教學課程:使用 Azure Databricks 擷取、轉換和載入資料
在本教學課程中,您會使用 Azure Databricks 來執行 ETL(擷取、轉換和載入數據)作業。 您會將數據從 Azure Data Lake Storage Gen2 擷取到 Azure Databricks、對 Azure Databricks 中的數據執行轉換,並將轉換的數據載入 Azure Synapse Analytics。
本教學課程中的步驟會使用適用於 Azure Databricks 的 Azure Synapse 連接器將數據傳輸到 Azure Databricks。 接著,此連接器會使用 Azure Blob 儲存體 作為在 Azure Databricks 叢集與 Azure Synapse 之間傳輸之數據的暫存記憶體。
下圖顯示應用程式流程:

本教學課程涵蓋下列工作:
- 建立 Azure Databricks 服務。
- 在 Azure Databricks 中建立 Spark 叢集。
- 在 Data Lake Storage Gen2 帳戶中建立文件系統。
- 將範例數據上傳至 Azure Data Lake Storage Gen2 帳戶。
- 建立服務主體。
- 從 Azure Data Lake Storage Gen2 帳戶擷取數據。
- 轉換 Azure Databricks 中的數據。
- 將數據載入 Azure Synapse。
如尚未擁有 Azure 訂用帳戶,請在開始之前先建立免費帳戶。
注意
本教學課程無法使用 Azure 免費試用訂用 帳戶來執行。 如果您有免費帳戶,請移至您的配置檔,並將訂用帳戶變更為 隨用隨付。 如需詳細資訊,請參閱 Azure 免費帳戶。 然後,為您所在區域的 vCPU 移除消費限制並要求增加配額。 當您建立 Azure Databricks 工作區時,您可以選取 試用版 (Premium - 14 天免費 DBU) 定價層,讓工作區存取免費 Azure Databricks DBU 14 天。
必要條件
開始本教學課程之前,請先完成這些工作:
建立 Azure Synapse、建立伺服器層級防火牆規則,並以伺服器管理員身分連線到伺服器。請參閱快速入門:使用 Azure 入口網站 建立和查詢 Synapse SQL 集區。
建立 Azure Synapse 的主要金鑰。 請參閱 建立資料庫主要金鑰。
建立 Azure Blob 記憶體帳戶及其內的容器。 此外,擷取存取金鑰以存取記憶體帳戶。 請參閱快速入門:使用 Azure 入口網站 上傳、下載及列出 Blob。
建立 Azure Data Lake Storage Gen2 儲存器帳戶。 請參閱 快速入門:建立 Azure Data Lake Storage Gen2 儲存器帳戶。
建立服務主體。 請參閱 如何:使用入口網站建立可存取資源的Microsoft Entra ID(先前稱為 Azure Active Directory) 應用程式和服務主體。
當您執行該文章中的步驟時,您必須執行幾個特定事項。
執行將應用程式指派給本文中角色一節中的步驟時,請務必將記憶體 Blob 數據參與者角色指派給 Data Lake Storage Gen2 帳戶範圍內的服務主體。 如果您將角色指派給父資源群組或訂用帳戶,您將會收到許可權相關錯誤,直到這些角色指派傳播至記憶體帳戶為止。
如果您想要使用訪問控制清單 (ACL) 將服務主體與特定檔案或目錄產生關聯,請參閱 Azure Data Lake Storage Gen2 中的存取控制。
執行文章中取得登入值一節中的步驟時,請將租使用者標識碼、應用程式識別碼和秘密值貼到文本檔中。
登入 Azure 入口網站。
收集您需要的資訊
請確定您已完成本教學課程的必要條件。
開始之前,您應該要有下列信息專案:
✔️ Azure Synapse 的資料庫名稱、資料庫伺服器名稱、使用者名稱和密碼。
✔️ Blob 記憶體帳戶的存取金鑰。
✔️ Data Lake Storage Gen2 記憶體帳戶的名稱。
✔️ 訂用帳戶的租用戶標識碼。
✔️ 您向 Microsoft Entra ID 註冊的應用程式應用程式識別碼(先前稱為 Azure Active Directory)。
✔️ 您 Microsoft向 Entra ID 註冊之應用程式的驗證密鑰(先前稱為 Azure Active Directory)。
建立 Azure Databricks 服務
在本節中,您會使用 Azure 入口網站 建立 Azure Databricks 服務。
從 Azure 入口網站功能表選取 [建立資源]。
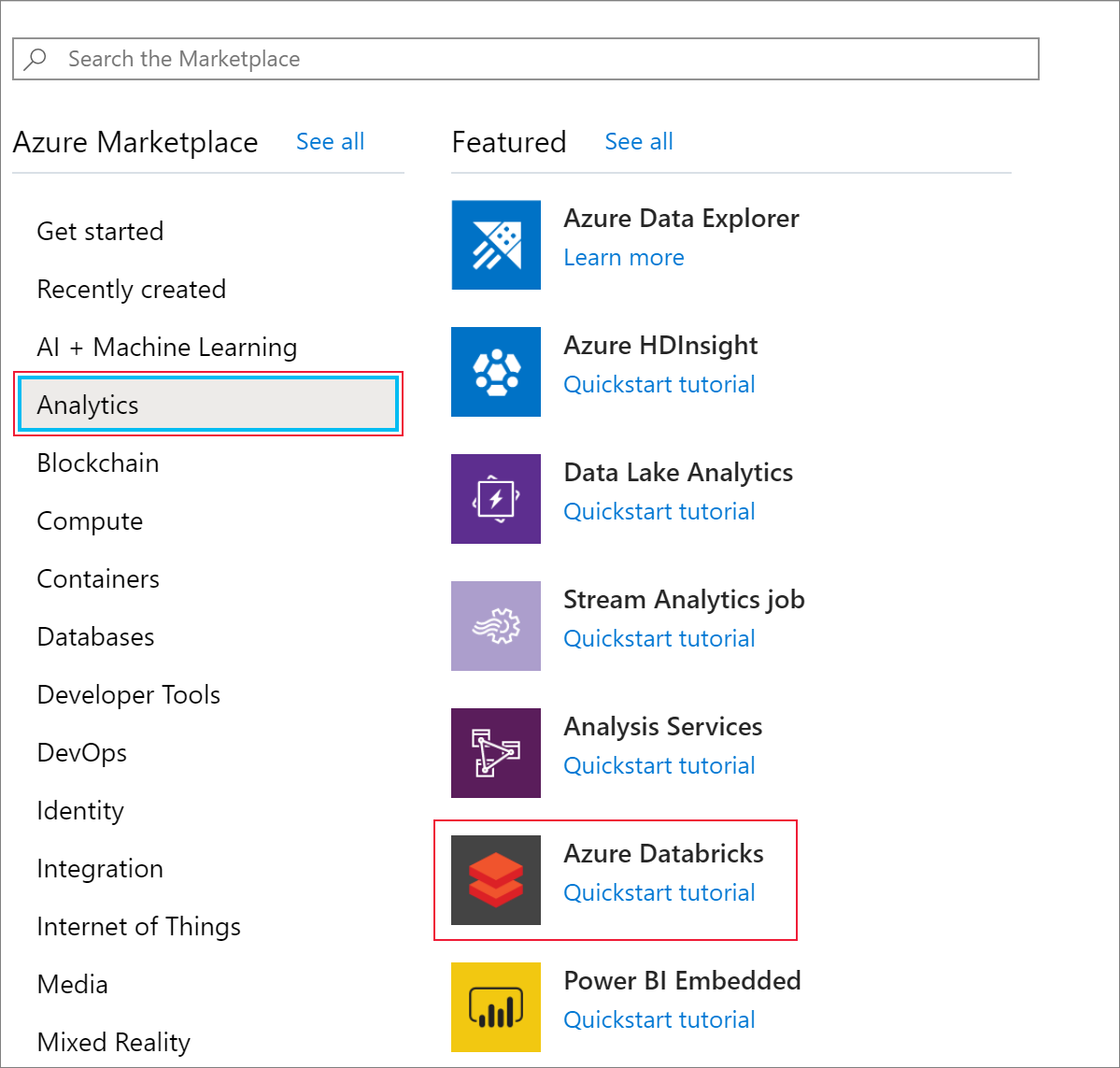
然後,選取 [分析>Azure Databricks]。
在 Azure Databricks Service 下,提供下列值來建立 Databricks 服務:
屬性 說明 工作區名稱 提供 Databricks 工作區的名稱。 訂用帳戶 從下拉式清單中選取您的 Azure 訂用帳戶。 資源群組 指定您是要建立新的資源群組,還是使用現有資源群組。 「資源群組」是存放 Azure 解決方案相關資源的容器。 如需詳細資訊,請參閱 Azure 資源群組概觀。 地點 選取 [美國西部 2]。 如需其他可用的區域,請參閱依區域提供的 Azure 服務。 定價層 選取 [標準]。 建立帳戶需要幾分鐘。 若要監視作業狀態,請檢視頂端的進度列。
選取 [釘選到儀表板],然後選取 [建立]。
