本文示範如何使用 基礎模型 API 部署模型,以及 配置吞吐量的過程。 Databricks 建議針對生產環境工作負載使用預配置的吞吐量,並提供具效能保證的基礎模型優化推論。
什麼是設定的吞吐量?
預配置的吞吐量指您可以同時提交到端點的請求中所能承載的 token 數量。 預先配置的吞吐量服務端點是專用的,按照每秒可傳送至端點的令牌範圍來設定。
如需詳細資訊,請參閱下列資源:
如需配置的吞吐量端點的支援模型架構清單,請參閱 馬賽克 AI 模型服務上支援的基礎模型。
要求
請參閱 規範。 如需部署微調的基礎模型,請參閱 部署微調的基礎模型。
[建議] 從 Unity 目錄部署基礎模型
重要
這項功能在 公開預覽版。
Databricks 建議使用 Unity 目錄中預先安裝的基礎模型。 您可以在結構描述 system (ai) 的目錄 system.ai 下找到這些模型。
若要部署基礎模型:
- 瀏覽至目錄總管中的
system.ai。 - 點擊要部署的模型名稱。
- 在模型頁面上,按一下「提供此模型」按鈕。
- 建立服務端點 頁面隨即出現。 請參閱 使用使用者介面建立配置的吞吐量端點。
注意
若要從 Unity 目錄中 system.ai 部署 Meta Llama 模型,您必須選擇適用的 指令 版本。 Unity 目錄中 system.ai 不支援 Meta Llama 模型的基底版本部署。 請參閱 裝載在 Databricks 支援的 Meta Llama 模型變體上的基礎模型。
從 Databricks Marketplace 部署基礎模型
或者,您可以從 Databricks Marketplace 將基礎模型安裝到 Unity 目錄。
您可以搜尋模型系列,並從模型頁面選取 [取得存取權],並提供登入認證,以將模型安裝至 Unity 目錄。
將模型安裝到 Unity 目錄之後,您可以使用服務 UI 建立模型服務端點。
部署經過微調的基礎模型
如果您無法使用 system.ai 結構描述中的模型,或從 Databricks Marketplace 安裝模型,您可以將模型記錄至 Unity 目錄,以部署微調的基礎模型。 本節和下列各節說明如何設定程式碼,以將 MLflow 模型記錄至 Unity 目錄,並使用 UI 或 REST API 建立佈建的輸送量端點。
如需支援的 Meta Llama 3.1、3.2 和 3.3 微調模型及其區域可用性,請參閱 Databricks 上裝載 的基礎模型。
要求
- MLflow 2.11 或更新版本僅支援部署微調的基礎模型。 Databricks Runtime 15.0 ML 和更新版本會預安裝相容的 MLflow 版本。
- Databricks 建議在 Unity 目錄中使用模型,以便更快速地上傳和下載大型模型。
定義目錄、結構描述和模型名稱
若要部署微調的基礎模型,請定義目標 Unity 目錄、結構描述和您選擇的模型名稱。
mlflow.set_registry_uri('databricks-uc')
CATALOG = "catalog"
SCHEMA = "schema"
MODEL_NAME = "model_name"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
記錄您的模型
若要啟用模型端點的布建吞吐量,您必須使用 MLflow transformers 風格來記錄模型,並在下列選項中,使用適當的模型類型介面來指定 task 參數:
"llm/v1/completions""llm/v1/chat""llm/v1/embeddings"
這些自變數會指定用於服務端點之模型的 API 簽章。 如需這些工作和對應輸入/輸出架構的詳細資訊,請參閱 MLflow 檔。
以下是如何將文字完成語言模型記錄在 MLflow 中的範例:
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.3-70B-Instruct", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.3-70B-Instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
# Specify the llm/v1/xxx task that is compatible with the model being logged
task="llm/v1/completions",
# Specify an input example that conforms to the input schema for the task.
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
# By passing the model name, MLflow automatically registers the Transformers model to Unity Catalog with the given catalog/schema/model_name.
