快取是改善數據倉儲系統效能的基本技術,可避免需要多次重新計算或擷取相同的數據。 在 Databricks SQL 中,快取可以大幅加快查詢執行速度,並將倉儲使用量降至最低,進而降低成本和更有效率的資源使用率。 每個快取層可改善查詢效能、將叢集使用量降到最低,並針對順暢的數據倉儲體驗優化資源使用率。
快取在資料倉儲中提供許多優點,包括:
- 速度:藉由將查詢結果或經常存取的數據儲存在記憶體或其他快速儲存媒體中,快取可以大幅減少查詢運行時間。 此記憶體特別有利於重複的查詢,因為系統可以快速擷取快取的結果,而不是重新計算結果。
- 減少叢集使用量:藉由重複使用先前計算的結果,快取可將額外計算資源的需求降到最低。 這樣可減少整體倉儲運行時間,以及額外計算叢集的需求,進而節省成本並提供更好的資源配置。
Databricks SQL 中的查詢快取類型
Databricks SQL 會執行數種類型的查詢快取。
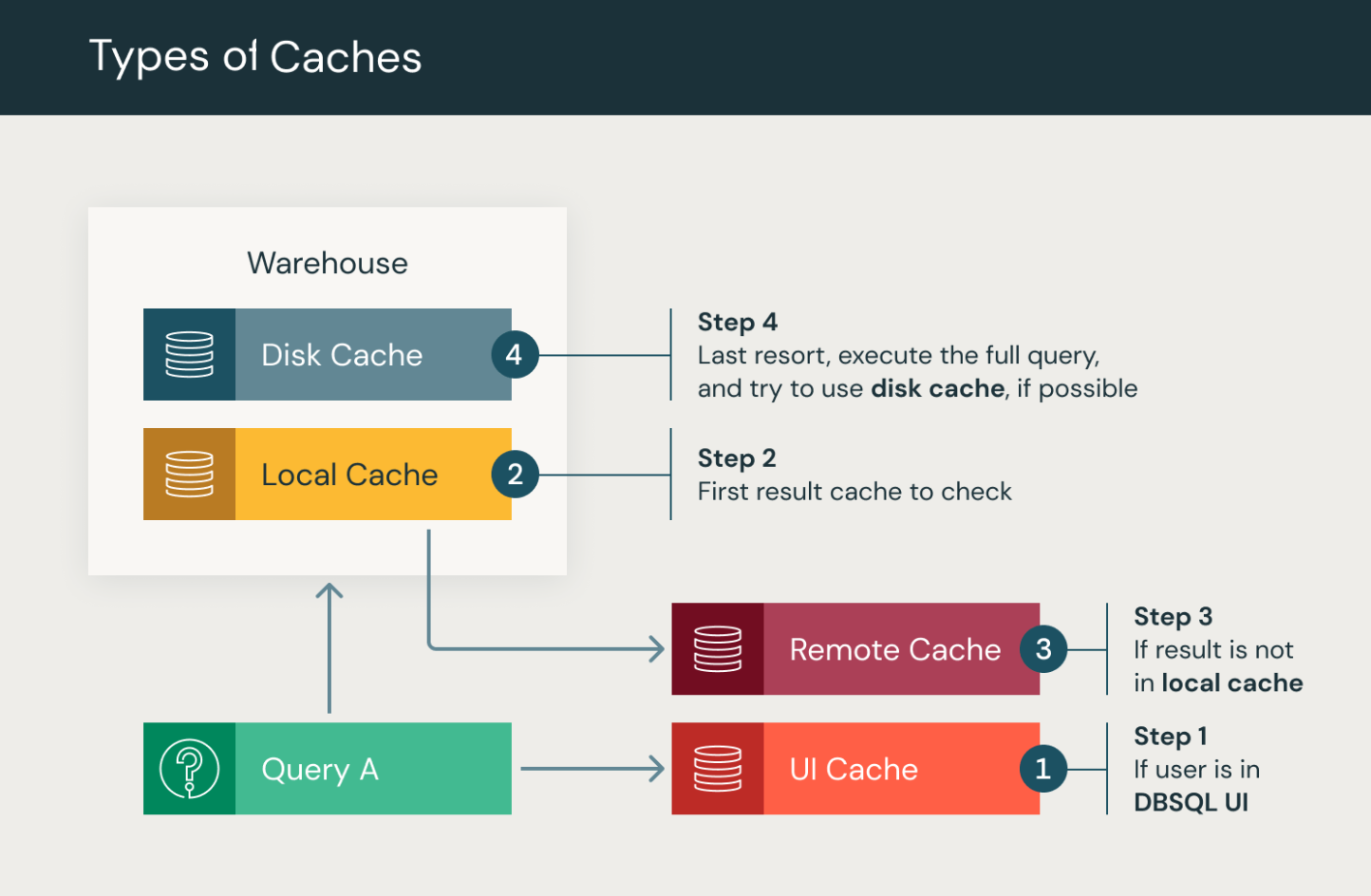
Databricks SQL UI 快取:在 Databricks SQL UI 中,逐用戶快取查詢結果與 SQL 編輯器視覺化。 當使用者首次開啟 SQL 查詢或舊有 SQL 儀表板時,Databricks SQL 介面快取會顯示最新的查詢結果,包括排程執行的結果。
Note
Databricks 的 SQL UI 快取不適用於 AI/BI 儀表板(前稱 Lakeview 儀表板)。 AI/BI 儀表板有自己的快取行為。 請參閱 資料集優化和快取。
Databricks SQL UI 快取最多有 7 天的生命週期。 快取位於您帳戶的 Azure Databricks 檔案系統中。 您可以重新執行不再想要儲存的查詢來刪除查詢結果。 重新執行之後,會將舊的查詢結果從快取中移除。 此外,一旦基礎表被更新後,快取就會失效。
結果快取:針對所有查詢透過 SQL 倉儲的查詢結果進行叢集快取。 結果快取同時包含本機和遠端結果快取,可藉由將查詢結果儲存在記憶體或遠端儲存媒體中,來共同改善查詢效能。
- 本機快取:本機快取是記憶體快取,可儲存在叢集存留期間的查詢結果,或直到快取已滿為止,以最先發生者為準。 此快取適用於加速重複查詢,而不需要重新計算相同的結果。 不過,一旦叢集停止或重新啟動,就會清除快取,並移除所有查詢結果。
- 遠程結果快取:遠端結果快取是無伺服器快取系統,可藉由將查詢結果保存為工作區系統數據來保留查詢結果。 因此,此快取不會因為 SQL 倉儲的停止或重新啟動而失效。 遠端結果快取可解決在記憶體中快取查詢結果的常見痛點,這些結果只有在計算資源運行時才會保持可用狀態。 遠端快取是 Databricks 工作區中所有倉儲的持續性共用快取。
存取遠程結果快取需要運行中的資料倉庫。 處理查詢時,叢集會先查看其本機快取,然後視需要查看遠端結果快取。 只有當查詢結果不在任一快取中時,查詢才會被執行。 本機和遠端快取的生命週期皆為24小時,並從快取進入時開始計算。 遠程結果快取即使在 SQL 倉儲停止或重新啟動後仍會保留。 基礎表更新後,這兩個快取都會失效。
遠端結果快取可用於使用 ODBC/JDBC 用戶端和 SQL 語句 API 的查詢。
若要停用查詢結果快取,您可以在 SQL 編輯器中執行
SET use_cached_result = false。重要
您應該只在測試或基準檢驗中使用此選項。
磁碟快取:本機 SSD 快取,以便從資料記憶體讀取數據,以透過 SQL 倉儲進行查詢。 磁碟快取的設計目的是藉由將數據儲存在磁碟上來增強查詢效能,以允許加速數據讀取。 擷取檔案時,會使用快速中繼格式自動快取數據。 藉由將檔案復本儲存在連接至計算節點的本機儲存上,磁碟快取可確保數據位於接近工作者的位置,進而改善查詢效能。 請參閱 在 Azure Databricks上使用快取來優化效能。
除了其主要功能之外,磁碟快取也會自動偵測基礎數據檔案的變更。 偵測到變更時,快取會失效。 磁碟快取會共用與本機結果快取相同的生命週期特性。 這表示當叢集停止或重新啟動時,快取會被清除,且必須重新載入。
查詢結果快取和 磁碟快取 會影響到 Databricks SQL UI 以及 BI 和其他外部用戶端 的查詢。