串流表是一種 Delta 表格,並具備額外串流或增量資料處理的支援。 串流表可以作為管線中一個或多個流的目標。
串流數據表是數據擷取的絕佳選擇,原因如下:
- 每個輸入數據行只會處理一次,這樣可模擬絕大多數資料擷取工作負載(也就是說,藉由將數據行附加或更新插入到數據表中)。
- 它們可以處理大量只能附加的資料。
串流表也是低延遲串流轉換的好選擇,因為它們能跨越列與時間窗口進行推理,處理大量資料,並提供低延遲處理。
下圖展示了資料流如何從串流來源讀取,並逐步寫入在一個管道內的串流表。
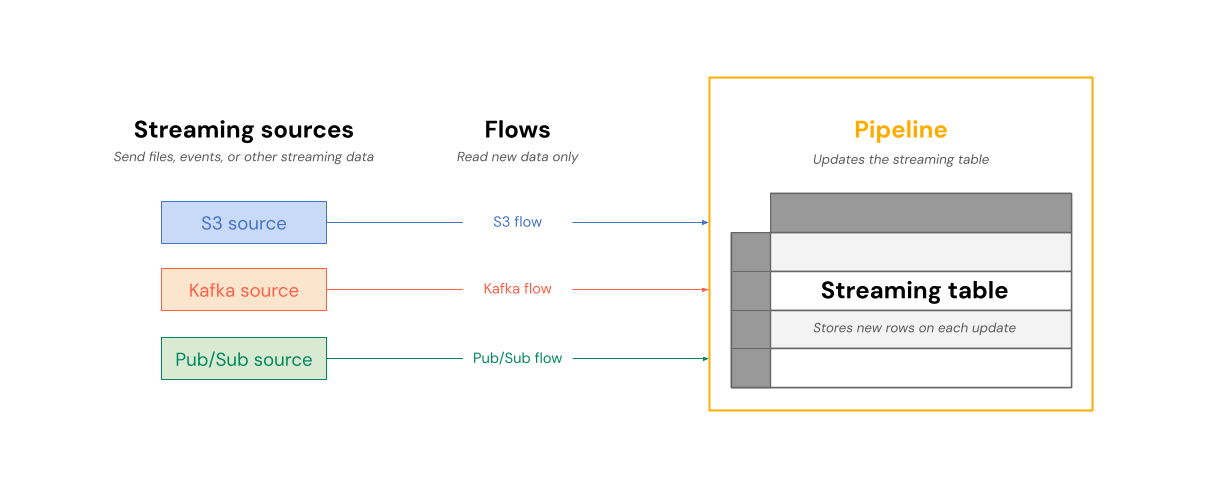
每次更新時,與串流資料表相關的流程會讀取串流來源中變更的資訊,並將新資訊附加到該資料表。
串流資料表由單一管線擁有並更新。 您會在管線的原始碼中明確定義串流資料表。 管線所定義的數據表無法由任何其他管線變更或更新。 您可以定義多個流程,以附加至單一串流數據表。
Azure Databricks 建立內部資料表以支援串流資料表處理。 這些表格會出現在 system.information_schema.tables 中,但在目錄檔案總管和其他工作區 UI 頁面中不可見。
備註
當你使用 Databricks SQL 在管線外建立串流資料表時,Azure Databricks 會建立一個用來更新資料表的管線。 您可以從工作區的左側導覽中選取 [作業與管線] 來查看管線。 您可以將 [管線類型 ] 資料行新增至檢視。 在管線中定義的串流資料表具有類型 ETL。 在 Databricks SQL 中建立的串流資料表的類型為MV/ST。
如需流程的詳細資訊,請參閱 使用 Lakeflow Spark 宣告式管線流程以累加方式載入和處理資料。
用於資料擷取的串流表
串流數據表是專為僅附加數據源所設計,且只會處理輸入一次。 這使得它們非常適合資料持續傳入且必須可靠擷取且不需重新處理現有紀錄的擷取工作負載。 Azure Databricks 支援從雲端儲存和串流訊息匯流排匯入資料。
從雲端儲存匯入檔案
你可以用串流表從雲端儲存空間中導入新檔案。 這些範例使用 Auto Loader 在新檔案抵達時逐步處理。
Python
from pyspark import pipelines as dp
# Create a streaming table
@dp.table
def customers_bronze():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.load("/Volumes/path/to/files")
)
要建立串流資料表,資料集定義必須是串流類型。 當你在資料集定義中使用這個 spark.readStream 函式時,它會回傳一個串流資料集。
SQL
-- Create a streaming table
CREATE OR REFRESH STREAMING TABLE customers_bronze
AS SELECT * FROM STREAM read_files(
"/volumes/path/to/files",
format => "json"
);
串流資料表需要串流資料集。 關鍵字STREAM在read_files之前,指示查詢將資料集視為串流。
接收串流訊息
你也可以用串流資料表從訊息匯流排擷取資料。 以下範例示範如何建立一個串流表,從 Pub/Sub 主題中讀取資料。
Python
@dp.table
def pubsub_raw():
auth_options = {
"clientId": client_id,
"clientEmail": client_email,
"privateKey": private_key,
"privateKeyId": private_key_id
}
return (
spark.readStream
.format("pubsub")
.option("subscriptionId", "my-subscription")
.option("topicId", "my-topic")
.option("projectId", "my-project")
.options(auth_options)
.load()
)
SQL
CREATE OR REFRESH STREAMING TABLE pubsub_raw
AS SELECT * FROM STREAM read_pubsub(
subscriptionId => 'my-subscription',
projectId => 'my-project',
topicId => 'my-topic',
clientEmail => secret('pubsub-scope', 'clientEmail'),
clientId => secret('pubsub-scope', 'clientId'),
