這很重要
湖底自動縮放可在以下地區使用:eastus,eastus2,centralus,southcentralus,westus,westus2,canadacentral,brazilsouth,northeurope,uksouth,westeurope,australiaeast,centralindia,southeastasia。
Lakebase 自動縮放是 Lakebase 的最新版本,具備自動縮放計算、縮放至零、分支及即時還原功能。 如果你是 Lakebase Provisioned 使用者,請參見 Lakebase Provisioned。
高可用性將主要讀寫運算與一個或多個分布於不同可用性區域的次要運算實例配對。 當主運算實例無法使用時,次要運算實例會被自動提升,您的應用程式將從最後一個已提交的交易繼續執行。 你的連接線保持不變。
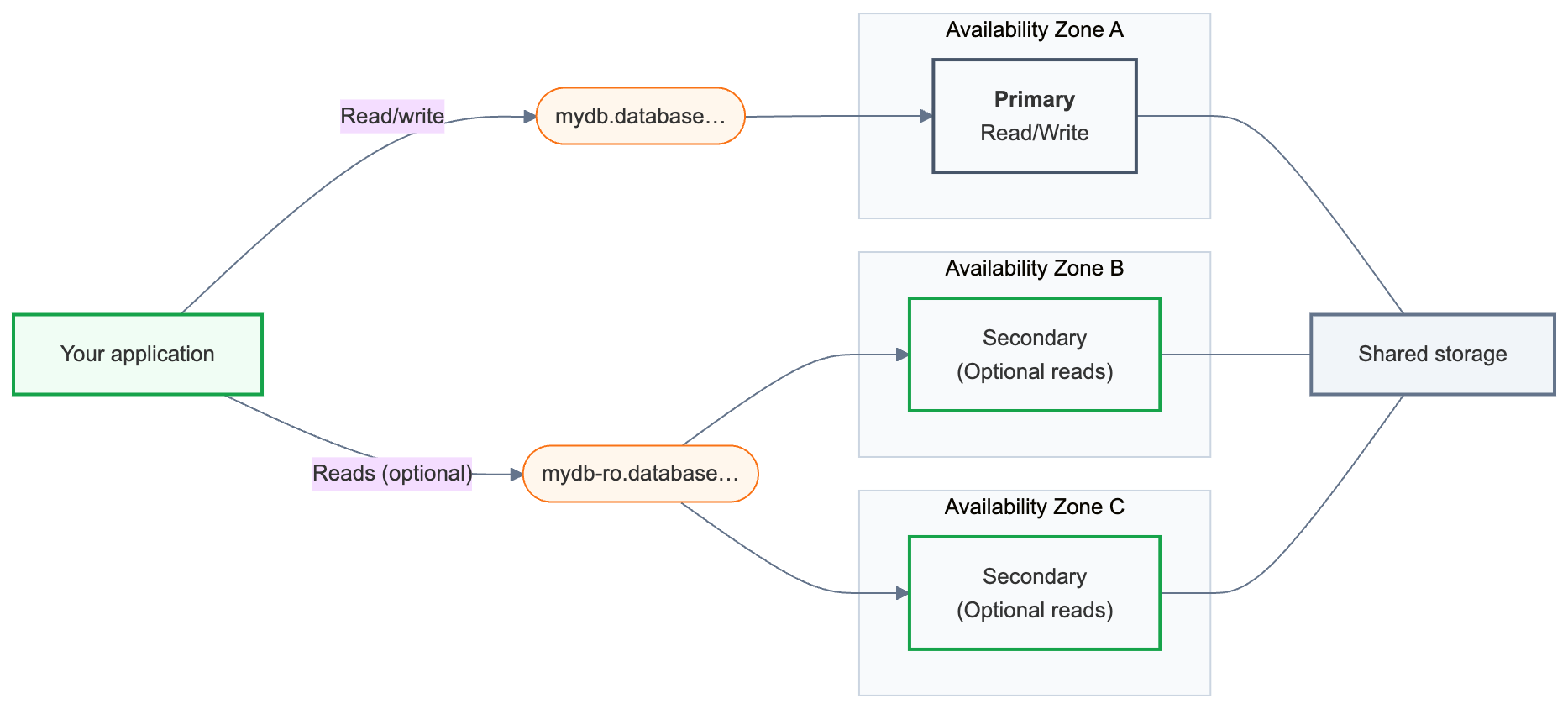
高可用性的運作方式
Lakebase 端點是你的應用程式連接的資料庫位址。 高可用性端點會暴露兩組連線串:
-
主要(
{endpoint-id}.database.{region}.databricks.com) — 您的主要讀寫連線。 在所有連接到你資料庫的應用程式中都使用這個功能。 故障轉移後,它會自動路由到現在的主要運算。 -
次要 (
{endpoint-id}-ro.database.{region}.databricks.com) — 僅在啟用允許存取唯讀運算實例時可用。 次要計算實例主要作為故障轉移待命;啟用讀取存取後,你還能將讀取查詢路由到這些實例。
這兩個連線字串都可以從你端點的 Connect 對話框中取得。
