在資料工程中, 回填 是指透過專為處理目前或串流資料而設計的資料管道追溯處理歷史資料的過程。
通常,這是將資料傳送至現有資料表的個別流程。 下圖顯示將歷史資料傳送至管線中青銅資料表的回填流程。
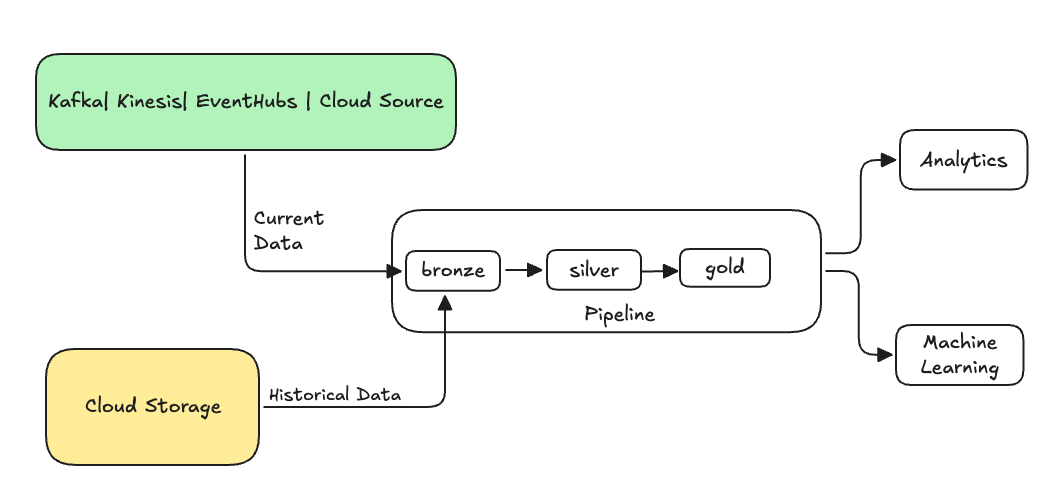
可能需要回填的一些案例:
- 處理來自舊版系統的歷史資料,以訓練機器學習 (ML) 模型或建置歷史趨勢分析儀表板。
- 由於上游資料來源的資料品質問題,重新處理資料子集。
- 您的業務需求已變更,您需要回填初始管線未涵蓋的不同時段的資料。
- 您的商務邏輯已變更,您需要重新處理歷程資料和目前資料。
Lakeflow Spark 宣告式管線中的回填處理支援使用 ONCE 選項的專用附加流程。 如需有關 選項的詳細資訊,請參閱 append_flow 或 ONCE。
將歷程記錄資料回填至串流資料表時的考量事項
- 一般而言,請將資料附加至 Bronze 串流表格。 下游的銀層和金層將從青銅層中獲取新數據。
- 請確定您的管線可以正常處理重複資料,以防相同的資料被多次附加。
- 請確定歷程資料結構描述與目前的資料結構描述相容。
- 請考慮資料磁碟區大小和所需的處理時間 SLA,並據以設定叢集和批次大小。
範例:將回填加入到現有的管線中
在此範例中,假設您有一條管線,可從雲端儲存來源擷取原始事件登記資料,從 2025 年 1 月 1 日開始。 您稍後意識到,您想要回填前三年的歷史資料,以用於下游報告和分析使用案例。 所有資料都位於一個位置,以 JSON 格式按年、月和日分割。
初始管線
以下是從雲端儲存體累加擷取原始事件註冊資料的起始管線程式碼。
Python
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
incremental_load_path = f"{source_root_path}/*/*/*"
# create a streaming table and the default flow to ingest streaming events
@dp.table(name="registration_events_raw", comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2025-01-01T00:00:00.000+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}") # safeguard to not process data before begin_year
)
SQL
-- create a streaming table and the default flow to ingest streaming events
CREATE OR REFRESH STREAMING LIVE TABLE registration_events_raw AS
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025'; -- safeguard to not process data before begin_year
在這裡,我們使用自動加載器選項 modifiedAfter 來確保我們不會處理來自雲存儲路徑的所有數據。 增量處理會在該界限處截斷。
小提示
其他資料來源 (例如 Kafka、Kinesis 和 Azure 事件中樞) 具有對等的讀取器選項,可達到相同的行為。
將過去 3 年的資料回填補足
現在您想要新增一或多個流程來回填先前的資料。 在此範例中,請執行下列步驟:
- 使用
append once流程。 這會執行一次性回填,而不會在第一次回填之後繼續執行。 程式碼會保留在您的管線中,如果管線已完全重新整理,則會重新執行回填。 - 建立三個回填流程,每年一個 (在此情況下,資料會在路徑中依年份分割)。 對於 Python,我們參數化流程的建立,但在 SQL 中,我們重複程式碼三次,每個流程一次。
如果您正在處理自己的專案,並且未使用無伺服器運算,您可能想要更新管線的最大工作者數量。 增加工作者數目上限可確保您有資源來處理歷程記錄資料,同時繼續在預期的 SLA 內處理目前的串流資料。
小提示
如果您使用無伺服器運算搭配增強型自動擴展 (預設值),則當負載增加時,叢集的大小會自動增加。
Python
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
backfill_years = spark.conf.get("backfill_years") # e.g. "2024,2023,2022"
incremental_load_path = f"{source_root_path}/*/*/*"
# meta programming to create append once flow for a given year (called later)
def setup_backfill_flow(year):
backfill_path = f"{source_root_path}/year={year}/*/*"
@dp.append_flow(
target="registration_events_raw",
once=True,
name=f"flow_registration_events_raw_backfill_{year}",
comment=f"Backfill {year} Raw registration events")
def backfill():
return (
spark
.read
.format("json")
.option("inferSchema", "true")
.load(backfill_path)
)
# create the streaming table
dp.create_streaming_table(name="registration_events_raw", comment="Raw registration events")
# append the original incremental, streaming flow
@dp.append_flow(
target="registration_events_raw",
name="flow_registration_events_raw_incremental",
comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2024-12-31T23:59:59.999+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}")
)
# parallelize one time multi years backfill for faster processing
# split backfill_years into array
for year in backfill_years.split(","):
setup_backfill_flow(year) # call the previously defined append_flow for each year
SQL
-- create the streaming table
CREATE OR REFRESH STREAMING TABLE registration_events_raw;
-- append the original incremental, streaming flow
CREATE FLOW
registration_events_raw_incremental
AS INSERT INTO
registration_events_raw BY NAME
SELECT * FROM STREAM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025';
-- one time backfill 2024
CREATE FLOW
registration_events_raw_backfill_2024
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2024/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2023
CREATE FLOW
registration_events_raw_backfill_2023
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2023/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2022
CREATE FLOW
registration_events_raw_backfill_2022
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2022/*/*",
format => "json",
inferColumnTypes => true
);
此實作會強調數個重要模式。
關注點分離
- 增量處理與回填作業無關。
- 每個流程都有自己的組態和最佳化設定。
- 增量作業和回填作業之間有明顯的區別。
受控執行
- 使用該
ONCE選項可確保每個回填只執行一次。 - 回填流程會保留在管線圖表中,但在完成後會變成閒置。 它已準備好在完全刷新時自動使用。
- 管線定義中有回填作業的明確稽核追蹤。
處理最佳化
- 您可以將大型回填區分割成多個較小的回填區,以加快處理速度,或控制處理。
- 使用增強型自動調整會根據目前的叢集負載動態調整叢集大小。
綱要演進
- 使用
schemaEvolutionMode="addNewColumns"能夠優雅地處理結構描述變更。 - 您在歷史和目前資料之間具有一致的結構描述推斷。
- 在較新的資料中可以安全地處理新資料行。