重要
Databricks Runtime 12.2 LTS 及更低版本的 Databricks Connect 已被棄用。 Databricks Runtime 12.2 LTS 及所有早期 LTS 版本已停止支援。 改用 Databricks Connect 來支援 Databricks Runtime 13.3 LTS 及以上 版本。 關於從 Databricks Connect for Databricks Runtime 12.2 LTS 及以下版本遷移到 Databricks Connect for Databricks Runtimes 13.3 LTS 及以上版本的資訊,請參見 「遷移至 Databricks Connect for Python 」或 「遷移至 Databricks Connect for Scala」。
Databricks Connect 可讓您將熱門 IDE,例如 Visual Studio Code 和 PyCharm、Notebook 伺服器和其他自定義應用程式連線至 Azure Databricks 叢集。
本文說明 Databricks Connect 的運作方式、逐步引導您完成開始使用 Databricks Connect 的步驟、說明如何針對使用 Databricks Connect 時可能發生的問題進行疑難解答,以及使用 Databricks Connect 執行與在 Azure Databricks 筆記本中執行之間的差異。
概觀
Databricks Connect 是 Databricks Runtime 的用戶端連結庫。 它可讓您使用 Spark API 撰寫作業,並在 Azure Databricks 叢集上遠端執行作業,而不是在本機 Spark 工作階段中執行。
例如,當您使用 Databricks Connect 執行 DataFrame 命令 spark.read.format(...).load(...).groupBy(...).agg(...).show() 時,命令的邏輯表示法會傳送至在 Azure Databricks 中執行的 Spark 伺服器,以在遠端叢集上執行。
使用 Databricks Connect,您可以:
- 從任何 Python、R、Scala 或 Java 應用程式執行大規模的 Spark 作業。 無論您在任何地方
import pyspark、require(SparkR)或import org.apache.spark,都可以直接從應用程式執行 Spark 作業,無須安裝任何 IDE 外掛程式或使用 Spark 提交腳本。 - 即使在使用遠端叢集時,也請逐步執行並偵錯 IDE 中的程式碼。
- 在開發函式庫時快速迭代。 您不需要在 Databricks Connect 中變更 Python 或 Java 連結庫相依性之後重新啟動叢集,因為每個用戶端會話都會與叢集中的彼此隔離。
- 關閉無用叢集,而不會遺失資料。 由於用戶端應用程式與叢集分離,因此不會受到叢集重新啟動或升級的影響,這通常會導致失去筆記本中定義的所有變數、RDD 和 DataFrame 物件。
注意
Databricks 建議在使用 SQL 查詢進行 Python 開發時,應使用 Databricks SQL Connector for Python,而不是 Databricks Connect。 適用於 Python 的 Databricks SQL Connector 比 Databricks Connect 更容易設定。 此外,Databricks Connect 會剖析並規劃本機計算機上執行的作業,而作業則會在遠端計算資源上執行。 這會使偵錯運行時間錯誤變得特別困難。 適用於 Python 的 Databricks SQL 連接器會將 SQL 查詢直接提交至遠端計算資源並擷取結果。
需求
本節列出 Databricks Connect 的需求。
僅支援下列 Databricks Runtime 版本:
- Databricks Runtime 12.2 LTS ML,Databricks Runtime 12.2 LTS
- Databricks Runtime 11.3 LTS ML、Databricks Runtime 11.3 LTS
- Databricks Runtime 10.4 LTS ML,Databricks Runtime 10.4 LTS
- Databricks Runtime 9.1 LTS ML、Databricks Runtime 9.1 LTS
- Databricks Runtime 7.3 LTS
您必須在開發計算機上安裝 Python 3,且用戶端 Python 安裝的次要版本必須與 Azure Databricks 叢集的次要 Python 版本相同。 下表顯示每個 Databricks Runtime 一起安裝的 Python 版本。
Databricks Runtime 的版本 Python 版本 12.2 LTS ML、12.2 LTS 3.9 11.3 LTS ML、11.3 LTS 3.9 10.4 LTS ML、10.4 LTS 3.8 9.1 LTS ML、9.1 LTS 3.8 7.3 LTS 3.7 Databricks 強烈建議您已針對與 Databricks Connect 搭配使用的每個 Python 版本啟用 Python 虛擬環境 。 Python 虛擬環境可協助您確定您使用的是正確的 Python 版本和 Databricks Connect。 這有助於減少解決相關技術問題所花費的時間。
例如,如果您在開發計算機上使用 venv ,而您的叢集正在執行 Python 3.9,則必須使用該版本建立
venv環境。 下列範例命令會產生腳本來啟動venv具有 Python 3.9 的環境,然後此命令會將這些腳本放在目前工作目錄中名為.venv的隱藏資料夾中:# Linux and macOS python3.9 -m venv ./.venv # Windows python3.9 -m venv .\.venv若要使用這些腳本來啟用此
venv環境,請參閱 venvs 的運作方式。另一個範例是,如果您在開發計算機上使用 Conda ,而您的叢集正在執行 Python 3.9,則必須使用該版本建立 Conda 環境,例如:
conda create --name dbconnect python=3.9若要使用此環境名稱啟動 Conda 環境,請執行
conda activate dbconnect。Databricks Connect 主要和次要套件版本必須一律符合您的 Databricks 運行時間版本。 Databricks 建議您一律使用與 Databricks Runtime 版本相符的最新 Databricks Connect 套件。 例如,當您使用 Databricks Runtime 12.2 LTS 叢集時,您也必須使用
databricks-connect==12.2.*套件。Java Runtime Environment (JRE) 8。 用戶端已經過 OpenJDK 8 JRE 的測試。 用戶端不支援 Java 11。
注意
在 Windows 上,如果您看到 Databricks Connect 找不到winutils.exe的錯誤,請參閱在 Windows 上找不到 winutils.exe。
設定用戶端
完成下列步驟以設定 Databricks Connect 的本機用戶端。
注意
開始設定本機 Databricks Connect 用戶端之前,您必須 符合 Databricks Connect 的需求 。
步驟 1:安裝 Databricks Connect 用戶端
啟用虛擬環境后,執行
uninstall命令,以卸載已安裝 PySpark。 因為databricks-connect套件與 PySpark 衝突,所以這是必要的。 如需詳細資訊,請參閱 衝突的 PySpark 安裝。 若要檢查是否已安裝 PySpark,請執行show命令。# Is PySpark already installed? pip3 show pyspark # Uninstall PySpark pip3 uninstall pyspark在虛擬環境仍啟用之後,請執行
install命令來安裝 Databricks Connect 用戶端。--upgrade使用 選項,將任何現有的用戶端安裝升級至指定的版本。pip3 install --upgrade "databricks-connect==12.2.*" # Or X.Y.* to match your cluster version.注意
Databricks 建議您附加 「dot-asterisk」 表示法來指定
databricks-connect==X.Y.*,而不是databricks-connect=X.Y,以確保已安裝最新的套件。
步驟 2:設定連線屬性
收集下列組態屬性。
Azure Databricks 個別工作區 URL。 這與
https://後接著您的叢集的伺服器主機名稱值相同;請參閱取得 Azure Databricks 計算資源的連線詳細資料。您的 Azure Databricks 個人存取令牌 或 Microsoft Entra ID(先前稱為 Azure Active Directory) 令牌。
- 針對 Azure Data Lake Storage (ADLS) 認證傳遞,您必須使用Microsoft Entra ID 令牌。 Microsoft Entra ID 認證傳遞僅在標準叢集上執行 Databricks Runtime 7.3 LTS 及以上版本時才受支援,並且不相容於服務主體驗證。
- 如需使用 Microsoft Entra 識別元令牌進行驗證的詳細資訊,請參閱 使用 Microsoft Entra ID 令牌進行驗證。
傳統運算的識別碼。 您可以從 URL 取得傳統運算 ID。 這裡的 ID 是
1108-201635-xxxxxxxx。 另請參閱 計算資源 URL 和 ID。