在 Azure Databricks 中建立 Spark 叢集
在 Azure 入口網站 中,移至您所建立的 Databricks 服務,然後選取 [啟動工作區]。
系統會將您重新導向至 Azure Databricks 入口網站。 從入口網站中,選取 [ 叢集]。

在 [ 新增叢集] 頁面中,提供建立叢集 的值。

填入下列欄位的值,並接受其他欄位的預設值:
輸入叢集的名稱。
請確定您選取 [ 在 __ 分鐘后終止閑置 ] 複選框。 如果未使用叢集,請提供持續時間(以分鐘為單位)來終止叢集。
選取 [建立叢集]。 叢集執行之後,您可以將筆記本附加至叢集並執行Spark作業。
在 Azure Data Lake Storage Gen2 帳戶中建立文件系統
在本節中,您會在 Azure Databricks 工作區中建立筆記本,然後執行代碼段來設定記憶體帳戶
在 Azure 入口網站 中,移至您所建立的 Azure Databricks 服務,然後選取 [啟動工作區]。
在左側,選取 [ 工作區]。 從 [工作區] 下拉式清單中,選取 [建立>筆記本]。

在 [ 建立筆記本 ] 對話框中,輸入筆記本的名稱。 選取 [Scala ] 作為語言,然後選取您稍早建立的Spark 叢集。

選取 建立。
下列程式代碼區塊會為 Spark 工作階段中存取的任何 ADLS Gen 2 帳戶設定預設服務主體認證。 第二個程式代碼區塊會將帳戶名稱附加至 設定,以指定特定 ADLS Gen 2 帳戶的認證。 將任一程式代碼區塊複製並貼到 Azure Databricks 筆記本的第一個數據格中。
會話設定
val appID = "<appID>" val secret = "<secret>" val tenantID = "<tenant-id>" spark.conf.set("fs.azure.account.auth.type", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id", "<appID>") spark.conf.set("fs.azure.account.oauth2.client.secret", "<secret>") spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<tenant-id>/oauth2/token") spark.conf.set("fs.azure.createRemoteFileSystemDuringInitialization", "true")帳戶組態
val storageAccountName = "<storage-account-name>" val appID = "<app-id>" val secret = "<secret>" val fileSystemName = "<file-system-name>" val tenantID = "<tenant-id>" spark.conf.set("fs.azure.account.auth.type." + storageAccountName + ".dfs.core.windows.net", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type." + storageAccountName + ".dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id." + storageAccountName + ".dfs.core.windows.net", "" + appID + "") spark.conf.set("fs.azure.account.oauth2.client.secret." + storageAccountName + ".dfs.core.windows.net", "" + secret + "") spark.conf.set("fs.azure.account.oauth2.client.endpoint." + storageAccountName + ".dfs.core.windows.net", "https://login.microsoftonline.com/" + tenantID + "/oauth2/token") spark.conf.set("fs.azure.createRemoteFileSystemDuringInitialization", "true") dbutils.fs.ls("abfss://" + fileSystemName + "@" + storageAccountName + ".dfs.core.windows.net/") spark.conf.set("fs.azure.createRemoteFileSystemDuringInitialization", "false")在此程式代碼區塊中,請將此程式代碼區塊中的、
<secret><tenant-id>、 和<storage-account-name>佔位元值取代<app-id>為您完成本教學課程的必要條件時所收集的值。 將<file-system-name>佔位元值取代為您想要提供檔案系統的任何名稱。和
<app-id><secret>來自您在建立服務主體時向 Active Directory 註冊的應用程式。<tenant-id>來自您的訂用帳戶。<storage-account-name>是 Azure Data Lake Storage Gen2 儲存器帳戶的名稱。
