定義變數
Azure DevOps Services | Azure DevOps Server 2022 - Azure DevOps Server 2019
變數可讓您輕鬆地將資料的重要部分放入管線的各個部分。 最常見的變數用法是定義接下來可在管線中使用的值。 所有變數都是字串,且是可變的。 變數的值可以隨著您管線的不同回合或不同作業進行變更。
當您在多個位置中以相同名稱定義相同變數時,最為本機範圍的變數會勝出。 因此,在作業層級定義的變數可以覆寫暫存層級的變數集。 在暫存層級定義的變數會覆寫管線根層級的變數集。 管線根層級的變數集會覆寫管線設定 UI 的變數集。 若要深入瞭解如何使用在作業、階段和根層級定義的變數,請參閱 變數範圍。
您可以使用變數搭配 表達式 來有條件地指派值,並進一步自定義管線。
變數與執行階段參數不同。 執行階段參數是在範本剖析期間輸入並提供使用。
使用者定義變數
當您定義變數時,可以使用 不同的語法(巨集、範本運算式或運行時間), 以及您使用的語法會決定變數在管線中的轉譯位置。
在 YAML 管線中,您可以在根、暫存和作業層級設定變數。 您也可以在 UI 中的 YAML 管線外部指定變數。 當您在 UI 中設定變數時,該變數可以加密並設定為祕密。
用戶定義的變數可以 設定為唯讀。 變數有命名限制(例如:您無法在變數名稱開頭使用secret)。
您可以使用 變數群組 ,讓變數可在多個管線之間使用。
使用 範本 在多個管線中使用的一個檔案中定義變數。
用戶定義的多行變數
Azure DevOps 支援多行變數,但有一些限制。
管線工作之類的下游元件可能無法正確處理變數值。
Azure DevOps 不會改變使用者定義的變數值。 變數值必須先正確格式化,才能以多行變數的形式傳遞。 格式化變數時,請避免特殊字元、不要使用受限制的名稱,並確定您使用適用於您代理程式操作系統的行尾格式。
多行變數的行為會根據操作系統而有所不同。 若要避免這種情況,請確定您已正確設定目標操作系統的多行變數格式。
即使您提供不支援的格式,Azure DevOps 也不會改變變數值。
系統變數
除了使用者定義變數之外,Azure Pipelines 還有具有預先定義值的系統變數。 例如,預先定義的變數 Build.BuildId 會提供每個組建的識別碼,並可用來識別不同的管線執行。 當您需要唯一值時, Build.BuildId 可以在腳本或工作中使用 變數。
如果您使用YAML或傳統組建管線,請參閱 預先定義的變數 ,以取得系統變數的完整清單。
如果您使用傳統發行管線,請參閱 發行變數。
當您執行管線時,系統會使用其目前值來設定系統變數。 某些變數會自動設定。 身為管線作者或終端使用者,您可以在管線執行之前變更系統變數的值。
系統變數是唯讀的。
環境變數
環境變數專屬於您使用的作業系統。 它們會以平台特定方式插入管線。 格式會對應至環境變數如何針對您的特定指令碼平台進行格式化。
在 UNIX 系統上 (macOS 和 Linux),環境變數的格式為 $NAME。 在 Windows 上,適用於批次的格式為 %NAME%,在 PowerShell 中為 $env:NAME。
系統與使用者定義變數也會插入為平台的環境變數。 當變數轉換成環境變數時,變數名稱會變成大寫,而句點會變成底線。 例如,變數名稱 any.variable 會變成變數名稱 $ANY_VARIABLE。
環境變數有 變數命名限制 (例如:您無法在變數名稱開頭使用 secret )。
變數命名限制
用戶定義的和環境變數可以包含字母、數位、 .和 _ 字元。 請勿使用系統保留的變數前置詞。 這些是:endpoint、、secretinput、path、 和 securefile。 任何以這些字串開頭的變數(不論大小寫為何)都不適用於您的工作和腳本。
瞭解變數語法
Azure Pipelines 支援三種不同的變數參考方式:巨集、範本運算式和執行階段運算式。 您可以將每個語法用於不同的用途,而且每個語法都有一些限制。
在管線中,在運行時間開始之前,範本表示式變數 (${{ variables.var }}) 會在編譯時間進行處理。 工作執行之前,巨集語法變數 ($(var)) 會在運行時間期間進行處理。 運行時間表達式 ($[variables.var]) 也會在運行時間期間處理,但要與條件和表示式搭配使用。 當您使用執行階段運算式時,其必須佔據整個定義右側。
在此範例中,您可以看到範本運算式在更新變數之後仍具有變數的初始值。 巨集語法變數的值會更新。 範本表達式值不會變更,因為所有範本運算式變數都會在編譯階段處理,再執行工作。 相反地,巨集語法變數會在每個工作執行之前進行評估。
