本文包含大規模實作預期的建議,以及預期所支援的進階模式範例。 這些模式會使用多個資料集搭配預期,並要求使用者瞭解具體化檢視、串流資料表和預期的語法和語意。
如需預期行為和語法的基本概觀,請參閱 使用管線期望管理資料品質。
可攜式且可重複使用的期望
Databricks 在實作預期時建議下列最佳做法,以改善可攜性並減輕維護負擔:
| Recommendation | Impact |
|---|---|
| 將期望定義與管線邏輯分開儲存。 | 輕鬆地將期望套用至多個資料集或管線。 更新、稽核和維護期望,而無需修改管道原始程式碼。 |
| 新增自訂標籤以建立相關期望群組。 | 根據標籤過濾期望。 |
| 在類似的資料集中一致地套用期望。 | 在多個資料集和管線中使用相同的期望來評估相同的邏輯。 |
下列範例示範如何使用 Delta 資料表或字典來建立中央預期儲存庫。 然後,自訂 Python 函數會將這些期望套用至範例管線中的資料集:
Delta 表格
下列範例會建立名為 維護規則的資料表 rules :
CREATE OR REPLACE TABLE
rules
AS SELECT
col1 AS name,
col2 AS constraint,
col3 AS tag
FROM (
VALUES
("website_not_null","Website IS NOT NULL","validity"),
("fresh_data","to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'","maintained"),
("social_media_access","NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)","maintained")
)
下列 Python 範例會根據表格中的 rules 規則定義資料品質預期。 該 get_rules() 函數從表格中 rules 讀取規則並返回一個 Python 字典,其中包含與傳遞給函數的參數匹配的 tag 規則。
在此範例中,字典使用@dp.expect_all_or_drop()裝飾器來強制執行資料品質限制。
例如,任何未通過 validity 標記規則的記錄都會被從 raw_farmers_market 表格中刪除。
from pyspark import pipelines as dp
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
df = spark.read.table("rules").filter(col("tag") == tag).collect()
return {
row['name']: row['constraint']
for row in df
}
@dp.table
@dp.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dp.table
@dp.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
