適用於:![]() Databricks SQL
Databricks SQL ![]() Databricks Runtime
Databricks Runtime
Azure Databricks 使用數個規則來解決數據類型之間的衝突:
您也可以在許多類型之間明確轉換:
- cast 函式 會在大多數類型間 cast,若無法 則回傳錯誤。
- try_cast函式 類似 cast 函式 ,但當傳遞無效值時會回傳 NULL。
- 其他 內建函式 使用提供的格式指示詞在型別之間進行轉換。
類型升遷
類型提升是將一種類型轉換成同一類型家族中包含原始類型所有可能值的另一種類型的過程。
因此,類型升級是安全的作業。 例如 TINYINT ,範圍從 -128 到 127。 其所有可能的值都可以安全地提升為 INTEGER。
類型優先順序清單
類型優先順序清單 定義指定數據類型的值是否可以隱含地升階為另一個數據類型。
| 數據類型 | 優先順序清單 (從最窄到最寬) |
|---|---|
| TINYINT | TINYINT -> SMALLINT -> INT -> BIGINT -> 十進位 -> 浮點 數(1) -> 雙倍 |
| SMALLINT | SMALLINT -> 整數 -> 雙倍數 -> 十進位 -> 浮點 數(1) -> 雙倍 |
| INT | INT -> BIGINT -> DECIMAL -> FLOAT (1) -> 雙倍 |
| BIGINT | 雙字元(BIINT)-> 十進位 -> 浮點 數(1) -> 雙倍 |
| DECIMAL | 小數點 -> 浮點數 (1) -> 雙重 |
| FLOAT | 浮子 (1) -> 雙倍 |
| DOUBLE | DOUBLE |
| DATE | 日期 -> 時間戳 |
| 時間 | 時間 (4) |
| TIMESTAMP | TIMESTAMP |
| ARRAY | 陣列 (2) |
| BINARY | BINARY |
| BOOLEAN | BOOLEAN |
| INTERVAL | INTERVAL |
| 地理 | 地理(任何) |
| 幾何 | 幾何(任意) |
| MAP | 地圖 (2) |
| STRING | STRING |
| STRUCT | STRUCT(2) |
| VARIANT | VARIANT |
| OBJECT | 物件 (3) |
(1) 對於最小公共型別,為避免精度損失,會跳過解析度FLOAT。
(2) 對於複數型態,優先順序規則會遞迴地套用到其組成元素。
(3)OBJECT 僅存在於 VARIANT。
(4) 與TIME(n)的TIME(m)最少常見類型為 TIME(max(n, m))。
TIME 不會晉升到 TIMESTAMP 其他類型。
字串和 NULL
特殊規則適用於 STRING 和無類型的 NULL。
-
NULL可以升階為任何其他類型。 -
STRING可升變為BIGINT、BINARY、BOOLEANDATEDOUBLEINTERVALTIMETIMESTAMP和 。 如果無法將實際字串值轉換成 最不常見的 Azure Databricks 類型 ,就會引發運行時錯誤。 提升到INTERVAL時,字串值必須符合間隔單位。
類型優先順序圖表
這是優先順序階層的圖形化描述,結合 類型優先順序清單 和 字串和 NUL 規則。
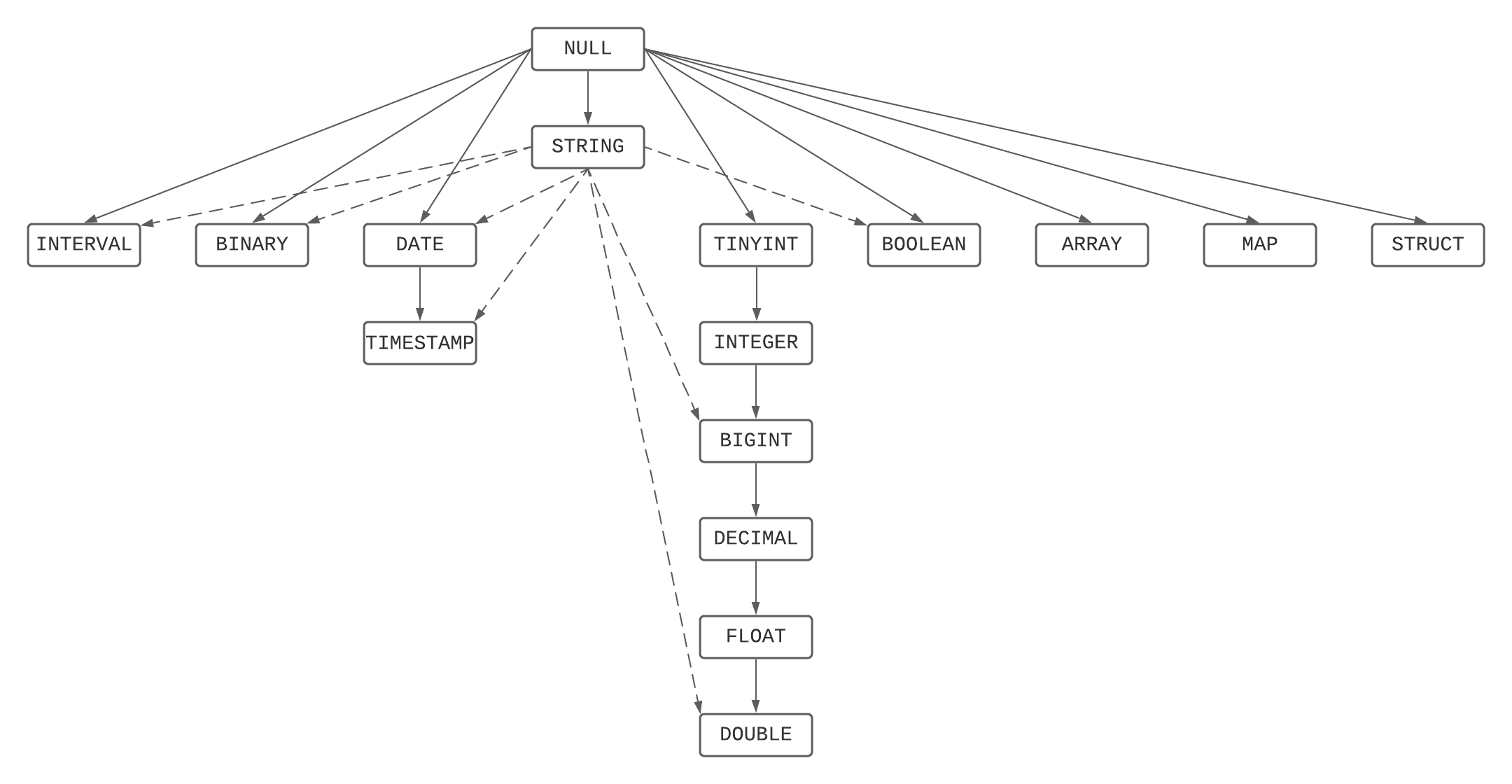
最不常見的類型解決
一組類型中,最不常見的類型是該類型集合中的所有元素透過類型優先順序圖表可達到的最窄的類型。
最不常見的類型解決方案是用來:
- 決定是否可以使用更狹窄型別的引數來調用期望特定型別參數的函式。
- 推導一個函數的參數型態,該函數期望對多個參數(如 coalesce、in、least、greatest)有共享參數型別。
- 推導運算子的運算元類型,例如算術運算或比較。
- 推導出像 case 表達式 這類表達式的結果類型。
- 推導陣列 與 映射 建構子的元素、鍵或值類型。
- 衍生 UNION、INTERSECT 或 EXCEPT set 運算符的結果類型。
參數化型別
有些資料型態帶有影響其精確度或縮放度的參數。 當最小常見型態涉及參數化型態時,會計算結果參數,使得兩種輸入型態的值都能無損地表示。
DECIMAL(p, s)
和 DECIMAL(p1, s1) 的DECIMAL(p2, s2)最小常見類型是 ,DECIMAL其刻度與精度可容納兩種類型的所有值:
resultScale = max(s1, s2)
maxIntegerDigits = max(p1 - s1, p2 - s2)
resultPrecision = min(38, resultScale + maxIntegerDigits)
若 resultScale + maxIntegerDigits 超過( 38 最大小數位精度),精度上限 38 為,刻度會降低以保留整數位數。
例如,最不常見的 和 類型是因為刻度數字和DECIMAL(10, 2)整數數字需要精度 DECIMAL(12, 5),並加寬以DECIMAL(15, 5)容納max(2, 5) = 5有 5 位小數點的有效數字。max(8, 7) = 813158 + 5 = 13
時間(p)
和 TIME(n) 中最不常見的類型TIME(m)是 TIME(max(n, m))。
例如,和 TIME(0) 的TIME(6)最小常見類型是TIME(6)。
附加規則
如果最不常見的類型解析為 FLOAT,則會套用特殊規則。 如果任何參與型別是精確的數值類型(TINYINT、SMALLINT、INTEGER、BIGINT 或 DECIMAL),則最小共同類型會變為 DOUBLE,以避免可能的數位遺失。
當最不常見的類型是 STRING 定序會遵循 定序優先順序規則計算。
隱含的向下轉型和交叉轉型
Azure Databricks 只在函式和運算符調用時使用這些形式的隱式轉換,且只有在能夠明確無誤地判斷意圖時才會這樣做。
隱式向下轉型
隱式向下轉型會自動將較寬的類型轉換成較窄的類型,而不需要明確指定轉換。 向下轉換很方便,但如果實際值無法在較狹窄的型別中表示,則會帶來未預料的執行時錯誤的風險。
向下轉換會套用 類型的反向優先清單。
GEOGRAPHY和GEOMETRY數據類型絕不會被向下轉型。
隱式類型轉換
隱含交叉轉換會將某個類型系列的值轉換成另一個類型系列,而不需要明確指定轉換。
Azure Databricks 支援下列來源的隱含交叉傳播:
- 除了
BINARY、GEOGRAPHY和GEOMETRY之外,任何簡單類型到STRING。 -
STRING任何簡單型別,但GEOGRAPHY和GEOMETRY除外。
- 除了
在函式調用上轉型
假設有已解析的函式或運算符,下列規則會依照每個參數和自變數組所列的順序套用:
如果支持的參數類型是自變數 類型優先順序圖表的一部分,Azure Databricks 會將自變數 升階 為該參數類型。
在大部分情況下,函式描述會明確指出支援的型別或鏈結,例如「任何數值類型」。
例如, sin(expr) 作用於 ,
DOUBLE但接受任意數值。若預期的參數型別為 a
STRING,且參數為簡單型態,Azure Databricks 會將參數交叉投射 至字串參數型別。例如, substr(str, start, len) 預期
str為STRING。 相反地,您可以傳遞數值或日期時間類型。若參數型別為 a
STRING,且預期參數型別為簡單型態,Azure Databricks 會將字串參數 交叉投射 至最寬的支援參數型別。例如,date_add(日期、天數) 需要
DATE和INTEGER。如果您使用兩個
date_add()來呼叫STRING,Azure Databricks 會將第一個轉換為STRING,然後將第二個DATE轉換為STRING。如果函式預期的參數是數值型別,例如
INTEGER或DATE型別,但傳入的參數是更一般的型別,例如DOUBLE或TIMESTAMP,Azure Databricks 會自動將該參數轉換為該參數型別。例如,函數 date_add(日期, 天數) 需要一個
DATE和INTEGER。如果調用
date_add()並傳遞TIMESTAMP和BIGINT,Azure Databricks 會將 下轉換為TIMESTAMP,並移除時間部分,還將DATE下轉換為BIGINT。否則,Azure Databricks 會引發錯誤。
Examples
只要自變數的類型有coalesce,該函式就能接受任何一組參數類型。
結果類型是自變數的最低通用類型。
-- The least common type of TINYINT and BIGINT is BIGINT
> SELECT typeof(coalesce(1Y, 1L, NULL));
BIGINT
-- INTEGER and DATE do not share a precedence chain or support crosscasting in either direction.
> SELECT typeof(coalesce(1, DATE'2020-01-01'));
Error: DATATYPE_MISMATCH.DATA_DIFF_TYPES
-- Both are ARRAYs and the elements have a least common type
> SELECT typeof(coalesce(ARRAY(1Y), ARRAY(1L)))
ARRAY<BIGINT>
-- The least common type of INT and FLOAT is DOUBLE
> SELECT typeof(coalesce(1, 1F))
DOUBLE
> SELECT typeof(coalesce(1L, 1F))
DOUBLE
> SELECT typeof(coalesce(1BD, 1F))
DOUBLE
-- The least common type between an INT and STRING is BIGINT
> SELECT typeof(coalesce(5, '6'));
BIGINT
-- The least common type is a BIGINT, but the value is not BIGINT.
> SELECT coalesce('6.1', 5);
Error: CAST_INVALID_INPUT
-- The least common type between a DECIMAL and a STRING is a DOUBLE
> SELECT typeof(coalesce(1BD, '6'));
DOUBLE
-- Two distinct explicit collations result in an error
> SELECT collation(coalesce('hello' COLLATE UTF8_BINARY,
'world' COLLATE UNICODE));
Error: COLLATION_MISMATCH.EXPLICIT
-- The resulting collation between two distinct implicit collations is indeterminate
> SELECT collation(coalesce(c1, c2))
FROM VALUES('hello' COLLATE UTF8_BINARY,
'world' COLLATE UNICODE) AS T(c1, c2);
NULL
-- The resulting collation between a explicit and an implicit collations is the explicit collation.
> SELECT collation(coalesce(c1 COLLATE UTF8_BINARY, c2))
FROM VALUES('hello',
'world' COLLATE UNICODE) AS T(c1, c2);
UTF8_BINARY
-- The resulting collation between an implicit and the default collation is the implicit collation.
> SELECT collation(coalesce(c1, 'world'))
FROM VALUES('hello' COLLATE UNICODE) AS T(c1, c2);
UNICODE
-- The resulting collation between the default collation and the indeterminate collation is the default collation.
> SELECT collation(coalesce(coalesce('hello' COLLATE UTF8_BINARY, 'world' COLLATE UNICODE), 'world'));
UTF8_BINARY
-- Least common type between GEOGRAPHY(srid) and GEOGRAPHY(ANY)
> SELECT typeof(coalesce(st_geogfromtext('POINT(1 2)'), to_geography('POINT(3 4)'), NULL));
geography(any)
-- Least common type between GEOMETRY(srid1) and GEOMETRY(srid2)
> SELECT typeof(coalesce(st_geomfromtext('POINT(1 2)', 4326), st_geomfromtext('POINT(3 4)', 3857), NULL));
geometry(any)
-- Least common type between GEOMETRY(srid1) and GEOMETRY(ANY)
> SELECT typeof(coalesce(st_geomfromtext('POINT(1 2)', 4326), to_geometry('POINT(3 4)'), NULL));
geometry(any)
-- Least common type between DECIMAL(10,2) and DECIMAL(12,5): precision accommodates both
> SELECT typeof(coalesce(CAST(1 AS DECIMAL(10,2)), CAST(1 AS DECIMAL(12,5))));
DECIMAL(15,5)
-- Least common type between TIME(0) and TIME(6) is the wider precision
> SELECT typeof(coalesce(TIME'10:30:00', CAST(TIME'10:30:00.123456' AS TIME(6))));
TIME(6)
函substring式預期其字串的參數型別為 STRING ,而 start 和 length 參數的型別為 INTEGER 。
-- Promotion of TINYINT to INTEGER
> SELECT substring('hello', 1Y, 2);
he
-- No casting
> SELECT substring('hello', 1, 2);
he
-- Casting of a literal string
> SELECT substring('hello', '1', 2);
he
-- Downcasting of a BIGINT to an INT
> SELECT substring('hello', 1L, 2);
he
-- Crosscasting from STRING to INTEGER
> SELECT substring('hello', str, 2)
FROM VALUES(CAST('1' AS STRING)) AS T(str);
he
-- Crosscasting from INTEGER to STRING
> SELECT substring(12345, 2, 2);
23
||(康卡特) 允許隱含的跨拋射到弦。
-- A numeric is cast to STRING
> SELECT 'This is a numeric: ' || 5.4E10;
This is a numeric: 5.4E10
-- A date is cast to STRING
> SELECT 'This is a date: ' || DATE'2021-11-30';
This is a date: 2021-11-30
date_add 可以因隱含的下移而以 a TIMESTAMP 或 BIGINT 來調用。
> SELECT date_add(TIMESTAMP'2011-11-30 08:30:00', 5L);
2011-12-05
date_add 可以因隱含的跨投法而用 STRINGs 調用。
> SELECT date_add('2011-11-30 08:30:00', '5');
2011-12-05