按 SHIFT + ENTER 鍵以執行此區塊中的程式碼。
將範例數據內嵌至 Azure Data Lake Storage Gen2 帳戶
在開始使用本節之前,您必須完成下列必要條件:
在筆記本資料格中輸入下列程式代碼:
%sh wget -P /tmp https://raw.githubusercontent.com/Azure/usql/master/Examples/Samples/Data/json/radiowebsite/small_radio_json.json
在儲存格中,按 SHIFT + ENTER 以執行程式碼。
現在,在此儲存格下方的新儲存格中,輸入下列程式代碼,並將出現在括弧中的值取代為您稍早使用的相同值:
dbutils.fs.cp("file:///tmp/small_radio_json.json", "abfss://" + fileSystemName + "@" + storageAccountName + ".dfs.core.windows.net/")
在儲存格中,按 SHIFT + ENTER 以執行程式碼。
從 Azure Data Lake Storage Gen2 帳戶擷取數據
您現在可以將範例 json 檔案載入為 Azure Databricks 中的數據框架。 將下列程式代碼貼到新的儲存格中。 以您的值取代括弧中顯示的佔位元。
val df = spark.read.json("abfss://" + fileSystemName + "@" + storageAccountName + ".dfs.core.windows.net/small_radio_json.json")按 SHIFT + ENTER 鍵以執行此區塊中的程式碼。
執行下列程式代碼以檢視資料框架的內容:
df.show()您會看到如下列程式碼片段的輸出:
+---------------------+---------+---------+------+-------------+----------+---------+-------+--------------------+------+--------+-------------+---------+--------------------+------+-------------+------+ | artist| auth|firstName|gender|itemInSession| lastName| length| level| location|method| page| registration|sessionId| song|status| ts|userId| +---------------------+---------+---------+------+-------------+----------+---------+-------+--------------------+------+--------+-------------+---------+--------------------+------+-------------+------+ | El Arrebato |Logged In| Annalyse| F| 2|Montgomery|234.57914| free | Killeen-Temple, TX| PUT|NextSong|1384448062332| 1879|Quiero Quererte Q...| 200|1409318650332| 309| | Creedence Clearwa...|Logged In| Dylann| M| 9| Thomas|340.87138| paid | Anchorage, AK| PUT|NextSong|1400723739332| 10| Born To Move| 200|1409318653332| 11| | Gorillaz |Logged In| Liam| M| 11| Watts|246.17751| paid |New York-Newark-J...| PUT|NextSong|1406279422332| 2047| DARE| 200|1409318685332| 201| ... ...您現在已將數據從 Azure Data Lake Storage Gen2 擷取到 Azure Databricks。
轉換 Azure Databricks 中的數據
原始範例數據 small_radio_json.json 檔案會擷取廣播電臺的物件,並具有各種不同的數據行。 在本節中,您會將數據轉換成只從數據集擷取特定數據行。
首先,只從 您所建立的數據框架擷取 firstName、 lastName、 gender、 location 和 level 數據行。
val specificColumnsDf = df.select("firstname", "lastname", "gender", "location", "level") specificColumnsDf.show()您會收到輸出,如下列代碼段所示:
+---------+----------+------+--------------------+-----+ |firstname| lastname|gender| location|level| +---------+----------+------+--------------------+-----+ | Annalyse|Montgomery| F| Killeen-Temple, TX| free| | Dylann| Thomas| M| Anchorage, AK| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Tess| Townsend| F|Nashville-Davidso...| free| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Alan| Morse| M|Chicago-Napervill...| paid| |Gabriella| Shelton| F|San Jose-Sunnyval...| free| | Elijah| Williams| M|Detroit-Warren-De...| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Tess| Townsend| F|Nashville-Davidso...| free| | Alan| Morse| M|Chicago-Napervill...| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Dylann| Thomas| M| Anchorage, AK| paid| | Alan| Morse| M|Chicago-Napervill...| paid| | Elijah| Williams| M|Detroit-Warren-De...| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Alan| Morse| M|Chicago-Napervill...| paid| | Dylann| Thomas| M| Anchorage, AK| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| +---------+----------+------+--------------------+-----+您可以進一步轉換此資料,將數據行層級重新命名為 subscription_type。
val renamedColumnsDF = specificColumnsDf.withColumnRenamed("level", "subscription_type") renamedColumnsDF.show()您會收到輸出,如下列代碼段所示。
+---------+----------+------+--------------------+-----------------+ |firstname| lastname|gender| location|subscription_type| +---------+----------+------+--------------------+-----------------+ | Annalyse|Montgomery| F| Killeen-Temple, TX| free| | Dylann| Thomas| M| Anchorage, AK| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Tess| Townsend| F|Nashville-Davidso...| free| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Alan| Morse| M|Chicago-Napervill...| paid| |Gabriella| Shelton| F|San Jose-Sunnyval...| free| | Elijah| Williams| M|Detroit-Warren-De...| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Tess| Townsend| F|Nashville-Davidso...| free| | Alan| Morse| M|Chicago-Napervill...| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Dylann| Thomas| M| Anchorage, AK| paid| | Alan| Morse| M|Chicago-Napervill...| paid| | Elijah| Williams| M|Detroit-Warren-De...| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Alan| Morse| M|Chicago-Napervill...| paid| | Dylann| Thomas| M| Anchorage, AK| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| +---------+----------+------+--------------------+-----------------+
將數據載入 Azure Synapse
在本節中,您會將轉換的數據上傳至 Azure Synapse。 您可以使用適用於 Azure Databricks 的 Azure Synapse 連接器,直接將數據框架上傳為 Synapse Spark 集區中的數據表。