工作區的唯一組織標識碼。 請參閱 取得工作區對象的識別碼。
Databricks Connect 連線至您的叢集上的指定埠。 預設連接埠為
15001。 如果您的叢集已設定為使用不同的埠,例如8787先前的 Azure Databricks 指示中所提供的埠,請使用已設定的埠號碼。
設定連線,如下所示。
您可以使用 CLI、SQL 組態或環境變數。 組態方法從最高到最低優先順序是:SQL 組態索引鍵、CLI 和環境變數。
CLI
執行
databricks-connect。databricks-connect configure授權會顯示:
Copyright (2018) Databricks, Inc. This library (the "Software") may not be used except in connection with the Licensee's use of the Databricks Platform Services pursuant to an Agreement ...接受授權並提供組態值。 針對 Databricks 主機 和 Databricks 令牌,輸入您在步驟 1 中指出的工作區 URL 和個人存取令牌。
Do you accept the above agreement? [y/N] y Set new config values (leave input empty to accept default): Databricks Host [no current value, must start with https://]: <databricks-url> Databricks Token [no current value]: <databricks-token> Cluster ID (e.g., 0921-001415-jelly628) [no current value]: <cluster-id> Org ID (Azure-only, see ?o=orgId in URL) [0]: <org-id> Port [15001]: <port>如果您收到一則訊息,顯示 Microsoft Entra ID token 過長,您可以將Databricks Token欄位保留空白,並在
~/.databricks-connect手動輸入令牌。
SQL 組態或環境變數。 下表顯示 SQL 組態索引鍵和環境變數,這些環境變數會對應至您在步驟 1 中指出的組態屬性。 若要設定 SQL 組態金鑰,請使用
sql("set config=value")。 例如:sql("set spark.databricks.service.clusterId=0304-201045-abcdefgh")。參數 SQL 組態金鑰 環境變數名稱 Databricks 主機 spark.databricks.service.address DATABRICKS_地址 Databricks 令牌 spark.databricks.service.token DATABRICKS_API_TOKEN 叢集識別碼 spark.databricks.service.clusterId DATABRICKS_CLUSTER_ID 組織識別碼 spark.databricks.service.orgId DATABRICKS_ORG_ID 連接埠 spark.databricks.service.port DATABRICKS_PORT
在虛擬環境仍啟用之後,測試 Azure Databricks 的聯機能力,如下所示。
databricks-connect test如果您設定的叢集未執行,測試會啟動叢集,該叢集會持續執行,直到其設定的自動結束時間為止。 輸出應如下所示:
* PySpark is installed at /.../.../pyspark * Checking java version java version "1.8..." Java(TM) SE Runtime Environment (build 1.8...) Java HotSpot(TM) 64-Bit Server VM (build 25..., mixed mode) * Testing scala command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab..., invalidating prev state ../../.. ..:..:.. WARN SparkServiceRPCClient: Syncing 129 files (176036 bytes) took 3003 ms Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2... /_/ Using Scala version 2.... (Java HotSpot(TM) 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala> spark.range(100).reduce(_ + _) Spark context Web UI available at https://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi View job details at <databricks-url>?o=0#/setting/clusters/<cluster-id>/sparkUi res0: Long = 4950 scala> :quit * Testing python command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab.., invalidating prev state View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi如果未顯示任何連線相關錯誤(
WARN訊息沒問題),則您已成功連線。
使用 Databricks Connect
本節說明如何設定慣用的 IDE 或筆記本伺服器,以使用 Databricks Connect 的用戶端。
本節內容:
- JupyterLab
- 經典 Jupyter Notebook
- PyCharm
- SparkR 和 RStudio Desktop
- sparklyr 和 RStudio Desktop
- IntelliJ (Scala 或 Java)
- PyDev 與 Eclipse
- 日蝕
- SBT
- Spark 介面
JupyterLab
注意
開始使用 Databricks Connect 之前,您必須先 符合需求 ,並 設定 Databricks Connect 的用戶端 。
若要使用 Databricks Connect 與 JupyterLab 和 Python,請遵循這些指示。
若要安裝 JupyterLab,請啟動 Python 虛擬環境,從終端機或命令提示字元執行下列命令:
pip3 install jupyterlab若要在網頁瀏覽器中啟動 JupyterLab,請從您啟動的 Python 虛擬環境執行下列命令:
jupyter lab如果 JupyterLab 未出現在您的網頁瀏覽器中,請從您的虛擬環境中複製以
localhost或127.0.0.1開頭的 URL,然後在瀏覽器的網址列中輸入。建立新的筆記本:在 JupyterLab 中,單擊 主功能表上的 [檔案 > 新 > 筆記本 ],選取 [Python 3][ipykernel], 然後按兩下 [ 選取]。
在筆記本的第一個數據格中,輸入 範例程式代碼 或您自己的程序代碼。 如果您使用自己的程式代碼,您至少必須具現化 實例
SparkSession.builder.getOrCreate(),如範例程式 代碼所示。若要執行筆記本,請按兩下 [ 執行 > 所有儲存格]。
若要偵錯筆記本,請按下筆記本工具列中 Python 3 (ipykernel) 旁的 Bug (啟用調試程式) 圖示。 設定一個或多個斷點,然後按下 執行 > 執行所有單元。
若要關閉 JupyterLab,請按兩下 [ 檔案 > 關機]。 如果 JupyterLab 進程仍在終端機或命令提示字元中執行,請按
Ctrl + c,然後輸入y以確認來停止此程式。
如需更具體的偵錯指示,請參閱 調試程式。
傳統 Jupyter Notebook
注意
開始使用 Databricks Connect 之前,您必須先 符合需求 ,並 設定 Databricks Connect 的用戶端 。
Databricks Connect 的組態腳本會自動將套件新增至專案組態。 若要開始使用 Python 核心,請執行:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
若要啟用執行和視覺化 SQL 查詢的 %sql 簡寫,請使用下列程式碼片段:
from IPython.core.magic import line_magic, line_cell_magic, Magics, magics_class
@magics_class
class DatabricksConnectMagics(Magics):
@line_cell_magic
def sql(self, line, cell=None):
if cell and line:
raise ValueError("Line must be empty for cell magic", line)
try:
from autovizwidget.widget.utils import display_dataframe
except ImportError:
print("Please run `pip install autovizwidget` to enable the visualization widget.")