spark.read.table("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Python 模組
下列範例會建立 Python 模組來維護規則。 在此範例中,請將此程式碼儲存在與用作管線原始程式碼的筆記本相同的資料夾中命名 rules_module.py 的檔案中:
def get_rules_as_list_of_dict():
return [
{
"name": "website_not_null",
"constraint": "Website IS NOT NULL",
"tag": "validity"
},
{
"name": "fresh_data",
"constraint": "to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'",
"tag": "maintained"
},
{
"name": "social_media_access",
"constraint": "NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)",
"tag": "maintained"
}
]
下列 Python 範例會根據檔案中 rules_module.py 定義的規則來定義資料品質預期。 該 get_rules() 函數返回一個 Python 字典,其中包含與傳遞給它的參數匹配的 tag 規則。
在此範例中,字典使用@dp.expect_all_or_drop()裝飾器來強制執行資料品質限制。
例如,任何未通過 validity 標記規則的記錄都會被從 raw_farmers_market 表格中刪除。
from pyspark import pipelines as dp
from rules_module import *
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
return {
row['name']: row['constraint']
for row in get_rules_as_list_of_dict()
if row['tag'] == tag
}
@dp.table
@dp.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dp.table
@dp.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
spark.read.table("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
資料列計數驗證
下列範例會驗證 和 table_a 之間的table_b資料列計數相等性,以檢查轉換期間是否遺失任何資料:
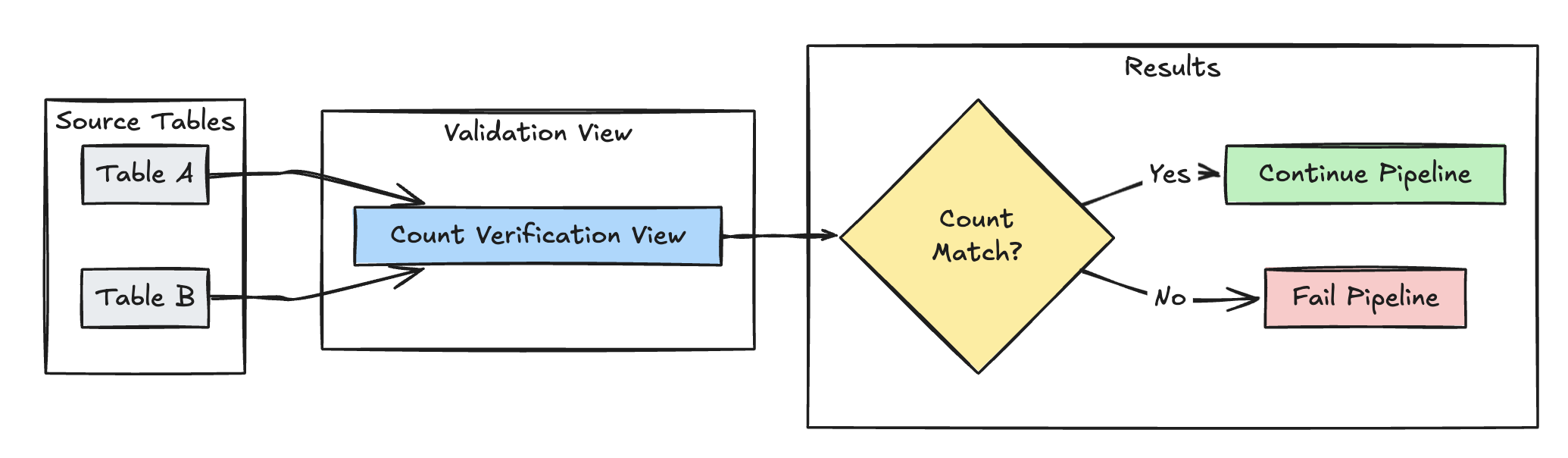
Python
@dp.view(