如先前所述,Azure Synapse 連接器會使用 Azure Blob 記憶體作為暫存記憶體,以上傳 Azure Databricks 與 Azure Synapse 之間的數據。 因此,您一開始會提供組態以連線到記憶體帳戶。 您必須已經建立帳戶,作為本文必要條件的一部分。
提供組態,以從 Azure Databricks 存取 Azure 儲存體 帳戶。
val blobStorage = "<blob-storage-account-name>.blob.core.windows.net" val blobContainer = "<blob-container-name>" val blobAccessKey = "<access-key>"指定在 Azure Databricks 與 Azure Synapse 之間移動數據時要使用的暫存資料夾。
val tempDir = "wasbs://" + blobContainer + "@" + blobStorage +"/tempDirs"執行下列代碼段,以在設定中儲存 Azure Blob 記憶體存取金鑰。 此動作可確保您不必以純文字將存取金鑰保留在筆記本中。
val acntInfo = "fs.azure.account.key."+ blobStorage sc.hadoopConfiguration.set(acntInfo, blobAccessKey)提供值以連線到 Azure Synapse 實例。 您必須已建立 Azure Synapse Analytics 服務作為必要條件。 使用 dwServer 的完整伺服器名稱。 例如:
<servername>.database.windows.net。//Azure Synapse related settings val dwDatabase = "<database-name>" val dwServer = "<database-server-name>" val dwUser = "<user-name>" val dwPass = "<password>" val dwJdbcPort = "1433" val dwJdbcExtraOptions = "encrypt=true;trustServerCertificate=true;hostNameInCertificate=*.database.windows.net;loginTimeout=30;" val sqlDwUrl = "jdbc:sqlserver://" + dwServer + ":" + dwJdbcPort + ";database=" + dwDatabase + ";user=" + dwUser+";password=" + dwPass + ";$dwJdbcExtraOptions" val sqlDwUrlSmall = "jdbc:sqlserver://" + dwServer + ":" + dwJdbcPort + ";database=" + dwDatabase + ";user=" + dwUser+";password=" + dwPass執行下列代碼段,以載入已轉換的數據框架、 renamedColumnsDF,作為 Azure Synapse 中的數據表。 此代碼段會在 SQL 資料庫中建立名為 SampleTable 的數據表。
spark.conf.set( "spark.sql.parquet.writeLegacyFormat", "true") renamedColumnsDF.write.format("com.databricks.spark.sqldw").option("url", sqlDwUrlSmall).option("dbtable", "SampleTable") .option( "forward_spark_azure_storage_credentials","True").option("tempdir", tempDir).mode("overwrite").save()注意
此範例會
forward_spark_azure_storage_credentials使用 旗標,這會導致 Azure Synapse 使用存取密鑰從 Blob 記憶體存取數據。 這是唯一支持的驗證方法。如果您的 Azure Blob 儲存體 僅限於選取虛擬網路,Azure Synapse 需要受控服務識別,而不是存取密鑰。 這會導致「此要求未獲授權執行這項作業」錯誤。
線上到 SQL 資料庫,並確認您看到名為 SampleTable 的資料庫。

執行選取查詢來驗證數據表的內容。 數據表應該有與 renamedColumnsDF 數據框架相同的數據。

清除資源
完成本教學課程之後,您可以終止叢集。 從 Azure Databricks 工作區中,選取 左側的 [叢集]。 若要讓叢集終止,請在 [動作] 下指向省略號 (...),然後選取 [終止] 圖示。

如果您未手動終止叢集,則會自動停止,前提是您在建立叢集時選取 了 [在閑置 后的 __ 分鐘后終止] 複選框。 在這種情況下,如果叢集在指定時間內處於非使用中狀態,叢集就會自動停止。
下一步
在本教學課程中,您已了解如何:
- 建立 Azure Databricks 服務
- 在 Azure Databricks 中建立 Spark 叢集
- 在 Azure Databricks 中建立筆記本
- 從 Data Lake Storage Gen2 帳戶擷取數據
- 轉換 Azure Databricks 中的數據
- 將數據載入 Azure Synapse