本教學課程示範如何使用 IntelliJ IDEA 和 Scala 外掛程式開始使用 Databricks Connect for Scala。
在本教學課程中,您會在 IntelliJ IDEA 中建立專案、安裝 Databricks Connect for Databricks Runtime 13.3 LTS 和更新版本,並從 IntelliJ IDEA 在您的 Databricks 工作區中執行簡單的程式代碼。
小提示
想了解如何使用 Declarative Automation Bundles 來建立一個在無伺服器運算上執行程式碼的 Scala 專案,請參見 「使用 Declarative Automation Bundles 建構 Scala JAR」。
需求
您必須滿足下列需求,才能完成本教學課程:
您的工作區、本機環境和計算符合 Databricks Connect for Scala 的需求。 請參閱 Databricks Connect 使用需求。
您必須準備好叢集識別碼。 若要取得集群ID,請在工作區側邊欄中點擊 計算,然後點擊您的集群名稱。 在您的網頁瀏覽器的網址列中,複製URL中
clusters和configuration之間的字元字串。您已在開發電腦上安裝 Java 開發工具套件 (JDK)。 如需要安裝的版本的相關資訊,請參閱 版本支援對照表。
備註
如果您沒有安裝 JDK,或在開發電腦上安裝多個 JDK,您可以在步驟 1 稍後安裝或選擇特定的 JDK。 選擇一個 JDK 安裝,其版本低於或高於您叢集上的 JDK 版本,可能會導致不預期的結果,甚至您的程式代碼可能完全無法執行。
您已安裝 IntelliJ IDEA 。 本教學課程已使用 IntelliJ IDEA Community Edition 2023.3.6 進行測試。 如果您使用不同版本的 IntelliJ IDEA,下列指示可能會有所不同。
您已安裝適用於 IntelliJ IDEA 的 Scala 外掛程式 。
步驟 1:設定 Azure Databricks 驗證
本教學課程使用 Azure Databricks OAuth 使用者對機器 (U2M) 驗證和 Azure Databricks 組態配置檔,以向 Azure Databricks 工作區進行驗證。 若要改用不同的驗證類型,請參閱 設定連線屬性。
設定 OAuth U2M 驗證需要 Databricks CLI,如下所示:
安裝 Databricks 的 CLI:
Linux、macOS
使用 Homebrew 透過執行以下指令安裝 Databricks CLI:
brew tap databricks/tap brew trust databricks/tap brew install databricks窗戶
您可以使用 winget、Chocolatey 或 Windows 子系統 Linux 版 (WSL) 來安裝 Databricks CLI。 如果您無法使用
winget、Chocolatey 或 WSL,您應該略過此步驟,然後使用命令提示字元或 PowerShell 來從來源安裝 Databricks CLI。備註
使用 Chocolatey 安裝 Databricks CLI 是 實驗性的。
若要使用
winget來安裝 Databricks CLI,請執行下列兩個命令,然後重新啟動命令提示字元:winget search databricks winget install Databricks.DatabricksCLI若要使用 Chocolatey 安裝 Databricks CLI,請執行下列命令:
choco install databricks-cli若要使用 WSL 來安裝 Databricks CLI:
透過 WSL 安裝
curl和zip。 如需詳細資訊,請參閱作業系統的文件。執行下列命令,使用 WSL 安裝 Databricks CLI:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
執行下列命令來確認已安裝 Databricks CLI,其中顯示已安裝 Databricks CLI 的目前版本。 此版本應該是 0.205.0 或更新版本:
databricks -v
起始 OAuth U2M 驗證,如下所示:
使用 Databricks CLI 在本地端啟動 OAuth 權杖管理,針對每個目標工作區執行以下命令。
在下列命令中,將
