模式演化 是指系統適應資料結構隨時間變化的能力。 這些變更在使用半結構化資料、事件串流或協力廠商來源時很常見,其中會新增欄位、資料類型會轉移或巢狀結構演變。
常見的變更包括:
- 新欄:先前未定義的其他欄位,有時具有自訂回填值。
-
欄位重新命名:例如將欄位名稱從
name變更為full_name。 - 刪除的資料行:從資料表結構中移除資料行。
-
類型加寬:將欄的類型變更為更廣泛的類型。 例如,
INT欄位變成DOUBLE。 -
其他類型變更:變更資料行的類型。 例如,
INT欄位變成STRING。
支援結構描述演進對於建置有彈性、長時間執行的管道至關重要,這些管道可以適應不斷變化的資料,而無需頻繁手動更新。
Components
Azure Databricks 結構描述演進涉及四個主要元件類別,每個類別都會獨立處理結構描述變更:
- 連接器:從外部來源擷取資料的元件。 其中包括 Auto Loader、Kafka、Kinesis 和 Lakeflow 連接器。
-
格式剖析器:解碼原始格式的函數,包括
from_json、 、from_avrofrom_xml和from_protobuf。 - 引擎:執行查詢的處理引擎,包括結構化串流。
- 資料集:串流資料表、物質化檢視、Delta 表格,以及持久化並提供資料的檢視。
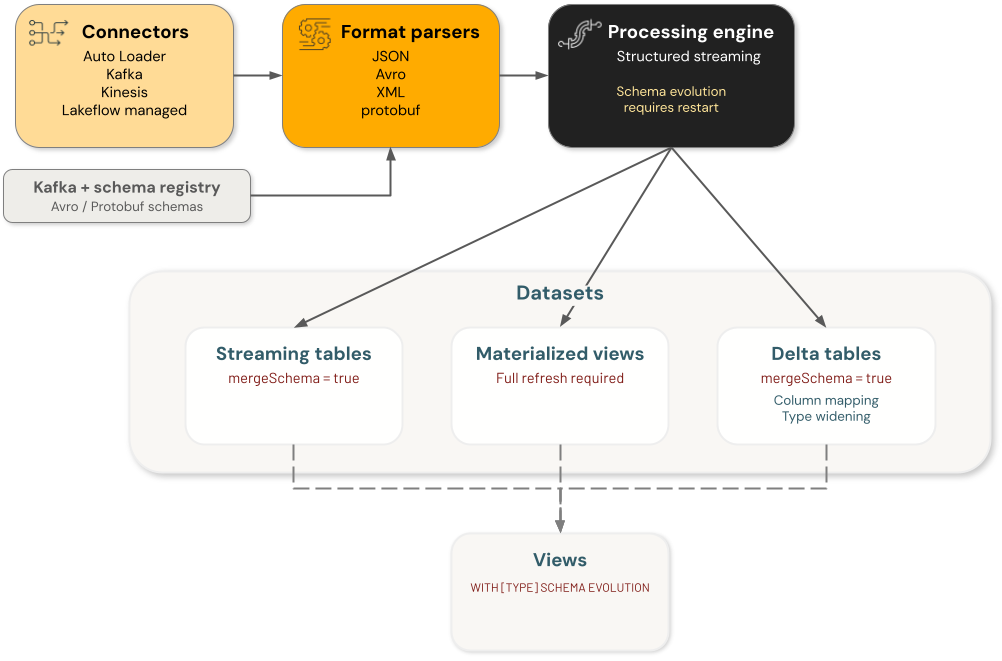
資料工程架構架構演進中的每個元件都是獨立的。 您負責在個別元件中設定結構描述演進,以在資料處理流程中實現所需的行為。
例如,使用自動載入器將資料擷取至 Delta 資料表時,有兩個持續性結構描述 - 一個由 Auto Loader 在其結構描述位置管理,另一個是目標 Delta 資料表的結構描述。 在穩定狀態下,這兩者是一樣的。 當自動載入器根據傳入資料演進其結構描述時,Delta 資料表也必須演化其結構描述,否則查詢會失敗。 在此情況下,您可以 (a) 啟用結構描述演進或使用直接 DDL 命令來更新目標 Delta 資料表結構描述,或 (b) 對目標 Delta 資料表進行完整重寫。
連接器對於結構設計演進的支援
下列各節詳細說明每個 Azure Databricks 元件如何處理不同類型的結構描述變更。
自動加載器
自動載入器支援欄位變更與字型拓寬。 使用 cloudFiles.schemaEvolutionMode 和 rescuedDataColumn 設定自動結構模式發展。 您可以手動設定 schemaHints 或不可變的 schema。 自動演進資料結構時,串流一開始會發生故障。 重新啟動時,會使用已演化的資料結構。 請參閱 自動載入器結構描述演進的運作方式。
-
新欄:支援與否,視所選取的項目而定
schemaEvolutionMode。 失敗,需要手動重新啟動才能將新資料行新增至結構描述。 -
欄位重新命名:支援,取決於所選內容
schemaEvolutionMode。 重新命名的欄位被視為新增的欄位,而對於新列,舊欄位會填入NULL。 發生失敗,需手動重新啟動才能更新資料表結構。 -
已移除的資料行:支援。 視為虛刪除操作,將已刪除欄的新增資料列設定為
NULL。 -
型別擴展:支援於 Databricks Runtime 16.4 及以上版本,設置
schemaEvolutionMode為addNewColumnsWithTypeWidening。 支援的資料型別變更會自動擴充。 未支援的型別變更會被記錄在rescuedDataColumn中。 請參見 自動型別擴展與 Auto Loader。 -
其他類型變更:不支援。 類型變更會在
rescuedDataColumn中擷取,如果rescueDataColumn已設定且schemaEvolutionMode設為rescue。 否則,需要手動進行綱要更改。
Delta 連接器
Delta 連接器可以支援方案演化。 若從啟用 欄位映射 與 schemaTrackingLocation 的 Delta 表格讀取,則支援結構演化以進行欄位重命名與刪除欄位。 您必須為每個變更設定正確的 Spark 組態,才能在不停止資料流程的情況下演進架構。 否則,每當偵測到變更時,資料串流就會演化其追蹤的結構描述,然後停止演化。 然後,您必須手動重新啟動串流查詢才能繼續處理。
-
新欄:支援。 啟用後
mergeSchema,新的欄位會自動新增。 否則查詢會失敗,必須重新啟動串流才能將新欄位加入結構,但 Delta 資料表不需要重寫。 -
欄重新命名:支援。 啟用
mergeSchema後,重新命名會自動處理。 否則,你可以在串流任務中使用 Spark 的設定spark.databricks.delta.streaming.allowSourceColumnRename來演化 schema。 -
已移除的資料行:支援。 啟用
mergeSchema後,刪除的欄位會自動處理。 否則,你可以在串流任務中使用 Spark 的設定spark.databricks.delta.streaming.allowSourceColumnDrop來演化 schema。 - 型別擴展:支援 Databricks Runtime 16.4 LTS 及以上版本。 在目標表格上啟用
mergeSchema並啟用類型擴展時,類型變更會被自動處理。 您可以使用表格屬性啟用type widening型別擴展。 - 其他類型變更:不支援。
SaaS 和 CDC 連接器
SaaS 和 CDC 連接器會在資料行變更時自動演進架構。 這是在偵測到變更時透過自動重新啟動來處理的。 類別變更需要完整重新整理。
- 新欄:支援。 查詢會自動重新啟動以解決結構描述不相符的問題。
- 欄重新命名:支援。 查詢會自動重新啟動以解決結構描述不相符的問題。 重新命名的資料行會被視為新增的資料行。
-
已移除的資料行:支援。 捨棄的資料行會被視為虛刪除,已刪除資料行的新資料列會被設為
NULL。 - 類型加寬:不支援。 更新結構描述需要完整重新整理。
- 其他類型變更:不支援。 更新結構描述需要完整重新整理。
Kinesis、Kafka、Pub/Sub 和 Pulsar 連接器
不支援原生結構描述演進。 每個連接器函式都會傳回二進位資料 Blob。 結構描述演進由格式剖析器處理。
- 新資料行:由格式剖析器處理。
- 列重新命名:由格式剖析器處理。
- 刪除的資料行:由格式剖析器處理。
- 類型加寬:由格式剖析器處理。
- 其他類型變更:由格式剖析器處理。
格式解析器的架構演進支援
from_json 解析器
from_json剖析器不支援架構演進。 您必須手動更新結構描述。 在 Lakeflow Spark 宣告式管線中使用from_json時,可以使用schemaLocationKey和schemaEvolutionMode來啟用自動模式演進。
- 新資料行:啟用自動結構描述演進時,其行為類似於自動載入器。
- 欄重新命名:啟用自動結構描述演進時,其行為類似於自動載入器。
- 捨棄的欄位:啟用自動結構演變時,其行為類似於自動載入器。
- 類型擴大:啟用自動結構描述演進時,其行為類似於自動載入器。
- 其他類型變更:啟用自動結構描述演進時,其行為類似於自動載入器。
from_avro 和 from_protobuf 解析器
from_avro 和 from_protobuf 剖析器的行為方式相同。 結構描述可以從 Confluent Schema Registry 擷取,也可以使用者提供結構描述,但必須手動更新結構描述。 在from_avro或from_protobuf函式中並無結構描述演變的概念;它必須由執行引擎和結構描述註冊表處理。
- 新的欄位:受Confluent Schema Registry支援。 否則,使用者必須手動更新結構描述。
- 欄位重新命名:支援Confluent Schema Registry。 否則,使用者必須手動更新結構描述。
- 被刪除的欄位:支援 Confluent Schema Registry。 否則,使用者必須手動更新結構描述。
- 型別擴大:已支援Confluent Schema Registry。 否則,使用者必須手動更新結構描述。
- 其他型別變更:受 Confluent Schema Registry 支援。 否則,使用者必須手動更新結構描述。
from_csv 和 from_xml 解析器
from_csv 和 from_xml 剖析器不支援結構描述演進。
- 新欄:不支援
- 欄重新命名:不支援
- 已刪除的資料行:不支援
- 類型擴展:不支援
- 其他類型變更:不支援
引擎對結構描述演進的支援
結構化串流
串流查詢的結構描述會在規劃階段鎖定,所有微批次都會重複使用該計劃,而不需重新規劃。 如果來源結構描述在執行過程中變更,查詢就會失敗,而且使用者必須重新啟動串流查詢,以便 Spark 可以針對新的結構描述重新規劃。
串流所寫入的資料集也必須支援結構演化。
- 新欄:支援。 查詢失敗,您必須重新啟動串流才能解決結構描述不相符的問題。
- 欄重新命名:支援。 查詢失敗,您必須重新啟動串流才能解決結構描述不相符的問題。
- 已移除的資料行:支援。 查詢失敗,您必須重新啟動串流才能解決結構描述不相符的問題。
- 類型擴展:支援。 查詢失敗,您必須重新啟動串流才能解決結構描述不相符的問題。
- 其他類型變更:支援。 查詢失敗,您必須重新啟動串流才能解決結構描述不相符的問題。
依資料集進行架構演化
串流數據表
串流資料表預設支援 合併結構演進 行為。 更新結構描述不需要手動重新啟動,但任意結構描述變更需要完整重新整理。
- 新欄:支援。 查詢會自動重新啟動,以解決結構描述不相符的問題。
- 欄重新命名:支援。 查詢會重新啟動以解決結構描述不相符的問題。 重新命名的資料行會被視為新增的資料行。
- 已移除的資料行:支援。 卸除的資料行會被視為虛刪除,其中已刪除資料行的新資料列會設定為 Null。
- 類型擴展:支援。 型別擴展必須在管線層級或直接在表格上啟用。 請參見 Lakeflow Spark 宣告式管線中的類型拓寬。
- 其他類型變更:不支援。 更新結構描述需要完整重新整理。
具象化視圖
結構描述或定義查詢的任何更新都會觸發具體化檢視的完整重新計算。
- 新資料行:觸發完整重新計算。
- 資料行重新命名:觸發完整重新計算。
- 已卸除的資料行:已觸發全面重新計算。
- 類型擴大:觸發完整重新計算。
- 其他類型變更:已觸發完整重新計算。
Delta 表格
Delta 資料表支援多種配置來更新資料表結構,包括重新命名、移除和擴展資料行類型,而不需要重寫資料表中的數據。 支援的設定包括 合併結構描述演進、欄位對應、類型擴展 和 覆寫結構描述。
- 新欄:支援。 在啟用合併模式演變的情況下,自動進化,無需重寫 Delta 資料表。 如果未啟用合併結構描述演進,則更新會失敗。
-
欄重新命名:支援。 可以透過啟用欄位映射的手動
ALTER TABLE DDL指令來執行重新命名。 不需要重寫 Delta 資料表。 -
已移除的資料行:支援。 可以在啟用欄位對應的情況下,使用手動
ALTER TABLE DDL命令刪除欄位。 不需要重寫 Delta 資料表。 -
類型擴展:支援。 當啟用型別擴展與合併結構演化時,會自動套用型別變更。 啟用類型加寬時,您可以透過手動
ALTER TABLE DDL指令加寬欄。 如果未設定任何一項,作業會失敗。 參見 具有自動模式演化的 Widen 類型。 -
其他類型變更:支援,但需要完整重寫 Delta 資料表。 您必須啟用
overwriteSchema,這將對 Delta Table 進行完整重寫。 否則,作業會失敗。
瀏覽次數
如果檢視具有不符合新結構描述的column_list,或具有無法剖析的查詢,則該檢視會變成無效。 如果不是這樣,您可以啟用 SCHEMA TYPE EVOLUTION 支援類型變更的結構描述演進;此外,SCHEMA EVOLUTION 可以支援類型變更,以及新增、重新命名和捨棄的資料行(這是類型演進的超集)。
-
新欄:支援。 在
SCHEMA EVOLUTION模式下,如果沒有明確的column_list,視圖會自動演變,無需任何手動干預。 否則,檢視可能會變成無效,且使用者無法查詢。 -
欄位重新命名:支援。 在
SCHEMA EVOLUTION模式下,如果沒有明確的column_list,視圖會自動演變,無需任何手動干預。 否則,視圖可能會變成無效。 -
已移除的資料行:支援。 在
SCHEMA EVOLUTION模式下,如果沒有明確的column_list,視圖會自動演變,無需任何手動干預。 否則,視圖可能會變成無效。 -
類型擴展:支援。 在
SCHEMA TYPE EVOLUTION模式下,視圖會針對任何類型變更自動更新。 在SCHEMA EVOLUTION模式下,如果沒有明確的column_list,視圖會自動演變,無需任何手動干預。 否則,視圖可能會變成無效。 -
其他類型變更:支援。 在
SCHEMA TYPE EVOLUTION模式下,視圖會針對任何類型變更自動更新。 在SCHEMA EVOLUTION模式下,如果沒有明確的column_list,視圖會自動演變,無需任何手動干預。 否則,視圖可能會變成無效。
Example
下列範例顯示如何使用在 Confluent Schema Registry 中註冊的 Avro 編碼承載擷取 Kafka 主題,並將其寫入已啟用結構描述演進的受管理 Delta 資料表。
說明要點:
- 與 Kafka 連接器整合。
- 使用from_avro搭配 Kafka Schema Registry 來解碼 Avro 記錄。
- 透過設定
avroSchemaEvolutionMode來處理結構描述演進。 - 將
mergeSchema功能啟用後寫入 Delta 資料表,以允許累加變更。
程式碼假設您有一個使用 Confluent 結構描述登錄的 Kafka 主題,輸出 Avro 編碼的資料。
# ----- CONFIG: fill these in -----
# Catalog and schema:
CATALOG = "<catalog_name>"
SCHEMA = "<schema_name>"
# Schema Registry:
# (This is where the producer evolves the schema)
SCHEMA_REG = "<schema registry endpoint>"
SR_USER = "<api key>"
SR_PASS = "<api secret>"
# Confluent Cloud: SASL_SSL broker:
BOOTSTRAP = "<server:ip>"
# Kafka topic:
TOPIC = "<topic>"