registered_model_name=registered_model_name
# Optionally, you can set save_pretrained to False to avoid unnecessary copy of model weight and gain more efficiency.
save_pretrained=False
)
注意
如果您使用 2.12 之前的 MLflow,則必須改為在相同 metadata 函式的 mlflow.transformer.log_model() 參數內指定工作。
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
配置的吞吐量也支持基礎和大型 GTE 嵌入模型。 以下是如何記錄模型 Alibaba-NLP/gte-large-en-v1.5 的範例,以便在已配置的吞吐量下提供服務:
model = AutoModel.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "gte-large"
}
)
在將您的模型記錄到 Unity Catalog 之後,繼續使用 UI 建立具備佈建輸送量的端點,以創建具有佈建輸送量的服務模型端點。
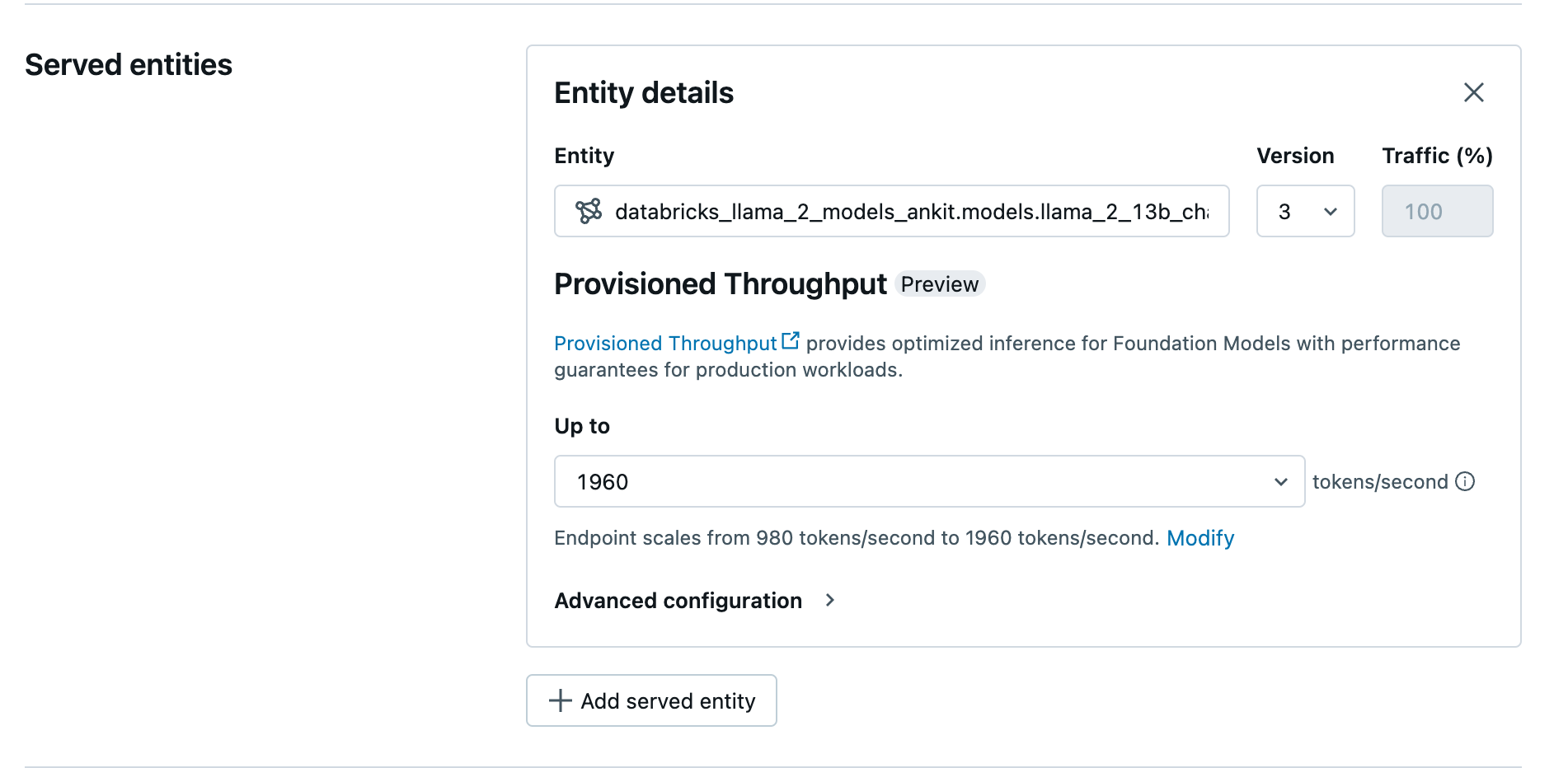
使用使用者介面(UI)建立配置的傳輸量端點
在已記錄的模型進入 Unity Catalog 後,使用下列步驟建立佈建的處理量服務端點。
- 前往您的工作區中的 Serving UI。
- 選取 [建立服務端點]。
- 在 [實體] 欄位中,從 Unity 目錄選取您的模型。 針對符合資格的模型,服務實例的UI將顯示 配置的吞吐量 畫面。
- 在 [最多] 的下拉式選單中,您可以配置您的端點每秒的最大令牌吞吐量。
- 配置的吞吐量端點會自動調整,因此您可以選取 [修改],以檢視端點每秒可縮減到的最少權杖數。
使用 REST API 建立布建的輸送量端點
若要使用 REST API 在布建的輸送量模式中部署模型,您必須在要求中指定 min_provisioned_throughput 和 max_provisioned_throughput 字段。 如果您想要 Python,您也可以使用 MLflow 部署 SDK建立端點
若要識別模型的適當佈建輸送量範圍,請參閱以遞增方式取得布建的輸送量。
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "prov-throughput-endpoint"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.foundation-model"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = "<YOUR-API-URL>"
API_TOKEN = "<YOUR-API-TOKEN>"
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
聊天完成工作的記錄機率
對於聊天任務之完成,您可以使用 logprobs 參數來提供令牌在大型語言模型生成過程中被取樣出現的對數概率。 您可以針對各種案例使用 logprobs,包括分類、評估模型不確定性,以及執行評估計量。 如需參數詳細數據,請參閱 聊天工作。
以遞增方式獲得佈建的吞吐量
預配置的吞吐量是以每秒令牌的增量來提供,不同的增量單位會隨著模型而改變。 若要識別適合您需求的範圍,Databricks 建議在平臺中使用模型優化資訊 API。
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
以下是來自 API 的範例回應:
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
筆記本範例
下列筆記本示範如何建立布建輸送量基礎模型 API 的範例:
為 GTE 模型筆記本預配置的吞吐量服務
BGE 模型筆記本的預設吞吐量服務
下列筆記本示範如何在 Unity Catalog 中下載並註冊 DeepSeek R1 蒸餾 Llama 模型,以便您可以使用已配置的 Foundation Model API 吞吐量端點來部署它。
DeepSeek R1 蒸餾 Llama 模型筆記本的預設吞吐量服務
局限性
- 模型部署可能會因為 GPU 容量問題而失敗,進而導致端點建立或更新期間發生逾時。 請連絡 Databricks 帳戶小組以協助解決。
- 基礎模型 API 的自動調整速度比 CPU 模型服務慢。 Databricks 建議使用超量配置,以避免請求超時。
- GTE v1.5 (英文) 不會產生正規化的內嵌。