name="count_verification",
comment="Validates equal row counts between tables"
)
@dp.expect_or_fail("no_rows_dropped", "a_count == b_count")
def validate_row_counts():
return spark.sql("""
SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)""")
SQL
CREATE OR REFRESH MATERIALIZED VIEW count_verification(
CONSTRAINT no_rows_dropped EXPECT (a_count == b_count)
) AS SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)
遺失記錄偵測
下列範例會驗證資料表中 report 是否存在所有預期的記錄:
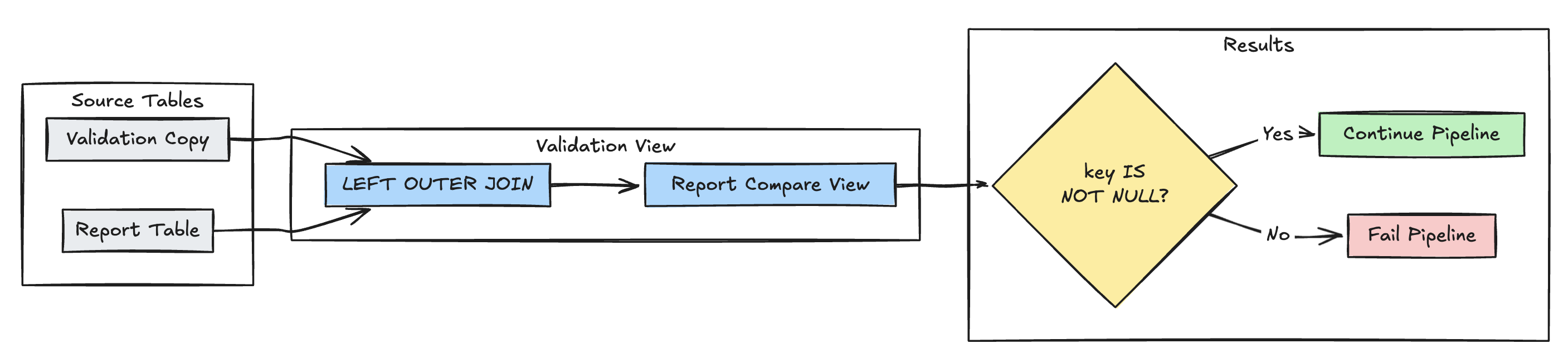
Python
@dp.view(
name="report_compare_tests",
comment="Validates no records are missing after joining"
)
@dp.expect_or_fail("no_missing_records", "r_key IS NOT NULL")
def validate_report_completeness():
return (
spark.read.table("validation_copy").alias("v")
.join(
spark.read.table("report").alias("r"),
on="key",
how="left_outer"
)
.select(
"v.*",
"r.key as r_key"
)
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_compare_tests(
CONSTRAINT no_missing_records EXPECT (r_key IS NOT NULL)
)
AS SELECT v.*, r.key as r_key FROM validation_copy v
LEFT OUTER JOIN report r ON v.key = r.key
主鍵唯一性
下列範例會驗證資料表之間的主索引鍵限制:
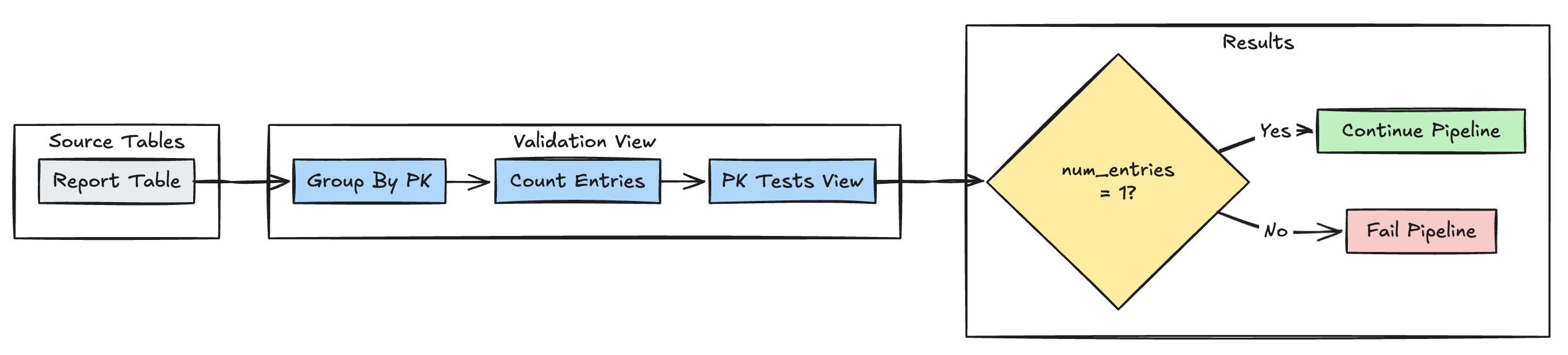
Python
@dp.view(
name="report_pk_tests",
comment="Validates primary key uniqueness"
)
@dp.expect_or_fail("unique_pk", "num_entries = 1")
def validate_pk_uniqueness():
return (
