Lakeflow pipelines 引入了數種新的 Python 程式碼結構,用於定義管線中的實體化檢視與串流資料表。 Python 支援開發管線是以 PySpark DataFrame 和結構化串流 API 的基本概念為基礎。
對於不熟悉 Python 和 DataFrame 的使用者,Databricks 建議使用 SQL 介面。 請參閱 使用 SQL 程式碼開發 Lakeflow 管道。 如需在兩種介面間做出選擇,請參見「選擇 SQL 與 Python」。
欲了解 Lakeflow pipelines Python 語法的完整參考,請參閱 Lakeflow pipelines Python 語言參考。
適用於管線開發的 Python 基本概念
建立管線資料集的 Python 程式碼必須回傳 DataFrames。
所有 Lakeflow pipelines 的 Python API 皆實作於此pyspark.pipelines模組中。 使用 Python 實作的管線程式碼必須明確匯入 pipelines Python 原始碼頂端的模組。 在我們的範例中,我們使用下列的 import 指令,並在範例中使用 dp 來參照 pipelines。
from pyspark import pipelines as dp
備註
Apache Spark™ 從 Spark 4.1 開始包含 宣告式管線 ,並可透過模組 pyspark.pipelines 取得。 Databricks Runtime 會透過其他 API 和整合來擴充這些開放原始碼功能,以供受控生產使用。
使用開放原始碼 pipelines 模組撰寫的程式碼會在 Azure Databricks 上執行,無需修改。 下列功能不屬於 Apache Spark 的一部分:
dp.create_auto_cdc_flowdp.create_auto_cdc_from_snapshot_flow@dp.expect(...)
管線讀寫的預設目錄和 schema 是在管線設定期間指定的。 請參閱 設定目標目錄和架構。
管道特定的 Python 程式碼與其他類型的 Python 程式碼有一項關鍵不同:Python 管道程式碼不會直接呼叫執行資料擷取和轉換的函數來建立資料集。 相反地,Lakeflow pipelines 會解析管線中設定的所有原始程式碼檔案裡來自 dp 模組的裝飾函式,並建立資料流程圖。
這很重要
若要避免管線執行時發生非預期的行為,請勿在定義數據集的函式中包含可能有副作用的程序代碼。 若要深入瞭解,請參閱 Python 參考。
使用 Python 建立具體化檢視或串流數據表
用 @dp.table 來從串流讀取的結果建立串流資料表。 使用 @dp.materialized_view 從批次讀取的結果來建立具體化檢視。
根據預設,具體化檢視和串流數據表名稱會從函式名稱推斷。 下列程式代碼範例示範建立具體化檢視表和串流數據表的基本語法:
備註
這兩個函式都會參考 samples 目錄中的相同數據表,並使用相同的裝飾函式。 這些範例強調具體化檢視和串流數據表的基本語法唯一差異是使用 spark.read 與 spark.readStream。
並非所有數據源都支援串流讀取。 某些數據源應該一律使用串流語意來處理。
from pyspark import pipelines as dp
@dp.materialized_view()
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dp.table()
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
或者,您可以使用 name 裝飾專案中的 @dp.table 自變數來指定資料表名稱。 下列範例示範具體化檢視表和串流數據表的這個模式:
from pyspark import pipelines as dp
@dp.materialized_view(name = "trips_mv")
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dp.table(name = "trips_st")
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
從物件記憶體載入資料
管線支援從 Azure Databricks 支援的所有格式載入資料。 請參閱 數據格式選項。
備註
這些範例會使用自動掛接到工作區的/databricks-datasets下可用的資料。 Databricks 建議使用磁碟區路徑或雲端 URI 來參考儲存在雲端物件記憶體中的數據。 請參閱什麼是 Unity Catalog 磁碟區?。
Databricks 建議在設定針對儲存在雲端物件儲存中的資料進行增量擷取的工作負載時,使用 Auto Loader 和串流資料表。 請參閱 什麼是自動載入器?。
下列範例會使用自動載入器從 JSON 檔案建立串流資料表:
from pyspark import pipelines as dp
@dp.table()
def ingestion_st():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
下列範例會使用批次語意來讀取 JSON 目錄,並建立具體化檢視:
from pyspark import pipelines as dp
@dp.materialized_view()
def batch_mv():
