10:24:00 Europe/Moscow|
|2019-02-28 09:29:00 Europe/Moscow|
+---------------------------------+
如範例所示,Spark 會考慮指定的時區,但會將所有本機時間戳調整為會話時區。 因為 MAKE_TIMESTAMP 類型假設所有值都屬於一個時區,所以傳遞至 TIMESTAMP WITH SESSION TIME ZONE 函式的原始時區會遺失,並且它甚至不會為每個值儲存時區。 根據 TIMESTAMP WITH SESSION TIME ZONE的定義,Spark 會將本機時間戳儲存在 UTC 時區,並在擷取日期時間字段或將時間戳轉換成字元串時使用會話時區。
此外,可以透過類型轉換從 LONG 類型構建時間戳。 如果 LONG 數據行包含自 1970-01-01-01 00:00:00Z 之後的秒數,則可以轉換成 Spark SQL TIMESTAMP:
select CAST(-123456789 AS TIMESTAMP);
1966-02-02 05:26:51
不幸的是,這種方法不允許您指定秒的小數部分。
另一種方式是從 STRING 類型的值建構日期和時間。 您可以使用特別關鍵字來創建文字值:
select timestamp '2020-06-28 22:17:33.123456 Europe/Amsterdam', date '2020-07-01';
2020-06-28 23:17:33.123456 2020-07-01
或者,您可以使用可套用至欄位中所有值的類型轉換:
select cast('2020-06-28 22:17:33.123456 Europe/Amsterdam' as timestamp), cast('2020-07-01' as date);
2020-06-28 23:17:33.123456 2020-07-01
輸入的時間戳字串會被解釋為在指定時區的本地時間戳;如果輸入字串中省略了時區,則會視為會話時區的時間戳。 具有異常模式的字串可以使用 to_timestamp() 函式轉換成時間戳。 支援的模式描述於 格式化和剖析的日期時間模式:
select to_timestamp('28/6/2020 22.17.33', 'dd/M/yyyy HH.mm.ss');
2020-06-28 22:17:33
如果您未指定模式,函式的行為會類似 CAST。
為了提供可用性,Spark SQL 會辨識所有接受字串並傳回時間戳或日期的方法中的特殊字串值:
-
epoch是日期1970-01-01或時間戳1970-01-01 00:00:00Z的別名。 -
now是會話時區目前的時間戳或日期。 在單一查詢中,它一律會產生相同的結果。 -
today是TIMESTAMP類型的目前日期開始,或只是DATE類型的目前日期。 -
tomorrow是時間戳紀錄的隔天開始,而對於DATE類型來說則是僅指隔天。 -
yesterday是目前TIMESTAMP類型的前一天或其開始。
例如:
select timestamp 'yesterday', timestamp 'today', timestamp 'now', timestamp 'tomorrow';
2020-06-27 00:00:00 2020-06-28 00:00:00 2020-06-28 23:07:07.18 2020-06-29 00:00:00
select date 'yesterday', date 'today', date 'now', date 'tomorrow';
2020-06-27 2020-06-28 2020-06-28 2020-06-29
Spark 可讓您從驅動程式端的現有外部物件集合建立 Datasets,並建立對應類型的數據行。 Spark 會將外部類型的實例轉換成語意相等的內部表示法。 例如,若要使用 Python 集合中的 Dataset 和 DATE 數據行來建立 TIMESTAMP,您可以使用:
import datetime
df = spark.createDataFrame([(datetime.datetime(2020, 7, 1, 0, 0, 0), datetime.date(2020, 7, 1))], ['timestamp', 'date'])
df.show()
+-------------------+----------+
| timestamp| date|
+-------------------+----------+
|2020-07-01 00:00:00|2020-07-01|
+-------------------+----------+