privateKeyId => secret('pubsub-scope', 'privateKeyId'),
privateKey => secret('pubsub-scope', 'privateKey')
);
Databricks 建議在提供授權選項時使用秘密。 請參閱 「設定 Access to Pub/Sub 」以了解所有認證選項。
如需將資料載入串流資料表的詳細資訊,請參閱 在管線中載入資料。
下圖表說明僅附加串流資料表的工作原理。

已經附加到串流表的列,在後續更新流程時不會被重新查詢。 如果你修改查詢(例如從 SELECT LOWER (name) 到 SELECT UPPER (name)),現有的列不會更新為大寫,但新的列會是大寫。 你可以觸發一次完整更新,重新查詢來源資料表中過去的所有數據,以更新串流資料表中的所有列。
串流表與低延遲串流
串流數據表是針對透過限定狀態進行低延遲串流所設計。 串流數據表會使用檢查點管理,使其非常適合用於低延遲串流。 不過,它們預期資料流是自然界限或受限於水印。
自然系結數據流是由具有妥善定義開始和結束的串流數據源所產生。 自然系結數據流的範例是從檔案目錄讀取數據,其中在放置初始檔案批次之後,不會新增任何新檔案。 該串流被視為有界,因為檔案數量有限,且在所有檔案處理完畢後串流結束。
您也可以使用水印來綁定資料流。 結構化串流中的浮水印是一種機制,透過指定系統應等待延遲事件多久,才會將時間窗口視為完成,來協助處理延遲資料。 沒有水印的無界限的資料流可能會導致管線因為記憶體壓力而失敗。
如需具狀態串流處理的詳細資訊,請參閱 使用浮水印最佳化有狀態處理。
串流快照連結
串流快照連接(Stream-snapshot joins)將串流資料集連接到一個在串流開始時快照的維度資料表。 由於維度表在該時間點被視為固定,串流開始後對其所做的任何變更不會反映在連接中。 當小差異不重要時,這種做法是可以接受的——例如,交易數量比客戶數量多出許多個數量級。
以下程式碼範例將一個名為customers的維度表有兩列,與一個不斷增長的資料集transactions進行連接。 它將這兩個資料集的連接呈現在一個稱為 sales_report的表格中。 如果外部程序透過新增一列()customer_id=3, name=Zoya更新客戶資料表,該新資料列將不會出現在連接中,因為靜態維度資料表在串流啟動時已被快照。
from pyspark import pipelines as dp
@dp.temporary_view
# assume this table contains an append-only stream of rows about transactions
# (customer_id=1, value=100)
# (customer_id=2, value=150)
# (customer_id=3, value=299)
# ... <and so on> ...
def v_transactions():
return spark.readStream.table("transactions")
# assume this table contains only these two rows about customers
# (customer_id=1, name=Bilal)
# (customer_id=2, name=Olga)
@dp.temporary_view
def v_customers():
return spark.read.table("customers")
@dp.table
def sales_report():
facts = spark.readStream.table("v_transactions")
dims = spark.read.table("v_customers")
return facts.join(dims, on="customer_id", how="inner")
串流數據表限制
串流資料表有下列限制:
-
有限演化: 你可以更改查詢,而不必重新計算整個資料集。 若沒有完整刷新,串流資料表每列只會被讀取一次,因此不同的查詢會處理不同的列。 例如,如果你將
UPPER()添加到查詢中的某個欄位,那麼只有變更後處理的列會變成大寫。 這表示你必須知道所有先前版本的查詢都在你的資料集中執行。 若要重新處理變更之前已處理的現有資料列,需要完整重新整理。 - 狀態管理: 串流資料表具有低延遲,並且需要天然有界或使用浮水印界定界限的串流。 如需詳細資訊,請參閱 使用浮水印最佳化有狀態處理。
- 聯結不會重新計算: 串流數據表中的聯結不會在維度變更時重新計算。 此特性適用於「快速但易錯」的情況。 如果你希望你的觀點永遠正確,你可能會想使用物質化視角。 具體化檢視一律正確,因為它們會在維度變更時自動重新計算聯結。 如需詳細資訊,請參閱 具體化檢視。