display_dataframe = lambda x: x
return display_dataframe(self.get_spark().sql(cell or line).toPandas())
def get_spark(self):
user_ns = get_ipython().user_ns
if "spark" in user_ns:
return user_ns["spark"]
else:
from pyspark.sql import SparkSession
user_ns["spark"] = SparkSession.builder.getOrCreate()
return user_ns["spark"]
ip = get_ipython()
ip.register_magics(DatabricksConnectMagics)
Visual Studio Code
注意
開始使用 Databricks Connect 之前,您必須先 符合需求 ,並 設定 Databricks Connect 的用戶端 。
若要使用 Databricks Connect 與 Visual Studio Code,請執行下列動作:
確認 已安裝 Python 延伸模組 。
開啟命令選擇區 (macOS 上的 Command+Shift+P 和 Windows/Linux 上的 Ctrl+Shift+P )。
選取 Python 解譯器。 移至 [ 程序代碼 > 喜好 > 設定設定],然後選擇 [Python 設定]。
執行
databricks-connect get-jar-dir。將命令傳回的目錄添加到
python.venvPath用戶設定 JSON 之下。 這應該新增至 Python 組態。停用linter。 按下右側的 ... 並 編輯 json 設定。 修改過的設定如下所示:
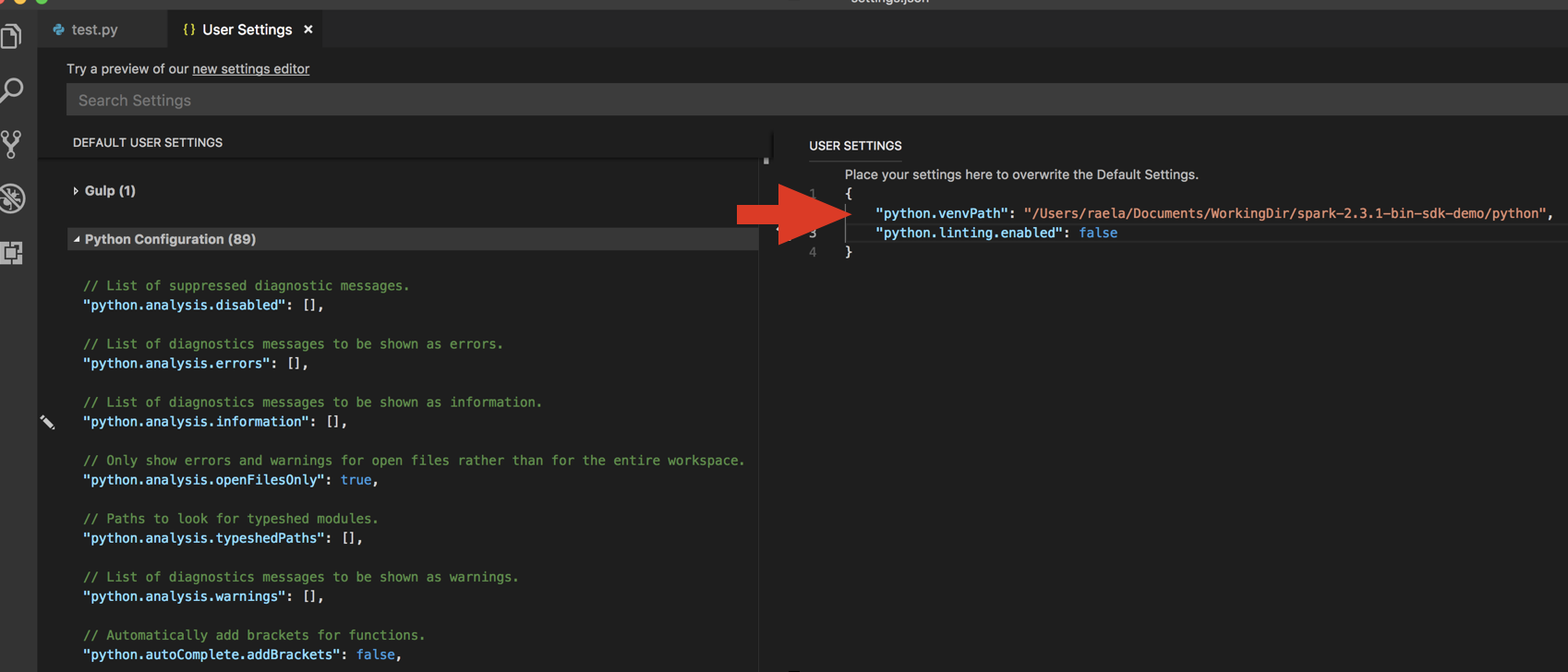
如果使用虛擬環境執行,這是針對 Python 在 VS Code 中開發的建議方式,請在命令面板中輸入
select python interpreter,並指向符合您叢集 Python 版本的環境。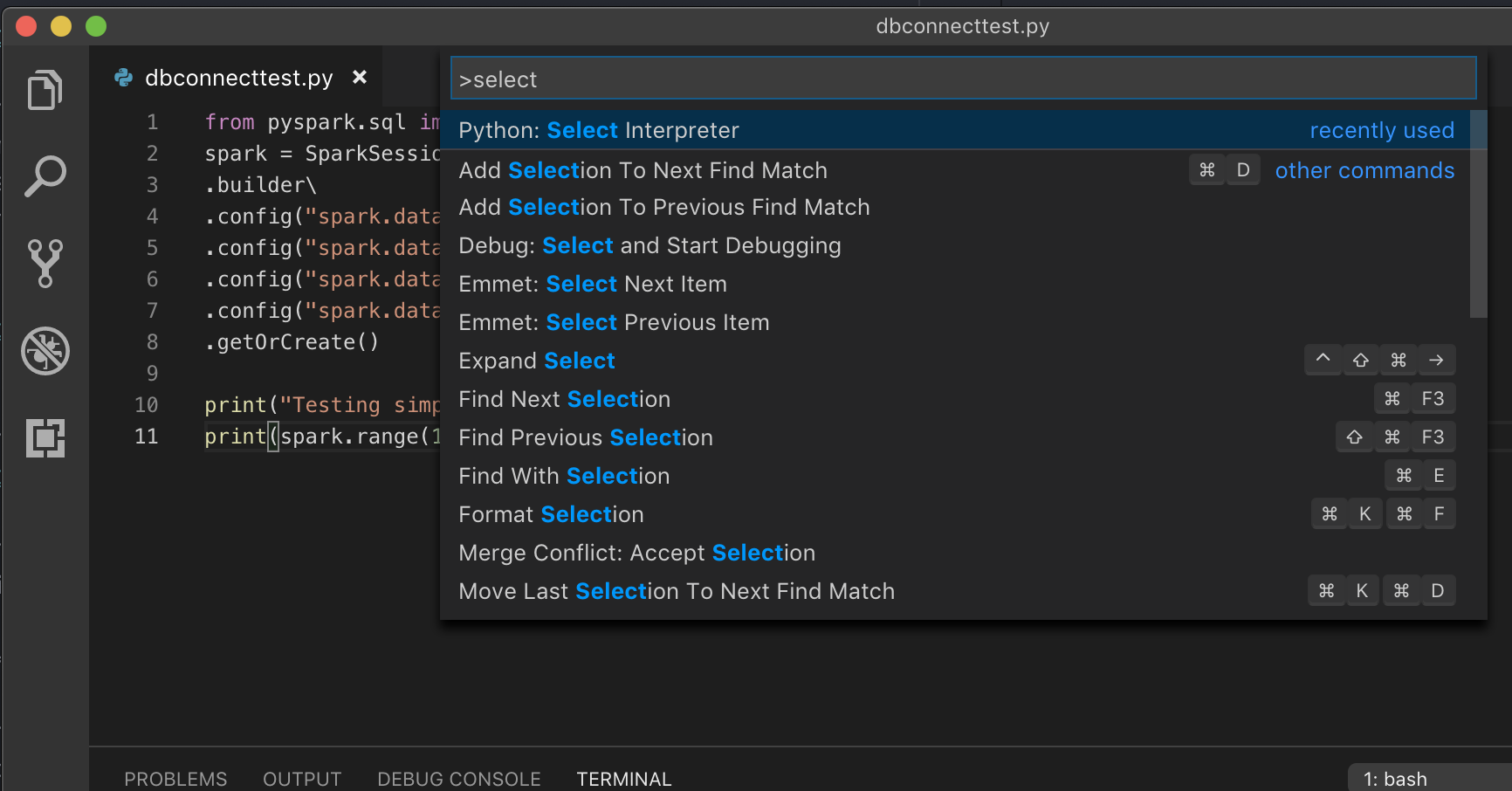
例如,如果您的叢集是 Python 3.9,您的開發環境應該是 Python 3.9。
PyCharm
注意
開始使用 Databricks Connect 之前,您必須先 符合需求 ,並 設定 Databricks Connect 的用戶端 。
Databricks Connect 的組態腳本會自動將套件新增至專案組態。
Python 3 叢集
當您建立 PyCharm 專案時,請選取 [現有解釋器]。 從下拉功能表中,選取您建立的 Conda 環境(請參閱 需求)。
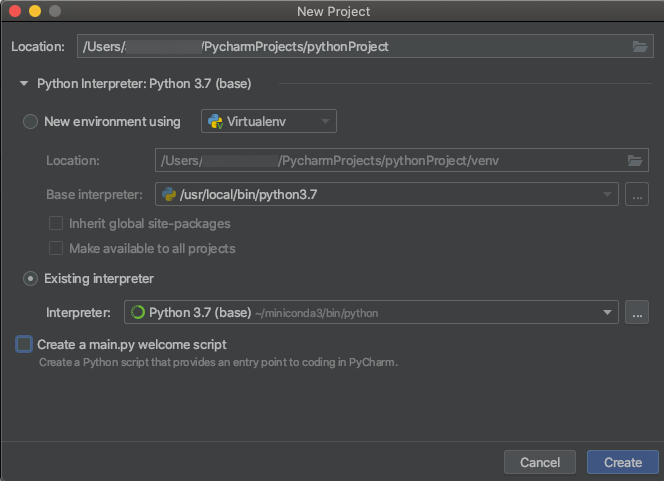
移至 [ 執行 > 編輯組態]。
新增
PYSPARK_PYTHON=python3為環境變數。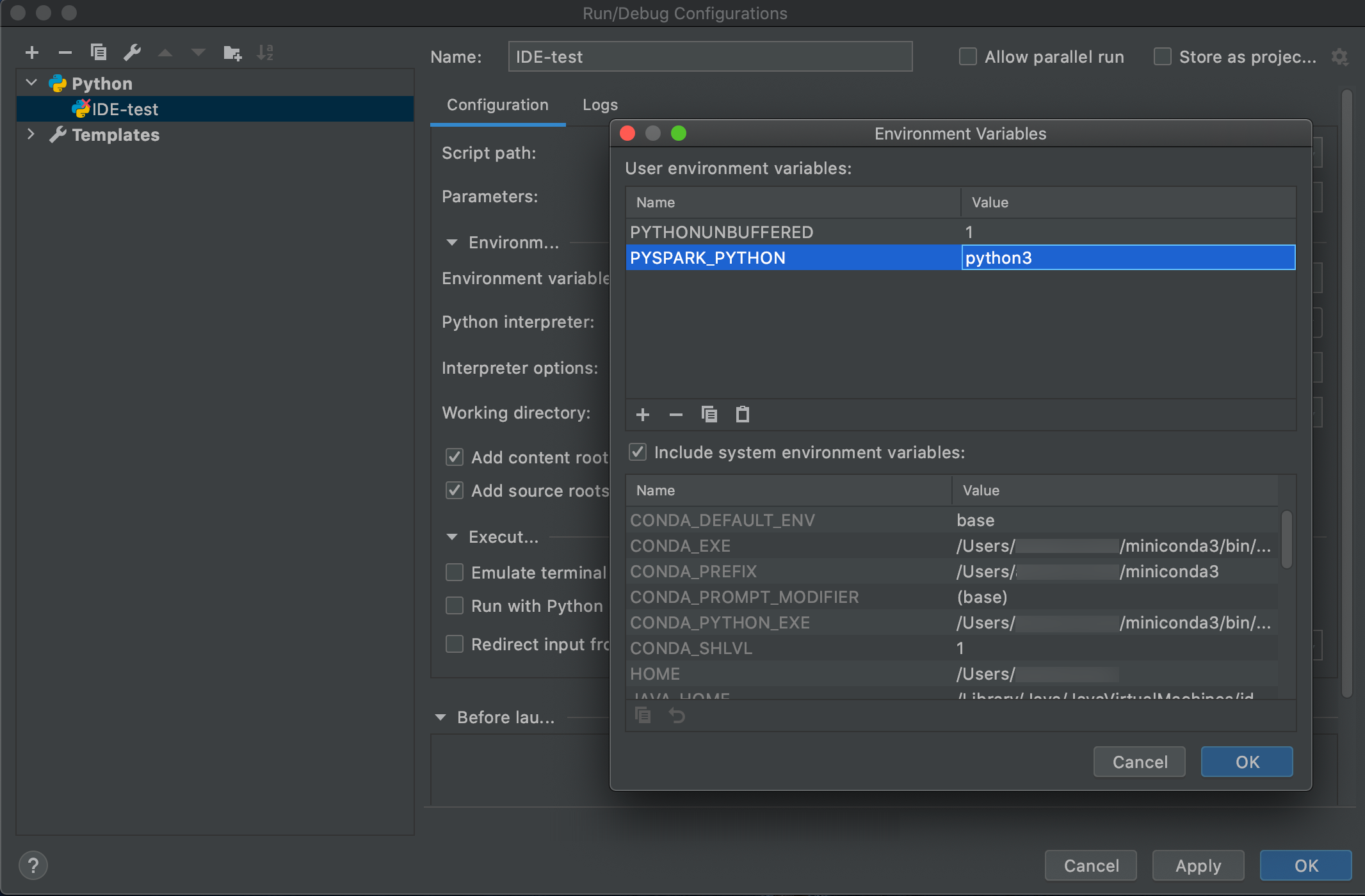
SparkR 和 RStudio Desktop
注意
開始使用 Databricks Connect 之前,您必須先 符合需求 ,並 設定 Databricks Connect 的用戶端 。
若要使用 Databricks Connect 與 SparkR 和 RStudio Desktop,請執行下列動作:
將開放原始碼Spark散發套件下載到您的開發電腦上,並解壓縮。 選擇與 Azure Databricks 叢集中相同的版本(Hadoop 2.7)。
執行
databricks-connect get-jar-dir。 此命令會傳回類似/usr/local/lib/python3.5/dist-packages/pyspark/jars的路徑。 複製 JAR 目錄檔案路徑上方一個目錄的檔案路徑,例如 ,/usr/local/lib/python3.5/dist-packages/pyspark這是SPARK_HOME目錄。將 Spark 庫路徑和 Spark 主目錄配置到 R 程式碼的頂端。 將
<spark-lib-path>設為您在步驟 1 中解壓縮開放原始碼 Spark 套件的目錄。 從步驟 2 設定<spark-home-path>為 Databricks Connect 目錄。# Point to the OSS package path, e.g., /path/to/.../spark-2.4.0-bin-hadoop2.7 library(SparkR, lib.loc = .libPaths(c(file.path('<spark-lib-path>', 'R', 'lib'), .libPaths()))) # Point to the Databricks Connect PySpark installation, e.g., /path/to/.../pyspark Sys.setenv(SPARK_HOME = "<spark-home-path>")起始 Spark 工作階段並開始執行 SparkR 命令。
sparkR.session() df <- as.DataFrame(faithful) head(df) df1 <- dapply(df, function(x) { x }, schema(df)) collect(df1)
sparklyr 和 RStudio Desktop
注意
開始使用 Databricks Connect 之前,您必須先 符合需求 ,並 設定 Databricks Connect 的用戶端 。
重要
這項功能處於公開預覽狀態。
您可以複製您使用 Databricks Connect 在本機開發的 sparklyr 相依程式代碼,並在 Azure Databricks 筆記本中執行,或在 Azure Databricks 工作區中裝載 RStudio Server,且程式代碼變更最少或沒有任何變更。
本節內容:
需求
- sparklyr 1.2 或更新版本。
- Databricks Runtime 7.3 LTS 或更新版本與相符的 Databricks Connect 版本。
安裝、設定及使用sparklyr
在 RStudio Desktop 中,從 CRAN 安裝 sparklyr 1.2 或更新版本,或從 GitHub 安裝最新的主要版本。
# Install from CRAN install.packages("sparklyr") # Or install the latest master version from GitHub install.packages("devtools") devtools::install_github("sparklyr/sparklyr")在已安裝正確版本的 Databricks Connect 中啟動 Python 環境,並在終端機中執行下列命令以取得
<spark-home-path>:databricks-connect get-spark-home起始 Spark 工作階段並開始執行 sparklyr 命令。