PySpark 會使用系統時區,將 Python 的日期時間物件轉換成驅動程式端的內部 Spark SQL 表示法,這與 Spark 的工作階段時區設定 spark.sql.session.timeZone不同。 內部值不包含原始時區的相關信息。 將來執行的操作會只依據 TIMESTAMP WITH SESSION TIME ZONE 類型定義來考慮 Spark SQL 會話時區的平行日期與時間戳值。
同樣地,Spark 會將下列類型辨識為 Java 和 Scala API 中的外部日期時間類型:
-
java.sql.Date和java.time.LocalDate作為DATE類型的外部類型 -
java.sql.Timestamp類型的java.time.Instant和TIMESTAMP。
java.sql.* 和 java.time.* 類型之間有差異。
java.time.LocalDate 和 java.time.Instant 已新增至 Java 8,且類型是以 Proleptic 公曆為基礎,這是 Databricks Runtime 7.0 和更新版本所使用的相同行事曆。
java.sql.Date 和 java.sql.Timestamp 在混合式行事曆下有另一個行事曆 (Julian + Gregorian 自 1582-10-15 起),這與 Databricks Runtime 6.x 和以下使用的舊版行事曆相同。 由於不同的行事曆系統,Spark 在轉換至內部 Spark SQL 表示法期間必須執行其他作業,並將輸入日期/時間戳從某個行事曆重新設定為另一個行事曆。 在 1900 年之後,重新基底作業對於新式時間戳有一點額外負荷,而且對於舊時間戳而言可能更為顯著。
下列範例示範如何從 Scala 集合建立時間戳。 第一個範例會從字串建構 java.sql.Timestamp 物件。 方法 valueOf 會將輸入字串解譯為預設 JVM 時區中的本機時間戳,這可能與 Spark 的工作階段時區不同。 如果您需要在特定時區內建構 java.sql.Timestamp 類別或 java.sql.Date 類別的實例,請查看 java.text.SimpleDateFormat(及其方法 setTimeZone)或 java.util.Calendar。
Seq(java.sql.Timestamp.valueOf("2020-06-29 22:41:30"), new java.sql.Timestamp(0)).toDF("ts").show(false)
+-------------------+
|ts |
+-------------------+
|2020-06-29 22:41:30|
|1970-01-01 03:00:00|
+-------------------+
Seq(java.time.Instant.ofEpochSecond(-12219261484L), java.time.Instant.EPOCH).toDF("ts").show
+-------------------+
| ts|
+-------------------+
|1582-10-15 11:12:13|
|1970-01-01 03:00:00|
+-------------------+
同樣地,您可以從 DATE 或 java.sql.Date集合建立 java.sql.LocalDate 數據行。 實例 java.sql.LocalDate 的平行化完全獨立於 Spark 的工作階段或 JVM 預設時區,而實例 java.sql.Date 的平行化則不然。 有細微差別:
-
java.sql.Date實例代表驅動程式上預設 JVM 時區的本機日期。 - 若要正確轉換成 Spark SQL 值,驅動程式和執行程式上的預設 JVM 時區必須相同。
Seq(java.time.LocalDate.of(2020, 2, 29), java.time.LocalDate.now).toDF("date").show
+----------+
| date|
+----------+
|2020-02-29|
|2020-06-29|
+----------+
若要避免任何行事曆和時區相關問題,建議 Java 8 類型 java.sql.LocalDate/Instant 做為平行處理時間戳或日期的 Java/Scala 集合的外部類型。
收集日期和時間戳
平行處理的反向作業是從執行程式收集日期與時間戳回到驅動程式,並傳回外部類型的集合。 例如,您可以使用 DataFrame 動作,將 collect() 提取回驅動程式:
df.collect()
[Row(timestamp=datetime.datetime(2020, 7, 1, 0, 0), date=datetime.date(2020, 7, 1))]
Spark 會將日期與時間戳數據行的內部值當做 UTC 時區中的時間瞬間,從執行程式傳送至驅動程式,並在驅動程式的系統時區中執行 Python datetime 物件的轉換,而不是使用 Spark SQL 會話時區。