# ----- end: config -----
BRONZE_TABLE = f"{CATALOG}.{SCHEMA}.bronze_users"
CHECKPOINT = f"/Volumes/{CATALOG}/{SCHEMA}/checkpoints/bronze_users"
# Kafka auth (example for Confluent Cloud SASL/PLAIN over SSL)
KAFKA_OPTS = {
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "PLAIN",
"kafka.sasl.jaas.config": f"kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='{SR_USER}' password='{SR_PASS}';"
}
# ----- Evolution knobs -----
# spark.conf.set("spark.databricks.delta.schema.autoMerge.enabled", value = True)
from pyspark.sql.functions import col
from pyspark.sql.avro.functions import from_avro
# Build reader
reader = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", BOOTSTRAP)
.option("subscribe", TOPIC)
.option("startingOffsets", "earliest")
)
# Attach Kafka auth options
for k, v in KAFKA_OPTS.items():
reader = reader.option(k, v)
# --- No native schema evolution supported. Returns a binary blob. ---
raw_df = reader.load()
# Decode Avro with Schema Registry
# --- The format parser handles updating the schema using the schema registry ---
decoded = from_avro(
data=col("value"),
jsonFormatSchema=None, # using SR
subject=f"{TOPIC}-value",
schemaRegistryAddress=SCHEMA_REG,
options={
"confluent.schema.registry.basic.auth.credentials.source": "USER_INFO",
"confluent.schema.registry.basic.auth.user.info": f"{SR_USER}:{SR_PASS}",
# Behavior on schema changes:
"avroSchemaEvolutionMode": "restart", # fail-fast so you can restart and adopt new fields
"mode": "FAILFAST"
}
).alias("payload")
bronze_df = raw_df.select(decoded, "timestamp").select("payload.*", "timestamp")
# Write to a managed Delta table as a STREAM
# --- Need to enable schema evolution separately for streaming to a Delta separately with mergeSchema --
(bronze_df.writeStream
.format("delta")
.option("checkpointLocation", CHECKPOINT)
.option("ignoreChanges", "true")
.outputMode("append")
.option("mergeSchema", "true") # only supports adding new columns. Renaming, dropping, and type changes need to be handled separately.
.trigger(availableNow=True) # Use availableNow trigger for Databricks SQL/Unity Catalog
.toTable(BRONZE_TABLE)
)