在這些連接字串背後,高可用性端點總是恰好有一個 主要 運算實例和一到三個 次要 運算實例。 主要處理所有讀寫流量。 次要運算實例在不同的可用性區域運行,並在故障時升格為主要實例。
每個次要運算實例都有一個 存取 設定,用以判斷是否同時提供讀取流量:
| 次要存取途徑 | 其功能是什麼 |
|---|---|
| 唯讀 | 次要計算實例透過 -ro 連接字串提供讀取,並可視需要升格為主要計算實例。 |
| Disabled | 次要運算實例已啟動並準備進行故障轉移,但不處理讀取流量 |
你可以在端點上的 「允許存取唯讀運算實例 」設定來控制,這個設定可以在 編輯計算 抽屜中存取。 啟用後,所有次要計算實例可提供讀取服務。停用後,它們只作為故障轉移的備援。 在這兩種情況下,運算硬體已經分配並執行中:升遷不需要重新配置,因此你的故障轉移容量會被保留,無論可用性區域的需求如何。
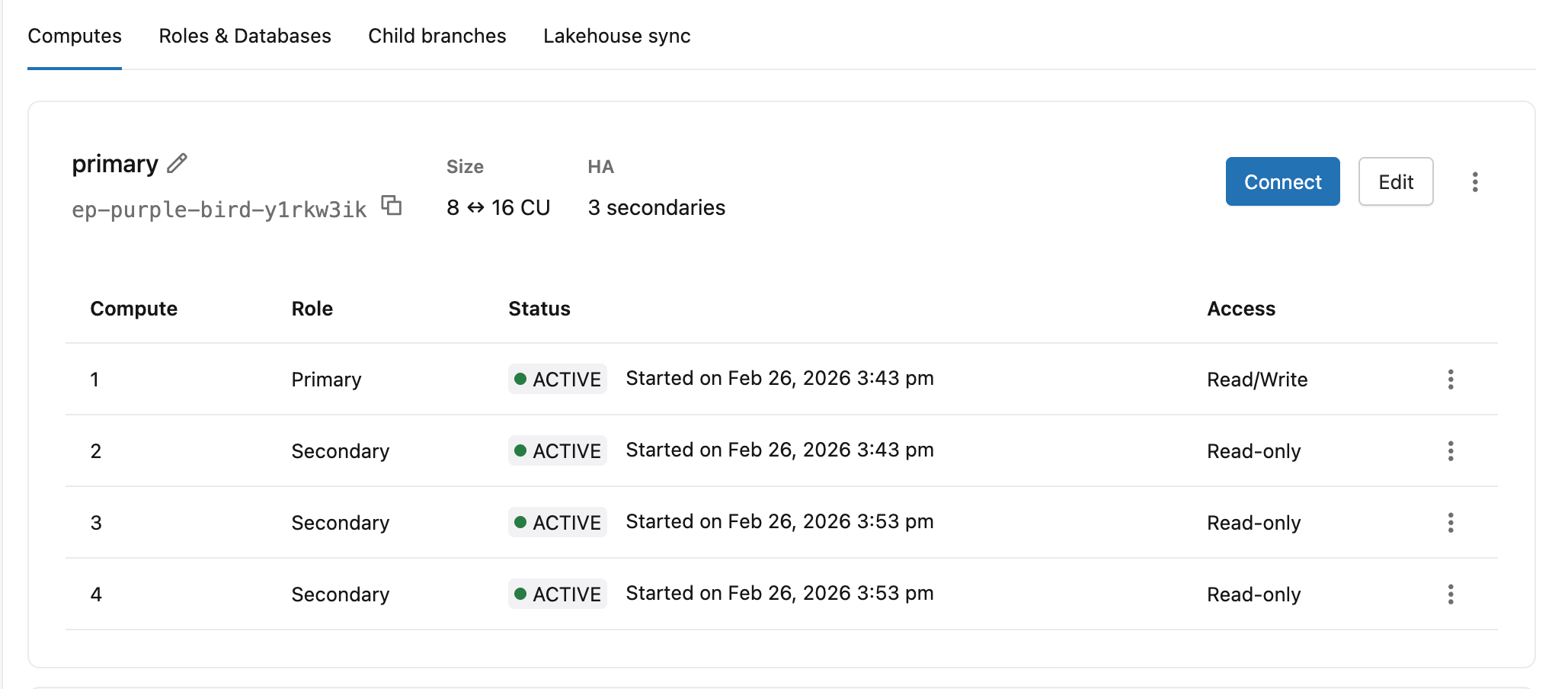
計算分頁一目了然地顯示每個計算實例 的角色(主要 或次要)、 狀態及 存取 等級。
AZ分布
Lakebase 將主運算與次要運算實例分散於可用區域,降低單一 AZ 故障同時影響主執行與所有次要運算實例的風險。
高可用性下的自動縮放
所有高可用性配置中的運算實例都共享相同的自動擴展範圍。 最小與最大 CU 之間的最大分布是 8 CU,這和獨立運算實例的限制一樣。
次要運算實例始終會縮放到與主實例相同的 CU 大小,確保你的資料庫容量在故障轉移後保持穩定。
在高可用性配置中,計算實例無法支援縮放至零。 你可以手動暫停所有運算實例,但暫停期間你的端點將無法使用。
次要運算實例與獨立讀取副本的比較
次要運算實例與獨立讀取副本是不同功能,可共存於同一分支:
| 次要計算實例 | 單獨的讀取副本 | |
|---|---|---|
| Purpose | 故障轉移 + 選擇性讀取卸載 | 僅讀取卸載 |
| 添加方式 | 高可用性配置 | 新增讀取複本 |
| 參與故障轉移 | 是的 | No |
| 連接字串 |
-ro 主要端點 |
擁有獨立端點 |
| 尺寸 | 與主要(端點層級)共享 | 尺寸獨立設置 |
當你需要同時具備高可用性和超出次級運算實例提供的額外讀取容量時,你可以將這兩者合併在同一分支上。 參見 讀取副本。
容錯移轉行為
自動故障轉移
Lakebase 持續監控主要運算的健康狀況。 當主節點無法使用時,系統會自動觸發故障切換。
故障轉移會保留所有已提交的交易。
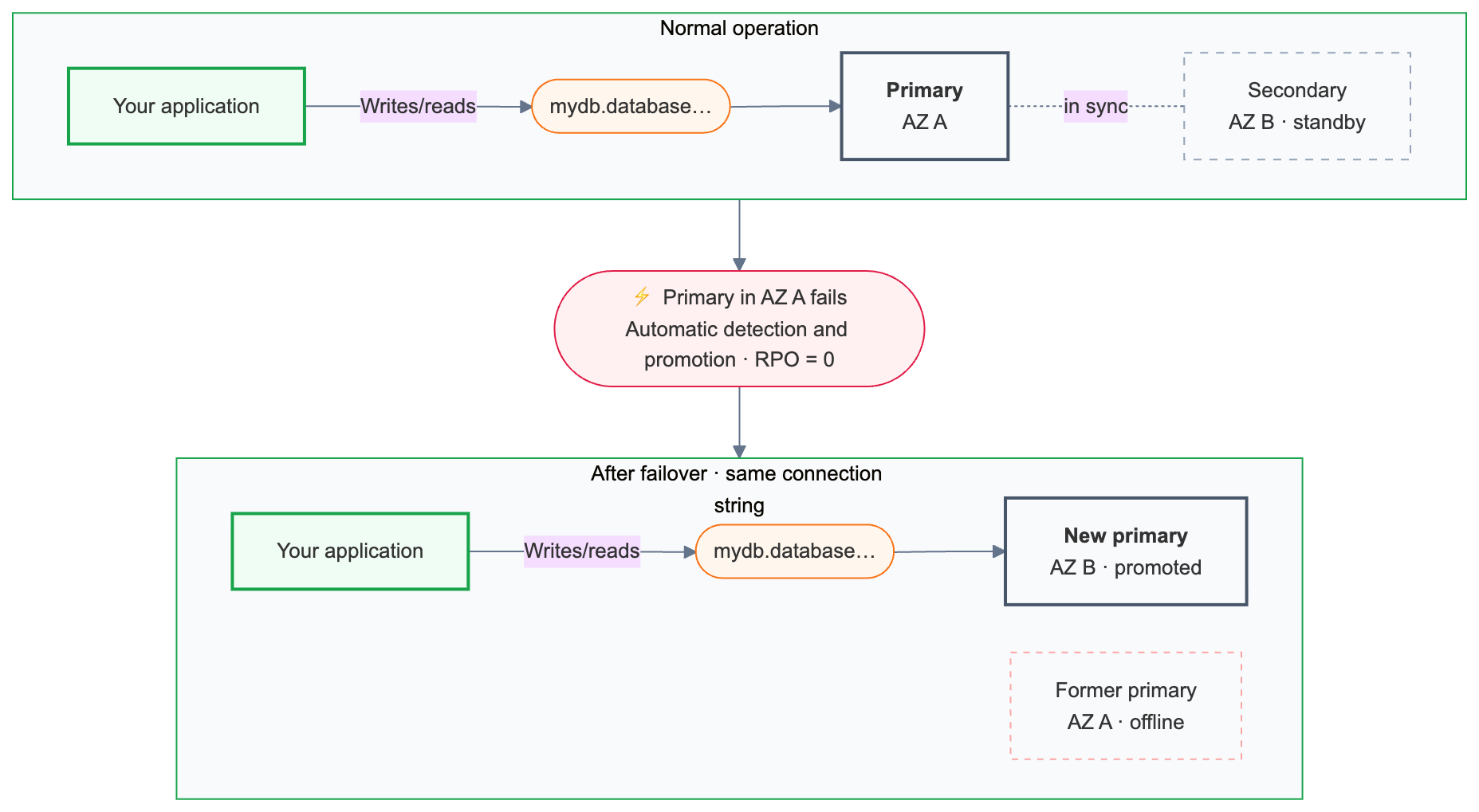
故障轉移完成後,主要連接字串{endpoint-id}.database.{region}.databricks.com會自動路由到新升級的運算實例。 應用程式不需要更改連線設定,但現有連線在故障轉移時會被終止,必須重新連接。 具有重試邏輯的應用程式會自動處理此事。
故障切換時啟用讀取存取
當啟用 「允許存取唯讀運算實例 」且發生故障轉移時,升級的次要節點將成為新的主節點,停止提供讀取。 如果你有兩個或以上可讀的次級訊號,連線串上的 -ro 讀取流量會以較低容量繼續進行,直到有替換節點配置完成。 如果只有一個,讀取會完全中斷,直到替換品準備好。
連線字串
Connect 對話框顯示兩個連線字串及其目前的運算狀態:
| Connect 對話框中的運算選項 | 連接字串 | 用途 |
|---|---|---|
Primary (name) ● Active |
{endpoint-id}.database.{region}.databricks.com |
所有寫入操作;必須符合當前主節點的讀取條件 |
Secondary (name) ● Active RO |