spark.read.table("report")
.groupBy("pk")
.count()
.withColumnRenamed("count", "num_entries")
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_pk_tests(
CONSTRAINT unique_pk EXPECT (num_entries = 1)
)
AS SELECT pk, count(*) as num_entries
FROM report
GROUP BY pk
架構演進模式
以下範例展示如何處理新增資料行的結構演進。 當您移轉資料來源或處理多個版本的上游資料時,請使用此模式,確保回溯相容性,同時強制執行資料品質:
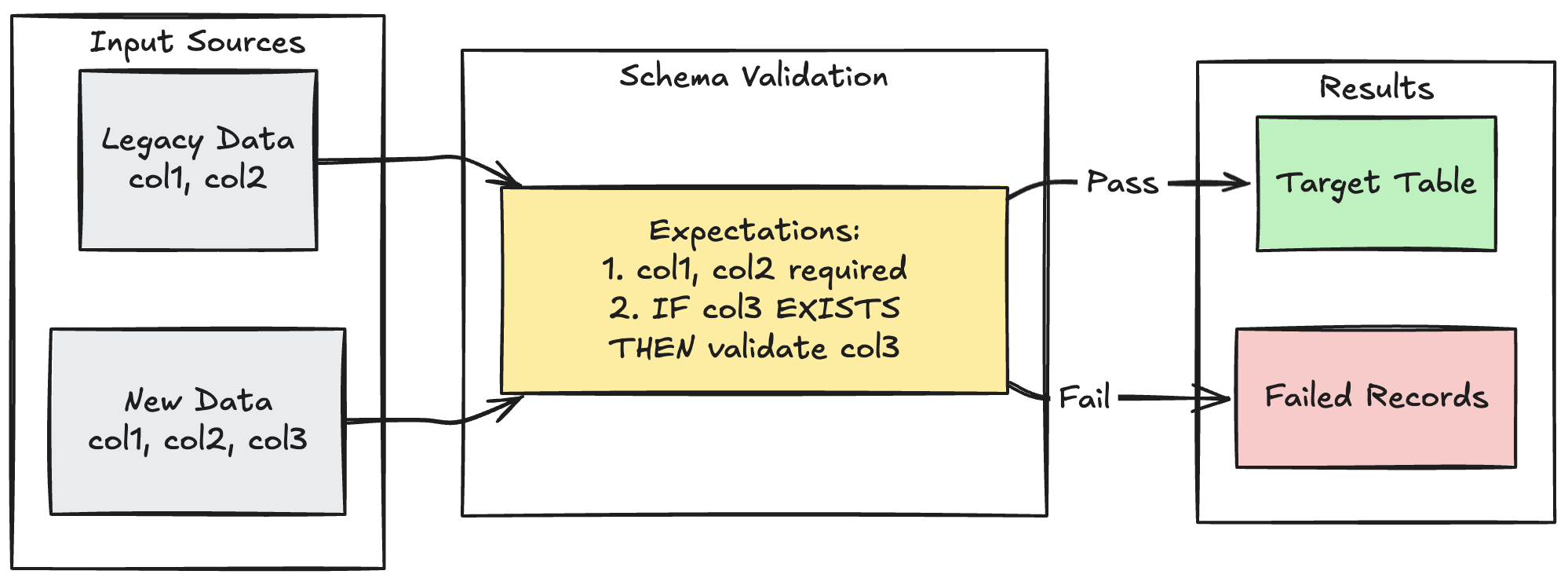
Python
@dp.table
@dp.expect_all_or_fail({
"required_columns": "col1 IS NOT NULL AND col2 IS NOT NULL",
"valid_col3": "CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END"
})
def evolving_table():
# Legacy data (V1 schema)
legacy_data = spark.read.table("legacy_source")
# New data (V2 schema)
new_data = spark.read.table("new_source")
# Combine both sources
return legacy_data.unionByName(new_data, allowMissingColumns=True)
SQL
CREATE OR REFRESH MATERIALIZED VIEW evolving_table(
-- Merging multiple constraints into one as expect_all is Python-specific API
CONSTRAINT valid_migrated_data EXPECT (
(col1 IS NOT NULL AND col2 IS NOT NULL) AND (CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END)
) ON VIOLATION FAIL UPDATE
) AS
SELECT * FROM new_source
UNION
SELECT *, NULL as col3 FROM legacy_source;
以範圍為基礎的驗證模式
下列範例示範如何根據歷史統計範圍驗證新資料點,以協助識別資料流程中的異常值和異常:
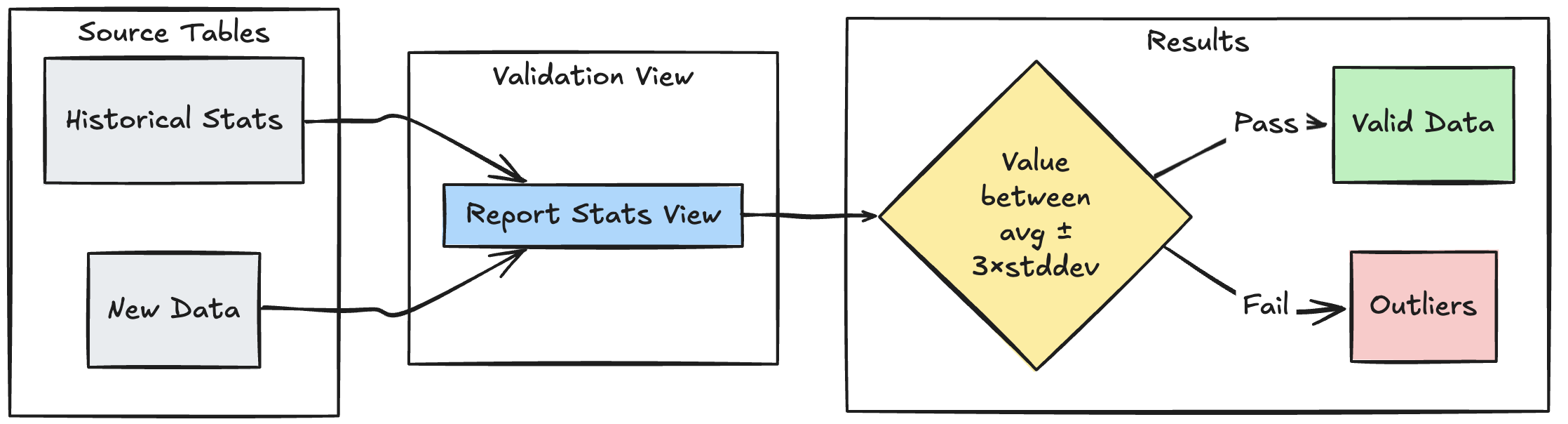
Python
@dp.view
def stats_validation_view():
