在 Azure Databricks 上執行 MLflow 專案
MLflow 專案是以可重複使用且可重現的方式封裝數據科學程式碼的格式。 MLflow Projects 元件包含用於執行專案的 API 和命令行工具,其也會與追蹤元件整合,以自動記錄原始碼的參數和 Git 認可,以重現性。
本文說明 MLflow 專案的格式,以及如何使用 MLflow CLI 從遠端在 Azure Databricks 叢集上執行 MLflow 專案,這可讓您輕鬆地垂直調整數據科學程式碼。
MLflow 專案格式
任何本機目錄或 Git 存放庫都可以視為 MLflow 專案。 下列慣例會定義專案:
- 項目的名稱是目錄的名稱。
- 如果存在,則會在 中
python_env.yaml指定軟體環境。python_env.yaml如果沒有檔案存在,MLflow 會在執行專案時使用只包含 Python 的 virtualenv 環境(特別是 virtualenv 可用的最新 Python)。 - 專案中的任何
.py或.sh檔案都可以是進入點,且未明確宣告任何參數。 當您使用一組參數執行這類命令時,MLflow 會使用--key <value>語法在命令行上傳遞每個參數。
您可以藉由新增 MLproject 檔案來指定更多選項,這是 YAML 語法中的文字檔。 範例 MLproject 檔案看起來像這樣:
name: My Project
python_env: python_env.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
針對 Databricks Runtime 13.0 ML 和更新版本,MLflow 項目無法在 Databricks 作業類型叢集中成功執行。 若要將現有的 MLflow 專案移轉至 Databricks Runtime 13.0 ML 和更新版本,請參閱 MLflow Databricks Spark 作業專案格式。
MLflow Databricks Spark 作業專案格式
MLflow Databricks Spark 作業專案是 MLflow 2.14 中引進的新 MLflow 專案。 此專案類型支援從 Spark 作業叢集中執行 MLflow 專案,而且只能使用 「databricks」 後端執行。 以下是這個新項目類型的檔案範例 MLproject :
name: My Project
databricks_spark_job:
python_file: "train.py" # the file which is the entry point file to execute
parameters: ["param1", "param2"] # a list of parameter strings
python_libraries: # dependencies required by this project
- mlflow==2.4.1 # MLflow dependency is required
- scikit-learn
Databricks Spark 作業項目不支援在 MLproject 檔案中指定下列區段: entry_points、 docker_env、 python_env或 conda_env。 您可以在 區段的 databricks_spark_job 欄位中指定python_libraries項目的相依性。 無法使用此項目類型自定義 Python 版本。 執行環境必須使用主要 Spark 驅動程式運行時間環境,在使用 Databricks Runtime 13.0 或更新版本的工作叢集中執行。 同樣地,定義為專案所需的所有 Python 相依性都必須安裝為 Databricks 叢集相依性。 此行為與先前的專案執行行為不同,其中連結庫需要安裝在不同的環境中。
執行 MLflow 專案
若要在預設工作區的 Azure Databricks 叢集上執行 MLflow 專案,請使用 命令:
mlflow run <uri> -b databricks --backend-config <json-new-cluster-spec>
其中 <uri> 是包含 MLflow 專案的 Git 存放庫 URI 或資料夾,而 <json-new-cluster-spec> 是包含 new_cluster結構的 JSON 檔。 Git URI 的格式應為: https://github.com/<repo>#<project-folder>。
範例叢集規格如下:
{
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
}
如果您需要在背景工作角色上安裝連結庫,請使用「叢集規格」格式。 請注意,Python 轉輪檔案必須上傳至 DBFS,並指定為 pypi 相依性。 例如:
{
"new_cluster": {
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
},
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
},
{
"pypi": {
"package": "/dbfs/path_to_my_lib.whl"
}
}
]
}
重要
.eggMLflow 項目不支援 和.jar相依性。- 不支援使用 Docker 環境的 MLflow 專案執行。
- 在 Databricks 上執行 MLflow 專案時,您必須使用新的叢集規格。 不支援對現有叢集執行專案。
使用SparkR
若要在 MLflow 專案執行中使用 SparkR,您的專案程式代碼必須先安裝並匯入 SparkR,如下所示:
if (file.exists("/databricks/spark/R/pkg")) {
install.packages("/databricks/spark/R/pkg", repos = NULL)
} else {
install.packages("SparkR")
}
library(SparkR)
您的項目接著可以初始化 SparkR 工作階段,並使用 SparkR 正常運作:
sparkR.session()
...