<workspace-url>替換成 您的 Azure Databricks 個別工作區的 URL,例如https://adb-1234567890123456.7.azuredatabricks.net。databricks auth login --configure-cluster --host <workspace-url>Databricks CLI 會提示您將輸入的資訊儲存為 Azure Databricks 設定檔。 按
Enter以接受建議的設定檔名稱,或輸入新或現有設定檔的名稱。 任何具有相同名稱的現有設定檔,會被您輸入的資訊覆蓋。 您可以使用個人檔案,在多個工作區之間快速切換您的驗證環境。若要取得任何現有設定檔的清單,請在個別的終端機或命令提示字元中,使用 Databricks CLI 來執行
databricks auth profiles命令。 若要檢視特定設定檔的現有設定,請執行 命令databricks auth env --profile <profile-name>。在網頁瀏覽器中,完成畫面上的指示,登入 Azure Databricks 工作區。
在終端機或命令提示字元中顯示的可用叢集清單中,使用向上鍵和向下鍵來選取工作區中的目標 Azure Databricks 叢集,然後按
Enter。 您也可以輸入叢集顯示名稱的任何部分,以篩選可用叢集的清單。若要檢視配置檔目前的 OAuth 令牌值和令牌即將到期的時間戳,請執行下列其中一個命令:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
如果您有多個具有相同
--host值的設定檔,您可能需要一起指定--host和-p選項,以協助 Databricks CLI 尋找正確的相符 OAuth 權杖資訊。
步驟 2:建立專案
啟動 IntelliJ IDEA。
在主功能表上,按一下 檔案 > 新 > 專案。
為您的專案命名一些有意義的 Name。
針對 位置,按資料夾圖示,然後按照螢幕上的指示完成來指定新 Scala 專案的路徑。
針對 Language,點擊 Scala。
針對 建置系統,按一下 [sbt]。
在 [JDK] 下拉式清單中,選取與叢集上 JDK 版本相符的開發電腦上現有的 JDK 安裝,或選取 [下載 JDK,然後依照螢幕上的指示下載符合您叢集上 JDK 版本的 JDK。 請參閱 需求。
備註
選擇比您的叢集上 JDK 版本更高或更低的 JDK 進行安裝可能會產生非預期的結果,或可能導致您的程式無法執行。
在 [sbt] 下拉式清單中,選取最新版本。
在 [Scala] 下拉式清單中,選取與您叢集上 Scala 版本相符的 Scala 版本。 請參閱 需求。
備註
選擇一個比叢集上版本高或低的 Scala 版本,可能會產生非預期的結果,或使您的程式碼無法運行。
請確認在Scala 旁邊的下載來源方塊已被勾選。
針對 套件前綴,輸入一些套件前綴值以用於專案的來源,例如
org.example.application。確定 [新增範例程式碼] 方塊已勾選。
點擊 建立。
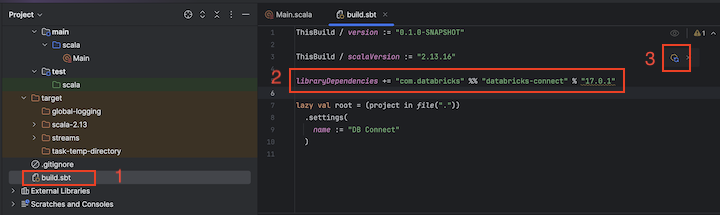
步驟 3:新增 Databricks Connect 套件
開啟新的 Scala 專案後,在 Project 工具視窗(檢視 > 工具視窗 > 專案)中,開啟名為
build.sbt的檔案,位於 專案名稱> 目標。將下列程式代碼新增至檔案結尾
build.sbt,它會宣告專案相依於 Scala 的特定 Databricks Connect 連結庫版本,其與叢集的 Databricks Runtime 版本相容:libraryDependencies += "com.databricks" %% "databricks-connect" % "17.3.+"將
17.3取代為與叢集上 Databricks Runtime 版本相符的 Databricks Connect 連結庫版本。 例如,Databricks Connect 17.3.+ 與 Databricks 的執行環境 17.3 LTS 相符。 你可以在 Maven 中央倉庫(適用於 Databricks Runtime 16.4 LTS 及以下版本) 或 Maven 中央倉庫(適用於 Databricks Runtime 17.0 及以上版本)中找到 Databricks Connect 函式庫的版本號。備註
使用 Databricks Connect 進行建置時,請勿在專案中包含 Apache Spark 元件,例如
org.apache.spark:spark-core。 相反地,請直接針對 Databricks Connect 進行編譯。點擊 載入 sbt 變更 通知圖示,以新的程式庫位置和相依關係更新 Scala 專案。
等到 IDE 底部的
sbt進度指示器消失。sbt載入程式可能需要幾分鐘的時間才能完成。
步驟 4:新增程序代碼
在 Project 工具視窗中,在
Main.scalasrc 中開啟名為 >的檔案,> 主要 > scala。將檔案中的任何現有程式碼替換為下列程式碼,並根據您的組態檔名稱儲存檔案。
如果步驟 1 的設定檔名稱為
DEFAULT,請將檔案中的任何現有程式碼取代為下列程式碼,然後儲存檔案。package org.example.application import com.databricks.connect.DatabricksSession import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = DatabricksSession.builder().remote().getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }如果步驟 1 的組態設定檔未命名
DEFAULT為 ,請改用下列程式代碼取代 檔案中的任何現有程式代碼。 將佔位符<profile-name>替換為步驟 1 的設定檔名稱,然後儲存檔案:package org.example.application import com.databricks.connect.DatabricksSession import com.databricks.sdk.core.DatabricksConfig import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val config = new DatabricksConfig().setProfile("<profile-name>") val spark = DatabricksSession.builder().sdkConfig(config).getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
步驟 5:設定 VM 選項
匯入 IntelliJ 中所在的
build.sbt目前目錄。在 IntelliJ 中選擇 Java 17。 移至 檔案>專案結構>SDK。
開啟
src/main/scala/com/examples/Main.scala。導覽至主要的設定以新增 VM 選項:
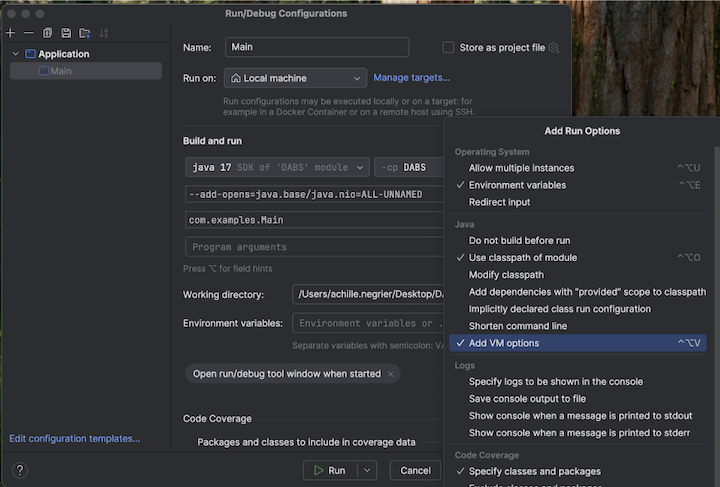
將下列項目新增至您的 VM 選項:
--add-opens=java.base/java.nio=ALL-UNNAMED
小提示
或者,如果您使用 Visual Studio Code,請將下列內容新增至您的 sbt 建置檔案:
fork := true
javaOptions += "--add-opens=java.base/java.nio=ALL-UNNAMED"
然後從終端機運行您的應用程序:
sbt run
步驟 6:執行程式碼
- 在遠端 Azure Databricks 工作區中啟動目標叢集。
- 叢集啟動之後,點擊主功能表上的 執行 > 執行「Main」。
- 在 [執行 工具] 視窗中([檢視 > 工具視窗 > 執行]),於 [主要] 索引標籤上,
samples.nyctaxi.trips表格的前 5 列顯示。
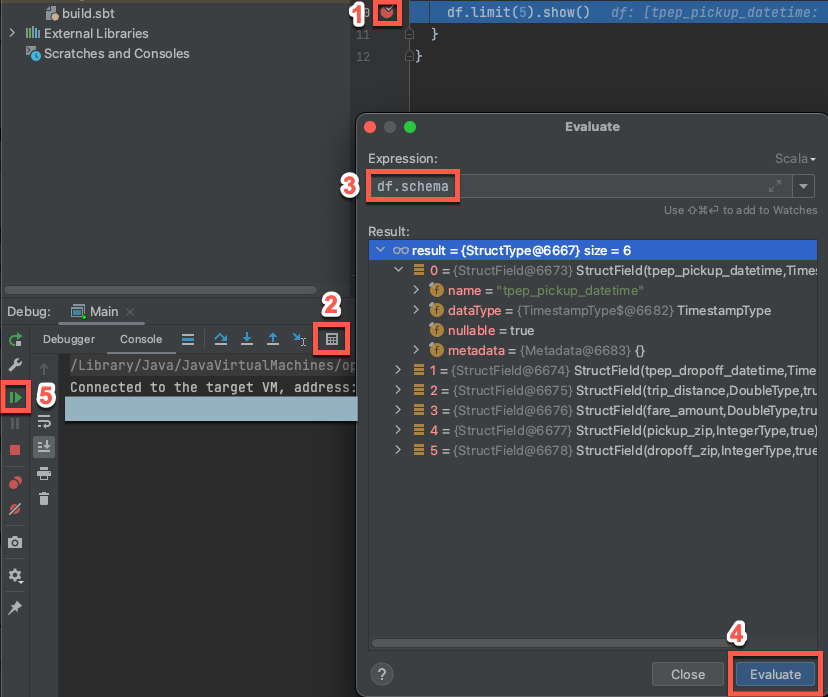
步驟 7:偵錯程式碼
當目標叢集仍在執行時,在前面的程式碼中,點擊
df.limit(5).show()旁的行號欄來設定斷點。在主功能表上,點擊 執行 > 偵錯 'Main'。 在 偵錯 工具視窗 (檢視 > 工具視窗 > 偵錯) 中的 Console 索引標籤上,點擊計算器(評估表示式)圖示。
輸入運算式
df.schema。按一下 [評估] 以顯示 DataFrame 的結構描述。
在偵錯工具視窗的側欄,按一下綠色箭頭(繼續程式)圖示。 表格的
samples.nyctaxi.trips前 5 列會出現在 [主控台] 窗格中。