variables:
- name: one
value: initialValue
steps:
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one)
displayName: First variable pass
- bash: echo "##vso[task.setvariable variable=one]secondValue"
displayName: Set new variable value
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one) # outputs secondValue
displayName: Second variable pass
巨集語法變數
大部分的檔範例都使用 巨集 語法 ($(var))。 巨集語法的設計目的是將變數值插入工作輸入和其他變數中。
具有巨集語法的變數會在工作在運行時間期間執行之前進行處理。 運行時間會在範本擴充之後發生。 當系統遇到巨集表示式時,它會以變數的內容取代表達式。 如果沒有該名稱的變數,則巨集表示式不會變更。 例如,如果 $(var) 無法取代, $(var) 則不會由任何專案取代。
巨集語法變數保持不變,沒有值,因為 之類的 $() 空值可能表示您正在執行的工作,而代理程式不應該假設您想要取代該值。 例如,如果您使用 $(foo) 在Bash工作中參考變數 foo ,則取代工作輸入中的所有 $() 運算式可能會中斷Bash腳本。
巨集變數只有在用於值時才會展開,而不是做為關鍵詞。 值會出現在管線定義的右側。 下列是有效的: key: $(value)。 下列無效: $(key): value。 巨集變數不會在用來內嵌顯示作業名稱時展開。 相反地,您必須使用 displayName 屬性。
注意
巨集語法變數只會針對 stages、 jobs和 steps展開。
例如,您無法在 或 trigger中使用 resource 巨集 語法。
此範例使用 巨集 語法搭配Bash、PowerShell和腳本工作。 使用巨集語法呼叫變數的語法,這三個語法都相同。
variables:
- name: projectName
value: contoso
steps:
- bash: echo $(projectName)
- powershell: echo $(projectName)
- script: echo $(projectName)
範本表達式語法
您可以使用範本表示式語法來展開 範本參數 和變數 (${{ variables.var }})。 在編譯階段處理範本變數,並在運行時間開始之前取代。 範本運算式是專為重複使用 YAML 部分做為範本而設計。
找不到取代值時,範本變數會以無訊息方式聯合成空字串。 範本運算式與巨集和運行時間表示式不同,可以顯示為索引鍵(左側)或值(右側)。 下列是有效的: ${{ variables.key }} : ${{ variables.value }}。
運行時間表達式語法
您可以將執行時間表示式語法用於執行時間 ($[variables.var]) 擴充的變數。 找不到取代值時,運行時間表達式變數會以無訊息方式聯合成空字串。 在作業條件中使用運行時間表達式,以支援作業的條件式執行,或整個階段。
運行時間表達式變數只有在用於值時才會展開,而不是做為關鍵詞。 值會出現在管線定義的右側。 下列是有效的: key: $[variables.value]。 下列無效: $[variables.key]: value。 運行時間表達式必須佔用索引鍵/值組的整個右側。 例如, key: $[variables.value] 有效,但 key: $[variables.value] foo 無效。
| 語法 | 範例 | 何時處理? | 它會在管線定義中展開的位置? | 找不到時如何轉譯? |
|---|---|---|---|---|
| 程式碼 | $(var) |
工作執行前的運行時間 | value (右側) | 指紋 $(var) |
| 範本表達式 | ${{ variables.var }} |
編譯時間 | 索引鍵或值(左側或右側) | 空字串 |
| 運行時間表達式 | $[variables.var] |
執行階段 | value (右側) | 空字串 |
我應該使用何種語法?
如果您要提供工作的輸入,請使用巨集語法。
如果您正在使用 條件 和 表示式,請選擇執行時間表示式。 不過,如果您不想列印空白變數,請勿使用執行時間表示式(例如: $[variables.var]。 例如,如果您有依賴具有特定值或無值之變數的條件式邏輯。 在此情況下,您應該使用巨集表達式。
如果您要在範本中定義變數,請使用範本表示式。
在管線中設定變數
在最常見的案例中,您會設定變數,並在 YAML 檔案內使用這些變數。 這可讓您追蹤版本控制系統中變數的變更。 您也可以在管線設定 UI 中定義變數(請參閱傳統索引標籤),並在 YAML 中參考變數。
以下是示範如何設定兩個變數和 platform的範例,configuration並在稍後的步驟中使用這些變數。 若要在 YAML 語句中使用變數,請將它包裝在 中 $()。 變數無法用來在 YAML 語句中定義 repository 。
# Set variables once
variables:
configuration: debug
platform: x64
steps:
# Use them once
- task: MSBuild@1
inputs:
solution: solution1.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
# Use them again
- task: MSBuild@1
inputs:
solution: solution2.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
變數範圍
在 YAML 檔案中,您可以在各種範圍設定變數:
- 在根層級,讓它可供管線中的所有作業使用。
- 在階段層級,使其僅適用於特定階段。
- 在作業層級,使其僅適用於特定作業。
當您在 YAML 頂端定義變數時,變數可供管線中的所有作業和階段使用,而且是全域變數。 在 YAML 中定義的全域變數不會顯示在管線設定 UI 中。
作業層級的變數會覆寫根層級和階段層級的變數。 階段層級的變數會覆寫根層級的變數。
variables:
global_variable: value # this is available to all jobs
jobs:
- job: job1
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable1: value1 # this is only available in job1
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable1)
- bash: echo $JOB_VARIABLE1 # variables are available in the script environment too
- job: job2
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable2: value2 # this is only available in job2
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable2)
- bash: echo $GLOBAL_VARIABLE
這兩個作業的輸出如下所示:
# job1
value
value1
value1
# job2
value
value2
value
指定變數
在上述範例中 variables ,關鍵詞後面接著索引鍵/值組的清單。
索引鍵是變數名稱,而值是變數值。
透過 範本,變數可以在一個 YAML 中定義,並包含在另一個 YAML 檔案中。
變數群組是一組變數,您可以跨多個管線使用。 它們可讓您管理及組織一個位置中各種階段通用的變數。
針對管線根層級的變數範本和變數群組使用此語法。
在此替代語法中 variables ,關鍵詞會採用變數規範清單。
變數規範適用於 name 一般變數、 group 變數群組,以及 template 包含變數範本。
下列範例示範這三個。
variables:
# a regular variable
- name: myvariable
value: myvalue
# a variable group
- group: myvariablegroup
# a reference to a variable template
- template: myvariabletemplate.yml
深入瞭解 使用範本重複使用變數。
透過環境存取變數
請注意,變數也可透過環境變數提供給腳本使用。 使用這些環境變數的語法取決於腳本語言。
名稱為大寫,並以 . 取代 _。 這會自動插入進程環境。 以下列出一些範例:
- 批次文稿:
%VARIABLE_NAME% - PowerShell 腳本:
$env:VARIABLE_NAME - Bash 指令稿:
$VARIABLE_NAME
重要
包含檔案路徑的預先定義變數會根據代理程式主機類型和殼層類型,轉譯為適當的樣式(Windows 樣式 C:\foo\ 與 Unix 樣式 /foo/)。 如果您在 Windows 上執行 bash 腳本工作,您應該使用環境變數方法來存取這些變數,而不是管線變數方法,以確保您有正確的檔案路徑樣式。
設定秘密變數
提示
秘密變數不會自動匯出為環境變數。 若要在您的腳本中使用秘密變數,請明確地將它們對應至環境變數。 如需詳細資訊,請參閱 設定秘密變數。
請勿在 YAML 檔案中設定秘密變數。 操作系統通常會記錄其執行之進程的命令,而且您不希望記錄檔包含您傳入做為輸入的秘密。 使用腳本的環境,或將 區塊內的 variables 變數對應至管線,將秘密傳遞至管線。
注意
Azure Pipelines 會在將數據發出至管線記錄時,努力遮罩秘密,因此您可能會在未設定為秘密的輸出和記錄中看到其他變數和數據遮罩。
您必須在管線的管線設定UI中設定秘密變數。 這些變數的範圍會限定於其設定所在的管線。 您也可以在變數群組中設定秘密變數。
若要在 Web 介面中設定祕密,請遵循下列步驟:
- 前往 [管線] 頁面,選取適當的管線,然後選取 [編輯]。
- 找出此管線的 [變數]。
- 新增或更新變數。
- 選取 [保留此值秘密] 選項,以加密方式儲存變數。
- 儲存管線。
祕密變數會以 2048 位元 RSA 金鑰待用加密。 代理程式上有祕密可供工作和指令碼使用。 留意誰可以存取並變更您的管線。
重要
我們努力遮罩秘密,使其無法出現在 Azure Pipelines 輸出中,但您仍然需要採取預防措施。 永遠不要將祕密回應為輸出。 某些作業系統會記錄命令列引數。 永遠不要在命令列上傳遞祕密。 相反地,我們建議您將祕密對應至環境變數。
我們絕不會遮罩秘密的子字串。 例如,如果 「abc123」 設定為秘密,則 「abc」 不會從記錄中遮罩。 這是為了避免在層級太細微時遮罩處理祕密,使記錄無法讀取。 因此,祕密不應包含結構化資料。 例如,如果「{ "foo": "bar" }」設定為祕密,則「bar」不會從記錄中遮罩處理。
不同於一般變數,它們不會自動解密為腳本的環境變數。 您必須明確對應秘密變數。
下列範例示範如何對應和使用PowerShell和Bash腳本中呼叫 mySecret 的秘密變數。 定義兩個全域變數。 GLOBAL_MYSECRET 會指派秘密變數 mySecret的值,並 GLOBAL_MY_MAPPED_ENV_VAR 指派非秘密變數 nonSecretVariable的值。 不同於一般管線變數,沒有稱為 MYSECRET的環境變數。
PowerShell 工作會執行腳本來列印變數。
$(mySecret):這是秘密變數的直接參考,而且可運作。$env:MYSECRET:這會嘗試以環境變數的形式存取秘密變數,因為秘密變數不會自動對應至環境變數,因此無法運作。$env:GLOBAL_MYSECRET:這會嘗試透過全域變數存取秘密變數,這也無法運作,因為秘密變數無法以這種方式對應。$env:GLOBAL_MY_MAPPED_ENV_VAR:這會透過可運作的全域變數存取非秘密變數。$env:MY_MAPPED_ENV_VAR:這會透過工作特定的環境變數來存取秘密變數,這是將秘密變數對應至環境變數的建議方式。
variables:
GLOBAL_MYSECRET: $(mySecret) # this will not work because the secret variable needs to be mapped as env
GLOBAL_MY_MAPPED_ENV_VAR: $(nonSecretVariable) # this works because it's not a secret.
steps:
- powershell: |
Write-Host "Using an input-macro works: $(mySecret)"
Write-Host "Using the env var directly does not work: $env:MYSECRET"
Write-Host "Using a global secret var mapped in the pipeline does not work either: $env:GLOBAL_MYSECRET"
Write-Host "Using a global non-secret var mapped in the pipeline works: $env:GLOBAL_MY_MAPPED_ENV_VAR"
Write-Host "Using the mapped env var for this task works and is recommended: $env:MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
- bash: |
echo "Using an input-macro works: $(mySecret)"
echo "Using the env var directly does not work: $MYSECRET"
echo "Using a global secret var mapped in the pipeline does not work either: $GLOBAL_MYSECRET"
echo "Using a global non-secret var mapped in the pipeline works: $GLOBAL_MY_MAPPED_ENV_VAR"
echo "Using the mapped env var for this task works and is recommended: $MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
上述腳本中這兩項工作的輸出看起來會像這樣:
Using an input-macro works: ***
Using the env var directly does not work:
Using a global secret var mapped in the pipeline does not work either:
Using a global non-secret var mapped in the pipeline works: foo
Using the mapped env var for this task works and is recommended: ***
您也可以在腳本之外使用秘密變數。 例如,您可以使用定義將秘密變數對應至工作 variables 。 此範例示範如何在 Azure 檔案複製工作中使用秘密變數 $(vmsUser) 和 $(vmsAdminPass) 。
variables:
VMS_USER: $(vmsUser)
VMS_PASS: $(vmsAdminPass)
pool:
vmImage: 'ubuntu-latest'
steps:
- task: AzureFileCopy@4
inputs:
SourcePath: 'my/path'
azureSubscription: 'my-subscription'
Destination: 'AzureVMs'
storage: 'my-storage'
resourceGroup: 'my-rg'
vmsAdminUserName: $(VMS_USER)
vmsAdminPassword: $(VMS_PASS)
參考變數群組中的秘密變數
此範例示範如何在 YAML 檔案中參考變數群組,以及如何在 YAML 中新增變數。 變數群組使用兩個變數: user 和 token。 變數 token 是秘密,而且會對應至環境變數 $env:MY_MAPPED_TOKEN ,以便在 YAML 中參考它。
此 YAML 會進行 REST 呼叫來擷取發行清單,並輸出結果。
variables:
- group: 'my-var-group' # variable group
- name: 'devopsAccount' # new variable defined in YAML
value: 'contoso'
- name: 'projectName' # new variable defined in YAML
value: 'contosoads'
steps:
- task: PowerShell@2
inputs:
targetType: 'inline'
script: |
# Encode the Personal Access Token (PAT)
# $env:USER is a normal variable in the variable group
# $env:MY_MAPPED_TOKEN is a mapped secret variable
$base64AuthInfo = [Convert]::ToBase64String([Text.Encoding]::ASCII.GetBytes(("{0}:{1}" -f $env:USER,$env:MY_MAPPED_TOKEN)))
# Get a list of releases
$uri = "https://vsrm.dev.azure.com/$(devopsAccount)/$(projectName)/_apis/release/releases?api-version=5.1"
# Invoke the REST call
$result = Invoke-RestMethod -Uri $uri -Method Get -ContentType "application/json" -Headers @{Authorization=("Basic {0}" -f $base64AuthInfo)}
# Output releases in JSON
Write-Host $result.value
env:
MY_MAPPED_TOKEN: $(token) # Maps the secret variable $(token) from my-var-group
重要
根據預設,GitHub 存放庫會提供與您的管線相關聯的秘密變數,無法提取分支的要求組建。 如需詳細資訊,請參閱 分叉的貢獻。
跨管線共用變數
若要在專案中的多個管線之間共用變數,請使用 Web 介面。 在 [鏈接庫] 底下,使用變數群組。
使用來自工作的輸出變數
某些工作會定義輸出變數,您可以在下游步驟、作業和階段中取用這些變數。 在 YAML 中,您可以使用相依性,跨作業和階段存取變數。
在下游工作中參考矩陣作業時,您必須使用不同的語法。 請參閱 設定多作業輸出變數。 您也需要針對部署作業中的變數使用不同的語法。 請參閱 支援部署作業中的輸出變數。
某些工作會定義輸出變數,您可以在相同階段的下游步驟和作業中取用這些變數。 在 YAML 中,您可以使用相依性來存取作業之間的變數。
- 若要從相同作業內的不同工作參考變數,請使用
TASK.VARIABLE。 - 若要從不同作業的工作參考變數,請使用
dependencies.JOB.outputs['TASK.VARIABLE']。
注意
根據預設,管線中的每個階段都會相依於 YAML 檔案中的階段。 如果您需要參考目前階段之前的階段,您可以將區段新增 dependsOn 至階段,以覆寫此自動預設值。
注意
下列範例使用標準管線語法。 如果您使用部署管線,變數和條件變數語法將會有所不同。 如需要使用的特定語法資訊,請參閱 部署作業。
在這些範例中,假設我們有名為 MyTask的工作,它會設定名為 的 MyVar輸出變數。
深入了解表達式 - 相依性中的語法。
在相同的作業中使用輸出
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- script: echo $(ProduceVar.MyVar) # this step uses the output variable
在不同的作業中使用輸出
jobs:
- job: A
steps:
# assume that MyTask generates an output variable called "MyVar"
# (you would learn that from the task's documentation)
- task: MyTask@1
name: ProduceVar # because we're going to depend on it, we need to name the step
- job: B
dependsOn: A
variables:
# map the output variable from A into this job
varFromA: $[ dependencies.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
在不同的階段中使用輸出
若要使用不同階段的輸出,參考變數的格式為 stageDependencies.STAGE.JOB.outputs['TASK.VARIABLE']。 在階段層級,但不是作業層級,您可以在條件中使用這些變數。
輸出變數只能在下一個下游階段中使用。 如果多個階段使用相同的輸出變數,請使用 dependsOn 條件。
stages:
- stage: One
jobs:
- job: A
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- stage: Two
dependsOn:
- One
jobs:
- job: B
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
- stage: Three
dependsOn:
- One
- Two
jobs:
- job: C
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
您也可以使用檔案輸入在階段之間傳遞變數。 若要這樣做,您必須在作業層級的第二個階段定義變數,然後將變數當做 env: 輸入傳遞。
## script-a.sh
echo "##vso[task.setvariable variable=sauce;isOutput=true]crushed tomatoes"
## script-b.sh
echo 'Hello file version'
echo $skipMe
echo $StageSauce
## azure-pipelines.yml
stages:
- stage: one
jobs:
- job: A
steps:
- task: Bash@3
inputs:
filePath: 'script-a.sh'
name: setvar
- bash: |
echo "##vso[task.setvariable variable=skipsubsequent;isOutput=true]true"
name: skipstep
- stage: two
jobs:
- job: B
variables:
- name: StageSauce
value: $[ stageDependencies.one.A.outputs['setvar.sauce'] ]
- name: skipMe
value: $[ stageDependencies.one.A.outputs['skipstep.skipsubsequent'] ]
steps:
- task: Bash@3
inputs:
filePath: 'script-b.sh'
name: fileversion
env:
StageSauce: $(StageSauce) # predefined in variables section
skipMe: $(skipMe) # predefined in variables section
- task: Bash@3
inputs:
targetType: 'inline'
script: |
echo 'Hello inline version'
echo $(skipMe)
echo $(StageSauce)
上述管線中階段的輸出如下所示:
Hello inline version
true
crushed tomatoes
列出變數
您可以使用 az pipelines variable list 命令列出管線中的所有變數。 若要開始使用,請參閱 開始使用 Azure DevOps CLI。
az pipelines variable list [--org]
[--pipeline-id]
[--pipeline-name]
[--project]
參數
- 組織:Azure DevOps 組織 URL。 您可以使用 來設定預設組織
az devops configure -d organization=ORG_URL。 如果未設定為預設或使用git config來挑選,則為必要項。 範例:--org https://dev.azure.com/MyOrganizationName/。 - pipeline-id:如果未提供 pipeline-name,則為必要專案。 管線的標識碼。
- pipeline-name:如果未提供 pipeline-id,則為必要專案,但如果提供 pipeline-id,則會忽略。 管線的名稱。
- 專案:專案的名稱或識別碼。 您可以使用 來設定預設專案
az devops configure -d project=NAME_OR_ID。 如果未設定為預設或使用git config來挑選,則為必要專案。
範例
下列命令會列出管線中標識碼 為 12 的所有變數,並以數據表格式顯示結果。
az pipelines variable list --pipeline-id 12 --output table
Name Allow Override Is Secret Value
------------- ---------------- ----------- ------------
MyVariable False False platform
NextVariable False True platform
Configuration False False config.debug
在指令碼中設定變數
腳本可以定義稍後在管線後續步驟中取用的變數。 這個方法所設定的所有變數都會視為字串。 若要從腳本設定變數,您可以使用命令語法並列印至 stdout。
從腳本設定作業範圍的變數
若要從文稿設定變數,您可以使用task.setvariable記錄命令。 這會更新後續作業的環境變數。 後續作業可以存取具有 巨集語法 的新變數,並在工作中當做環境變數。
當 為 true 時 issecret ,變數的值將會儲存為秘密,並從記錄中遮罩。 如需秘密變數的詳細資訊,請參閱 記錄命令。
steps:
# Create a variable
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes" # remember to use double quotes
# Use the variable
# "$(sauce)" is replaced by the contents of the `sauce` variable by Azure Pipelines
# before handing the body of the script to the shell.
- bash: |
echo my pipeline variable is $(sauce)
後續步驟也會將管線變數新增至其環境。 您無法在定義之步驟中使用 變數。
steps:
# Create a variable
# Note that this does not update the environment of the current script.
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes"
# An environment variable called `SAUCE` has been added to all downstream steps
- bash: |
echo "my environment variable is $SAUCE"
- pwsh: |
Write-Host "my environment variable is $env:SAUCE"
上述管線的輸出。
my environment variable is crushed tomatoes
my environment variable is crushed tomatoes
設定多作業輸出變數
如果您想要讓變數可供未來的作業使用,您必須使用 isOutput=true將它標示為輸出變數。 然後,您可以使用 語法將它對應至未來的作業 $[] ,並包含設定變數的步驟名稱。 多作業輸出變數僅適用於相同階段中的作業。
若要將變數傳遞至不同階段的作業,請使用階段相 依性 語法。
注意
根據預設,管線中的每個階段都會相依於 YAML 檔案中的階段。 因此,每個階段都可以使用先前階段的輸出變數。 若要存取進一步階段,您必須改變相依性圖表,例如,如果階段 3 需要階段 1 中的變數,您必須在階段 1 上宣告明確的相依性。
當您建立多作業輸出變數時,應該將表達式指派給變數。 在這裡 YAML 中, $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] 會指派給 變數 $(myVarFromJobA)。
jobs:
# Set an output variable from job A
- job: A
pool:
vmImage: 'windows-latest'
steps:
- powershell: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable into job B
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobA: $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] # map in the variable
# remember, expressions require single quotes
steps:
- script: echo $(myVarFromJobA)
name: echovar
上述管線的輸出。
this is the value
this is the value
如果您要將變數從某個階段設定為另一個階段,請使用 stageDependencies。
stages:
- stage: A
jobs:
- job: A1
steps:
- bash: echo "##vso[task.setvariable variable=myStageOutputVar;isOutput=true]this is a stage output var"
name: printvar
- stage: B
dependsOn: A
variables:
myVarfromStageA: $[ stageDependencies.A.A1.outputs['printvar.myStageOutputVar'] ]
jobs:
- job: B1
steps:
- script: echo $(myVarfromStageA)
如果您要從 矩陣 或 配量設定變數,請在從下游作業存取變數時參考變數,您必須包含:
- 作業的名稱。
- 步驟。
jobs:
# Set an output variable from a job with a matrix
- job: A
pool:
vmImage: 'ubuntu-latest'
strategy:
maxParallel: 2
matrix:
debugJob:
configuration: debug
platform: x64
releaseJob:
configuration: release
platform: x64
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the $(configuration) value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the debug job
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobADebug: $[ dependencies.A.outputs['debugJob.setvarStep.myOutputVar'] ]
steps:
- script: echo $(myVarFromJobADebug)
name: echovar
jobs:
# Set an output variable from a job with slicing
- job: A
pool:
vmImage: 'ubuntu-latest'
parallel: 2 # Two slices
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the slice $(system.jobPositionInPhase) value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobsA1: $[ dependencies.A.outputs['job1.setvarStep.myOutputVar'] ]
steps:
- script: "echo $(myVarFromJobsA1)"
name: echovar
請務必在作業名稱前面加上部署作業的輸出變數。 在這裡情況下,作業名稱為 A:
jobs:
# Set an output variable from a deployment
- deployment: A
pool:
vmImage: 'ubuntu-latest'
environment: staging
strategy:
runOnce:
deploy:
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the deployment variable value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromDeploymentJob: $[ dependencies.A.outputs['A.setvarStep.myOutputVar'] ]
steps:
- bash: "echo $(myVarFromDeploymentJob)"
name: echovar



使用表達式設定變數
您可以使用表示式來設定變數。 我們已經遇到一個案例,將變數設定為先前作業中另一個變數的輸出。
- job: B
dependsOn: A
variables:
myVarFromJobsA1: $[ dependencies.A.outputs['job1.setvarStep.myOutputVar'] ] # remember to use single quotes
您可以使用任何支援的運算式來設定變數。 以下是將變數設定為做為計數器的範例,從 100 開始,每次執行都會遞增 1,並且每天重設為 100。
jobs:
- job:
variables:
a: $[counter(format('{0:yyyyMMdd}', pipeline.startTime), 100)]
steps:
- bash: echo $(a)
如需計數器、相依性和其他表達式的詳細資訊,請參閱 表達式。
設定步驟的可設定變數
您可以在步驟內定義 settableVariables ,或指定無法設定任何變數。
在此範例中,腳本無法設定變數。
steps:
- script: echo This is a step
target:
settableVariables: none
在這裡範例中,文稿允許變數 sauce ,但不允許變數 secretSauce。 您會在管線執行頁面上看到警告。

steps:
- bash: |
echo "##vso[task.setvariable variable=Sauce;]crushed tomatoes"
echo "##vso[task.setvariable variable=secretSauce;]crushed tomatoes with garlic"
target:
settableVariables:
- sauce
name: SetVars
- bash:
echo "Sauce is $(sauce)"
echo "secretSauce is $(secretSauce)"
name: OutputVars
在佇列時允許
如果變數出現在 YAML 檔案的區塊中 variables ,則會修正其值,而且無法在佇列時間覆寫。 最佳做法是在 YAML 檔案中定義您的變數,但有時沒有意義。 例如,您可能想要定義秘密變數,而不會在 YAML 中公開變數。 或者,您可能需要在管線執行期間手動設定變數值。
您有兩個選項可用來定義佇列時間值。 您可以在 UI 中定義變數,然後選取 [讓使用者在執行此管線時覆寫此值] 選項,或者您可以改用運行時間參數。 如果您的變數不是秘密,最佳做法是使用 運行時間參數。
若要在佇列時間設定變數,請在管線中新增變數,然後選取覆寫選項。
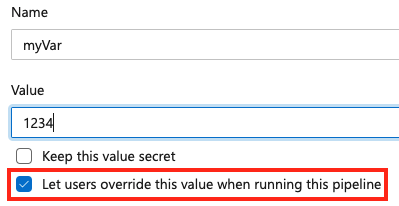
若要允許在佇列時間設定變數,請確定變數不會同時出現在 variables 管線或作業的區塊中。 如果您在 YAML 和 UI 的 variables 區塊中定義變數,則 YAML 中的值具有優先順序。

變數的擴充
如果您在多個範圍中設定具有相同名稱的變數,則會套用下列優先順序 (優先順序最高的優先)。
- YAML 檔案中設定的作業層級變數
- YAML 檔案中設定的階段層級變數
- YAML 檔案中設定的管線層級變數
- 在佇列時設定的變數
- 管線設定 UI 中設定的管線變數
在下列範例中,相同的變數 a 是在 YAML 檔案中的管線層級和作業層級設定。 它也會在變數群組 G中設定,並在管線設定UI中設定為變數。
variables:
a: 'pipeline yaml'
stages:
- stage: one
displayName: one
variables:
- name: a
value: 'stage yaml'
jobs:
- job: A
variables:
- name: a
value: 'job yaml'
steps:
- bash: echo $(a) # This will be 'job yaml'
當您在相同範圍中設定具有相同名稱的變數時,最後一個設定值會優先。
stages:
- stage: one
displayName: Stage One
variables:
- name: a
value: alpha
- name: a
value: beta
jobs:
- job: I
displayName: Job I
variables:
- name: b
value: uno
- name: b
value: dos
steps:
- script: echo $(a) #outputs beta
- script: echo $(b) #outputs dos
注意
當您在 YAML 檔案中設定變數時,請勿在 Web 編輯器中將其定義為在佇列時間可設定。 您目前無法在佇列時變更 YAML 檔案中設定的變數。 如果您需要在佇列時設定變數,請勿在 YAML 檔案中設定它。
啟動執行時,變數會展開一次,並在每個步驟的開頭再次展開。 例如:
jobs:
- job: A
variables:
a: 10
steps:
- bash: |
echo $(a) # This will be 10
echo '##vso[task.setvariable variable=a]20'
echo $(a) # This will also be 10, since the expansion of $(a) happens before the step
- bash: echo $(a) # This will be 20, since the variables are expanded just before the step
上述範例中有兩個步驟。 的擴充 $(a) 會在作業的開頭發生一次,並在兩個步驟的開頭一次。
因為變數會在作業開始時展開,因此您無法在策略中使用變數。 在下列範例中,您無法使用 變數 a 來展開作業矩陣,因為變數只能在每個展開作業的開頭使用。
jobs:
- job: A
variables:
a: 10
strategy:
matrix:
x:
some_variable: $(a) # This does not work
如果變數 a 是上一個作業的輸出變數,您可以在未來的工作中使用它。
- job: A
steps:
- powershell: echo "##vso[task.setvariable variable=a;isOutput=true]10"
name: a_step
# Map the variable into job B
- job: B
dependsOn: A
variables:
some_variable: $[ dependencies.A.outputs['a_step.a'] ]
遞歸展開
在代理程式上,使用 $( ) 語法參考的變數會以遞歸方式展開。
例如:
variables:
myInner: someValue
myOuter: $(myInner)
steps:
- script: echo $(myOuter) # prints "someValue"
displayName: Variable is $(myOuter) # display name is "Variable is someValue"