return spark.read.format("json").load("/databricks-datasets/retail-org/sales_orders")
用預期驗證數據
您可以使用預期來設定及強制執行資料品質條件約束。 請參閱 使用管線期望來管理資料品質。
下列程式代碼會使用 @dp.expect_or_drop 來定義名為 valid_data 的預期,以在數據擷取期間卸除 null 的記錄:
from pyspark import pipelines as dp
@dp.table()
@dp.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders_valid():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
查詢管線中定義的實體化視圖和串流資料表
下列範例會定義四個資料集:
- 名為
orders的串流數據表,會載入 JSON 數據。 - 名為
customers的具體化檢視,可載入 CSV 數據。 - 名為
customer_orders的具體化檢視,聯結來自orders和customers數據集的記錄、將順序時間戳轉換成日期,然後選取customer_id、order_number、state和order_date字段。 - 名為
daily_orders_by_state的具體化檢視,會匯總每個州的每日訂單計數。
備註
在查詢管線中的檢視或資料表時,您可以直接指定目錄和架構,也可以使用管線中設定的預設值。 在此範例中,orders、customers和 customer_orders 數據表會從您管線設定的預設目錄和架構中寫入和讀取。
舊版發佈模式會使用 LIVE 架構來查詢管線中定義的其他具體化檢視和串流數據表。 在新管線中,LIVE 架構語法會被默默地忽略。 請參閱 LIVE 架構(舊版)。
from pyspark import pipelines as dp
from pyspark.sql.functions import col
@dp.table()
@dp.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
@dp.materialized_view()
def customers():
return spark.read.format("csv").option("header", True).load("/databricks-datasets/retail-org/customers")
@dp.materialized_view()
def customer_orders():
return (spark.read.table("orders")
.join(spark.read.table("customers"), "customer_id")
.select("customer_id",
"order_number",
"state",
col("order_datetime").cast("int").cast("timestamp").cast("date").alias("order_date"),
)
)
@dp.materialized_view()
def daily_orders_by_state():
return (spark.read.table("customer_orders")
.groupBy("state", "order_date")
.count().withColumnRenamed("count", "order_count")
)
在 for 迴圈中建立數據表
您可以使用 Python for 循環,以程式設計方式建立多個數據表。 當您有許多數據源或目標數據集只因少數參數而有所不同時,這可能會很有用,這導致維護所需的總程式碼較少,而且程式碼冗贅較少。
for 迴圈會依序列順序評估邏輯,但一旦為數據集完成規劃,管線就會平行執行邏輯。
這很重要
使用此模式來定義資料集時,請確定傳遞至 for 迴圈的值清單一律是加總的。 如果先前在管線中定義的資料集於未來的管線運行中被省略,該資料集會自動從目標結構中移除。
下列範例會建立五個數據表,依區域篩選客戶訂單。 在這裡,區域名稱是用來設定目標具體化檢視的名稱,以及篩選源數據。 暫存檢視可用來定義建構最終具體化檢視時所用源數據表的聯結。
from pyspark import pipelines as dp
from pyspark.sql.functions import collect_list, col
@dp.temporary_view()
def customer_orders():
orders = spark.read.table("samples.tpch.orders")
customer = spark.read.table("samples.tpch.customer")
return (orders.join(customer, orders.o_custkey == customer.c_custkey)
.select(
col("c_custkey").alias("custkey"),
col("c_name").alias("name"),
col("c_nationkey").alias("nationkey"),
col("c_phone").alias("phone"),
col("o_orderkey").alias("orderkey"),
