Data Lakehouse 是一種數據管理系統,結合了數據湖和數據倉儲的優點。 本文說明 Lakehouse 架構模式,以及您可以在 Azure Databricks 上執行哪些動作。
Data Lakehouse 的用途為何?
Data Lakehouse 為新式組織提供可調整的記憶體和處理功能,這些組織想要避免隔離系統來處理不同的工作負載,例如機器學習 (ML) 和商業智慧 (BI)。 Data Lakehouse 可協助建立單一事實來源、消除備援成本,並確保數據新鮮度。
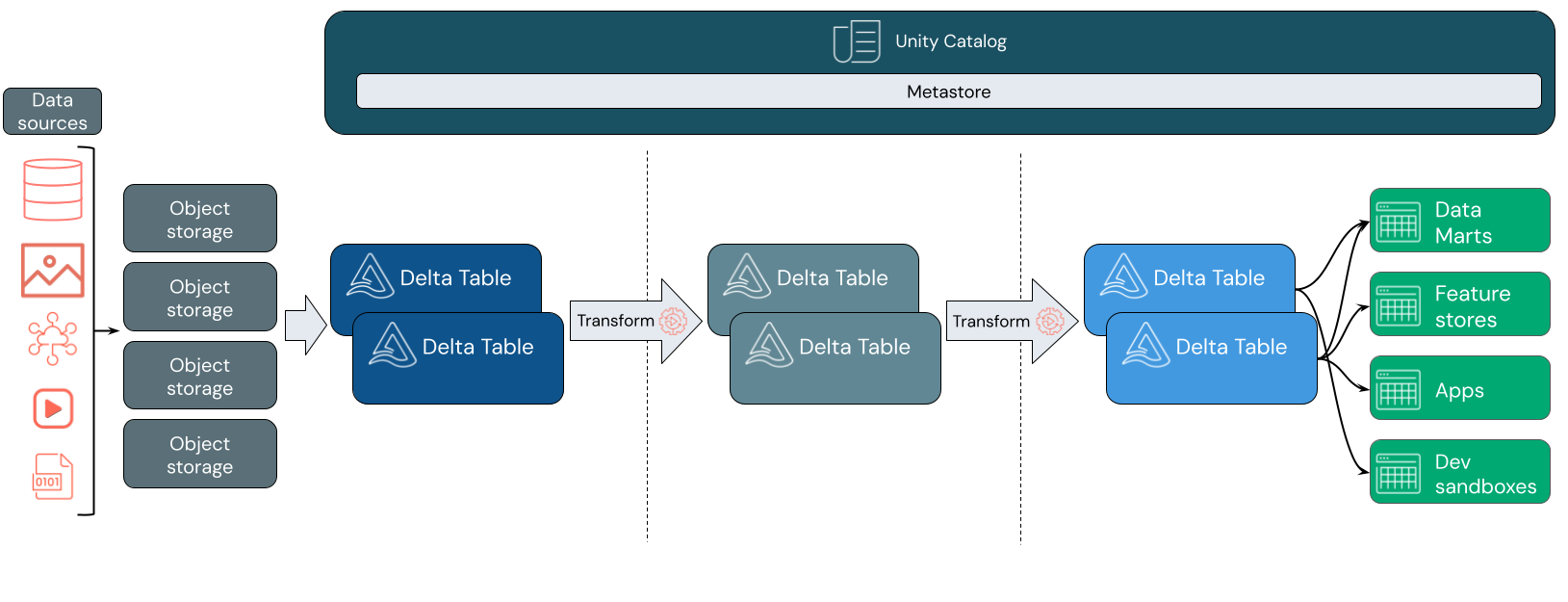
數據湖倉通常使用一種數據設計模式,以逐步改善、豐富和完善數據,隨著移經暫存和轉換層。 湖倉的每一層級都可以包含一個或多個階層。 這種模式通常稱為獎章架構。 如需詳細資訊,請參閱 什麼是 Medallion Lakehouse 架構?
Databricks Lakehouse 如何運作?
Databricks 建置在 Apache Spark 上。 Apache Spark 可讓大規模擴充的引擎在與記憶體分離的計算資源上執行。 如需詳細資訊,請參閱 Apache Spark 概觀
Databricks Lakehouse 使用兩種額外的關鍵技術:
- Delta Lake:支援 ACID 交易和架構強制執行的優化儲存層。
- Unity 目錄:適用於數據和 AI 的統一、精細的治理解決方案。
數據擷取
在擷取層中,批次或串流數據會從各種來源和各種格式抵達。 第一個邏輯層提供該數據以原始格式登陸的位置。 當您將這些檔案轉換成 Delta 數據表時,您可以使用 Delta Lake 的架構強制執行功能來檢查遺失或未預期的數據。 您可以使用 Unity 目錄,根據您的資料控管模型和必要的數據隔離界限來註冊數據表。 Unity 目錄可讓您追蹤數據經過轉換和精簡的歷程,以及套用統一的治理模型,讓敏感數據保持私密且安全。
數據處理、策展和整合
驗證之後,您就可以開始策劃和精簡您的數據。 數據科學家和機器學習從業者經常在這個階段使用數據,以開始結合或建立新功能並完成數據清理。 一旦徹底清理數據,就可以將其整合並重新組織成專為符合特定業務需求而設計的數據表。
寫入架構的方式,結合 Delta 架構演進的能力,意味著您可以變更此層,而不需要重寫用於為最終使用者提供數據的下游邏輯。
數據服務
最後一層會為終端使用者提供乾淨、擴充的數據。 最終的數據表應該設計為適用於所有使用者案例的數據提供。 統一的治理模型表示您可以追蹤數據譜系回到單一事實來源。 數據配置已針對不同的工作優化,可讓使用者存取機器學習應用程式、數據工程和商業智慧和報告的數據。
若要深入瞭解 Delta Lake,請參閱 什麼是 Azure Databricks 中的 Delta Lake? 若要深入瞭解 Unity 目錄,請參閱 什麼是 Unity 目錄?
Databricks Lakehouse 的功能
以 Databricks 為基礎的湖倉屋取代了現代數據公司目前依賴於數據湖和數據倉儲的狀況。 您可以執行的一些重要工作包括:
- 實時數據處理: 實時處理串流數據以進行即時分析和動作。
- 數據整合: 整合單一系統中的數據,以啟用共同作業,併為組織建立單一事實來源。
- 架構演進: 修改數據架構,以適應不斷變化的業務需求,而不會中斷現有的數據管線。
- 數據轉換: 使用 Apache Spark 和 Delta Lake 可為您的數據帶來速度、延展性和可靠性。
- 數據分析和報告: 使用針對數據倉儲工作負載優化的引擎來執行複雜的分析查詢。
- 機器學習與 AI: 將進階分析技術套用至所有數據。 使用 ML 擴充您的資料並支援其他工作負載。
- 數據版本設定和譜系: 維護數據集的版本歷程記錄,並追蹤譜系,以確保數據源和可追蹤性。
- 數據控管: 使用單一統一系統來控制數據的存取,並執行稽核。
- 數據共享: 允許跨小組共用策劃的數據集、報表和深入解析,促進共同作業。
- 營運分析: 使用資料品質監控監控資料品質指標、模型品質指標和漂移。
Lakehouse 與 Data Lake 與數據倉儲
數據倉儲為商業智慧(BI)決策提供約 30 年的動力,已演變為一組控制數據流的系統設計指導方針。 企業數據倉儲會將 BI 報表的查詢優化,但可能需要幾分鐘甚至數小時才能產生結果。 針對不太可能以高頻率變更的數據而設計,數據倉儲會尋求防止同時執行查詢之間的衝突。 許多數據倉儲都依賴專屬格式,這些格式通常會限制對機器學習的支援。 Azure Databricks 上的數據倉儲會利用 Databricks Lakehouse 和 Databricks SQL 的功能。 如需詳細資訊,請參閱 Azure Databricks 上的數據倉儲。
在數據儲存的技術進步和數據類型及數量的指數增長推動下,數據湖在過去十年間被廣泛使用。 Data Lake 會以廉價且有效率的方式儲存和處理數據。 數據湖通常定義於反對數據倉儲:數據倉儲會為 BI 分析提供乾淨的結構化數據,而數據湖會永久且廉價地以任何格式儲存任何性質的數據。 許多組織會使用 Data Lake 進行數據科學和機器學習,但不會因為其未經驗證的性質而使用 BI 報告。
資料湖倉結合了資料湖和資料倉儲的優點,並提供:
- 開啟,直接存取以標準數據格式儲存的數據。
- 針對機器學習和數據科學優化的索引通訊協定。
- BI 和進階分析的低查詢延遲和高可靠性。
透過將最佳化的中繼資料層與以標準格式儲存在雲端物件儲存中的經過驗證的資料相結合,資料湖庫可讓您在不同的使用案例中在同一個平台上使用相同的資料。
下一步
若要深入瞭解如何使用 Databricks 來實作及操作湖倉(Lakehouse)系統的原則和最佳做法,請參閱 精心設計的湖倉數據屋簡介