# Calculate statistical bounds from historical data
bounds = spark.sql("""
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE
date >= CURRENT_DATE() - INTERVAL 30 DAYS
""")
# Join with new data and apply bounds
return spark.read.table("new_data").crossJoin(bounds)
@dp.table
@dp.expect_or_drop(
"within_statistical_range",
"amount BETWEEN lower_bound AND upper_bound"
)
def validated_amounts():
return spark.read.table("stats_validation_view")
SQL
CREATE OR REFRESH MATERIALIZED VIEW stats_validation_view AS
WITH bounds AS (
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE date >= CURRENT_DATE() - INTERVAL 30 DAYS
)
SELECT
new_data.*,
bounds.*
FROM new_data
CROSS JOIN bounds;
CREATE OR REFRESH MATERIALIZED VIEW validated_amounts (
CONSTRAINT within_statistical_range EXPECT (amount BETWEEN lower_bound AND upper_bound)
)
AS SELECT * FROM stats_validation_view;
隔離無效記錄
此模式會將期望與暫存資料表和檢視結合,以在管線更新期間追蹤資料品質指標,並在下游作業中為有效和無效記錄啟用個別的處理路徑。
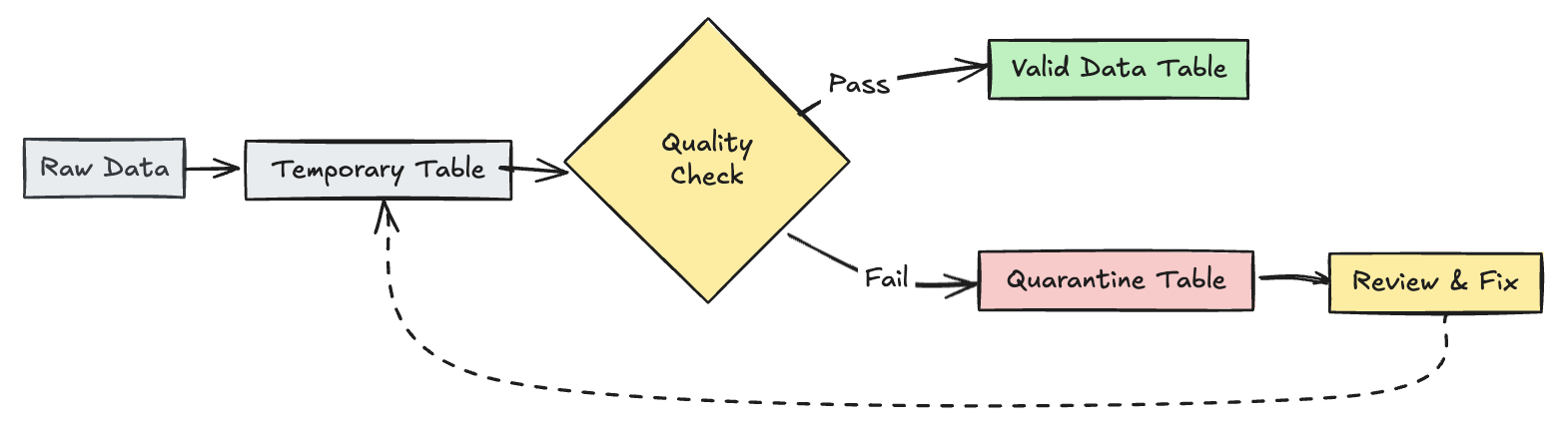
Python
from pyspark import pipelines as dp
from pyspark.sql.functions import expr
rules = {
"valid_pickup_zip": "(pickup_zip IS NOT NULL)",
"valid_dropoff_zip": "(dropoff_zip IS NOT NULL)",
}
quarantine_rules = "NOT({0})".format(" AND ".join(rules.values()))
@dp.view
def raw_trips_data():
return spark.readStream.table("samples.nyctaxi.trips")
@dp.table(