library(sparklyr) sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) library(dplyr) src_tbls(sc) iris_tbl %>% count關閉連線。
spark_disconnect(sc)
資源
如需詳細資訊,請參閱 sparklyr GitHub 自述檔。
如需程式代碼範例,請參閱 sparklyr。
sparklyr 和 RStudio Desktop 限制
不支援下列功能:
- sparklyr 串流 API
- sparklyr ML API
- broom API
- csv_file串行化模式
- spark 提交
IntelliJ (Scala 或 Java)
注意
開始使用 Databricks Connect 之前,您必須先 符合需求 ,並 設定 Databricks Connect 的用戶端 。
若要使用 Databricks Connect 與 IntelliJ (Scala 或 Java),請執行下列動作:
執行
databricks-connect get-jar-dir。將相依性指向從 命令傳回的目錄。 移至 [檔案 > 專案結構 > 模組 > 相依性 > '+' 符號 > JAR 或目錄。
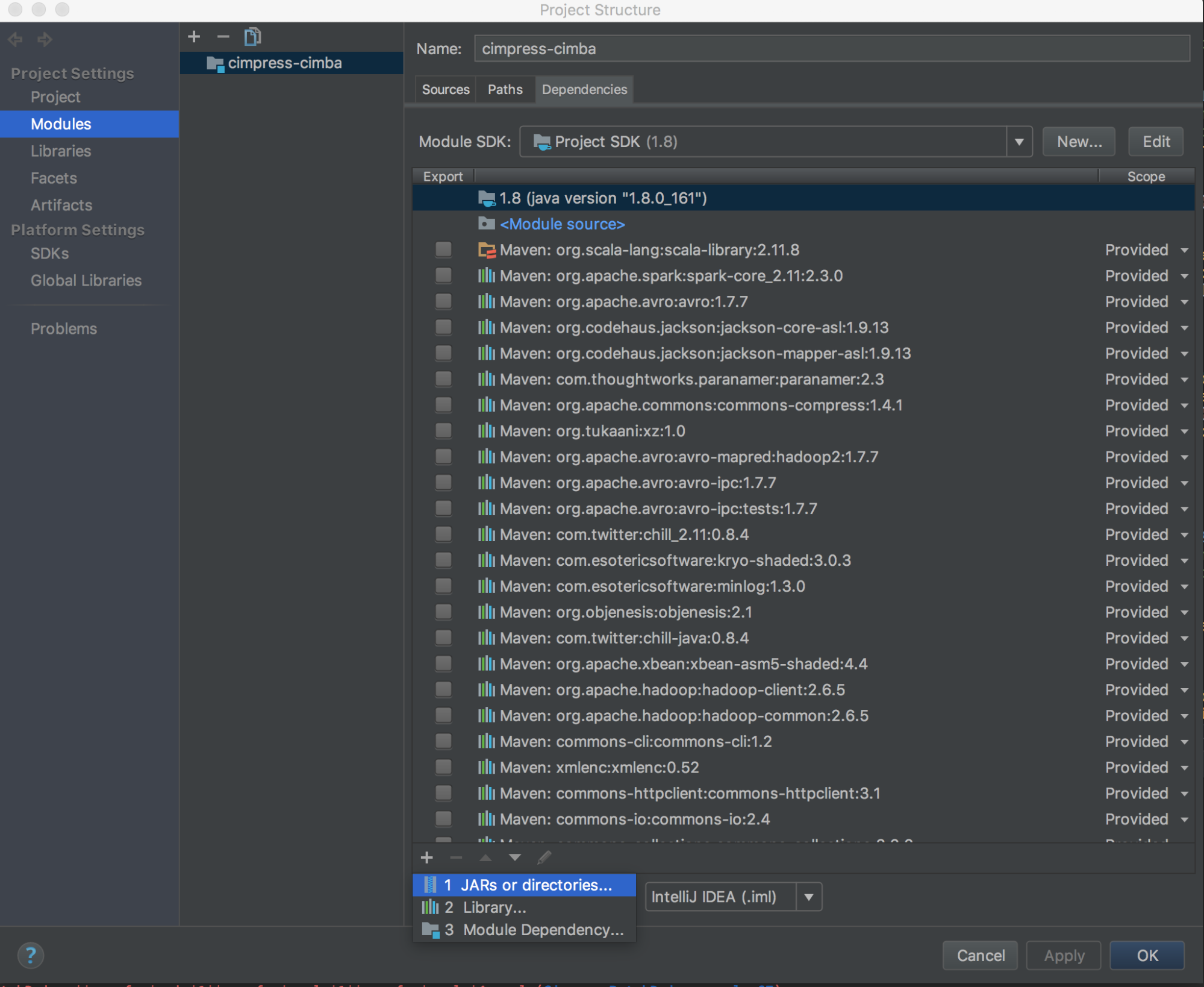
為避免衝突,我們強烈建議從您的 classpath 移除任何其他 Spark 安裝。 如果無法這樣做,請確定您新增的 JAR 位於 classpath 的前面。 特別是,它們必須優於任何其他已安裝的 Spark 版本(否則您會使用其中一個其他 Spark 版本在本機執行,或者會引發
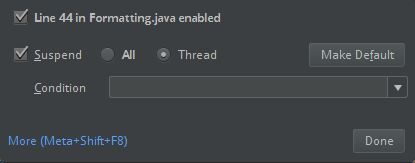
ClassDefNotFoundError)。檢查 IntelliJ 中分解選項的設定。 預設為 All,如果您在偵錯時設定斷點,可能導致網路逾時。 將它設定為 Thread ,以避免停止背景網路線程。
PyDev 與 Eclipse
注意
開始使用 Databricks Connect 之前,您必須先 符合需求 ,並 設定 Databricks Connect 的用戶端 。
若要搭配 Eclipse 使用 Databricks Connect 和 PyDev,請遵循這些指示。
- 啟動 Eclipse。
- 創建專案:按一下 檔案 > 新增 > 專案 > PyDev > PyDev 專案,然後按 下一步。
- 指定 項目名稱。
- 針對 [項目內容],指定 Python 虛擬環境的路徑。
- 請按在繼續之前請設定解釋器。
- 按兩下 [ 手動設定]。
- 按兩下 [ 新增 > 瀏覽 python/pypy exe]。
- 流覽到並選取虛擬環境所參考的 Python 解釋器的完整路徑,然後按一下 [開啟]。
- 在 [ 選取解釋器] 對話框中,按兩下 [ 確定]。
- 在需要選取 對話框中,按一下確定。
- 在 [ 喜好設定 ] 對話框中,按兩下 [ 套用並關閉]。
- 在 [PyDev 專案 ] 對話框中,按兩下 [ 完成]。
- 按一下 [ 開啟透視圖]。
- 將 Python 程式代碼 (
.py) 檔案新增至專案,其中包含 範例程式代碼或您自己的程式代碼 。 如果您使用自己的程式代碼,您至少必須具現化 實例SparkSession.builder.getOrCreate(),如範例程式 代碼所示。 - 開啟 Python 程式代碼檔案後,設定您希望程式代碼在執行時暫停的任何斷點。
- 按一下執行>執行或執行>除錯。
如需更具體的執行和偵錯指示,請參閱 執行程式。
Eclipse
注意
開始使用 Databricks Connect 之前,您必須先 符合需求 ,並 設定 Databricks Connect 的用戶端 。
若要使用 Databricks Connect 和 Eclipse,請執行下列動作:
執行
databricks-connect get-jar-dir。將外部 JAR 組態指向從 命令傳回的目錄。 移至 [專案] 功能表 > [屬性] > [Java 建置路徑] > [庫] > [新增外部 JAR]。
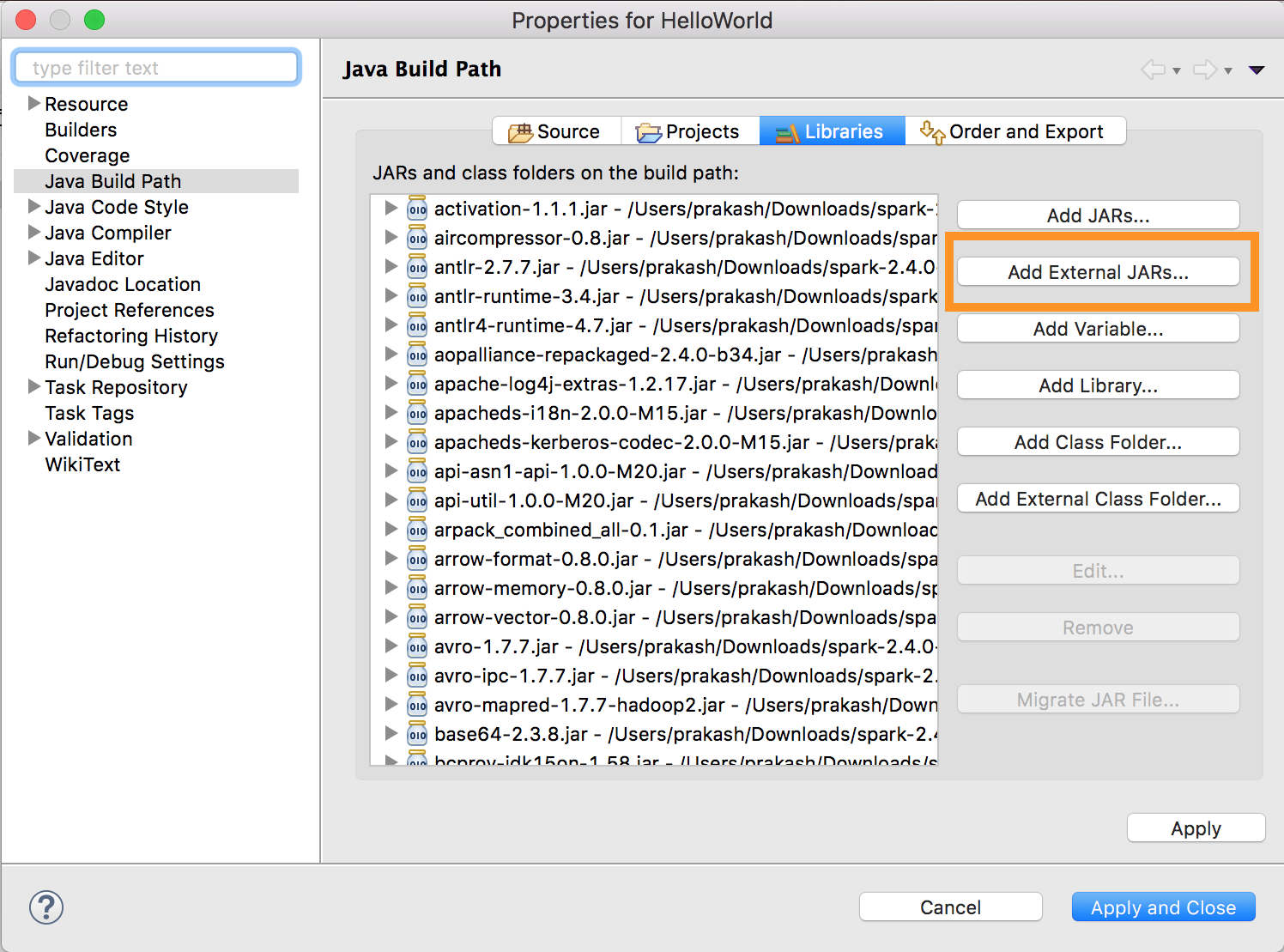
為避免衝突,我們強烈建議從您的 classpath 移除任何其他 Spark 安裝。 如果無法這樣做,請確定您新增的 JAR 位於 classpath 的前面。 特別是,它們必須優於任何其他已安裝的 Spark 版本(否則您會使用其中一個其他 Spark 版本在本機執行,或者會引發
ClassDefNotFoundError)。
SBT
注意
開始使用 Databricks Connect 之前,您必須先 符合需求 ,並 設定 Databricks Connect 的用戶端 。
若要搭配 SBT 使用 Databricks Connect,您必須設定您的 build.sbt 檔案,以連結至 Databricks Connect JARs,而非一般的 Spark 函式庫相依性。 您可以使用下列範例組建檔案中的 指示詞來執行此 unmanagedBase 動作,其假設 Scala 應用程式具有 com.example.Test 主要物件:
build.sbt
name := "hello-world"
version := "1.0"
scalaVersion := "2.11.6"
// this should be set to the path returned by ``databricks-connect get-jar-dir``
unmanagedBase := new java.io.File("/usr/local/lib/python2.7/dist-packages/pyspark/jars")
mainClass := Some("com.example.Test")
Spark 命令列介面
注意
開始使用 Databricks Connect 之前,您必須先 符合需求 ,並 設定 Databricks Connect 的用戶端 。
若要使用 Databricks Connect 搭配 Spark 殼層和 Python 或 Scala,請遵循這些指示。
啟用虛擬環境后,請確定
databricks-connect test命令已在 [設定用戶端] 中順利執行。啟動虛擬環境後,激活 Spark 殼層。 針對 Python,執行
pyspark命令。 針對 Scala,執行spark-shell命令。# For Python: pyspark# For Scala: spark-shellSpark 命令列介面會隨即出現,舉例來說,例如 Python:
Python 3... (v3...) [Clang 6... (clang-6...)] on darwin Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.... /_/ Using Python version 3... (v3...) Spark context Web UI available at http://...:... Spark context available as 'sc' (master = local[*], app id = local-...). SparkSession available as 'spark'. >>>針對 Scala:
Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3... /_/ Using Scala version 2... (OpenJDK 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala>如需瞭解如何使用 Spark 殼層搭配 Python 或 Scala 在叢集上執行命令的詳細資訊,請參閱互動式分析與 Spark 殼層。
使用內建的
spark變數來代表您執行中的叢集上的SparkSession,例如:Python。>>> df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rows針對 Scala:
>>> val df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rows若要停止 Spark shell,請按
Ctrl + d或Ctrl + z,或執行命令quit()或exit()以停止 Python,或:q或:quit以停止 Scala。
程式代碼範例
這個簡單的程式代碼範例會查詢指定的數據表,然後顯示指定的數據表的前 5 個數據列。 若要使用不同的數據表,請調整 對 spark.read.table的呼叫。
from pyspark.sql.session import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
這個較長的程式代碼範例會執行下列動作:
- 建立記憶體內部 DataFrame。
- 在
zzz_demo_temps_table架構中使用名稱default建立資料表。 如果已有這個名稱的數據表存在,則會先刪除數據表。 若要使用不同的架構或數據表,請調整對spark.sql、temps.write.saveAsTable或兩者的呼叫。 - 將 DataFrame 的內容儲存至數據表。
- 在數據表的內容上執行
SELECT查詢。 - 顯示查詢的結果。
- 刪除資料表。
Python
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from datetime import date
spark = SparkSession.builder.appName('temps-demo').getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
程式語言 Scala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import java.sql.Date
object Demo {
def main(args: Array[String]) {
val spark = SparkSession.builder.master("local").getOrCreate()
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
val schema = StructType(Array(
StructField("AirportCode", StringType, false),
StructField("Date", DateType, false),
StructField("TempHighF", IntegerType, false),
StructField("TempLowF", IntegerType, false)
))
val data = List(
Row("BLI", Date.valueOf("2021-04-03"), 52, 43),
Row("BLI", Date.valueOf("2021-04-02"), 50, 38),
Row("BLI", Date.valueOf("2021-04-01"), 52, 41),
Row("PDX", Date.valueOf("2021-04-03"), 64, 45),
Row("PDX", Date.valueOf("2021-04-02"), 61, 41),
Row("PDX", Date.valueOf("2021-04-01"), 66, 39),
Row("SEA", Date.valueOf("2021-04-03"), 57, 43),
Row("SEA", Date.valueOf("2021-04-02"), 54, 39),
Row("SEA", Date.valueOf("2021-04-01"), 56, 41)
)
val rdd = spark.sparkContext.makeRDD(data)
val temps = spark.createDataFrame(rdd, schema)
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default")
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table")
temps.write.saveAsTable("zzz_demo_temps_table")
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
val df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC")
df_temps.show()
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table")
}
}
JAVA
import java.util.ArrayList;
import java.util.List;
import java.sql.Date;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.Dataset;
public class App {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("Temps Demo")
.config("spark.master", "local")
.getOrCreate();
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
StructType schema = new StructType(new StructField[] {
new StructField("AirportCode", DataTypes.StringType, false, Metadata.empty()),
new StructField("Date", DataTypes.DateType, false, Metadata.empty()),
new StructField("TempHighF", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("TempLowF", DataTypes.IntegerType, false, Metadata.empty()),
});
List<Row> dataList = new ArrayList<Row>();
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-03"), 52, 43));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-02"), 50, 38));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-01"), 52, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-03"), 64, 45));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-02"), 61, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-01"), 66, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-03"), 57, 43));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-02"), 54, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-01"), 56, 41));
Dataset<Row> temps = spark.createDataFrame(dataList, schema);
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default");
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table");
temps.write().saveAsTable("zzz_demo_temps_table");
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
Dataset<Row> df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC");
df_temps.show();
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table");
}
}
處理相依性
一般而言,您的主要類別或 Python 檔案會有其他相依性 JAR 和檔案。 您可以呼叫 sparkContext.addJar("path-to-the-jar") 或 sparkContext.addPyFile("path-to-the-file")來新增這類相依性 JAR 和檔案。 您也可以使用 addPyFile() 介面新增 Egg 檔案和 zip 檔案。 每次在 IDE 中執行程式代碼時,相依性 JAR 和檔案都會安裝在叢集上。
Python
from lib import Foo
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
#sc.setLogLevel("INFO")
print("Testing simple count")
print(spark.range(100).count())
print("Testing addPyFile isolation")
sc.addPyFile("lib.py")
print(sc.parallelize(range(10)).map(lambda i: Foo(2)).collect())
class Foo(object):
def __init__(self, x):
self.x = x
Python + Java UDF
from pyspark.sql import SparkSession
from pyspark.sql.column import _to_java_column, _to_seq, Column
## In this example, udf.jar contains compiled Java / Scala UDFs:
#package com.example
#
#import org.apache.spark.sql._
#import org.apache.spark.sql.expressions._
#import org.apache.spark.sql.functions.udf
#
#object Test {
# val plusOne: UserDefinedFunction = udf((i: Long) => i + 1)
#}
spark = SparkSession.builder \
.config("spark.jars", "/path/to/udf.jar") \
.getOrCreate()
sc = spark.sparkContext
def plus_one_udf(col):
f = sc._jvm.com.example.Test.plusOne()
return Column(f.apply(_to_seq(sc, [col], _to_java_column)))
sc._jsc.addJar("/path/to/udf.jar")
spark.range(100).withColumn("plusOne", plus_one_udf("id")).show()
程式語言 Scala
package com.example
import org.apache.spark.sql.SparkSession
case class Foo(x: String)