例
此範例示範如何建立實驗、在 Azure Databricks 叢集上執行 MLflow 教學課程專案、檢視作業執行輸出,以及檢視實驗中的執行。
需求
- 使用
pip install mlflow安裝 MLflow。 - 安裝及設定 Databricks CLI。 需要 Databricks CLI 驗證機制,才能在 Azure Databricks 叢集上執行作業。
步驟 1:建立實驗
在工作區中,選取 [ 建立 > MLflow 實驗]。
在 [名稱] 欄位中輸入
Tutorial。按一下 [建立]。 記下實驗標識碼。 在此範例中,它是
14622565。
步驟 2:執行 MLflow 教學課程專案
下列步驟會設定 MLFLOW_TRACKING_URI 環境變數並執行專案、將定型參數、計量和定型模型記錄到上一個步驟中記下的實驗:
將
MLFLOW_TRACKING_URI環境變數設定為 Azure Databricks 工作區。export MLFLOW_TRACKING_URI=databricks執行 MLflow 教學課程項目,訓練 葡萄酒模型。 將取代
<experiment-id>為您在上一個步驟中注意到的實驗標識碼。mlflow run https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine -b databricks --backend-config cluster-spec.json --experiment-id <experiment-id>=== Fetching project from https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine into /var/folders/kc/l20y4txd5w3_xrdhw6cnz1080000gp/T/tmpbct_5g8u === === Uploading project to DBFS path /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Finished uploading project to /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Running entry point main of project https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine on Databricks === === Launched MLflow run as Databricks job run with ID 8651121. Getting run status page URL... === === Check the run's status at https://<databricks-instance>#job/<job-id>/run/1 ===複製 MLflow 執行輸出最後一行中的 URL