temporary=True,
partition_cols=["is_quarantined"],
)
@dp.expect_all(rules)
def trips_data_quarantine():
return (
spark.readStream.table("raw_trips_data").withColumn("is_quarantined", expr(quarantine_rules))
)
@dp.view
def valid_trips_data():
return spark.read.table("trips_data_quarantine").filter("is_quarantined=false")
@dp.view
def invalid_trips_data():
return spark.read.table("trips_data_quarantine").filter("is_quarantined=true")
SQL
CREATE TEMPORARY STREAMING LIVE VIEW raw_trips_data AS
SELECT * FROM STREAM(samples.nyctaxi.trips);
CREATE OR REFRESH TEMPORARY STREAMING TABLE trips_data_quarantine(
-- Option 1 - merge all expectations to have a single name in the pipeline event log
CONSTRAINT quarantined_row EXPECT (pickup_zip IS NOT NULL OR dropoff_zip IS NOT NULL),
-- Option 2 - Keep the expectations separate, resulting in multiple entries under different names
CONSTRAINT invalid_pickup_zip EXPECT (pickup_zip IS NOT NULL),
CONSTRAINT invalid_dropoff_zip EXPECT (dropoff_zip IS NOT NULL)
)
PARTITIONED BY (is_quarantined)
AS
SELECT
*,
NOT ((pickup_zip IS NOT NULL) and (dropoff_zip IS NOT NULL)) as is_quarantined
FROM STREAM(raw_trips_data);
CREATE TEMPORARY LIVE VIEW valid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=FALSE;
CREATE TEMPORARY LIVE VIEW invalid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=TRUE;