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
...
.getOrCreate();
spark.sparkContext.setLogLevel("INFO")
println("Running simple show query...")
spark.read.format("parquet").load("/tmp/x").show()
println("Running simple UDF query...")
spark.sparkContext.addJar("./target/scala-2.11/hello-world_2.11-1.0.jar")
spark.udf.register("f", (x: Int) => x + 1)
spark.range(10).selectExpr("f(id)").show()
println("Running custom objects query...")
val objs = spark.sparkContext.parallelize(Seq(Foo("bye"), Foo("hi"))).collect()
println(objs.toSeq)
}
}
存取 Databricks 公用程式
本節說明如何使用 Databricks Connect 來存取 Databricks 公用程式。
您可以使用 dbutils.fs 和 dbutils.secrets 公用程式,這些是 Databricks Utilities (dbutils) 參考模組的一部分。
支援的指令包括dbutils.fs.cp、、dbutils.fs.headdbutils.fs.lsdbutils.fs.mkdirsdbutils.fs.mvdbutils.fs.put、dbutils.fs.rm、dbutils.secrets.get、、、、 。 dbutils.secrets.getBytesdbutils.secrets.listdbutils.secrets.listScopes
請參閱 檔案系統公用程式 (dbutils.fs) 或 run dbutils.fs.help() 和 Secrets 公用程式 (dbutils.secrets) 或執行 dbutils.secrets.help()。
Python
from pyspark.sql import SparkSession
from pyspark.dbutils import DBUtils
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
print(dbutils.fs.ls("dbfs:/"))
print(dbutils.secrets.listScopes())
使用 Databricks Runtime 7.3 LTS 或更新版本時,若要在本機和 Azure Databricks 叢集中均可運作地存取 DBUtils 模組,請使用下列指令 get_dbutils():
def get_dbutils(spark):
from pyspark.dbutils import DBUtils
return DBUtils(spark)
否則,請使用下列 get_dbutils():
def get_dbutils(spark):
if spark.conf.get("spark.databricks.service.client.enabled") == "true":
from pyspark.dbutils import DBUtils
return DBUtils(spark)
else:
import IPython
return IPython.get_ipython().user_ns["dbutils"]
程式語言 Scala
val dbutils = com.databricks.service.DBUtils
println(dbutils.fs.ls("dbfs:/"))
println(dbutils.secrets.listScopes())
在本機和遠端檔案系統之間複製檔案
您可以使用 dbutils.fs 在用戶端與遠端檔案系統之間複製檔案。 方案 file:/ 是指客戶端上的本地檔案系統。
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark)
dbutils.fs.cp('file:/home/user/data.csv', 'dbfs:/uploads')
dbutils.fs.cp('dbfs:/output/results.csv', 'file:/home/user/downloads/')
可透過該方式傳輸的檔案大小上限為 250 MB。
啟用 dbutils.secrets.get
由於安全性限制,預設會停用呼叫 dbutils.secrets.get 的能力。 請連絡 Azure Databricks 支持人員,為您的工作區啟用此功能。
設定Hadoop組態
在用戶端上,您可以使用適用於 SQL 和 DataFrame 作業的 spark.conf.set API 來設定 Hadoop 組態。 必須將sparkContext 上設定的 Hadoop 組態,設定在叢集組態或筆記本中。 這是因為上 sparkContext 設定的組態不會系結至用戶會話,但會套用至整個叢集。
疑難排解
執行 databricks-connect test 以檢查連線問題。 本節說明您在 Databricks Connect 中可能會遇到的一些常見問題,以及如何加以解決。
本節內容:
- Python 版本不符
- 伺服器未啟用
- 相互衝突的 PySpark 安裝
-
衝突
SPARK_HOME -
二進位程式的衝突或遺漏項目
PATH - 叢集上的串行化設定衝突
-
在 Windows 上找不到
winutils.exe - Windows 上的檔名、目錄名稱或磁碟區標籤法不正確
Python 版本不一致
檢查您在本機使用的 Python 版本,至少具有與叢集上版本相同的次要版本(例如, 3.9.16 相較於 3.9.15 是 OK, 3.9 與 3.8 不是)。
如果您在本機安裝多個 Python 版本,請藉由設定 PYSPARK_PYTHON 環境變數 (例如, PYSPARK_PYTHON=python3) 確定 Databricks Connect 使用正確的版本。
伺服器未啟用
確定叢集已啟用 Spark 伺服器。spark.databricks.service.server.enabled true 如果是,您應該會在驅動程序記錄中看到下列幾行:
../../.. ..:..:.. INFO SparkConfUtils$: Set spark config:
spark.databricks.service.server.enabled -> true
...
