學習如何使用 Lakeflow Spark 宣告式管線(SDP)建立新的管線以進行資料編排與自動載入器。 此教學透過清理資料並建立查詢,擴展範例流程,找出前 100 名使用者。
在這個教學中,你將學習如何使用 Lakeflow 管線編輯器來:
- 建立一個預設資料夾結構的新管線,並從一組範例檔案開始。
- 利用期望定義資料品質約束。
- 利用編輯器功能擴展管線,新增轉換以進行資料分析。
需求
在開始這個教學之前,你必須:
- 登入 Azure Databricks 工作區。
- 請在你的工作空間啟用 Unity Catalog。
- 必須為您的工作區啟用 Lakeflow pipelines 編輯器,並且您需要選擇加入。 請參閱 啟用 Lakeflow 管線編輯器和更新的監控。
- 擁有建立運算資源或存取運算資源的權限。
- 擁有在目錄中建立新架構的權限。 必要的權限為
ALL PRIVILEGES或USE CATALOG與 。CREATE SCHEMA
步驟 1:建立管線
在此步驟中,你將使用預設的資料夾結構和程式碼範例建立一個管線。 程式碼範例會參考 users 範例資料來源中的 wanderbricks 表格。
在你的 Azure Databricks 工作區中,點選
 新建,然後
新建,然後  ETL 流程。 這會開啟管線編輯器,在「建立管線」頁面。
ETL 流程。 這會開啟管線編輯器,在「建立管線」頁面。點擊標頭即可為您的管線命名。
在名稱下方,選擇輸出表的預設目錄和結構。 當您在管線定義中未指定目錄與結構時,會使用此工具。
在管線的下一步中,根據您的語言偏好,點選
 您可以從 SQL 的範例程式碼開始,或點選 從 Python 的範例程式碼開始。 這會改變範例程式碼的預設語言,但你可以之後再加入另一種語言的程式碼。 這會建立一個預設的資料夾結構,並附上範例程式碼,幫助你開始使用。
您可以從 SQL 的範例程式碼開始,或點選 從 Python 的範例程式碼開始。 這會改變範例程式碼的預設語言,但你可以之後再加入另一種語言的程式碼。 這會建立一個預設的資料夾結構,並附上範例程式碼,幫助你開始使用。你可以在工作區左側的管線資產瀏覽器中查看範例程式碼。 在
transformations下,有兩個檔案,各自產生一個管道資料集。 下面explorations有一本筆記本,裡面有程式碼幫助你查看管線的輸出。 點擊檔案後,你可以在編輯器中查看並編輯程式碼。輸出資料集尚未建立,螢幕右側的 管線圖 是空白的。
要執行管線程式碼(資料夾中的
transformations程式碼),請點擊畫面右上角的 「執行管線 」。執行結束後,工作區底部會顯示兩個新建立的資料表,
sample_users_<pipeline-name>以及sample_aggregation_<pipeline-name>。 你也可以看到工作區右側的 管線圖 現在顯示了兩個表格,其中那sample_users就是 的sample_aggregation來源。
步驟2:套用資料品質檢查
此步驟中,你會在 sample_users 表格中新增資料品質檢查。 你用 管線期望 來限制資料。 此時,刪除所有沒有有效電子郵件地址的使用者紀錄,並將清理後的資料表輸出為 users_cleaned。
在管線資產瀏覽器中,點選
然後選擇 轉換。在 「建立新轉換檔案 」對話框中,請做出以下選擇:
- 選擇 Python 或 SQL 作為語言。 這不必與你之前的選擇相同。
- 給檔案取個名字。 在這裡情況下,請選擇
users_cleaned。 - 對於 目的地路徑,保留預設路徑。
- 關於 資料集類型,可以保留無選擇,或者選擇 實體化檢視。 如果你選擇 Materialized 視圖,它會幫你產生範例程式碼。
在你的新程式碼檔案中,根據你在前一畫面的選擇,請修改程式碼以符合以下內容(使用 SQL 或 Python)。 請用完整名稱替換你的
sample_users資料表<pipeline-name>。SQL
-- Drop all rows that do not have an email address CREATE MATERIALIZED VIEW users_cleaned ( CONSTRAINT non_null_email EXPECT (email IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM sample_users_<pipeline-name>;Python
from pyspark import pipelines as dp # Drop all rows that do not have an email address @dp.table @dp.expect_or_drop("no null emails", "email IS NOT NULL") def users_cleaned(): return ( spark.read.table("sample_users_<pipeline_name>") )點選 「執行管線 」以更新管線。 現在應該有三張桌子。
步驟三:分析頂尖用戶
接著,根據他們創造的預約數量,列出前 100 名用戶。 將wanderbricks.bookings資料表連接到users_cleaned實體檢視表。
在管線資產瀏覽器中,點選
然後選擇 轉換。在 「建立新轉換檔案 」對話框中,請做出以下選擇:
- 選擇 Python 或 SQL 作為語言。 這不必與你之前的選擇相符。
- 給檔案取個名字。 在這裡情況下,請選擇
users_and_bookings。 - 對於 目的地路徑,保留預設路徑。
- 對於 資料集類型,請保留為 「無選擇」。
在你的新程式碼檔案中,根據你在前一畫面的選擇,請修改程式碼以符合以下內容(使用 SQL 或 Python)。
SQL
-- Get the top 100 users by number of bookings CREATE OR REFRESH MATERIALIZED VIEW users_and_bookings AS SELECT u.name AS name, COUNT(b.booking_id) AS booking_count FROM users_cleaned u JOIN samples.wanderbricks.bookings b ON u.user_id = b.user_id GROUP BY u.name ORDER BY booking_count DESC LIMIT 100;Python
from pyspark import pipelines as dp from pyspark.sql.functions import col, count, desc # Get the top 100 users by number of bookings @dp.table def users_and_bookings(): return ( spark.read.table("users_cleaned") .join(spark.read.table("samples.wanderbricks.bookings"), "user_id") .groupBy(col("name")) .agg(count("booking_id").alias("booking_count")) .orderBy(desc("booking_count")) .limit(100) )點擊 「執行管線 」以更新資料集。 當執行完成後,你可以在 管線圖 中看到有四個表格,包括新的
users_and_bookings表格。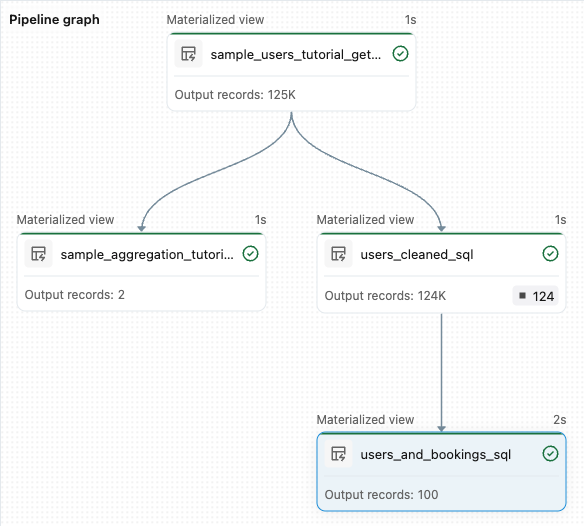
後續步驟
現在你已經學會如何使用 Lakeflow pipelines 編輯器的一些功能並建立了管線,以下是一些其他功能值得你進一步了解:
在建立管線時處理及除錯轉換的工具:
內建 Databricks 資產套件 整合,可直接從編輯器進行高效協作、版本控制及 CI/CD 整合: