本文提供使用 EventProcessorClient 類型時可能會遇到之常見問題的解決方案。 如果您要尋找使用 Azure 事件中樞時可能會遇到之其他常見問題的解決方案,請參閱 針對 Azure 事件中樞進行疑難解答。
當您使用事件處理器時,會出現 412 錯誤,表示前置條件失敗。
當客戶端嘗試取得或更新分區的擁有權時,如果本機的擁有權記錄版本已過期,則會發生 412 前置條件錯誤。 當另一個處理器實例竊取分割區擁有權時,就會發生此問題。 如需詳細資訊,請參閱下一節。
分割區擁有權經常變更
當實例數目 EventProcessorClient 變更時(也就是新增或移除),執行中的實例會嘗試在本身之間負載平衡分割區。 在處理器數量改變後的幾分鐘內,分區預期會變更擁有者。 平衡之後,分割區擁有權應該穩定且不常變更。 如果分割區擁有權在處理器數目是常數時經常變更,則表示有問題。 我們建議您提交一個包含記錄和重現步驟的 GitHub 問題。
區段擁有權是透過CheckpointStore中的擁有權記錄來決定。 在每一個負載平衡間隔,將會執行EventProcessorClient下列工作:
- 提取最新的所有權紀錄。
- 檢查記錄,查看哪些記錄的時間戳尚未在分區擁有權過期間隔內更新。 只會考慮符合此準則的記錄。
- 如果有任何未擁有的數據分割,而且 實例
EventProcessorClient之間的負載不平衡,事件處理器用戶端會嘗試宣告分割區。 - 更新拥有它的分區的擁有權記錄,這些分區有与該分區的活跃链接。
您可以在建立 EventProcessorClient 時使用 EventProcessorClientBuilder 來設定負載平衡和擁有權到期的間隔,如下列清單所述:
- loadBalancingUpdateInterval(Duration) 方法會指出負載平衡週期的執行頻率。
- partitionOwnershipExpirationInterval(Duration) 方法表示在處理器將分割區視為未擁有之前,自擁有權記錄更新以來的最小時間量。
例如,如果擁有權記錄在上午9:30更新,且partitionOwnershipExpirationInterval 為2分鐘。 當負載平衡周期發生,並注意到擁有權記錄在過去 2 分鐘或上午9點32分之前未更新時,則會將分區視為未擁有。
如果其中一個分割取用者發生錯誤,程式會關閉對應的取用者,但在下一個負載平衡週期之前,不會嘗試回收它。
"...目前接收者『<RECEIVER_NAME>』與 epoch『<0』正在斷開連線"
整個錯誤訊息看起來類似下列輸出:
New receiver 'nil' with higher epoch of '0' is created hence current receiver 'nil' with epoch '0'
is getting disconnected. If you are recreating the receiver, make sure a higher epoch is used.
TrackingId:<GUID>, SystemTracker:<NAMESPACE>:eventhub:<EVENT_HUB_NAME>|<CONSUMER_GROUP>,
Timestamp:2022-01-01T12:00:00}"}
當新增或移除實例 EventProcessorClient 後進行負載平衡時,預期會發生此錯誤。 負載平衡是持續的過程。 當您與您的消費者搭配使用 BlobCheckpointStore 時,預設情況下每約 30 秒,消費者會檢查哪些消費者擁有各個分區的宣告,然後執行一些邏輯來判斷它是否需要從另一個消費者「竊取」分區。 用來判斷分割區獨佔擁有權的服務機制稱為 Epoch。
不過,如果未新增或移除任何實例,就應該解決基礎問題。 如需詳細資訊,請參閱 分割區擁有權經常變更 一節和 提出 GitHub 問題。
高 CPU 使用率
高 CPU 使用量通常是因為實例擁有太多分割區。 我們建議每個 CPU 核心不超過三個分割區。 最好從每個 CPU 核心分配 1.5 個分割區開始,然後藉由增加所擁有的分割區數量進行測試。
記憶體不足與選定堆記憶體大小
如果 JVM 目前的最大堆積不足以執行應用程式,記憶體不足 (OOM) 問題就可能發生。 您可能想要測量應用程式的堆積需求。 然後,根據結果,使用 -Xmx JVM 選項設定適當的最大堆積記憶體來調整堆積大小。
您不應該將-Xmx指定為大於主機(VM或容器)的可用記憶體或設定限制的值,例如容器組態中的記憶體要求。 您應該為主機配置足夠的記憶體,以支援 Java 堆積。
下列步驟描述測量最大 Java 堆積值的一般方法:
在接近生產環境的環境中執行應用程式,其中應用程式會在生產環境預期的尖峰負載下傳送、接收及處理事件。
等候應用程式達到穩定狀態。 在這個階段,應用程式和 JVM 會載入所有網域對象、類別類型、靜態實例、物件集區 (TCP、DB 連線集區)等。
在穩定狀態下,您會看到堆積集合的穩定鋸形圖樣,如下列螢幕快照所示:
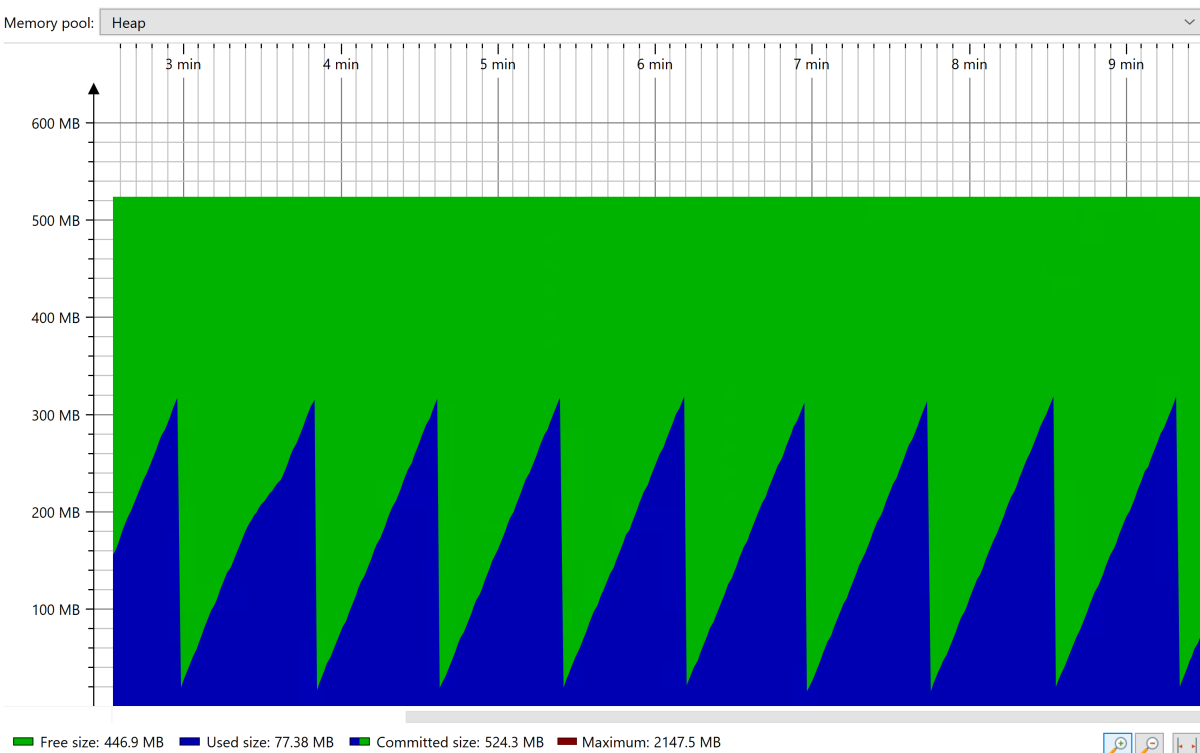
應用程式到達穩定狀態之後,使用 JConsole 之類的工具強制進行完整垃圾收集(GC)。 觀察完整 GC 之後所佔用的記憶體。 您想要調整堆積的大小,讓完整 GC 之後只佔用 30%。 您可以使用此值來設定堆積大小上限(使用
-Xmx)。

如果您已在容器中,請調整容器的大小,使其具有額外約 1 GB 的記憶體,以滿足 JVM 實例的非堆記憶體需求。
處理器用戶端停止接收
處理器用戶端通常會在主機應用程式中持續執行幾天。 有時候,它會注意到 EventProcessorClient 不會處理一或多個分割區。 通常沒有足夠的信息來判斷例外狀況發生的原因。
EventProcessorClient停止是嘗試從瞬時錯誤中復原時發生的底層原因(也就是競態條件)的徵狀。 如需我們需要的資訊,請參閱 提出 GitHub 問題。
處理器重新啟動時收到重複的 EventData
EventProcessorClient 和事件中樞服務保證至少傳遞一次。 您可以新增元資料來辨別重複的事件。 如需詳細資訊,請參閱 Stack Overflow 上的 Azure 事件中樞是否保證至少傳遞一次? 如果您需要「僅一次」投遞,您應該考慮使用 Service Bus ,因為它會等候來自用戶端的確認。 如需傳訊服務的比較,請參閱 在 Azure 傳訊服務之間選擇。
基礎層級用戶端停止接收
EventHubConsumerAsyncClient 是事件中樞連結庫所提供的低階取用者用戶端,專為需要對其回應式應用程式擁有更大控制權和彈性的進階使用者所設計。 此用戶端提供低階介面,可讓使用者管理 Reactor 鏈結內的反壓、線程和復原。 不同於 EventProcessorClient, EventHubConsumerAsyncClient 不包含所有終端機原因的自動復原機制。 因此,用戶必須處理終端事件,並選取適當的 Reactor作員來實作復原策略。
當 EventHubConsumerAsyncClient::receiveFromPartition 連線發生無法重試的錯誤或一系列連線復原嘗試連續失敗時,方法會發出終端機錯誤,以耗盡最大重試限制。 雖然低階接收者嘗試從暫時性錯誤復原,但取用者用戶端的使用者預期會處理終端事件。 如果希望持續接收事件,應用程式應調整 Reactor 鏈結,在終端事件時建立新的消費者客戶端。
從傳統舊版移轉至新的客戶端程式庫
移轉 指南 包含從舊版用戶端移轉和移轉舊版檢查點的步驟。
後續步驟
如果您在使用適用於 Java 的 Azure SDK 用戶端連結庫時,本文中的疑難解答指引無法解決問題,建議您