collect() 與上一節所述的 show() 動作不同。
show() 在將時間戳轉換成字串時使用會話時區,並在驅動程式上收集產生的字串。
在 Java 和 Scala API 中,Spark 預設會執行下列轉換:
- Spark SQL
DATE值會轉換成java.sql.Date實例。 - Spark SQL
TIMESTAMP值會轉換成java.sql.Timestamp實例。
這兩個轉換都會在驅動程式上的預設 JVM 時區中執行。 如此一來,若要擁有您可以使用 Date.getDay()、getHour()等取得的相同日期時間欄位,並使用 Spark SQL 函式 DAY、HOUR,則驅動程式上的預設 JVM 時區與執行器上的會話時區應該一致。
與從 java.sql.Date/Timestamp製作日期/時間戳類似,Databricks Runtime 7.0 會執行從 Proleptic 公曆到混合式行事曆 (Julian + 公曆) 的重新計算。 對於現代日期(1582年之後)和時間戳(1900年之後),這項作業幾乎是不需要額外負擔的,但對於古代日期和時間戳,它可能會帶來一些額外的負荷。
您可以避免這類行事曆相關問題,並要求 Spark 傳回自 Java 8 以來新增的 java.time 類型。 如果您將 SQL 組態 spark.sql.datetime.java8API.enabled 設為 true,則 Dataset.collect() 動作會傳回:
- Spark SQL 中
java.time.LocalDate類型的DATE - Spark SQL 中
java.time.Instant類型的TIMESTAMP
現在,由於 Java 8 類型和 Databricks Runtime 7.0 和更新版本都是以 Proleptic 公曆為基礎,因此轉換不會受到行事曆相關問題的影響。 動作 collect() 不取決於預設 JVM 時區。 時間戳轉換完全不相依於時區。 日期轉換會使用 SQL 組態中的工作階段時區 spark.sql.session.timeZone。 例如,考慮一個具有 Dataset 和 DATE 資料行的 TIMESTAMP,預設 JVM 時區設定為 Europe/Moscow,會話時區設定為 America/Los_Angeles。
java.util.TimeZone.getDefault
res1: java.util.TimeZone = sun.util.calendar.ZoneInfo[id="Europe/Moscow",...]
spark.conf.get("spark.sql.session.timeZone")
res2: String = America/Los_Angeles
df.show
+-------------------+----------+
| timestamp| date|
+-------------------+----------+
|2020-07-01 00:00:00|2020-07-01|
+-------------------+----------+
show() 動作會在會話時間 America/Los_Angeles列印時間戳,但如果您收集 Dataset,則會轉換成 java.sql.Timestamp,且 toString 方法會列印 Europe/Moscow:
df.collect()
res16: Array[org.apache.spark.sql.Row] = Array([2020-07-01 10:00:00.0,2020-07-01])
df.collect()(0).getAs[java.sql.Timestamp](0).toString
res18: java.sql.Timestamp = 2020-07-01 10:00:00.0
實際上,當地時間戳 2020-07-01 00:00:00 在 UTC 時是 2020-07-01T07:00:00Z。 您可以觀察到,如果您啟用 Java 8 API 並收集資料集:
df.collect()
res27: Array[org.apache.spark.sql.Row] = Array([2020-07-01T07:00:00Z,2020-07-01])
您可以將 java.time.Instant 物件轉換成與全域 JVM 時區無關的任何本機時間戳。 這是 java.time.Instant 優於 java.sql.Timestamp的優點之一。 前者需要變更全域 JVM 設定,這會影響相同 JVM 上的其他時間戳。 因此,如果您的應用程式處理不同時區中的日期或時間戳,而且應用程式在使用 Java 或 Scala Dataset.collect() API 收集資料至驅動程式時,不應該彼此衝突,建議您使用 SQL 組態切換至 Java 8 API spark.sql.datetime.java8API.enabled。