{endpoint-id}-ro.database.{region}.databricks.com |
讀取卸載至次要運算實例(僅在啟用 「允許存取唯讀運算實例 」時可用) |
主要連接串總是導向目前的主連接串,包括故障轉移後。
每個計算實例也有自己的直接連接字串,可透過每列的動作選單(⋮)從 Computes 標籤存取。 直接連線是用來排除個別運算實例的問題,而非用於應用程式。 直接連接字串是針對每個計算節點的,且當次節點加入、移除或升級時可能會改變。
高可用性限制
| Limit | 價值 |
|---|---|
| 計算執行個體 | 2、3 或 4(1 個主 + 1–3 個次要計算實例) |
| 自動縮放範圍(最大− 最小) | 最低與最高之間的差距不超過 8 CU |
| 調整至零 | 在高可用性配置中,無法用於計算實例 |
最佳做法
遵循這些做法有助於你的應用程式在故障轉移事件中保持韌性與可用性。
| 練習 | 詳細資料 |
|---|---|
| 實作連線重試邏輯 | 正在進行的連線在故障轉移時會被終止。 與失敗的主要連線可能會掛機直到逾時——在驅動程式中設定 TCP 保持連線或連線逾時,以迅速偵測故障。 被升遷的次級連線會主動終止,並立即回傳錯誤。 具有重試邏輯的應用程式會在幾秒內自動重新連接。 |
| 根據你的使用情境設定次要數量 | 每個次要計算實例代表為故障轉移預先分配的硬體。 減少次要數量意味著故障轉移能力減少,覆蓋的可用區域也變少。 一個次要運算實例提供容錯備援。 如果您啟用可讀的次要副本,需要設定兩個或以上。 當僅有一個資源時,在故障切換期間,讀取會完全中斷,直到替換流程完成。 |
| 避免次要運算實例過載 | 服務可能會重新啟動過載或落後的次要運算實例。 監控查詢負載和連線數量,若觀察到持續高利用率,則增加 CU 大小。 |