../../.. ..:..:.. INFO SparkContext: Loading Spark Service RPC Server
../../.. ..:..:.. INFO SparkServiceRPCServer:
Starting Spark Service RPC Server
../../.. ..:..:.. INFO Server: jetty-9...
../../.. ..:..:.. INFO AbstractConnector: Started ServerConnector@6a6c7f42
{HTTP/1.1,[http/1.1]}{0.0.0.0:15001}
../../.. ..:..:.. INFO Server: Started @5879ms
有衝突的 PySpark 安裝
套件 databricks-connect 與 PySpark 衝突。 在 Python 中初始化 Spark 內容時,安裝這兩者會造成錯誤。 這可以透過數種方式來顯示,包括「數據流損毀」或「找不到類別」錯誤。 如果您已在 Python 環境中安裝 PySpark,請確定它已卸載,再安裝 databricks-connect。 卸載 PySpark 之後,請務必完全重新安裝 Databricks Connect 套件:
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==12.2.*" # or X.Y.* to match your specific cluster version.
衝突 SPARK_HOME
如果您先前已在計算機上使用Spark,IDE可能會設定為使用其中一個其他版本的Spark,而不是 Databricks Connect Spark。 這可以透過數種方式來顯示,包括「數據流損毀」或「找不到類別」錯誤。 您可以藉由檢查環境變數的值 SPARK_HOME 來查看正在使用哪一個 Spark 版本:
Python
import os
print(os.environ['SPARK_HOME'])
程式語言 Scala
println(sys.env.get("SPARK_HOME"))
JAVA
System.out.println(System.getenv("SPARK_HOME"));
解決方法
如果 SPARK_HOME 設定為用戶端中 Spark 以外的版本,您應該取消設定 SPARK_HOME 變數,然後再試一次。
檢查 IDE 環境變數設定、您的 .bashrc、 .zshrc或 .bash_profile 檔案,以及可能設定的任何其他環境變數。 您很可能必須結束並重新啟動 IDE 以清除舊狀態,而且如果問題持續發生,您甚至可能需要建立新的專案。
您不應該將 SPARK_HOME 設定為新值,解除設定應該就足夠了。
二進位檔的衝突或遺漏 PATH 項目
您可以設定PATH,讓類似的 spark-shell 命令執行其他先前安裝的二進位檔,而不是 Databricks Connect 所提供的二進位檔。 這可能會導致 databricks-connect test 失敗。 您應該確保優先使用 Databricks Connect 二進位檔,或移除先前安裝的其他二進位檔。
如果您無法執行像spark-shell這樣的命令,也可能是pip3 install無法自動設定您的PATH,因此您必須手動將安裝目錄bin新增至您的PATH。 即使沒有設定,仍然可以使用 Databricks Connect 和 IDE。 不過, databricks-connect test 命令將無法運作。
叢集上的序列化設定衝突
如果您在執行 databricks-connect test時看到「數據流損毀」錯誤,這可能是因為叢集串行化設定不相容。 例如,設定 spark.io.compression.codec 設定可能會導致此問題。 若要解決此問題,請考慮從叢集設定中移除這些設定,或在 Databricks Connect 用戶端中設定組態。
在 Windows 上找不到winutils.exe
如果您在 Windows 上使用 Databricks Connect,請參閱:
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
請遵循指示在 Windows 上設定 Hadoop 路徑。
Windows 上的檔名、目錄名稱或磁碟區標籤法不正確
如果您使用 Windows 和 Databricks Connect,請參閱:
The filename, directory name, or volume label syntax is incorrect.
Java 或 Databricks Connect 是安裝在含有空格的路徑目錄中。 您可以藉由安裝至不含空格的目錄路徑,或使用簡短名稱格式來設定路徑,來解決此問題。
使用 Microsoft Entra 識別碼令牌進行驗證
注意
下列資訊僅適用於 Databricks Connect 7.3.5 到 12.2.x 版。
Databricks Connect for Databricks Runtime 13.3 LTS 和更新版本目前不支援Microsoft Entra ID 令牌。
當您使用 Databricks Connect 7.3.5 到 12.2.x 版時,您可以使用 Microsoft Entra ID 令牌進行驗證,而不是使用個人存取令牌。 Microsoft Entra 標識符令牌的存留期有限。 當Microsoft Entra ID 令牌過期時,Databricks Connect 會失敗並出現 Invalid Token 錯誤。
針對 Databricks Connect 7.3.5 到 12.2.x 版,您可以在執行中的 Databricks Connect 應用程式中提供Microsoft Entra ID 令牌。 您的應用程式必須取得新的存取令牌,並將其設定為 spark.databricks.service.token SQL 組態密鑰。
Python
spark.conf.set("spark.databricks.service.token", new_aad_token)
程式語言 Scala
spark.conf.set("spark.databricks.service.token", newAADToken)
更新令牌之後,應用程式可以繼續使用會話上下文中建立的相同 SparkSession 和任何物件及狀態。 為避免間歇性錯誤,Databricks 建議您在舊令牌到期之前提供新的令牌。
您可以延長Microsoft Entra ID 令牌的存留期,以在應用程式執行期間保存。 若要這樣做,請將 具有適當長存留期的 TokenLifetimePolicy 附加至您用來取得存取令牌的 Microsoft Entra ID 授權應用程式。
注意
Microsoft Entra ID 傳遞機制使用兩個令牌:之前描述的 Microsoft Entra ID 存取令牌,該令牌在 Databricks Connect 7.3.5 版至 12.2.x 版中設定,以及 Databricks 在處理請求時為特定資源生成的 ADLS 傳遞令牌。 您無法使用 Microsoft Entra ID 令牌有效期限原則來延長 ADLS 傳遞令牌的有效期限。 如果您將命令傳送至超過一小時的叢集,如果命令在一小時後存取 ADLS 資源,就會失敗。
限制
- 結構化串流。
- 在遠端叢集上執行不屬於 Spark 作業的任意程式代碼。
- 不支援 Delta 資料表作業的原生 Scala、Python 和 R API,例如
DeltaTable.forPath。 不過,SQL API(spark.sql(...))與涵蓋 Delta Lake 作業的 Spark API(例如,spark.read.load)皆支持對 Delta 數據表進行操作。 - 複製到 。
- 使用屬於伺服器目錄一部分的 SQL 函式、Python 或 Scala UDF。 不過,在本機環境中引入的 Scala 和 Python UDF 運作正常。
- Apache Zeppelin 0.7.x 和以下版本。
- 使用 資料表訪問控制連線到叢集。
- 聯機到已啟用進程隔離的叢集(換句話說,其中
spark.databricks.pyspark.enableProcessIsolation設定為true)。 - Delta
CLONESQL 命令。 - 全域暫存視圖。
-
考拉和
pyspark.pandas。 -
CREATE TABLE table AS SELECT ...SQL 命令不一定會運作。 請改用spark.sql("SELECT ...").write.saveAsTable("table")。
- Microsoft Entra ID 憑證傳遞僅在執行 Databricks Runtime 7.3 LTS 和更新版本的標準叢集中受支援,且不與服務主體驗證相容。
- 下列 Databricks 工具(
dbutils)參考資料: