預測最佳化會在 Azure Databricks 上,對 Unity Catalog 受管理資料表(Delta Lake 和 Iceberg)自動執行 OPTIMIZE、VACUUM 和 ANALYZE,無須手動維護,也不必花時間追蹤效能問題。
注意
預測優化預設為 2024 年 11 月 11 日或之後創建的帳號啟用。 Databricks 正在逐步啟用現有帳號。 預計此部署將於2026年8月完成。 要檢查你的帳戶是否已經啟用,請參見 「驗證預測優化是否已啟用」。
啟用預測優化後,Databricks 會自動執行以下操作:
- 識別需要維護作業的表格,並排隊執行這些作業。
- 將數據寫入 Managed 資料表時收集統計數據。
這消除了不必要的維護操作,也免去了手動追蹤與排查效能問題的負擔。
Databricks 建議對所有 Unity Catalog 管理的資料表進行預測優化。 例如,自動液體分群會根據你的資料使用模式,智慧地優化資料版面。 請參閱 針對數據表使用液體叢集。
預測優化會執行哪些作業?
預測優化會在 Unity Catalog 管理的資料表上執行以下操作:
| 作業 | 描述 |
|---|---|
OPTIMIZE |
觸發已啟用資料表的增量分群處理。 請參閱 針對數據表使用液體叢集。 藉由優化檔案大小來改善查詢效能。 請參閱 優化資料檔設定。 |
VACUUM |
藉由刪除數據表不再參考的數據檔來降低記憶體成本。 請參閱 使用真空移除未使用的數據檔。 |
ANALYZE |
掃描資料表並收集統計資料以提升查詢效能。 看......ANALYZE TABLE計算統計數據。 若要移除透過預測優化收集的統計數據,請參見 ANALYZE TABLE ......放棄統計數據。 |
注意
OPTIMIZE 在透過預測優化執行時無法執行 ZORDER 。 在使用 Z 階的資料表上,預測優化會忽略 Z 階檔案。
如果已啟用自動液體群集,預測性優化可能會在叢集數據之前選取新的叢集索引鍵。 請參閱 自動液體群集。
警告
的 VACUUM 保留期限由 delta.deletedFileRetentionDuration 表屬性決定,預設為 7 天。
VACUUM 移除該視窗中不再由 Delta 表格版本參考的資料檔案。 為了更長時間保留資料(例如支援延長時間旅行),在啟用預測優化前先設定以下屬性:
ALTER TABLE table_name SET TBLPROPERTIES ('delta.deletedFileRetentionDuration' = '30 days');
計算與計費
預測優化使用無伺服器運算來執行 ANALYZE、OPTIMIZE 和 VACUUM 的作業。 你的帳號會透過無伺服器作業的 SKU 來計費。
請參閱 Databricks 受控服務的定價。 請參見使用系統表追蹤預測優化。
先決條件
使用預測優化必須符合以下條件:
- 你的 Azure Databricks 工作空間必須在支援區域中使用進階層級。
- 你必須使用 SQL 倉庫或 Databricks Runtime 12.2 LTS 或以上版本。
- 僅支援 Unity Catalog 管理的資料表。
- 如果你需要儲存帳號的私人連線,請設定無伺服器私密連線。 請參閱 設定 Azure 資源的私人連線。
啟用預測性優化
你可以為帳戶、目錄、結構或表格啟用預測優化。 所有 Unity 目錄受控數據表預設都會繼承帳戶值。 你可以在目錄、架構或資料表層級覆寫帳戶預設值。
您必須具備以下權限以啟用或關閉預測優化:
| Unity Catalog 物件 | 權限 |
|---|---|
| 帳戶 | 帳戶管理員 |
| 目錄 | 目錄擁有者,或擁有 MANAGE 目錄權限的使用者 |
| 圖式 | 架構擁有者,或是對結構擁有 MANAGE 權限的使用者 |
| 表 | 資料表擁有者,或是擁有 MANAGE 資料表權限的使用者 |
啟用或停用帳戶的預測優化
帳戶管理員可以啟用對帳戶中所有元資料庫的預測優化。 目錄和架構預設會繼承這個設定,但你可以在任一層級覆寫此設定。
- 進入帳號控制台。
- 導航至設定,然後導航至功能啟用。
- 在預測優化旁邊選擇你想要的選項(例如啟用)。
注意
- 不具有預測優化支援的區域,其中繼存放區未被啟用。
- 停用帳戶層級的預測優化不會影響已特別啟用的目錄或資料結構。
啟用或停用目錄、結構或表格的預測優化
預測優化會使用繼承模型。 當目錄啟用時,該目錄中的結構會繼承設定,啟用結構內的資料表也會繼承該設定。 你可以明確啟用或停用目錄、結構或資料表的預測優化,以覆蓋此行為。
注意
你可以先在目錄、架構或資料表層級關閉預測優化,再在帳戶層級啟用。 如果之後在帳號層級啟用預測最佳化,對於已明確停用此功能的物件,預測最佳化仍不會啟用。
請使用以下語法啟用、停用或重置預測優化,以繼承父物件:
ALTER CATALOG [catalog_name] { ENABLE | DISABLE | INHERIT } PREDICTIVE OPTIMIZATION;
ALTER { SCHEMA | DATABASE } schema_name { ENABLE | DISABLE | INHERIT } PREDICTIVE OPTIMIZATION;
ALTER TABLE table_name { ENABLE | DISABLE | INHERIT } PREDICTIVE OPTIMIZATION;
參見 ALTER TABLE。
驗證是否啟用預測優化
該 Predictive Optimization 欄位是 Unity Catalog 的屬性,用來顯示是否啟用預測優化。 如果設定是從父物件繼承來的,欄位值會顯示這點。
請使用以下語法檢查狀態:
DESCRIBE (CATALOG | SCHEMA | TABLE) EXTENDED name
看看為什麼預測優化會跳過表格
在 Databricks 執行時間 18 及以上版本中,預測優化評估受管理資料表後,請使用 Catalog Explorer 的 歷史 標籤查看為何某操作被跳過。 結果可能長達24小時才會顯現。
使用目錄總管中的歷程索引標籤
你可以在目錄總管的 歷史 標籤中查看資料表的跳過原因。 在 操作 欄位, 自動 標籤表示操作已執行,未 套用 標籤表示操作被跳過。 自動標籤包含預測優化及其他自動操作,例如串流自動壓縮。
若要查看略過原因,請按一下作業欄中帶有未套用標籤的資料列。
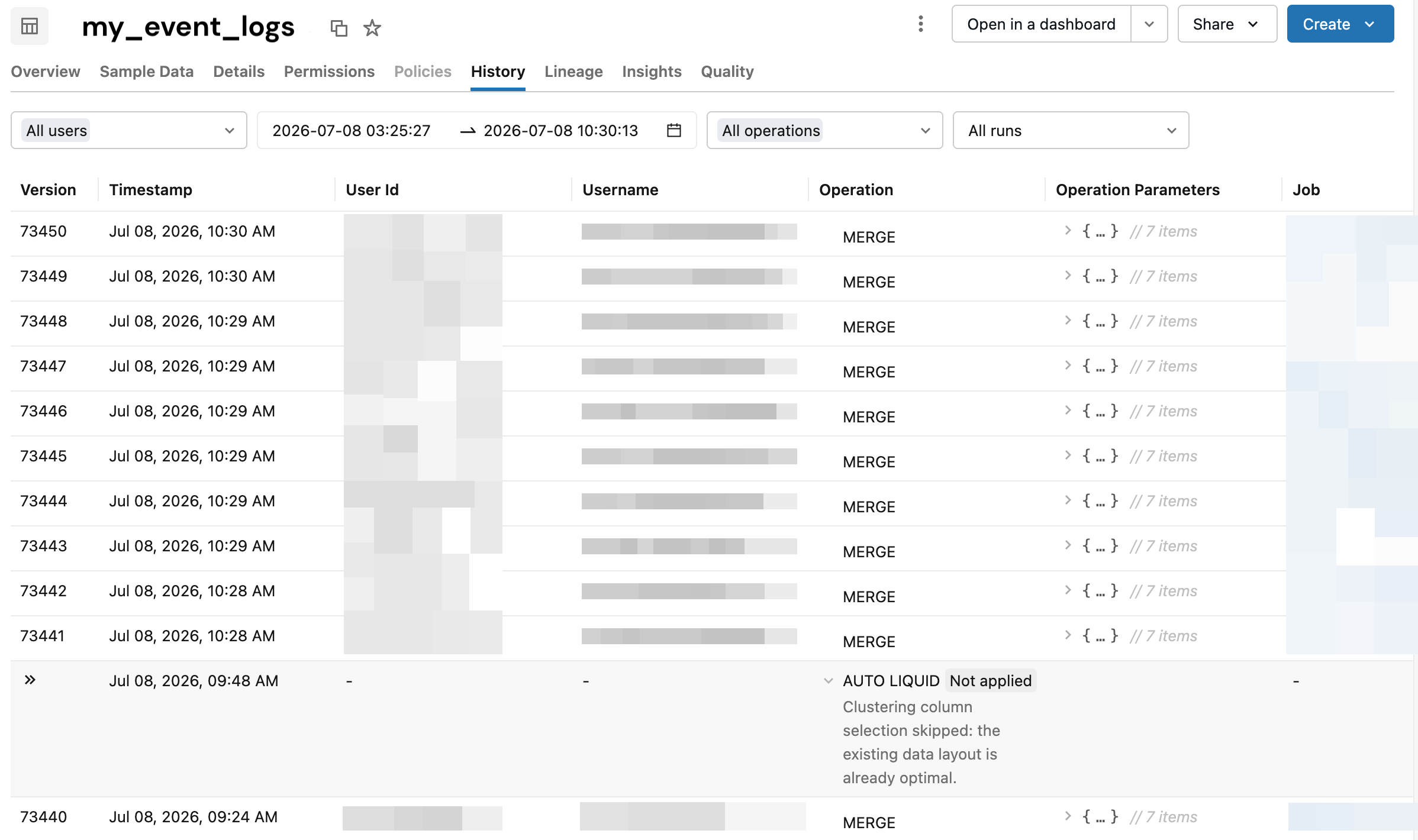
下表描述目錄總管中顯示的自動操作類型:
| 目錄探索器的運作 | 描述 |
|---|---|
OPTIMIZE |
檔案壓縮以提升查詢效能,或增量液體聚類 |
AUTO LIQUID |
液體聚類金鑰的評估或演進 |
VACUUM |
移除不再被資料表參考的資料檔案 |
用系統表追蹤預測優化
Databricks 提供系統表 system.storage.predictive_optimization_operations_history ,用於可觀察性分析預測優化作業、成本與影響。 請參閱 預測優化系統資料表參考。
私人連結錯誤訊息
若系統表將操作標記為失敗 FAILED: PRIVATE_LINK_SETUP_ERROR,則無伺服器私有連結可能未正確配置。 請參閱 設定 Azure 資源的私人連線。
限制
預測優化不會在以下表格類型上執行:
- 以 OpenSharing 接收者身分載入至工作區的資料表
- 外部數據表