https://<databricks-instance>#job/<job-id>/run/1。
步驟 3:檢視 Azure Databricks 作業執行
開啟您在瀏覽器中上一個步驟中複製的網址,以檢視 Azure Databricks 作業執行輸出:
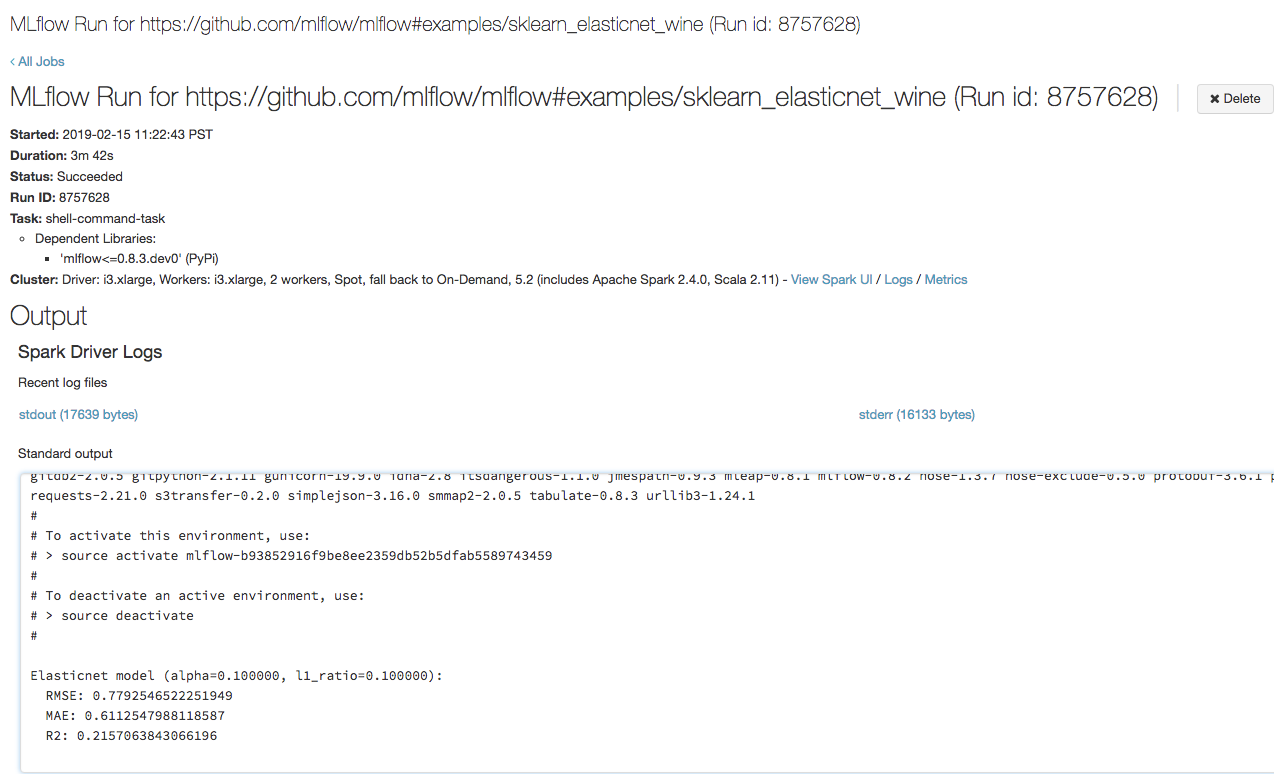
步驟 4:檢視實驗和 MLflow 執行詳細數據
流覽至 Azure Databricks 工作區中的實驗。
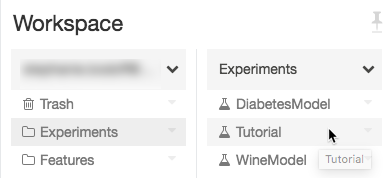
按兩下實驗。
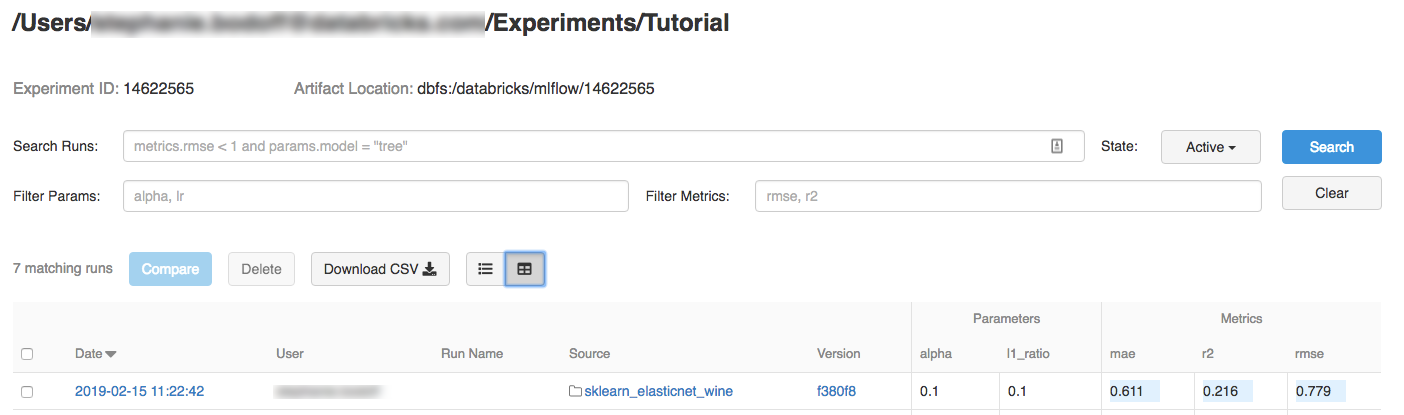
若要顯示執行詳細數據,請按兩下 [日期] 資料行中的連結。
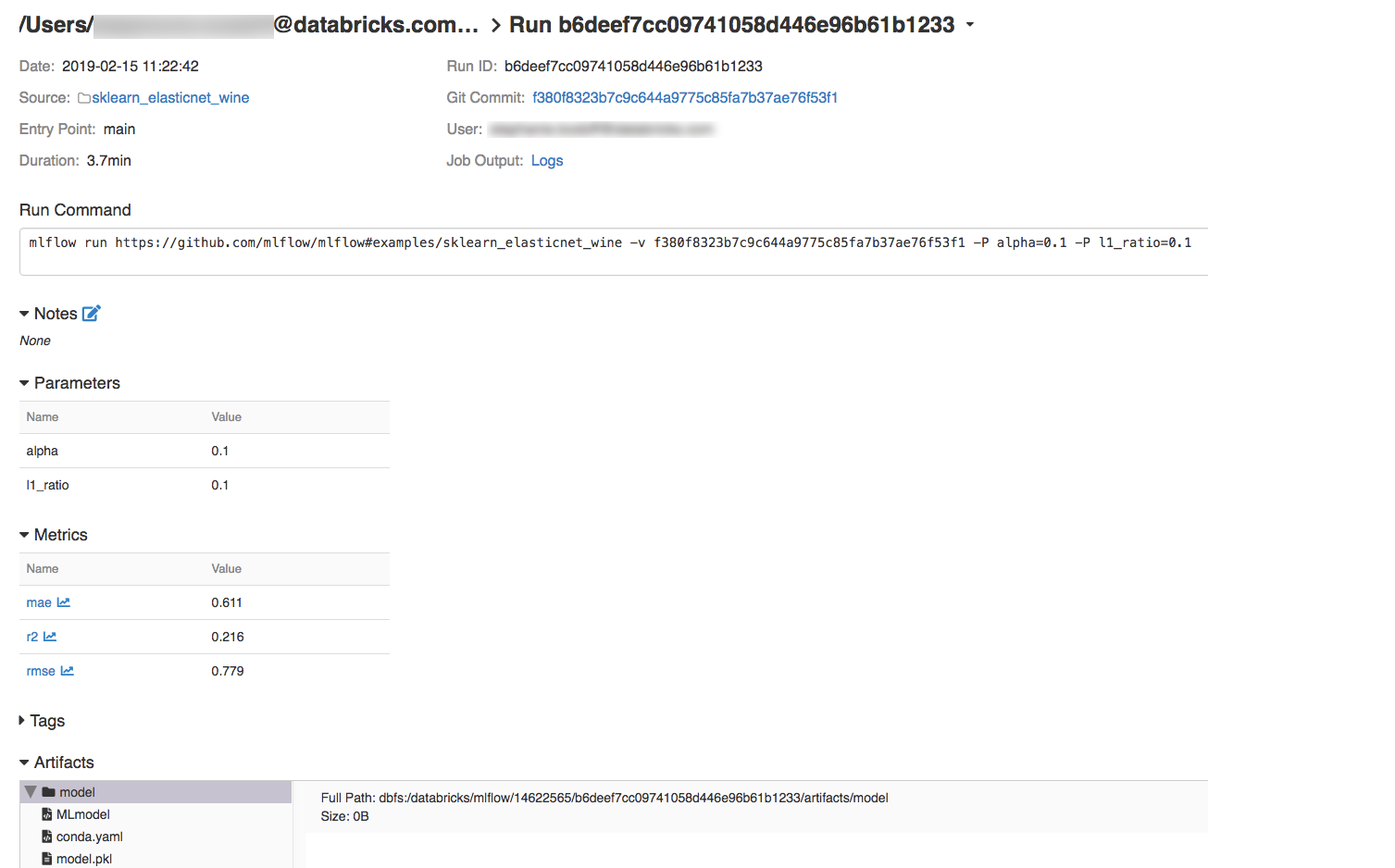
您可以按下 [作業輸出] 字段中的 [記錄 ] 連結,檢視執行中的記錄。
資源
如需一些範例 MLflow 專案,請參閱 MLflow 應用程式連結庫,其中包含一個已準備好執行的專案存放庫,旨在讓您輕鬆地將 ML 功能納入您的程式代碼。
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應