湖屋的指導原則
指導原則是層級零的規則,可定義並影響您的架構。 若要建置可協助企業在現在和未來成功運作的 Data Lakehouse,組織中利害關係人之間的共識非常重要。
策劃數據並提供受信任的數據即產品
策展數據對於為 BI 和 ML/AI 建立高價值數據湖至關重要。 將數據視為具有清楚定義、架構和生命周期的產品。 確保語意一致性,且數據品質會從層到層改善,讓商務使用者可以完全信任數據。
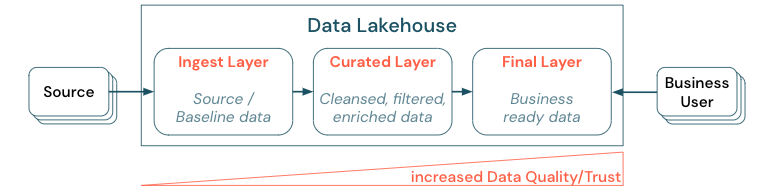
藉由建立分層式(或多躍點)架構來策劃數據是 Lakehouse 的重要最佳做法,因為它可讓數據小組根據品質層級來建構數據,並定義每一層的角色和責任。 常見的分層方法是:
- 內嵌層:源數據會擷取到湖屋第一層,而且應該保存在那裡。 從擷取層建立所有下游數據時,視需要重建此層的後續層。
- 策展層:第二層的目的是保留清理、精簡、篩選和匯總的數據。 此層的目標是為所有角色和功能提供健全、可靠的分析與報告基礎。
- 最後一層:第三層是圍繞商務或專案需求而建立;它提供不同的檢視作為數據產品給其他業務單位或專案、準備安全性需求的數據(例如匿名數據),或優化效能(使用預先匯總的檢視)。 此層中的數據產品被視為企業真相。
所有層的管線都需要確保符合數據品質條件約束,這表示即使在並行讀取和寫入期間,數據隨時都正確、完整、可存取且一致。 新數據的驗證會在數據輸入到策劃層時進行,而下列 ETL 步驟可改善此數據的品質。 數據質量必須改善,因為數據會逐一查看層,因此,數據的信任會從商務角度增加。
消除數據尋址接收器並將數據移動降至最低
請勿使用依賴這些不同複本的商務程式建立數據集復本。 復本可能會變成數據尋址接收器,而導致數據湖品質降低,最後變成過時或不正確的深入解析。 此外,若要與外部合作夥伴共享數據,請使用企業共享機制,以安全的方式直接存取數據。
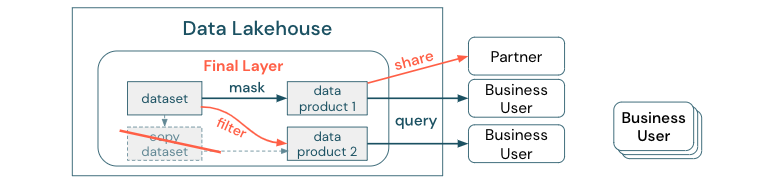
為了清楚區分數據復本與數據尋址接收器:獨立或拋出的數據復本本身並不有害。 有時需要提升靈活度、實驗和創新。 不過,如果這些復本會隨著相依的下游商務數據產品運作,它們就會變成數據尋址接收器。
為了防止數據尋址接收器,數據小組通常會嘗試建立機制或數據管線,讓所有複本與原始複本保持同步。 由於這種情況不太可能持續發生,因此數據質量最終會降低。 這也可能導致更高的成本,以及使用者大幅失去信任。 另一方面,數個商務使用案例需要與合作夥伴或供應商共用數據。
重要層面是安全地可靠地共用最新版本的數據集。 數據集的複本通常不夠,因為它們可以快速脫離同步。 相反地,應該透過企業數據共用工具來共享數據。
透過自助將價值創造大眾化
如果使用者無法輕鬆存取其 BI 和 ML/AI 工作的平臺或數據,則最佳數據湖無法提供足夠的價值。 降低存取所有業務單位數據和平台的障礙。 請考慮精簡數據管理程式,併為平臺和基礎數據提供自助存取。
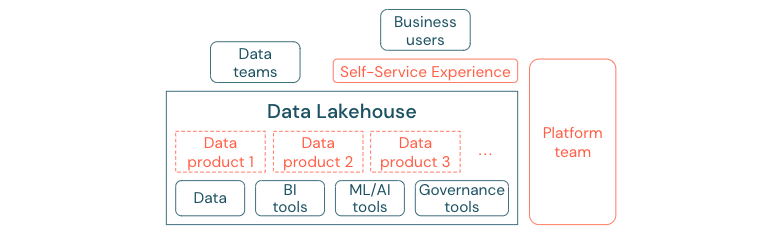
成功移至數據驅動文化的企業將蓬勃發展。 這表示每個業務單位都會從分析模型或分析自己的或集中提供的數據衍生其決策。 對於取用者,數據必須易於探索且安全存取。
數據產生者的良好概念是「數據即產品」:數據是由一個業務單位或業務夥伴提供和維護,例如產品,並由其他合作物件使用適當的許可權控制。 這些數據產品必須建立、提供、探索及取用自助體驗,而不是依賴中央小組和潛在的緩慢要求程式。
不過,不只是重要的數據。 數據的民主化需要適當的工具,讓每個人都能夠產生或取用及了解數據。 因此,您需要 Data Lakehouse 成為新式數據和 AI 平臺,以提供基礎結構和工具來建置數據產品,而不需要重複設定另一個工具堆棧的工作。
採用全組織的數據控管策略
數據是任何組織的重要資產,但您無法讓所有人存取所有數據。 數據存取必須主動管理。 訪問控制、稽核和譜系追蹤是正確且安全使用數據的關鍵。
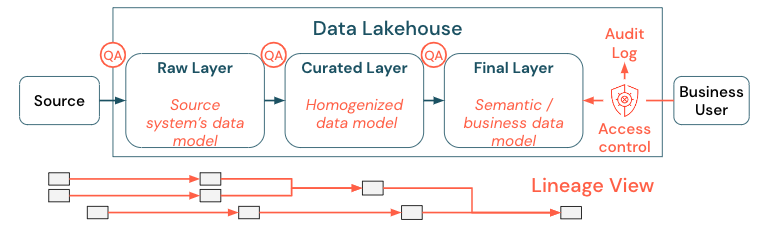
數據控管是一個廣泛的主題。 Lakehouse 涵蓋下列維度:
數據品質
正確且有意義的報表、分析結果和模型最重要的先決條件是高質量數據。 質量保證 (QA) 必須存在於所有管線步驟周圍。 如何實作此作業的範例包括擁有數據合約、會議 SLA、保持架構穩定,以及以受控制的方式加以演進。
數據目錄
另一個重要層面是數據探索:所有商務領域的使用者,特別是在自助模型中,必須能夠輕鬆地探索相關數據。 因此,Lakehouse 需要涵蓋所有商務相關數據的數據目錄。 資料目錄的主要目標如下:
- 請確定整個業務都統一呼叫並宣告相同的商務概念。 您可以將它視為策劃和最後一層中的語意模型。
- 精確地追蹤數據譜系,讓使用者可以說明這些數據如何到達其目前的形狀和表單。
- 維護高品質的元數據,這與數據本身一樣重要,以便適當地使用數據。
存取控制
由於湖屋中的數據的價值創造發生在所有商業領域,因此湖屋必須以一流的公民的身份建立安全。 公司可能會有更開放的數據存取原則,或嚴格遵循最低許可權原則。 獨立於這一點,數據訪問控制必須位在每一層中。 請務必從一開始就實作精細等級的許可權配置(數據行和數據列層級訪問控制、角色型或屬性型訪問控制)。 公司可以從較不嚴格的規則開始。 但是,隨著湖屋平台的成長,一個更複雜的安全制度的所有機制和程式都應該已經到位。 此外,Lakehouse 中數據的所有存取權都必須由 get-go 中的稽核記錄控管。
鼓勵開啟介面和開啟格式
開放介面和數據格式對於 Lakehouse 與其他工具之間的互操作性至關重要。 其可簡化與現有系統的整合,並開啟已將其工具與平臺整合的合作夥伴生態系統。
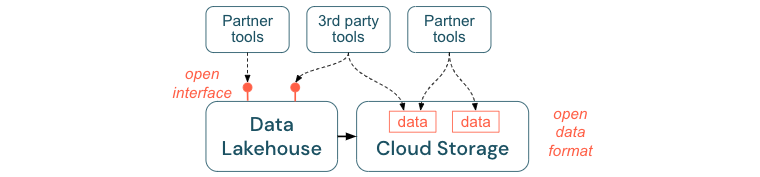
開放介面對於啟用互操作性並防止任何單一廠商相依性至關重要。 傳統上,廠商會建置專屬技術和封閉介面,以限制企業儲存、處理及共享數據的方式。
建置開放式介面可協助您為未來建置:
- 它會增加數據的壽命和可移植性,讓您可以將其與更多應用程式搭配使用,並用於更多使用案例。
- 其會開啟合作夥伴的生態系統,其可快速利用開放介面將其工具整合到 Lakehouse 平臺。
最後,透過標準化數據開放格式,總成本將大幅降低:您可以直接在雲端記憶體上存取數據,而不需要透過專屬平臺傳送數據,而可能會產生高輸出和計算成本。
建置以調整和優化效能和成本
數據不可避免地會持續成長並變得更加複雜。 若要為您的組織提供未來需求,您的 Lakehouse 應該能夠進行調整。 例如,您應該能夠視需要輕鬆地新增資源。 成本應受限於實際耗用量。
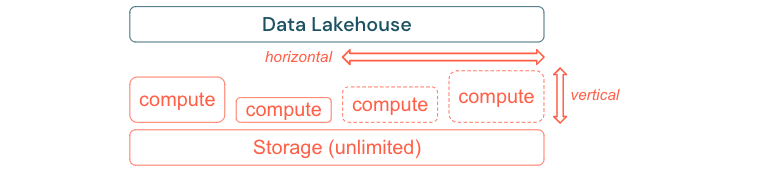
標準 ETL 程式、商務報告和儀錶板通常具有記憶體和計算觀點的可預測資源需求。 不過,新的專案、季節性工作或新式方法,例如模型定型(變換、預測、維護)會產生資源需求的尖峰。 若要讓企業能夠執行所有這些工作負載,則需要可調整的記憶體和計算平臺。 新的資源必須隨選輕鬆新增,而且只有實際耗用量才會產生成本。 一旦尖峰結束,就可以重新釋放資源,並據以降低成本。 通常,這稱為水平調整(較少或更多節點)和垂直調整(較大或較小的節點)。
調整也可讓企業藉由選取具有更多資源或具有更多節點的叢集來改善查詢的效能。 但是,與其永久提供大型機器和叢集,不如只在需要時布建大型機器和叢集,以將整體效能與成本比率優化。 優化的另一個層面是記憶體與計算資源。 由於使用此數據的數據量與工作負載之間沒有明確的關聯性(例如,只使用部分數據或對小型數據進行密集計算),因此在分離記憶體和計算資源的基礎結構平臺上,是個不錯的做法。