col("o_orderstatus").alias("orderstatus"),
col("o_totalprice").alias("totalprice"),
col("o_orderdate").alias("orderdate"))
)
@dp.temporary_view()
def nation_region():
nation = spark.read.table("samples.tpch.nation")
region = spark.read.table("samples.tpch.region")
return (nation.join(region, nation.n_regionkey == region.r_regionkey)
.select(
col("n_name").alias("nation"),
col("r_name").alias("region"),
col("n_nationkey").alias("nationkey")
)
)
# Extract region names from region table
region_list = spark.read.table("samples.tpch.region").select(collect_list("r_name")).collect()[0][0]
# Iterate through region names to create new region-specific materialized views
for region in region_list:
@dp.materialized_view(name=f"{region.lower().replace(' ', '_')}_customer_orders")
def regional_customer_orders(region_filter=region):
customer_orders = spark.read.table("customer_orders")
nation_region = spark.read.table("nation_region")
return (customer_orders.join(nation_region, customer_orders.nationkey == nation_region.nationkey)
.select(
col("custkey"),
col("name"),
col("phone"),
col("nation"),
col("region"),
col("orderkey"),
col("orderstatus"),
col("totalprice"),
col("orderdate")
).filter(f"region = '{region_filter}'")
)
以下是此管線數據流圖形的範例:
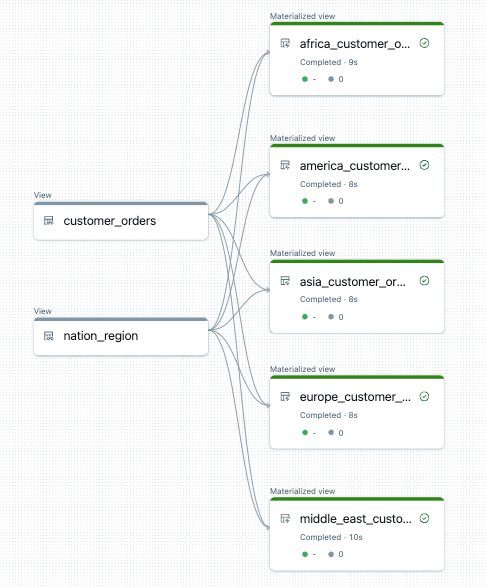
疑難解答:for 迴圈會建立許多具有相同值的數據表
執行管線用來評估 Python 程式碼的延遲執行模型,需要在調用經 @dp.materialized_view() 裝飾的函數時,您的邏輯必須直接參考個別值。
下列範例示範兩個正確的方法來定義具有 for 循環的數據表。 在這兩個範例中,tables 清單中的每個資料表名稱都會在由 @dp.materialized_view()裝飾的函式中被明確引用。
from pyspark import pipelines as dp
# Create a parent function to set local variables
def create_table(table_name):
@dp.materialized_view(name=table_name)
def t():
return spark.read.table(table_name)
tables = ["t1", "t2", "t3"]
for t_name in tables:
create_table(t_name)
# Call `@dp.materialized_view()` within a for loop and pass values as variables
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dp.materialized_view(name=t_name)
def create_table(table_name=t_name):
return spark.read.table(table_name)
下列範例 未正確引用 的值。 此範例會建立具有不同名稱的數據表,但所有數據表都會從 for 迴圈中的最後一個值載入數據:
from pyspark import pipelines as dp
# Don't do this!
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dp.materialized(name=t_name)
def create_table():
return spark.read.table(t_name)
從實體化視圖或串流表永久刪除記錄
若要從已啟用刪除向量的具體化檢視或串流資料表中永久刪除記錄,例如針對GDPR合規性,必須在對象的 Delta 基礎資料表上執行其他作業。 若要確保從具體化檢視刪除記錄,請參閱 永久刪除具有啟用刪除向量之具體化檢視中的記錄。 若要確保從串流資料表刪除記錄,請參閱 從串流資料表永久刪除記錄。